文章目录
- Spring整合Elasticsearch
- 引入依赖
- 配置Elasticsearch
- 解决冲突
- 使用Elasticsearch
- Spring Data Elasticsearch
- 建立映射关系
- 常用方法
- 添加数据
- 修改数据
- 删除数据
- 搜索数据(es核心)
- 步骤
- 构造搜索条件 并 应用
- 进行查询
- 使用查询结果
Spring整合Elasticsearch
引入依赖
- spring-boot-starter-data-elasticsearch
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency>
配置Elasticsearch
- cluster-name集群名
- cluster-nodes集群节点
# ElasticsearchProperties
# 配置集群名,与es配置文件中的一致
spring.data.elasticsearch.cluster-name=nowcoder
# 集群节点,格式 节点ip地址:端口
spring.data.elasticsearch.cluster-nodes=127.0.0.1:9300
解决冲突
如果项目中使用了redis,则需要解决冲突
es和redis都基于netty,这两者在启动netty时,会产生冲突:系统会认为redis已经启动了netty,es无法再启动
要尽可能在服务启动早期的时候,修改es.set.netty.runtime.available.processors为 false
修改入口类,因为入口类是最先被加载的
@PostConstruct: 管理bean的生命周期,主要用于初始化的方法,该注解修饰的方法在构造器调用完以后被执行
在这个初始化方法中修改系统属性就足够早
@SpringBootApplication
public class CommunityApplication {@PostConstructpublic void init() {// 解决netty启动冲突问题// es.set.netty.runtime.available.processors 从 Netty4Utils.setAvailableProcessors() 中找到// 设置系统属性System.setProperty("es.set.netty.runtime.available.processors", "false");}public static void main(String[] args) {SpringApplication.run(CommunityApplication.class, args);}}
使用Elasticsearch
Spring Data Elasticsearch
用于访问es服务器的API
-
ElasticsearchTemplate :有特殊情况,DiscussPostRepository处理不了时使用
-
ElasticsearchRepository: 接口,需要定义一个子接口继承他,声明访问哪些数据,Spring会自动实现这个接口
所有的代码都是Spring自动生成的,Spring会自动将实体数据和es服务器的索引进行映射,因此需要用注解
代码实例:
// es可以看成特殊的数据库,因此加上注解@Repository // @Mapper是MyBa'ti'd专有注解 // @Repository是spring提供的,针对数据访问层的注解 @Repository // es的接口一般取名XXXRepository,该接口访问的是帖子,故叫DiscussPostRepository public interface DiscussPostRepository extends ElasticsearchRepository<DiscussPost, Integer> {// 继承时要用泛型声明:当前接口要处理的实体类,以及实体类中的id类型// 父接口ElasticsearchRepository中 已经定义好了对es服务器访问的增删改查方法// 声明完泛型,加上注解之后,spring会自动实现自定义的子接口DiscussPostRepository }
建立映射关系
要对spring说明哪个实体类和es的索引怎样进行对应,建立映射关系,映射完成后,spring底层就可以帮我们生成实现类
-
用@Document指明 表 和 es 中索引的对应关系
@Document ( indexName = “…”, type = “…”, shards = , replicas = )
indexName: 实体数据映射到哪个索引上。通常为全小写的类名
type: 实体数据映射到哪个类型上。类型已经在逐步被弱化甚至取消了,因此写成固定的 _doc
shards: 创建几个分片。根据服务器处理能力配
replicas: 创建几个副本。
没有指定索引会创建这个索引,并且是根据指定分片和副本进行创建的 -
指明 实体中属性 和 es中字段 的对应关系
给类中每个 属性 上加注解用于和 索引中的字段 相关联
表的id属性要 加 @id 注解
@Id // 与索引中id字段对应private int id;
其他普通属性 加 @Field注解并指明字段类型
// 用于普通字段,需指明字段类型@Field(type = FieldType.Integer)private int userId;
当某些属性 对应的 es字段要用于关键词匹配时,需在注解中指明使用的analyzer和searchAnalyzer
analyzer为存储时候的解析器/分词器。
当我们存一句话时,会提取出关键词,并用关键词关联这句话,搜索时就可以通过关键词搜到这句话
因此存的时候,因该尽可能将一句话拆出尽可能多的关键词,以扩大搜索范围。
故需要一个范围非常大的分词器,而我们安装的中文分词器中存在这样的分词器——ik_max_word
searchAnalyzer为搜索时候解析器/分词器
搜索时,输入的句子不需要拆出过多关键词,不用拆的过细
如”互联网校招“,可以拆出:互联网、联网、网校、校招等关键词,但实际上我们没有这些意思
此时要使用拆分出尽可能少但满足用户需求的词语——ik_smart
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")private String content;
// 将数据库中帖子存到es服务器里,就可以去es服务器中搜索这些帖子了
@Document(indexName = "discusspost", type = "_doc", shards = 6, replicas = 3)
public class DiscussPost {@Id // 与索引中id字段对应private int id;// userId为普通字段@Field(type = FieldType.Integer)private int userId;// 搜帖子主要在title和content中查找@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")private String title;@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")private String content;// 不用在这些字段进行搜索,就不用analyzer和searchAnalyzer属性@Field(type = FieldType.Integer)private int type;@Field(type = FieldType.Integer)private int status;@Field(type = FieldType.Date)private Date createTime;@Field(type = FieldType.Integer)private int commentCount;@Field(type = FieldType.Double)private double score;}
