一、前言
在过去的几十年里,一些微架构设计技术促进了处理器速度的提高。其中一个进步是推测执行(Speculative execution),它被广泛用于提高性能,猜测CPU未来可能的执行方向,并提前执行这些路径上的指令。比如说,程序的控制流依赖于位于外部物理内存中的未缓存值,由于访问内存比访问CPU寄存器慢得多,因此通过需要数百个时钟周期才能知道该值。CPU没有进入IDLE来浪费这些周期,而是尝试猜测控制流的方向,保存其寄存器状态的检查点,并继续在猜测的路径上推测地执行程序。当值最终从内存返回时,CPU检查其初始猜测的正确性。如果猜测错误,CPU通过将寄存器状态恢复到存储的检查点来丢弃错误的推测执行,从而导致性能与处于IDLE差不多。但是,如果猜测是正确的,则提交推测的执行结果,从而产生显著的性能增益,因为在延迟期间完成了有用的工作。Spectre攻击通过欺骗处理器,使其推测性地执行在正确的程序执行下不应该执行的具有可测量副作用的操作,并通过侧通道(Side channel)将受害者的机密信息泄露出去。

二、背景知识
2.1投机执行(Speculative execution)
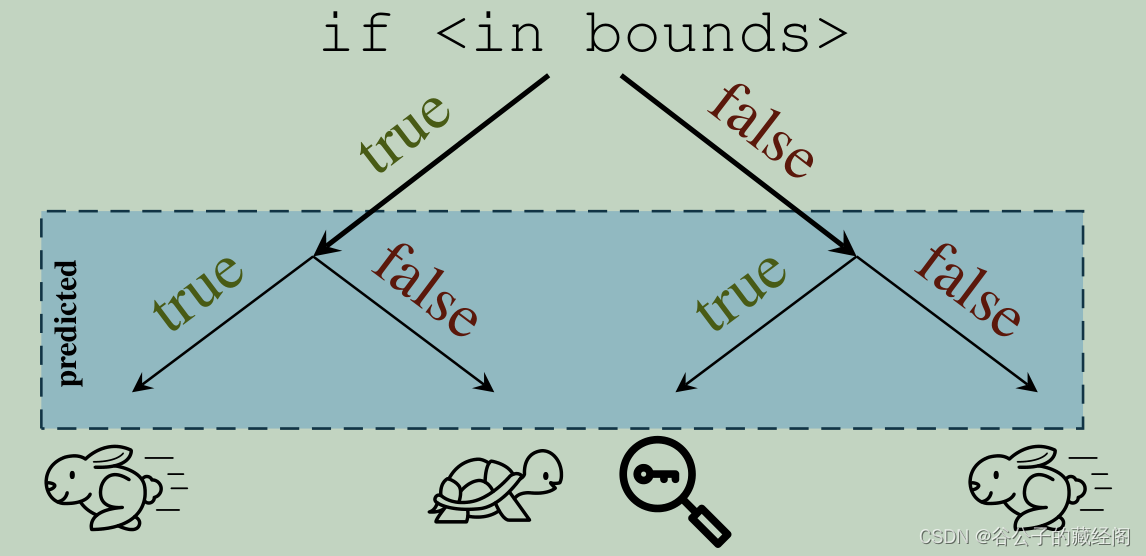
通常,处理器不知道程序的未来指令流。例如,当乱序执行到达一个条件分支指令时,该指令的方向取决于之前尚未完成执行的指令。在这种情况下,处理器可以保存其当前的寄存器状态,对程序将执行的路径做出预测,并投机地沿着预测路径执行指令。如果预测被证明是正确的,则保存执行的结果,从而在等待期间产生优于空闲的性能优势。否则,当处理器确定它遵循错误的路径时,它会通过恢复其寄存器状态并沿着正确的路径执行,从而放弃其投机执行的内容。现代CPU的投机执行可以提前运行几百条指令,该限制通常由CPU中重排序缓冲区(Reoder buffer)的大小决定的。下图为在条件分支预测的正确结果已知之前,分支预测器继续处理最有可能的分支目标,如果正确预测了结果,将导致整体执行速度加快。但是,如果边界检查被错误地预测为真,攻击者可能会在某些情况下泄露机密信息。
2.2分支预测 (Branch Prediction)
在投机执行期间,处理器对分支指令的可能结果进行猜测。更高的预测准率可以增加投机指令成功的提交,进而提高性能。
2.3微架构侧信道攻击 (Microarchitecture Side-Channel Attacks)
当多个程序在同一硬件上并发或分时执行时,由一个程序的行为引起的微体系结构状态的变化可能会影响其他程序。这反过来又可能导致意想不到的信息从一个程序泄漏到另一个程序。
Flush+Reload技术及其变体Evict+Reload技术,这两个技术中,攻击者首先从与受害者共享的缓存中删除缓存行。受害者执行一段时间后,攻击者探测在被驱逐的缓存行对应的地址执行内存读取所需的时间。如果受害者访问了被监控的缓存线,则数据将在缓存中,并且访问将很快。否则,如果受害者没有访问该行,则读取将很慢。因此,通过测量访问时间,攻击者可以了解受害者是否在驱逐和探测步骤之间访问了被监视的缓存行。
这两种技术之间的主要区别是用于从缓存中清除被监视的缓存行的机制。在Flush+Reload技术中,攻击者使用专用的机器指令,例如x86的clflush来驱逐行。使用Evict+Reload,通过在存储行的缓存集中强制争用来实现驱逐,例如,通过访问加载到缓存中的其他内存位置,并且(由于缓存的大小有限)导致处理器丢弃(Evict)随后探测的行。
三、Spectre攻击示例
考虑下面的代码示例:
