一、概述
1、是什么
是单模态“小”语言模型,是一个“Bidirectional Encoder Representations fromTransformers”的缩写,是一个语言预训练模型,通过随机掩盖一些词,然后预测这些被遮盖的词来训练双向语言模型(编码器结构)。可以用于句子分类、词性分类等下游任务,本身旨在提供一个预训练的基础权重。
2、亮点
文章中总结为三点:
* 展示了双向预训练对语言表示的重要性。
* 预训练的特征表示对特定任务降低了精心设计架构的需求。
* BERT 提高了 11 个 NLP 任务的最新指标。
PS
* base版本整体结构和OpenAI的GPT是相同的,只是掩码机制不同,甚至训练数据和策略也尽可能可GPT相同来做对比,并验证了在下游任务的高效性。large是进行了模型缩放。
* 但是如今2024年还是Open AI 的GPT这种纯解码器一统天下,并且后续针对bert的改进,反而移除一些本文的tick,比如NSP任务等。
* 原版论文还是建议看看,因为本文是提供了一个预训练模型,然后可以用于各种下游任务(并且文章解释了怎么处理数据和改动模型),并且也简要介绍了对应的下游任务,可以对NLP领域有个很好的认识。
二、模型
1、模型结构
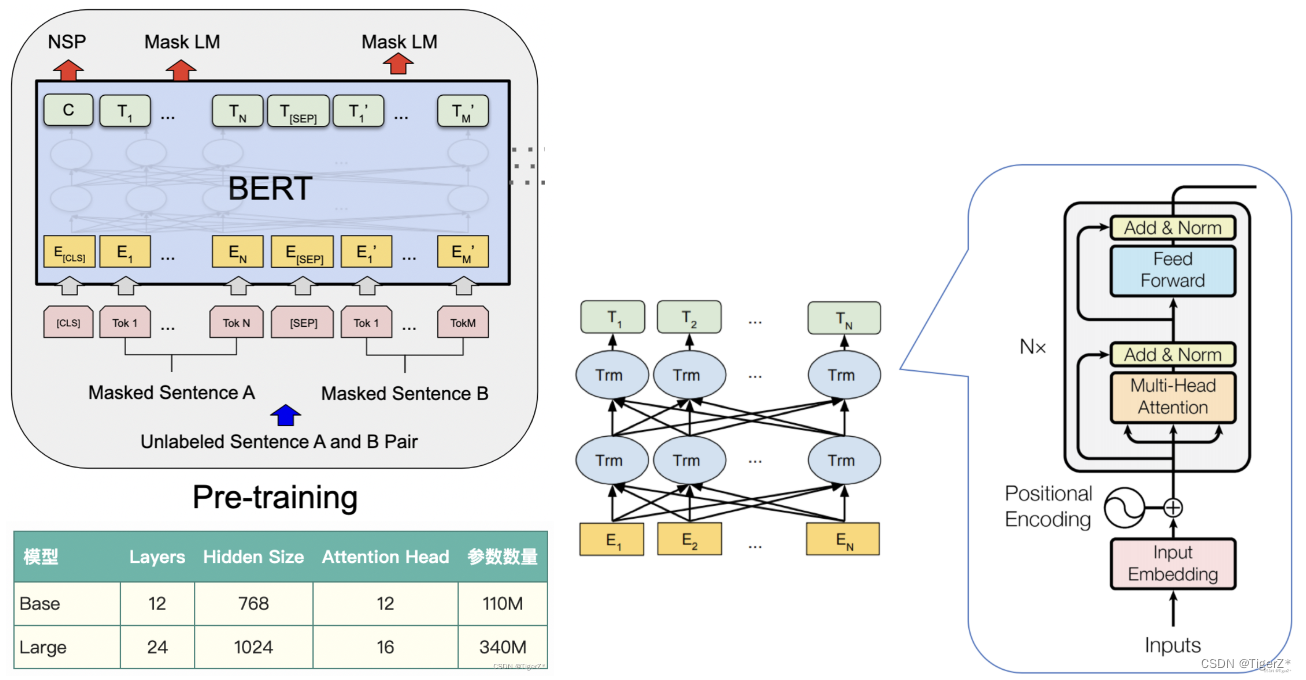
输入需要进行多种embedding处理,模型整体就是标准的transformer编码器,只不过针对不同的任务出入输出头稍有改动:
1)预训练任务:两个loss,分别是预测掩码token和预测两个句子是不是连贯的。也就是后面的Mask LM 和NSP任务。文中训练了base 和 large两个版本。
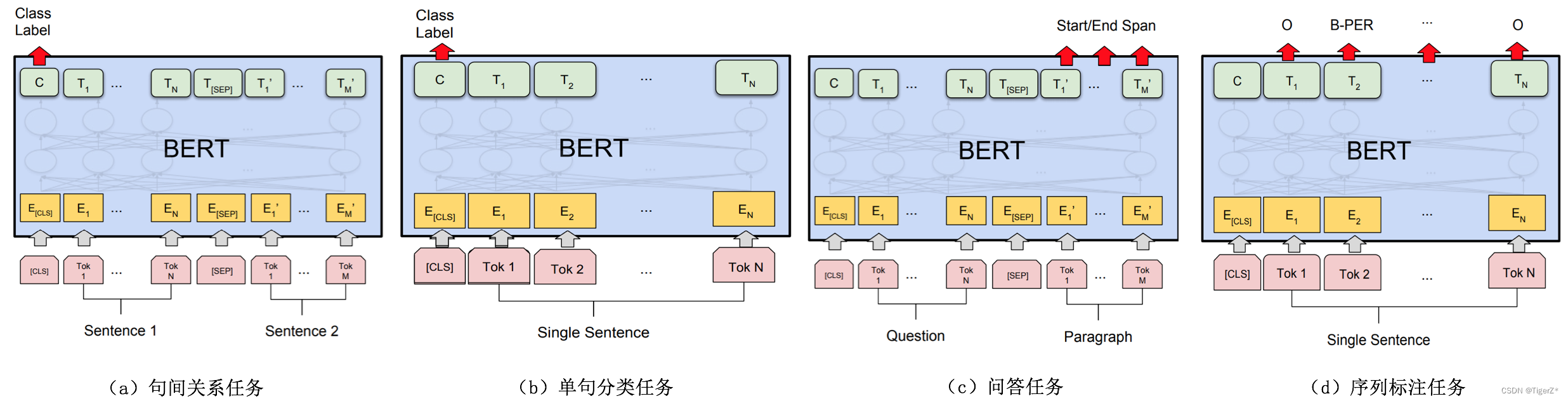
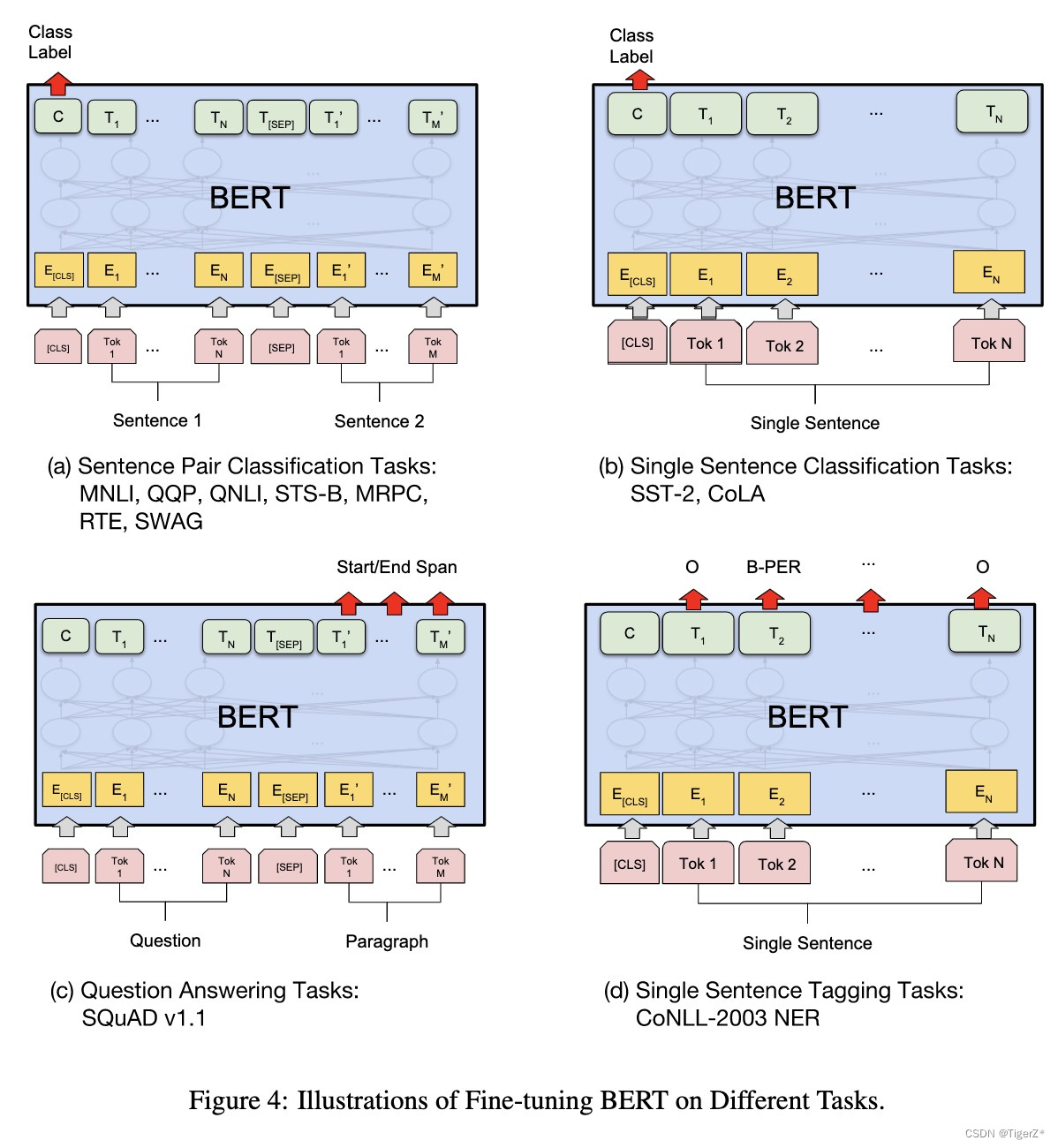
2)下游任务:主要分为四大类,两个句子的关系分类、单句分类(比如情感分类)、问答(不是生成模型,所以答案是提供的文本中的一个片段,预测起止点)、句子内次分类(比如实体识别)。