常用方法
添加数据
一次添加一条数据:save(一条数据)
@Testpublic void testInsert() {// 给es服务器添加数据:save(一条数据)// 在mysql中找到一条数据discussMapper.selectDiscussPostById(241),添加到es服务器// 不用特地创建索引,索引不存在时,es会帮我们自动创建discussRepository.save(discussMapper.selectDiscussPostById(241));discussRepository.save(discussMapper.selectDiscussPostById(242));discussRepository.save(discussMapper.selectDiscussPostById(243));}
一次添加多条数据:saveAll(多条数据)
@Testpublic void testInsertList() {// 一次添加多条数据:saveAll(多条数据)// discussMapper.selectDiscussPosts(101, 0, 100) mysql分页查找discussRepository.saveAll(discussMapper.selectDiscussPosts(101, 0, 100));discussRepository.saveAll(discussMapper.selectDiscussPosts(102, 0, 100));discussRepository.saveAll(discussMapper.selectDiscussPosts(103, 0, 100));discussRepository.saveAll(discussMapper.selectDiscussPosts(111, 0, 100));discussRepository.saveAll(discussMapper.selectDiscussPosts(112, 0, 100));discussRepository.saveAll(discussMapper.selectDiscussPosts(131, 0, 100));discussRepository.saveAll(discussMapper.selectDiscussPosts(132, 0, 100));discussRepository.saveAll(discussMapper.selectDiscussPosts(133, 0, 100));discussRepository.saveAll(discussMapper.selectDiscussPosts(134, 0, 100));}
修改数据
调用save方法将之前的数据再覆盖一遍
@Testpublic void testUpdate() {// 查出第231条数据,修改属性DiscussPost post = discussMapper.selectDiscussPostById(231);post.setContent("我是新人,使劲灌水.");// 用save覆盖原来的discussRepository.save(post);}
删除数据
一次删除一条数据:deleteById( id )
@Testpublic void testDelete() {discussRepository.deleteById(231);}
一次删除所有数据:deleteAll
风险高,不常用
@Testpublic void testDelete() {discussRepository.deleteAll();}
搜索数据(es核心)
步骤
-
构造搜索条件 并 应用
搜索条件:要不要排序、分页、结果要不要高亮显示等
高亮显示:给关键词加em标签,在文本显示到网页上时,前端可以给em加样式
搜索条件构造方式:SearchQuery对象,实现类是NativeSearchQuery,而NativeSearchQueryBuilder是一个可以构造NativeSearchQuery的工具类
SearchQuery searchQuery = new NativeSearchQueryBuilder()// 1)指定查询条件:withQuery// 查询条件由QueryBuilders对象构造,multiMatchQuery用于指定查询关键词和查询字段范围.withQuery(QueryBuilders.multiMatchQuery("互联网寒冬", "title", "content"))// 2)指定排序条件// 优先按照置顶排序,再按分数(精品贴会被折算成分数),都相同就按创建时间排序.withSort(SortBuilders.fieldSort("type").order(SortOrder.DESC)).withSort(SortBuilders.fieldSort("score").order(SortOrder.DESC)).withSort(SortBuilders.fieldSort("createTime").order(SortOrder.DESC))// 3)指定分页条件.withPageable(PageRequest.of(0, 10))// 4)指定给哪些字段里匹配词进行高亮显示.withHighlightFields(new HighlightBuilder.Field("title").preTags("<em>").postTags("</em>"),new HighlightBuilder.Field("content").preTags("<em>").postTags("</em>"))// 5)执行,即应用搜索条件.build(); -
进行查询
分页查询结果用spring提供的Page对象接收
Page中封装多个实体,即当前这一页的实体方法一:用Repository进行搜索
Page<DiscussPost> page = discussRepository.search(searchQuery);存在问题:
es返回结果包含:原始结果(即匹配到的结果) 和 高亮显示部分(即匹配到的关键词前后一部分内容,不是整个内容,不会浪费空间)
需要将高亮显示部分整合到原始结果中,进行一个替换,太过麻烦,不够完善问题原因:
查询方法discussRepository.search(searchQuery)的源码底层调用如下方法进行查询:
elasticTemplate.queryForPage(searchQuery, class, SearchResultMapper)得到的两份数据,需要用SearchResultMapper进行组装,但默认实现类底层没有组装,即底层获取得到了高亮显示部分, 但是没有返回(结果里看不到).

