ES 和传统关系型数据库有很多区别, 比如传统数据中普遍都有一个叫“最大连接数”的设置。目的是使数据库系统工作在可控的负载下,避免出现负载过高,资源耗尽,谁也无法登录的局面。
那 ES 在这方面有类似参数吗?答案是没有,这也是为何 ES 会被流量打爆的原因之一。
针对大并发访问 ES 服务,造成 ES 节点 OOM,服务中断的情况,极限科技旗下的 INFINI Gateway 产品(以下简称 “极限网关”)可从两个方面入手,保障 ES 服务的可用性。
- 限制最大并发访问连接数。
- 限制非重要索引的请求速度,保障重要业务索引的访问速度。
下面我们来详细聊聊。
架构图
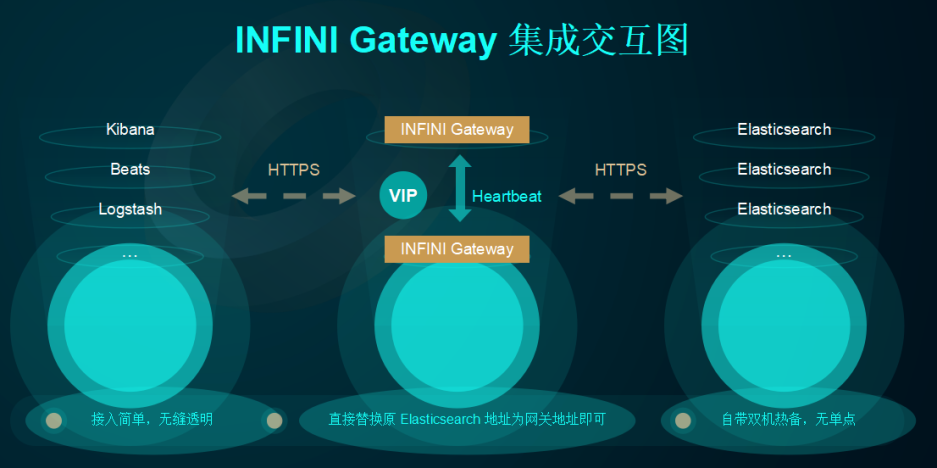
所有访问 ES 的请求都发给网关,可部署多个网关。
限制最大连接数
在网关配置文件中,默认有最大并发连接数限制,默认最大 10000。
entry:- name: my_es_entryenabled: truerouter: my_routermax_concurrency: 10000network:binding: $[[env.GW_BINDING]]# See `gateway.disable_reuse_port_by_default` for more information.reuse_port: true
使用压测程序测试,看看到达 10000 个连接后,能否限制新的连接。

超过的连接请求,被丢弃。更多信息参考官方文档。
限制索引写入速度
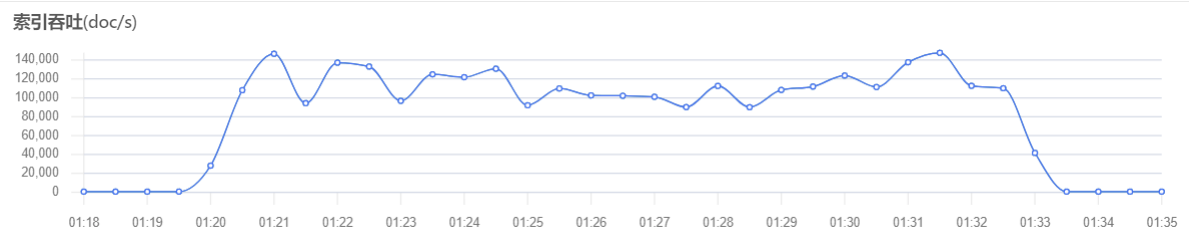
我们先看看不做限制的时候,测试环境的写入速度,在 9w - 15w docs/s 之间波动。虽然峰值很高,但不稳定。
接下来,我们通过网关把写入速度控制在最大 1w docs/s 。
对网关的配置文件 gateway.yml ,做以下修改。
env: # env 下添加THROTTLE_BULK_INDEXING_MAX_BYTES: 40485760 #40MB/sTHROTTLE_BULK_INDEXING_MAX_REQUESTS: 10000 #10k docs/sTHROTTLE_BULK_INDEXING_ACTION: retry #retry,dropTHROTTLE_BULK_INDEXING_MAX_RETRY_TIMES: 10 #1000THROTTLE_BULK_INDEXING_RETRY_DELAY_IN_MS: 100 #10router: # route 部分修改 flow- name: my_routerdefault_flow: default_flowtracing_flow: logging_flowrules:- method:- "*"pattern:- "/_bulk"- "/{any_index}/_bulk"flow:- write_flowflow: #flow 部分增加下面两段- name: write_flowfilter:- flow:flows:- bulking_indexing_limit- elasticsearch:elasticsearch: prodmax_connection_per_node: 1000- name: bulking_indexing_limitfilter:- bulk_request_throttle:indices:"test-index":max_bytes: $[[env.THROTTLE_BULK_INDEXING_MAX_BYTES]]max_requests: $[[env.THROTTLE_BULK_INDEXING_MAX_REQUESTS]]action: $[[env.THROTTLE_BULK_INDEXING_ACTION]]retry_delay_in_ms: $[[env.THROTTLE_BULK_INDEXING_RETRY_DELAY_IN_MS]]max_retry_times: $[[env.THROTTLE_BULK_INDEXING_MAX_RETRY_TIMES]]message: "bulk writing too fast" #触发限流告警message自定义log_warn_message: true
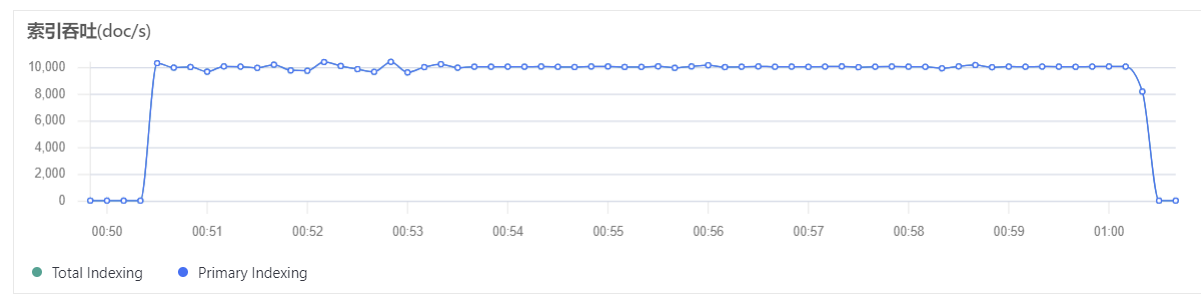
再次压测,test-index 索引写入速度被限制在了 1w docs/s 。
限制多个索引写入速度
上面的配置是针对 test-index 索引的写入速度控制。如果想添加其他的索引,新增一段配置即可。
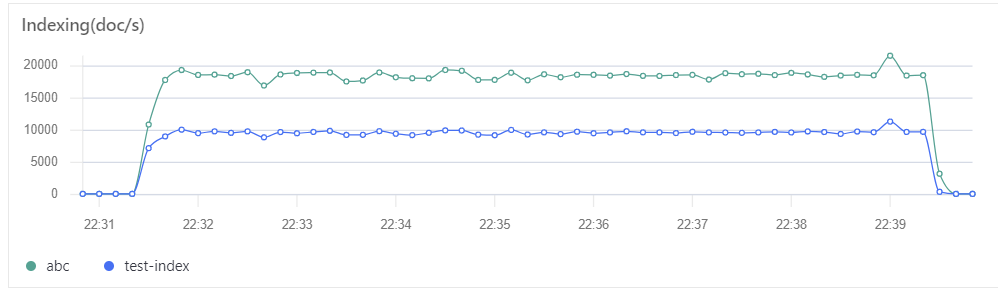
比如,我允许 abc 索引写入达到 2w docs/s,test-index 索引最多不超过 1w docs/s ,可配置如下。
- name: bulking_indexing_limitfilter:- bulk_request_throttle:indices:"abc":max_requests: 20000action: dropmessage: "abc doc写入超阈值" #触发限流告警message自定义log_warn_message: true"test-index":max_bytes: $[[env.THROTTLE_BULK_INDEXING_MAX_BYTES]]max_requests: $[[env.THROTTLE_BULK_INDEXING_MAX_REQUESTS]]action: $[[env.THROTTLE_BULK_INDEXING_ACTION]]retry_delay_in_ms: $[[env.THROTTLE_BULK_INDEXING_RETRY_DELAY_IN_MS]]max_retry_times: $[[env.THROTTLE_BULK_INDEXING_MAX_RETRY_TIMES]]message: "bulk writing too fast" #触发限流告警message自定义log_warn_message: true