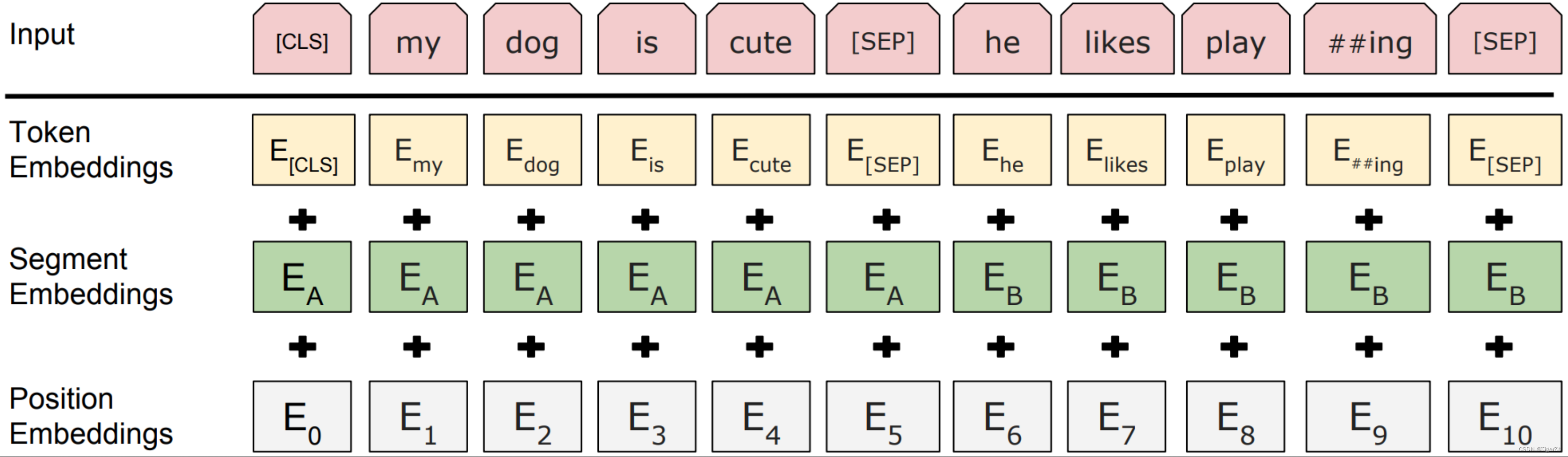
输入如下。针对不同的任务,BERT模型的输入可以是单句或者句对。对于每一个输入的Token,它的表征由其对应的词表征(Token Embedding)、段表征(Segment Embedding)和位置表征(Position Embedding)相加产生。其中BERT的分词是“Case-preserving WordPiece model”,它在分词的同时保留了原始文本的大小写信息。
预训练整体对应的网络结构如下:
不同的下游任务的模型结构如下图:
下游任务对应到数据集
2、模型亮点
双向注意力训练的解码器,并且有单词和句子两个任务。
PS
可惜现在GPT的decoder 一统天下了。
三、数据
1、数据标签
对于英文模型,使用了Wordpiece模型来产生Subword从而减小词表规模;对于中文模型,直接训练基于字的模型。 具体因为涉及到预训练和不同类型的下游任务,这里稍微有点复杂,一条一条梳理。
预训练目标:BERT预训练过程包含两个不同的预训练任务,分别是Masked Language Model和Next Sentence Prediction任务。
下游任务:分为句子分类、token分类。
1-1)Masked Language Model任务
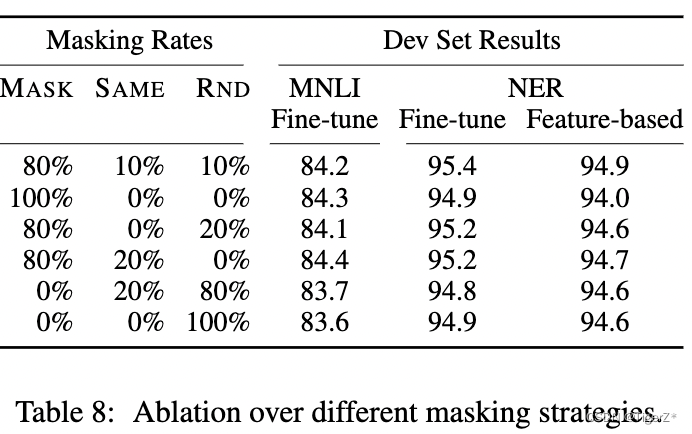
就是预测被mask掉的词,文章提出一种mask策略(这个过程发生在WordPiece tokenization之后,而且对所有token一视同仁,后面有对应的消融实验):在一个batch 内先随机选取15%的单词作为mask候选,然后对这15%单词进行二次抽样,其中80%需要被替换成[MASK]的词进行替换,10%的随机替换为其他词,10%保留原词。原因是:在微调时[MASK]总是不可见,会造成预训练和微调时的不一致。论文中的例子如下:

1-2)Next Sentence Prediction任务
