注意:本文引用自专业人工智能社区Venus AI
更多AI知识请参考原站 ([www.aideeplearning.cn])
反向传播算法
梯度下降和反向传播是神经网络训练过程中两个非常重要的概念,它们密切相关。梯度下降是一种常用的优化算法,它的目标是找到一个函数的最小值或最大值。在神经网络中,梯度下降算法通过调整每个神经元的权重,以最小化网络的损失函数。损失函数是用来衡量网络的输出与真实值之间的误差。梯度下降算法的核心思想是计算损失函数对权重的偏导数,然后按照这个偏导数的反方向调整权重。
反向传播是一种有效的计算梯度的方法,它可以快速计算网络中每个神经元的偏导数。反向传播通过先正向传播计算网络的输出,然后从输出层到输入层反向传播误差,最后根据误差计算每个神经元的偏导数。反向传播算法的核心思想是通过链式法则将误差向后传递,计算每个神经元对误差的贡献。
综上所述,梯度下降和反向传播是神经网络训练过程中两个重要的概念,梯度下降算法用于优化网络的权重,反向传播算法用于计算每个神经元的偏导数。它们密切相关,并在神经网络的训练中起着重要的作用。下面用一个例子演示神经网络层参数更新的完整过程。
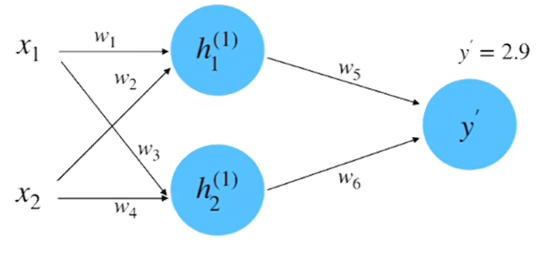
(1)初始化网络,构建一个只有一层的神经网络,如下图所示。
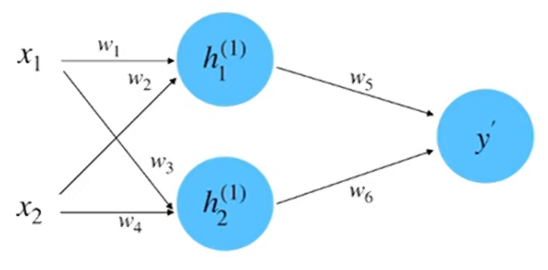
假设图 2-9 中神经网络的输入和输出的初始化为: 。参数的初始化为:
。
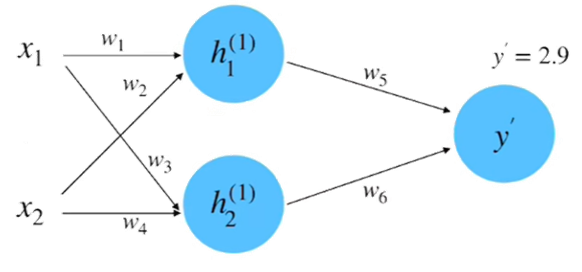
(2) 前向计算, 如下图所示。
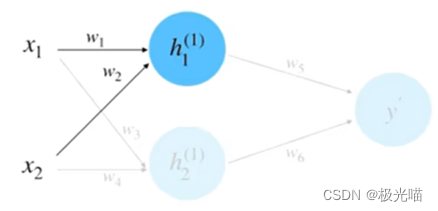
根据输入和权重计算 得:
同理, 计算 等于 0.95 。将
和
相乘求和到前向传播的计算结果, 如下图所示。
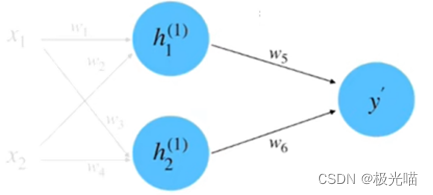
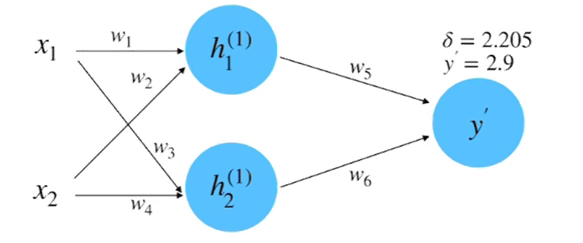
(3) 计算损失: 根据数据真实值 y=0.8 和平方差损失函数来计算损失, 如下图所示。
(4) 计算梯度: 此过程实际上就是计算偏微分的过程, 以参数 的偏微分计算为例,如下图所示。
根据链式法则:
其中:
所以:
(5) 反向传播计算梯度: 在第 4 步中是以参数 为例子来计算偏微分的。如果以参数
为例子, 它的偏微分计算就需要用到链式法则, 过程如下图所示。
(6)梯度下降更新网络参数
假设这里的超参数 “学习速率” 的初始值为 0.1 , 根据梯度下降的更新公式, w1 参数的更新计算如下所示:
同理, 可以计算得到其他的更新后的参数:
到此为止, 我们就完成了参数迭代的全部过程。可以计算一下损失看看是否有减小, 计算如下:
此结果相比较于之间计算的前向传播的结果 2.205, 是有明显的减小的。