文章目录
- 原理
- 选举机制(重点)
- 情况1:正常启动集群
- 情况2:集群启动完,中途有机器挂了
- 监听器
- 客户端向服务端写入数据
- 客户端向服务端Leader节点写入
- 客户端向服务端Follower节点写入
- Paxos算法(每个节点都可以提议者)
- ZAB协议算法 - Paxos算法的改良 - 集群仅能一位提议者(即Leader)
- 认识
- 崩溃恢复
- Leader挂,重新选举
- 数据恢复
- CAP理伦
- 脚本
- 集群统一启动、关闭、状态查看脚本
- 源码分析(粗略)
- 辅助源码
- 持久化
- 序列化
- 服务端启动流程
- 服务端选举Leader流程
- Leader、Follower数据同步流程
- 服务端Leader启动Zk过程
- 服务端Follower启动Zk过程
- 客户端连接Zk服务端过程
原理
选举机制(重点)
情况1:正常启动集群
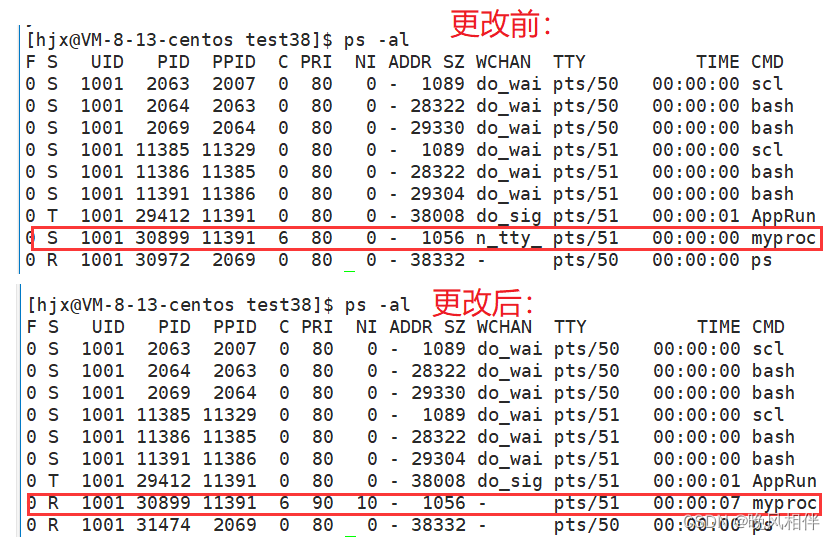
集群正常总固定票数: conf/zoo.cfg里面的server.的配置行数
特点:
- 一旦选举出领导leader,除非作为leader的zookeeper挂了,否则不会在重新选举,其他新进的zookeeper集群都作为追随者Following
- 存活的zookeeper机器必须【集群正常总固定票数】的一半以上才会进行选举leader角色,否则一直是Looking
- zookeeper可以给自己投票,一旦每个人的票数都一样,交换myid查看后,谁大就把投自己的票改投成myid最大的那个

集群中5台zookeeper机器依次启动后选举领导的整个过程

情况2:集群启动完,中途有机器挂了
监听器
流程: zookeeper客户端告知服务端需要监听某某节点的数据变化,服务端一旦节点发生变化,就将变化通知内容推送给客户端

监听数据的变化

监听子节点增删的变化

客户端向服务端写入数据
客户端向服务端Leader节点写入
流程: Leader会传递给Follower去写入,如果 超半数的zookeeper都写入成功,则Leader服务端机器会告诉客户端数据写入成功 ,剩下Follower还未写入的Leader会慢慢通知他们写入,反正最终zookeeper服务端集群内所有机器都写入成功

客户端向服务端Follower节点写入
流程: Follower会先将 客户端的写入请求转给Leader,Leader自己将写入请求先执行,在将这个写入请求分发给集群内所有Follower机器 ,所有集群中超过半数的zookeeper都写入成功,则Leader会告知当初最开始那台Follower机器说明此次写入成功,然后由该台Follower告知客户端集群此次写入成功