模型输入需要附加一个起始Token,记为[CLS],对应最终的Hidden State(即Transformer的输出)可以用来表征整个句子,用于下游的分类任务。
模型能够处理句间关系。为区别两个句子,用一个特殊标记符[SEP]进行分隔,另外针对不同的句子,将学习到的Segment Embeddings 加到每个Token的Embedding上。对于单句输入,只有一种Segment Embedding;对于句对输入,会有两种Segment Embedding。
论文中的例子如下,构造方法是随机构造50%是成对的句子,50%不是成对的句子,并且也要保证整个句子长度小于512个token。和上面的mask策略是共同作用的。
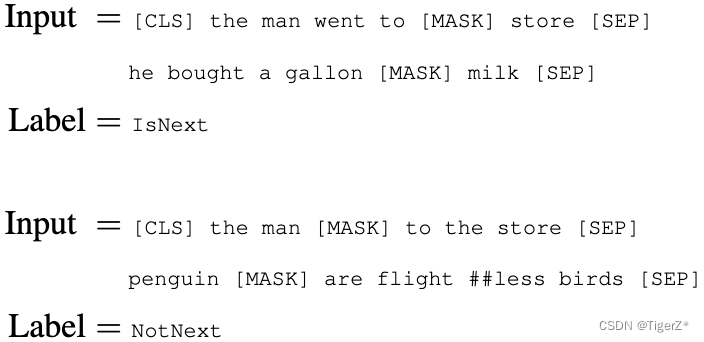
2-1)GLUE 句子分类下游任务
可以为单个句子或者句子对。
输入和预训练一样,有cls、sep token,没有Mask。
输出使用cls token对应的最后一个隐层的向量作为句子的整体表示,仅仅引入一个全连接层,映射到分类类别数,计算标准的softmax 分类损失。
2-2)SQuAD v1.1
其实就是给定问题,在指定段落里面找答案的起止点,不需要改写答案。这里确实有点绕,所以再重复贴一下模型图。这里输入如下图,比较好理解。输出增加了两个可学习的verctor(就是两个变量分别称为S、E),然后对每个输出单词做点乘,计算为起点的概率(终点同理):![]() 。然后起点到终点的整个段落的概率定义如下:
。然后起点到终点的整个段落的概率定义如下:![]() 。
。
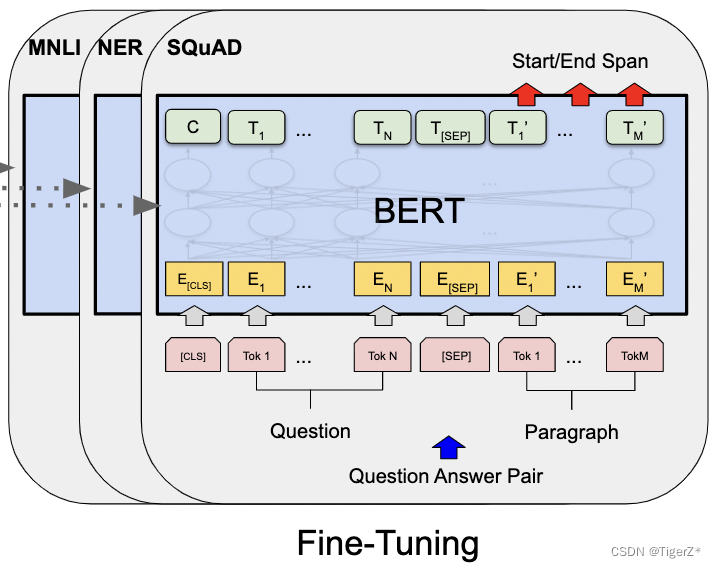
2-3)SQuAD v2.0
我们将没有答案的问题视为在 [CLS] 标记处具有开始和结束的答案跨度。预测的时候没有对应答案得分Snull =S·C + E·C,有对应的答案的得分最大值![]() ,然后当
,然后当![]() ,阈值t是在验证集使F1最大调节出来的。
,阈值t是在验证集使F1最大调节出来的。
2-4)SWAG