方法二:直接用ElasticsearchTemplate进行搜索
elasticTemplate. queryForPage(搜索条件, 实体类型, 处理两部分结果合并问题的接口)通过匿名内部类方式,实现接口:
new SearchResultMapper() {@Overridepublic <T> AggregatedPage<T> mapResults(SearchResponse response, Class<T> aClass, Pageable pageable) {... ...} }实现接口方法:
-
获取搜索命令查询结果
通过response获取搜索命令的数据,可能会得到多条数据,放在SearchHits中
SearchHits hits = response.getHits(); -
判断结果是否为空
搜索命令返回结果的数据量,即返回结果有几条数据
if (hits.getTotalHits() <= 0) {return null; } -
遍历每一条数据,转成目标实体存储
将这些实体存储在集合中List<DiscussPost> list
for (SearchHit hit : hits)hits中每一条数据hit的形式如下
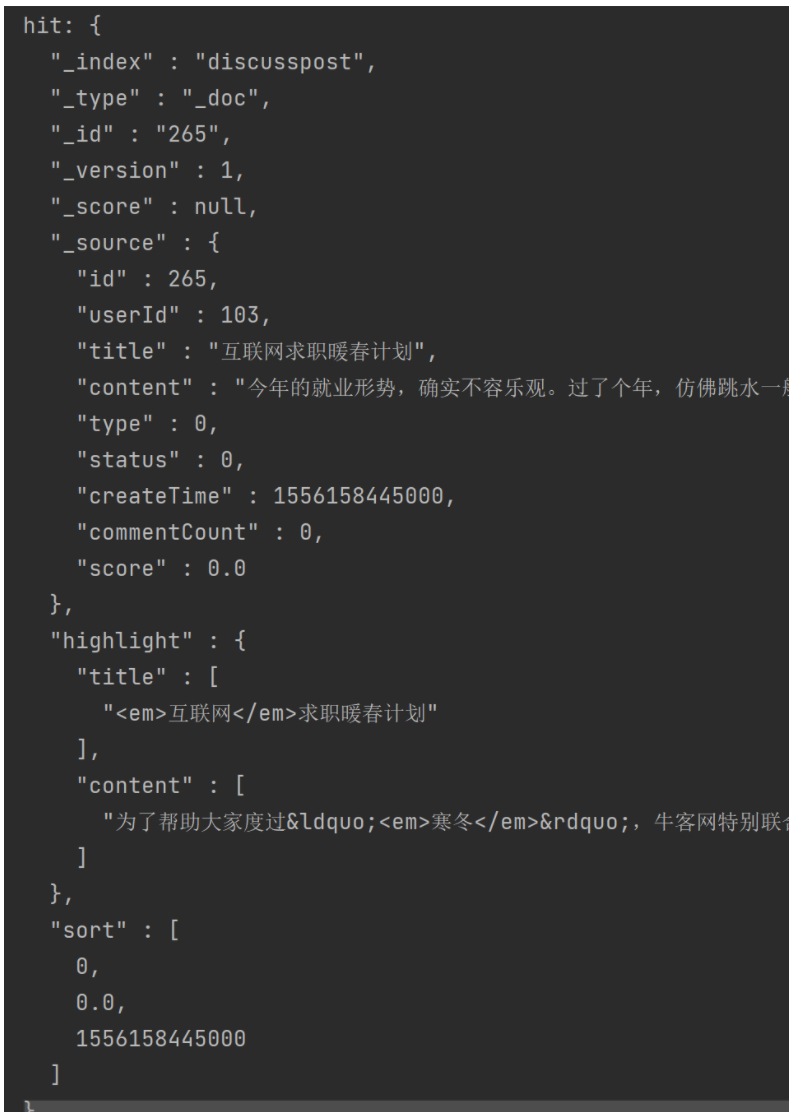
1)处理非高亮显示内容:
获取非高亮内容:
es的返回数据是json格式,SearchHit对象里将json格式对象数据封装成了Map格式
hit.getSourceAsMap():可以获取map形式数据,通过指定map的key可以调用每一个字段的值
处理步骤:
(1)对所有的字段,不管实际有没有高亮显示,都先获取非高亮显示版本不能直接获取高亮显示内容并存入实体,可能导致某些实体属性为空,因为不确定具体在哪个字段中匹配到关键字,某些字段可能没有匹配到关键字
后续处理高亮显示数据时,会用有高亮显示的字段,覆盖 实体属性 原来的非高亮内容
hit.getSourceAsMap().get("id")(2)再把 获取到的任何类型的数据 都转成 字符串
String id = hit.getSourceAsMap().get("id").toString();(3)存到java实体中时,转为对应类型
post.setId(Integer.valueOf(id));2)处理高亮显示内容
获取高亮显示数据
hit.getHighlightFields()(1)获取指定字段高亮显示数据
HighlightField contentField = hit.getHighlightFields().get("content");高亮数据格式:

(2)判断该字段是否有高亮显示数据:有些字段中没有关键字,就没有高亮内容
if (contentField != null)(3)有高亮显示数据时,获取高亮内容第一段
getFragments():返回值是个数组,将内容做了分段,每一段都是 匹配的词语 前后的一部分内容,如上图
由于字段中匹配的词语可能是多个,因此我们只需要第一段设置高亮了就可以
contentField.getFragments()[0].toString()(4)存入实体对应属性(此时就替换了属性中非高亮数据)
post.setContent(contentField.getFragments()[0].toString()); -
返回一个包含 实体集合 的数据
方法返回值是AggregatedPage类型
因此为需要构造AggregatedPage接口的实现类AggregatedPageImpl
实现类中会传多个参数,参数顺序需要看底层源码// list: 结果集合 // pageable:方法的参数 // hits.getTotalHits():数据总条数 return new AggregatedPageImpl(list, pageable, hits.getTotalHits(), response.getAggregations(), response.getScrollId(), hits.getMaxScore());
代码汇总
