目录
一、前言
二、版本信息
三、配置相关文件
1.修改spark-env.sh文件
2.修改.bashrc文件
四、安装Python3.5.2并更改默认Python版本
1.查看当前默认Python版本
2.安装Python3.5.2
2.1 下载Python源码
2.2 解压源码
2.3 配置安装路径
2.4 编译和安装
2.5 验证安装
2.6 创建 Python 符号链接
五、启动Pyspark
一、前言
pyspark提供了简单的方式来学习API,并且提供了交互的方式来分析数据。你可以输入一条语句,pyspark 会立即执行语句并返回结果,这就是我们所说的交互式解释器( Read-Eval-Print Loop,REPL )。它为我们提供了交互式执行环境,表达式计算完成以后就会立即输出结果,而不必等到整个程序运行完毕。因此可以即时查看中间结果并对程序进行修改,这样一来, 就可以在很大程度上提高程序开发效率。Spark支持Scala和Python,由于Spark框架本身就是使用Scala语言开发的,所以,使用spark-shell命令会默认进入Scala的交互式执行环境。如果要进入Python的交互式执行环境,则需要执行pyspark命令。
与其他Shell工具不一样的是,在其他Shell工具中,我们只能使用单机的硬盘和内存来操作数据,而pyspark可用来与分布式存储在多台机器上的内存或者硬盘上的数据进行交互,并且处理过程的分发由Spark自动控制完成,不需要用户参与。
在配置pyspark之前默认读者已经安装Spark2.4.0到/usr/local目录下!
二、版本信息
虚拟机产品:VMware® Workstation 17 Pro 虚拟机版本:17.0.0 build-20800274
ISO映像文件:ubuntukylin-22.04-pro-amd64.iso
Hadoop版本:Hadoop 3.1.3
JDK版本:Java JDK 1.8
Spark版本:Spark 2.4.0
Python版本:Python 3.5.2
这里有我放的百度网盘下载链接,读者可以自行下载:
链接:https://pan.baidu.com/s/121zVsgc4muSt9rgCWnJZmw
提取码:wkk6
注意:其中的ISO映象文件为ubuntukylin-16.04.7版本的而不是22.04版本,22.04版本内存过大无法上传,见谅!!!
三、配置相关文件
1.修改spark-env.sh文件
修改Spark的配置文件spark-env.sh:
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
vim ./conf/spark-env.sh- 在第一行添加以下配置信息并保存:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)这条配置信息的作用是将Hadoop的类路径设置到环境变量SPARK_DIST_CLASSPATH中,确保Spark可以访问Hadoop的所有必需类库和配置。这对于在Hadoop集群上运行Spark作业,或者需要访问存储在HDFS上的数据时尤为重要。
有了上面的配置信息以后,Spark就可以把数据存储到Hadoop分布式文件系统(HDFS)中,可以从HDFS中读取数据。如果没有配置上面的信息,Spark就只能读写本地数据,无法读写HDFS中的数据。
2.修改.bashrc文件
.bashrc文件中必须包括以下环境变量的设置:
- JAVA_HOME
- HADOOP_HOME
- SPARK_HOME
- PYTHONPATH
- PYSPARK_PYTHON
- PATH
如果读者已经设置了这些环境变量则不需要重新添加设置;如果还没有设置,则需要使用vim编辑器打开.bashrc文件,命令如下:
vim ~/.bashrc把该文件修改为如下内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=$PATH:${JAVA_HOME}/bin:/usr/local/hbase/bin
export HADOOP_HOME=/usr/local/hadoop
export SPARK_HOME=/usr/local/spark
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/1ib/py4j-0.10.7-src.zip:$PYTHONPATH
export PYSPARK_PYTHON=python3
export PATH=$HADOOP_HOME/bin:$SPARK_HOME/bin:$PATH在上述设置中,PYTHONPATH环境变量主要是为了在python3中引入pyspark库,PYSPARK_PYTHON变量主要用于设置pyspark运行的Python版本。需要注意的是,在PYTHONPATH中,出现了py4j-0.10.7-src.zip,这个文件名必须与“/usr/local/spark/python/lib”目录下的py4j-0.10.7-src.zip保持一致。

最后,需要在Linux终端中执行如下代码让该环境变量生效:
source ~/.bashrc四、安装Python3.5.2并更改默认Python版本
在启动pyspark之前我们需要注意Ubuntu22.04所自带的python3的版本为3.10.12!!!该版本与我们所使用的Spark2.4.0版本并不兼容!!!故需安装Python3.5.2
1.查看当前默认Python版本
在终端中输入python3(并不是python,具体原因可移步于本人的另一篇文章:Ubuntu进入python时报错:找不到命令 “python”,“python3” 命令来自 Debian 软件包 python3-CSDN博客)即可看到当前系统中默认的python版本是 3.10.12:

输入exit()命令并按回车键或使用快捷键Ctrl+D退出Python 3的交互式会话并返回到系统的命令行界面。
同样进入/usr/bin目录下搜索python可以看到python的可执行文件的版本:

2.安装Python3.5.2
2.1 下载Python源码
Python3.5.2的源代码压缩包请读者自行到Python官网下载或者从本文章中二、版本信息的百度网盘中进行下载
下载完成后将文件从物理机拖拽到虚拟机Ubuntu22.04系统中的家目录下的下载文件夹中:
2.2 解压源码
在终端中进入下载目录,解压 Python 源码文件:
cd ~/下载
tar -zxvf Python-3.5.2.tgz
2.3 配置安装路径
进入解压后的 Python 源码目录,并执行以下命令进行配置,指定安装路径为 /usr(注意:若不指定安装路径,默认安装路径为/usr/local):
cd ./Python-3.5.2
./configure --prefix=/usr
2.4 编译和安装
接着,执行以下命令编译和安装 Python:
make
sudo make install2.5 验证安装
最后,运行以下命令验证 Python 是否已成功安装到 /usr/bin 中:
python3 --version
再次查看Python默认版本即可看到已经更改为Python3.5.2:

2.6 创建 Python 符号链接
确保系统中有正确的 Python 符号链接指向要使用的 Python 版本:
sudo ln -s /usr/bin/python3 /usr/bin/python五、启动Pyspark
完成上述安装及配置后启动Pyspark:
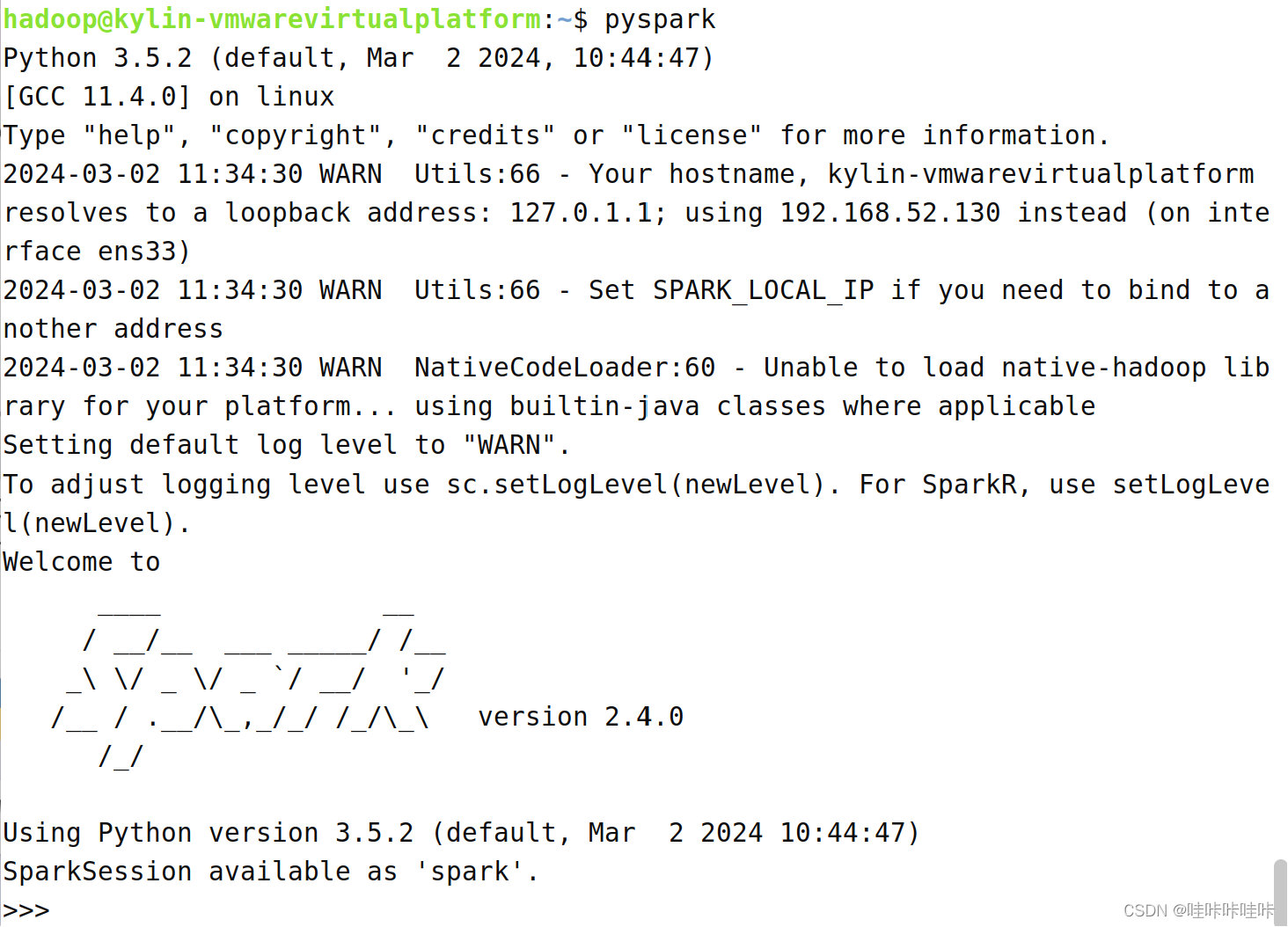
可以看到启动成功!!!