本身是多选,这里将问题分别匹配一个答案,构成N个文本对,然后对每个文本对单独像句子对分类任务一样,在cls token上训练分类器。
2、数据构成
预训练
为了和GPT作对比,数据等也尽可能相同:BERT使用BooksCorpus (800M words)、Wikipedia (2,500M words),其中GPT使用的仅仅为BooksCorpus (800M words)。
下游任务
MNLI:Multi-Genre Natural Language Inference,两个句子的蕴含分类任务。给定一对句子,目标是预测第二个句子是否是相对于第一个句子的蕴涵、矛盾或中性。
QQP:Quora Question Pairs,两个句子分类任务。目标是确定 Quora (果壳问答网站,类似知乎)上提出的两个问题在语义上是否等价。
QNLI:Question Natural Language Inference,标准的问答任务。被转换为二元分类任务,正例是(问题、句子)对,包含正确答案,负例是来自同一段落的(问题、句子),不包含答案。
SST-2:Stanford Sentiment Treebank,二元单句分类任务,包括从电影评论中提取的句子及其情感的注释。
CoLA:The Corpus of Linguistic Acceptability,二元单句分类任务,其目标是预测英语句子在语法上是否“可接受”。
STS-B:The Semantic Textual Similarity Benchmark,一组从新闻标题和其他来源中提取的句子对。他们用从 1 到 5 的分数进行注释,表示两个句子在语义含义方面的相似程度。
MRPC:Microsoft Research Paraphrase Corpus,从在线新闻源中自动提取的句子对组成,人工注释对中的句子在语义上是否等价。
WNLI Winograd NLI:小型自然语言推理数据集,GLUE 网页指出,该数据集的构建存在问题。
RTE:Recognizing Textual Entailment,类似于 MNLI 的二元蕴涵任务,但训练数据要少得多。