Page<DiscussPost> page = elasticTemplate.queryForPage(searchQuery, DiscussPost.class, new SearchResultMapper() {@Overridepublic <T> AggregatedPage<T> mapResults(SearchResponse response, Class<T> aClass, Pageable pageable) {SearchHits hits = response.getHits();if (hits.getTotalHits() <= 0) {return null;}List<DiscussPost> list = new ArrayList<>();for (SearchHit hit : hits) {DiscussPost post = new DiscussPost();// 处理非高亮显示结果String id = hit.getSourceAsMap().get("id").toString();post.setId(Integer.valueOf(id));String userId = hit.getSourceAsMap().get("userId").toString();post.setUserId(Integer.valueOf(userId));String title = hit.getSourceAsMap().get("title").toString();post.setTitle(title);String content = hit.getSourceAsMap().get("content").toString();post.setContent(content);String status = hit.getSourceAsMap().get("status").toString();post.setStatus(Integer.valueOf(status));String createTime = hit.getSourceAsMap().get("createTime").toString();// String转Date:String-->Long-->Datepost.setCreateTime(new Date(Long.valueOf(createTime)));String commentCount = hit.getSourceAsMap().get("commentCount").toString();post.setCommentCount(Integer.valueOf(commentCount));// 处理高亮显示的结果HighlightField titleField = hit.getHighlightFields().get("title");if (titleField != null) {post.setTitle(titleField.getFragments()[0].toString());}HighlightField contentField = hit.getHighlightFields().get("content");if (contentField != null) {post.setContent(contentField.getFragments()[0].toString());}list.add(post);}return new AggregatedPageImpl(list, pageable,hits.getTotalHits(), response.getAggregations(), response.getScrollId(), hits.getMaxScore());}}); -
-
使用查询结果
// 一共查到多少数据匹配System.out.println(page.getTotalElements());// 一共有多少页System.out.println(page.getTotalPages());// 当前处在第几页System.out.println(page.getNumber());// 每一页显示多少条数据System.out.println(page.getSize());// 遍历Page中数据,逐一查看// Page继承了Iterable接口,可以被遍历for (DiscussPost post : page) {System.out.println(post);}
![Sqli-labs靶场第13关详解[Sqli-labs-less-13]](https://img-blog.csdnimg.cn/direct/a715019025d54292b17bd97d8ce87138.png)




![[Java 探索者之路] 一个大厂都在用的分布式任务调度平台](https://img-blog.csdnimg.cn/img_convert/89422053301ff68eb7b70f012117d4b8.png)