Paxos算法(每个节点都可以提议者)
Paxos算法: 基于消息传递且具有高度容错特性的一致性算法。快速正确的在一个分布式系统保持数据值一致,保证无论发生任何异常都不会破坏系统的一致性
Propose(提议): 任务编号
Proposal(提案): 任务编号+任务内容

Paxos算法完美情况

Paxos算法弊端

ZAB协议算法 - Paxos算法的改良 - 集群仅能一位提议者(即Leader)
认识
概念: 只有一台客户端(Leader)负责处理外部的写事务请求,然后Leader客户端将数据同步到其他Follower节点。即Zookeeper只有一个Leader可以发起提案
此图对应的是上图的流程图

崩溃恢复
Leader挂,重新选举
数据恢复
CAP理伦
分布式系统最多同时满足CAP其中的两项,不可能三项同时满足
Zookeeper:满足的是CP的两项要求
脚本
集群统一启动、关闭、状态查看脚本
zk.sh
#!/bin/bash
# 运行此脚本前必须把当前机器人的公私密钥给到目标运行机器 == 要不然每次运行此脚本时都会叫你输入每台目标机器的密码
# 命令1(本机生成RSA公私密钥):ssh-keygen -t rsa
# 命令2(将密钥传给目标三台机器即192.168.19.107、192.168.19.108、192.168.19.109 ):ssh-copy-id root@目标机器IPfor currentHostName in 192.168.19.107 192.168.19.108 192.168.19.109
doecho "=================zookeeper【${currentHostName}】【$1】==============================="case $1 in"start") {ssh $currentHostName "cd /opt/module/zookeeper-3.9.1 && sh bin/zkServer.sh start"};;"stop") {ssh $currentHostName "cd /opt/module/zookeeper-3.9.1 && sh bin/zkServer.sh stop"};;"status") {ssh $currentHostName "cd /opt/module/zookeeper-3.9.1 && sh bin/zkServer.sh status"};;*) {echo "未知命令,仅支持start|stop|status"}esacdone
源码分析(粗略)
辅助源码
持久化
数据存储: 集群中的数据会在内存(树)、磁盘中各存一份
接口: 快照【org.apache.zookeeper.server.persistence.SnapShot】、事务记录【org.apache.zookeeper.server.persistence.TxnLog】
事务日志(txnlog): ZooKeeper会将所有的写操作以事务的形式记录在事务日志中,这些写操作包括创建节点、更新节点数据、删除节点等。事务日志是一个追加写的日志文件,用于记录每个写操作的详细信息。通过事务日志,ZooKeeper可以保证数据的一致性和持久性
快照(snapshot): ZooKeeper定期会生成一个快照文件,用于保存当前内存中所有节点的状态。快照文件包含了所有节点的数据和元数据信息。当ZooKeeper服务器启动时,会首先加载最新的快照文件,然后通过回放事务日志来恢复到最新的状态。
Zookeeper启动数据恢复流程: 先加载最新的快照文件,然后通过回放事务日志来将数据恢复到最新的状态

序列化
接口: 序列化、反序列化【org.apache.jute.Record】

服务端启动流程
入口类: org.apache.zookeeper.server.quorum.QuorumPeerMain#main

服务端选举Leader流程

Leader、Follower数据同步流程
概括: Follower必须去看Leader保持一致,而不是Leader跟Follower保持一致
【Follower】Learner: org.apache.zookeeper.server.quorum.Learner#registerWithLeader
【Leader】LearnerHandler: org.apache.zookeeper.server.quorum.LearnerHandler#run

服务端Leader启动Zk过程
核心: org.apache.zookeeper.server.quorum.Leader#startZkServer

服务端Follower启动Zk过程
核心: org.apache.zookeeper.server.quorum.Follower#followLeader

客户端连接Zk服务端过程
核心入口: org.apache.zookeeper.ZooKeeperMain#main

刚兴趣的同行可以进群沟通交流,内置机器人供大家愉快


![[网鼎杯 2020 半决赛]AliceWebsite --不会编程的崽](https://img-blog.csdnimg.cn/direct/43cf0115e3b94e65940f98ffe51712a8.png)