SQuAD v1.1:10w个众包问题/答案对的集合。给定一个来自维基百科的段落和对应的问题,任务是预测答案在文章中的跨度(也就是起止点)。
SQuAD v2.0:对比V1.1,还有可能对应的段落没有问题的答案。
SWAG:Situations With Adversarial Generations,包含 113k 个句子对,用于评估常识推理。
3、数据清洗
可能都是开源数据,并且为了保持和Open AI相同,文章并没有提到如何清洗这两个数据源。
四、策略
1、训练过程
预训练
单阶段训练,训练所有网络参数,两个任务的loss取平均。值得注意的一个预训练加速细节(原理是transformer的自注意力随着序列长度二次方增加运算量):使用序列长度为 128 训练90% 的Step,然后使用 512 序列长度训练其余10% 来学习位置嵌入。
训练超参数如下:
*bs = 256、sequence length = 512、Step = 100W,相当于:128,000 token/batch、训练了40个epoch。
*学习率为 1e-4 的 Adam,β1 = 0.9,β2 = 0.999,L2 权重衰减为 0.01,学习率在前 10,000 步预热,学习率的线性衰减。
*在所有层上使用 0.1 的 dropout 概率。
*激活函数和GPT相同为gelu。
*训练损失是平均掩码 LM 似然和平均下一句预测似然的总和。
*BERTBASE 的训练是在4 cloud Pod (总共 16 个 TPU 芯片),LARGE 的训练是在 16 个 Cloud TPU pod(总共 64 个 TPU 芯片)上进行的。均需要 4 天完成训练。
下游任务Finetune整体总结
如模型结构部分,应用与不同的下游任务(不同下游任务都略有区别,大的数据集,比如10W+样本的对超参数选择不敏感),超参数整体和预训练相同,但是batch size、学习率、训练epoch不同,如下:
*batch size 选择16 或32.