限速效果如下
更多信息参考官方文档。
限制读请求速度
我们先看看不做限制的时候,测试环境的读取速度,7w qps 。
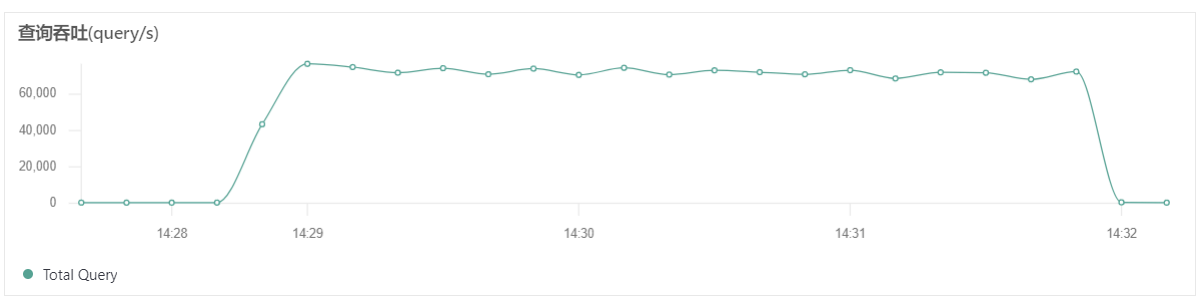
接下来我们通过网关把读取速度控制在最大 1w qps 。
继续对网关的配置文件 gateway.yml 做以下修改。
- name: default_flowfilter:- request_path_limiter:message: "Hey, You just reached our request limit!" rules:- pattern: "/(?P<index_name>abc)/_search"max_qps: 10000group: index_name- elasticsearch:elasticsearch: prodmax_connection_per_node: 1000
再次进行测试,读取速度被限制在了 1w qps 。

限制多个索引读取速度
上面的配置是针对 abc 索引的写入速度控制。如果想添加其他的索引,新增一段配置即可。
比如,我允许 abc 索引读取达到 1w qps,test-index 索引最多不超过 2w qps ,可配置如下。
- name: default_flowfilter:- request_path_limiter:message: "Hey, You just reached our request limit!"rules:- pattern: "/(?P<index_name>abc)/_search"max_qps: 10000group: index_name- pattern: "/(?P<index_name>test-index)/_search"max_qps: 20000group: index_name- elasticsearch:elasticsearch: prodmax_connection_per_node: 1000
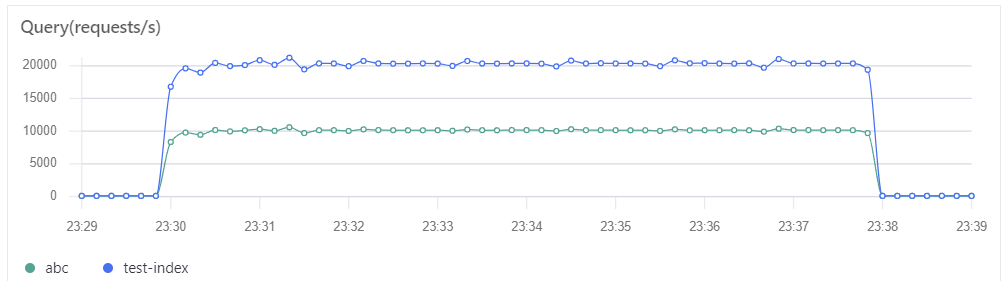
更多信息参考官方文档。
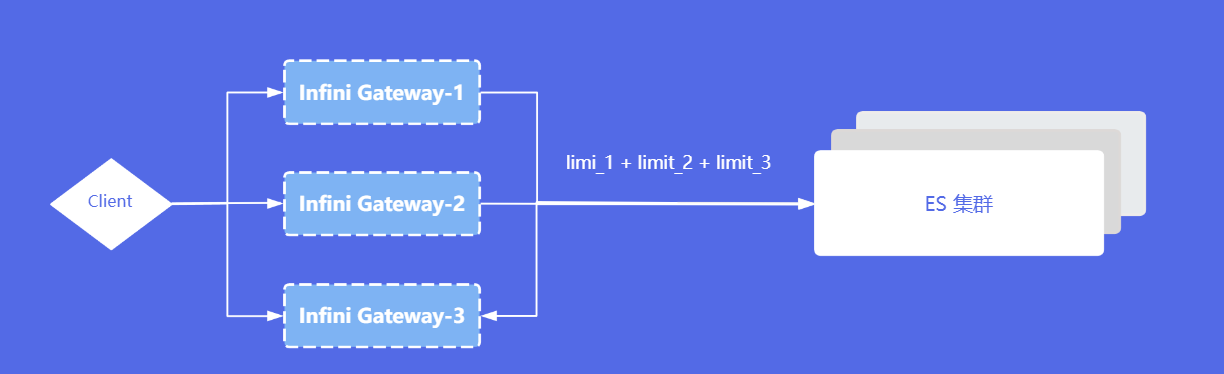
多个网关限速
限速是每个网关自身的控制,如果有多个网关,那么后端 ES 集群收到的请求数等于多个网关限速的总和。
本次介绍就到这里了。相信大家在使用 ES 的过程中也遇到过各种各样的问题。欢迎大家来我们这个平台分享自己的问题、解决方案等。如有任何问题,请随时联系我,期待与您交流!