if (x < array1_size)y = array2[array1[x] * 4096];在上面的示例中,假设变量x包含攻击者控制的数据。为了确保对array1的内存访问的有效性,上面代码包含一个if语句,其目的是验证x的值是否在合法范围内。但按照下面方式,攻击者可以绕过这个if语句,从而从进程的地址空间读取潜在的机密数据。
首先,在初始的错误训练阶段,攻击者用x的有效输入调用上述代码,从而训练CPU分支预测器期望if为真。接下来,攻击者使用在array1大小边界之外的值为x,CPU没有等待分支结果的确定,而是猜测边界检查将为真,并且已经推测地执行指令,使用恶意x计算array2[array1[x]*4096]。投机执行逻辑将x加上array1基址,并从内存子系统读取数据,并快速返回秘密字节k的值,之后使用k来计算array2[k * 4096]的地址。然后它继续发送一个请求从内存读取这个地址的数据(会出现缓存缺失)。虽然从array2中读取的数据已经在执行中,但当边界检查的结果最终确定时,CPU发现它预测错了并将所做的任何更改恢复到之前的微架构状态。然而,从array2的读取(取决于k)对缓存所做的更改不会被还原。因此攻击者测量array2中的哪个位置被加载到缓存,例如通过Flush_Reload方式,最终从速度最快的位置就可以推测出k的值了。
Meltdown是利用乱序执行来泄漏内核内存。Meltdown在两个主要方面不同于Spectre,首先,Meltdown不使用分支预测,它依赖于这样的观察:当一条指令引起异常时,随后的指令在被终止之前会被乱序执行。其次,Meltdown利用了Intel和一些ARM处理器特有的漏洞,该漏洞允许某些推测执行的指令绕过内存保护。结合这些问题,Meltdown可以从用户空间访问内核内存。这种访问会导致一个异常,但是在发出异常之前,访问之后的指令会通过一个缓存隐蔽通道(Cache covert channel)泄漏被访问内存的内容。
相比之下,Spectre攻击针对的处理器范围更广,包括大多数AMD和ARM处理器。此外,KAISER已被广泛应用于缓解Meltdown攻击,但它并不能防范Spectre。
四、解决方案
1.防止投机执行。Spectre攻击需要投机执行,确保指令只在确定控制流的情况下执行,可以防止投机执行,从而防止Spectre攻击,但这种方式会导致处理器性能显著下降。
2.防止访问机密数据。例如谷歌Chrome浏览器使用的一种方法是在单独的进程中执行每个网站。因为Spectre攻击只利用受害者的权限,所以像我们使用JavaScript执行的攻击将无法访问分配给其它网站的进程的数据。
3.防止数据进入隐蔽通道。未来的处理器可能会跟踪数据是否作为投机操作的结果被获取。如果是,则防止在可能泄漏数据的后续操作中使用该数据。不过,当前的处理器通常不具备这种能力。
4.限制从隐蔽通道提取数据。例如为了缓解基于JavaScript的攻击,主要浏览器提供商进一步降低了JavaScript计时器的分辨率,可能会增加抖动。不过当前处理器缺乏完全消除隐蔽信号所需的机制。因此,虽然这种方法可能会降低攻击性能,但并不能保证不可能发生攻击。
五、结语
支持软件安全技术的一个基本假设是处理器将忠实地执行程序指令,包括其安全检查。Spectre利用投机执行违反这一假设的事实,不需要任何软件漏洞,并且允许攻击者读取私有内存获得数据。软件安全从根本上依赖于硬件和软件开发人员对CPU实现允许(和不允许)从计算中暴露哪些信息有一个清晰的共同理解。上述的对策也只是权宜之计,因为任何特定的代码构造在当今的处理器上是否安全,通常需要有正式的硬件架构保证,所以长期的解决方案需要从根本上改变指令集架构。