*Learning rate (Adam): 5e-5, 3e-5, 2e-5。
*epochs数: 2, 3, 4
下游任务Finetune-GLUE句子分类
主要在模型输出的增加一个分类层,对应输入的cls token。batch size 32 训练3 个epoch,学习率尝试5e-5, 4e-5, 3e-5, 2e-5并选择验证集效果最好的。
注意:这里发现BERT large版本训练不稳定,采取的策略是随机多训练几个版本,然后选择验证集上效果好的,这里的随机包含:数据随机shuffle和分类层随机初始化。
下游任务SQuAD v1.1句子分类
batch size 32 训练3 个epoch,学习率5e-5。
下游任务SQuAD v2.0句子分类
batch size 48 训练2 个epoch,学习率5e-5。
下游任务SWAG句子分类
batch size 16 训练3 个epoch,学习率2e-5。
2、推理过程
暂无
五、结果
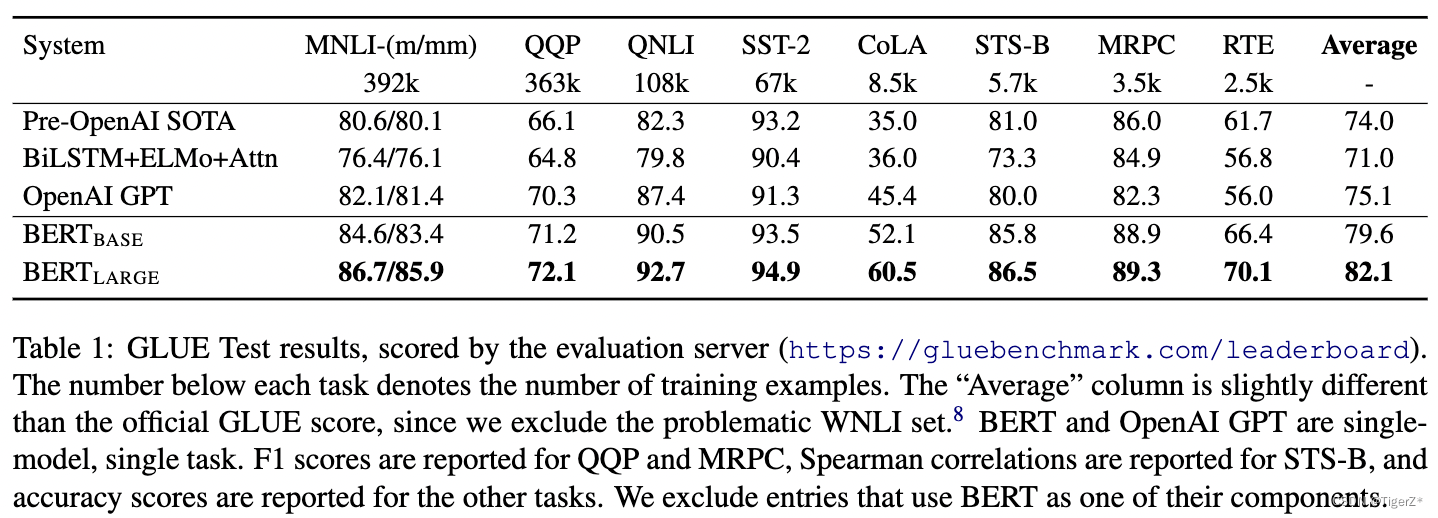
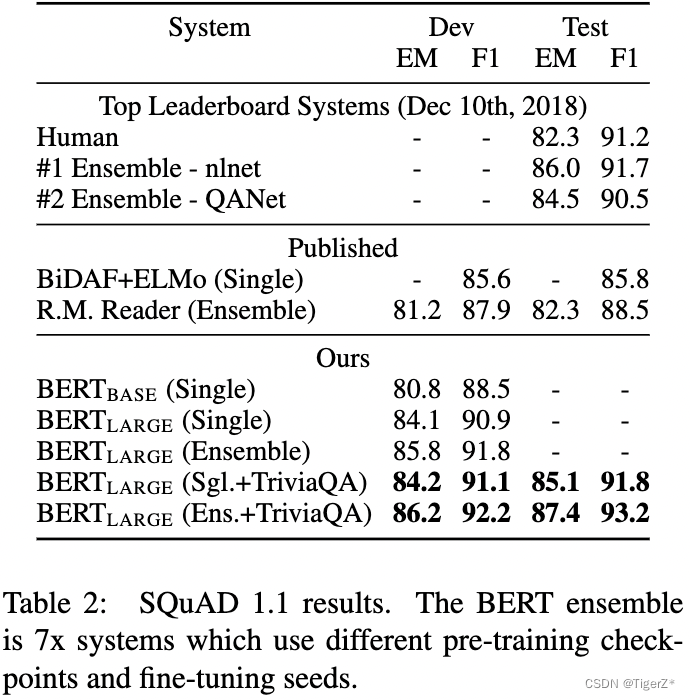
1、多维度对比。
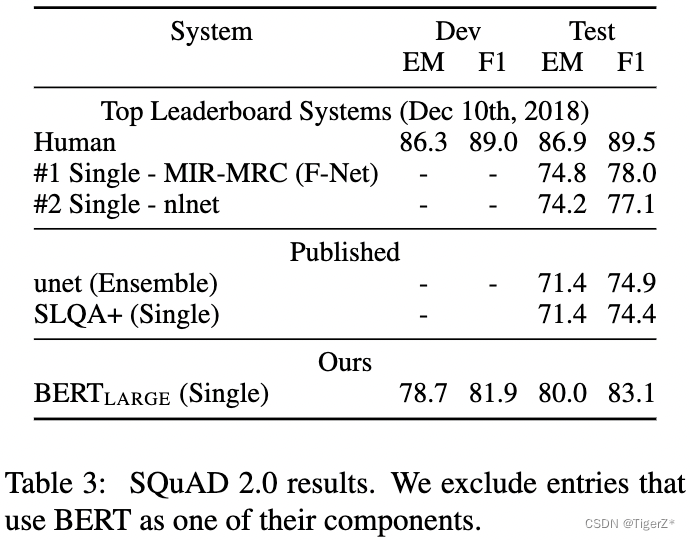
四个下游任务,分别见四个表。
GLUE:发现large版本结果都比base版本好(包含哪些训练数据很少的场景),并且好于Open AI。

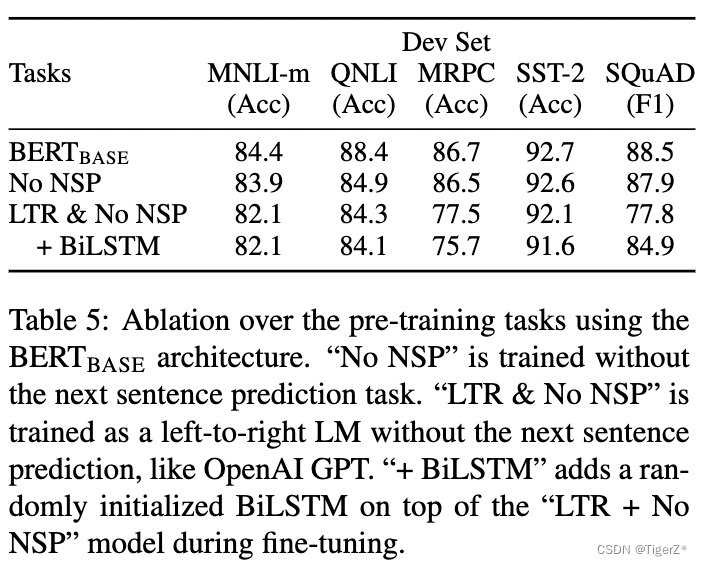
2、消融实验
训练任务
涉及:有无预测下一个句子任务(NSP)、MLM对比LTR任务(预测中间词和从左预测右面即GPT)。他的结果显示预测下一个句子能提升性能,MLM好于LTR。(PS:然而后面bert的改进去掉了NSP任务,GPT系列数据上来效果强悍。所以这些经验真的会随着数据和模型规模上来反而成为阻碍。)
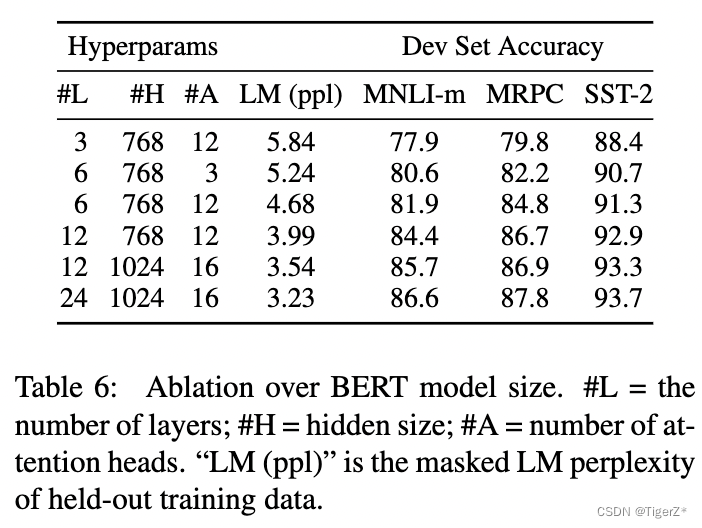
模型大小
