过拟合
- 即模型在训练集上表现的很好,但是在测试集上效果却很差。也就是说,在已知的数据集合中非常好,再添加一些新数据进来效果就会差很多
欠拟合
- 即模型在训练集上表现的效果差,没有充分利用数据,预测准确率很低,拟合结果严重不符合预期
dropout层
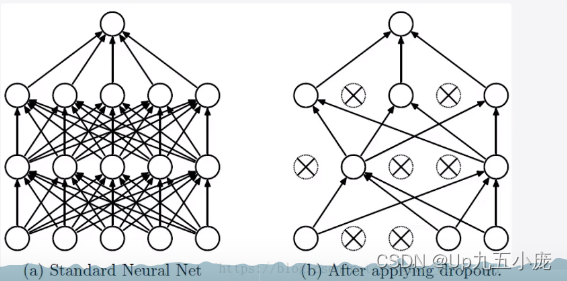
为什么说Dropout可以解决过拟合
- 取平均的作用
先回到标准的模型即没有dropout,我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采取“5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。 - 减少神经元之间复杂的共适应关系
因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其他特征下才有效果的情况。 - dropout类似于性别在生物进化中的角色
物种为了生存往往会倾向于适用这种环境,环境突变则会导致物种难以做出及时的反应,性别的出现可以繁衍出适用新环境的变种,有效的阻止过拟合,即避免环境改变时物种可能面临的灭绝
参数选择原则
- 理想的模型刚好在欠拟合和过拟合的界线上,也就是正好拟合数据。
首先开发一个过拟合的模型
- 添加更多的层
- 让每一层变得更大
- 训练更多的轮次
然后抑制过拟合
- dropout
- 正则化
- 图像增强
- 增大训练数据是抑制过拟合的最好办法,在没有数据的前提下,上面三种方法可以来抑制过拟合
再次调节超参数
- 学习速率
- 隐藏单层神经元数
- 训练轮次
- 超参数的选择是一个经验与不断测试的结果。经典机器学习的方法,如特征工程,增加训练数据也要做
- 交叉验证
构建网络的总原则
- 总的原则是:保证神经网络容量组个拟合数据
- 增大网络容量,直到过拟合
- 采取措施抑制过拟合
- 继续增大网络容量,直到过拟合