最基础也是最好理解的大模型训练并行手段就是数据并行。
数据并行的发展史实际上目前看也经历了2个阶段:
-
1. DP Data Parallel
-
2. DDP Distributed Data Parallel
-
这两者特别容易被搞混,下面我们来看一下这两者的区别。
DP是在Pytorch中最早引入的分布式并行手段。
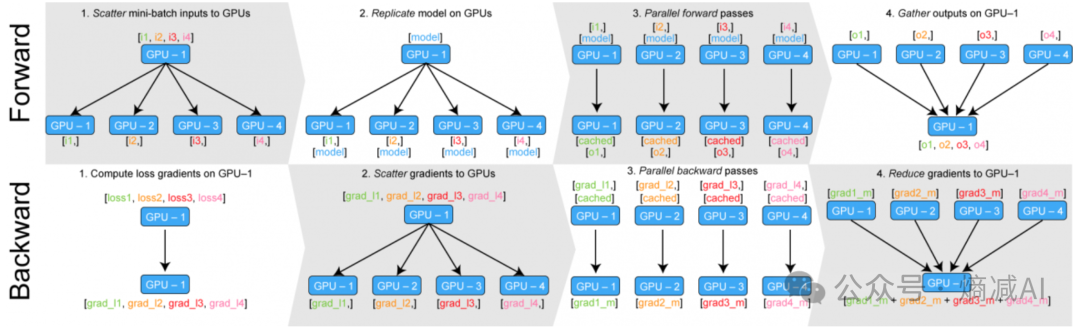
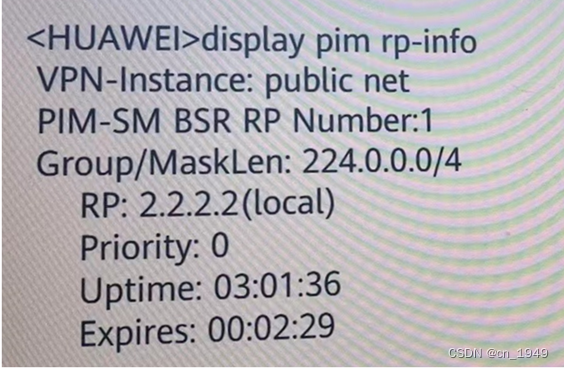
DP的通信和运行方式
DP是线程通信,只用于单机内部的多块GPU之间的通信,不会跨机器节点进行通信。
-
如图所示,DP从流程上看,是将整个minibatch的数据加载到主线上,然后再将更小批次的sub-minibatches的数据分散到整个机器的各块GPU中进行计算。
-
一般来讲DP的主GPU为GPU1,它负责持有模型,并且copy到其他的模型里,而且训练的mini-batch也是先给到GPU1,然后再通过Scatter的通信,将minibatch进一步打散成sub-minibatches,然后不同的ub-minibatches给到不同的GPU来进行训练处理。
-
在前向计算时,每个GPU自己计算自己得这一部分数据,然后GPU1通过gather来手机所有的输出,再进行统一的损失计算。
-
把损失在 GPU 之间 scatter,在各个GPU之上运行后