除了模型的层数、隐层维度、head 头数外,其余训练超参一致。这里作者证明随着模型规模的提升,下游任务的性能也提升,即使下游任务数据很少也可以finetune(接一个分类头,并且bert的参数也更新),然后获得稳定提升(随着模型规模)。这里作者特别提到之前有人做实验,证明模型规模不能太大,不然反而性能会降低这里是通过特征的方式,没有finetune。
PS:这里感觉有点后面GPT系列对齐的苗头了。
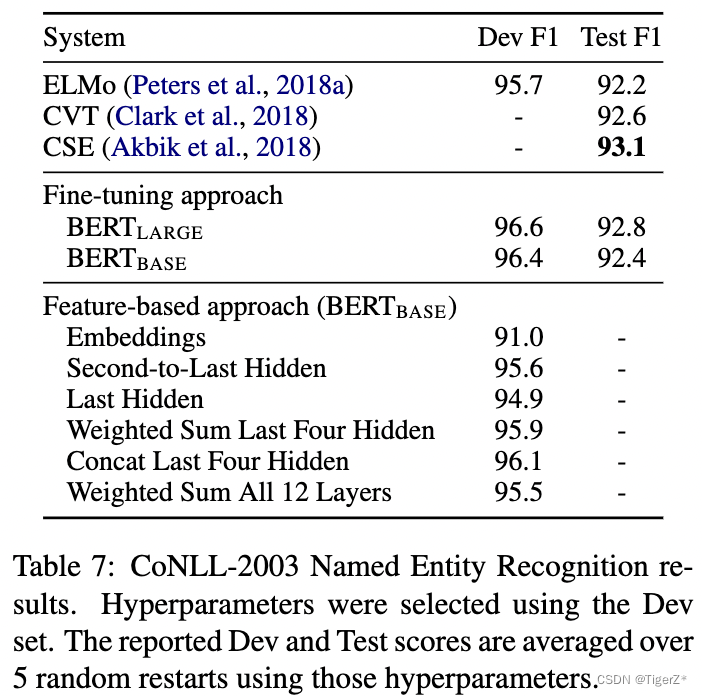
基于特征
这里和图像领域不太一样哈,对应CLIP里面的叫Liner prob策略,也就是冻结bert参数,然后对bert的输出再训练一个分类器。而该论文的finetune就是全部bert跟着分类器更新参数。对比结果如下,证明bert的特征也挺好(当然低于finetune)。
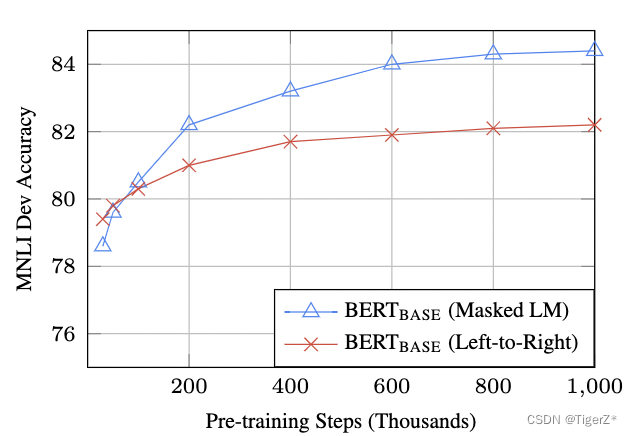
训练时长(Step数)
*与 500k 步相比,BERTBASE 在 1M 步上训练时在 MNLI 上实现了几乎 1.0% 的额外准确度。
*MLM 模型的收敛速度略慢于 LTR 模型。然而,就绝对准确性而言,MLM 模型几乎很快就开始优于 LTR 模型。
不同的mask策略
需要注意,对于基于特征的方法,将 BERT 的最后 4 层作为特征连接起来,这在第 5.3 节中被证明是最好的方法。其实差距不是特别大。
六、使用方法
见git和上面的下游任务模型结构介绍部分,对不同下游任务不同。
七、待解决
论文提到的缺点
由于每个Batch中只有15%的词会被预测,因此模型的收敛速度比起单向的语言模型会慢,训练花费的时间会更长。(作者认为从提升收益的角度来看,付出的代价是值得的。)
改进算法
并且很多原始认为很有用的tick已经不再使用,比如预测句子任务。BERT的主要创新在于它的双向训练结构,它能够在预训练阶段同时考虑上下文中的左侧和右侧信息。自从BERT发布以来,许多研究者和工程师都在尝试改进这个模型。以下是一些BERT改进的论文总结:
1、RoBERTa(A Robustly Optimized BERT Pretraining Approach)
发现:BERT可能由于其训练过程没有被充分优化而受到限制。
改进:更长时间的训练、更大的数据集、更大的batch size、不使用Next Sentence Prediction(NSP)任务。
结果:在多个基准测试上取得了比原始BERT更好的结果。
2、ALBERT(A Lite BERT for Self-supervised Learning of Language Representations)
发现:BERT模型非常庞大,需要大量的内存和计算资源。
改进:参数共享、降低模型大小的同时保持性能。
结果:减小了模型的内存占用,同时在某些任务上保持或超越了BERT的性能。
3、DistilBERT(Distilling the Knowledge in a Neural Network)
发现:BERT模型过于庞大,对于某些应用来说不够高效。
改进:利用知识蒸馏技术,将BERT的知识转移到更小的模型。
结果:模型大小减少了40%,速度提升了60%,同时保持了97%的BERT性能。
4、XLNet(Generalized Autoregressive Pretraining for Language Understanding)
发现:BERT的双向上下文理解能力强,但是受限于其掩蔽语言模型(MLM)的预训练方式。
改进:结合了自回归语言模型和BERT的优点,提出了置换语言模型(PLM)。
结果:在多项NLP任务上超越了BERT和GPT的性能。
5、ERNIE(Enhanced Representation through kNowledge Integration)
发现:BERT没有充分利用外部知识,如实体、短语和语义关系等。
改进:整合了外部知识,通过实体掩蔽和短语掩蔽来增强语言表示。
结果:在特定任务上,如情感分析和实体识别,性能得到了显著提升。
6、SpanBERT(SpanBERT: Improving Pre-training by Representing and Predicting Spans)
发现:BERT的单个词掩蔽可能不足以捕捉到更长的依赖关系。
改进:专注于跨度的预测而不是单个词的预测,以更好地表示和预测文本跨度。
结果:在句子级和跨度级任务上均显示出改进。
八、参考链接
Transformer 源码解读:Transformer源码详解(Pytorch版本) - 知乎
bert 源码解读:Bert源码详解(Pytorch版本) - 知乎