Redis是做什么的?
- Redis是一个开源,内存存储的数据结构服务器,可用作数据库,高速缓存和消息队列。
- Redis将数据储存在内存当中
内存的特点
- 易失性(在断电之后数据就没有了)
- 进行读取数据等IO操作的速度要比存在硬盘中的数据要更快
- 缺点是内存的价格更高
正因为redis将数据存储在内存当中,又因为内存的易失性所以像订单信息等需要持久化存储的数据就不适合存放在redis当中。
Redis的适用场景
- 在大型的秒杀库存扣减,app首页流量高峰,很容易将传统的关系型数据库(mysql,oracle等)给压垮。(当系统有系统瓶颈的时候,比如说表里面有2000万条数据(数据量非常大),并且表的访问量非常高的时候。redis的引入是为了减轻数据库的压力,防止大数据量的查询将mysql压垮。)
-
很多没必要持久化的数据,比如说短信验证码,点赞数等。
-
分布式锁。
-
分布式缓存(session共享)。
为什么点赞要用redis去实现,而不是用mysql?
- 点赞属于频率高的操作,需要频繁的对点赞数进行读取和更改操作。也就意味着会有许多用户同时对点赞数进行访问和更改。对于低于千万级的数据量,我们可以用mysql的分表和cache去解决点赞问题。但是对于千万级以上的数据量,会对mysql数据库造成很大的压力。
- 在mysql不进行加锁处理的情况下,如果有很多的线程对点赞数进行访问和修改,很可能线程一刚获取到了点赞数10,但是线程二在线程一读取之后立刻对点赞数进行了加操作,变成11。但是线程一并不知道点赞数已经发生了变化。在进行+1后将点赞数更新回去。这样就造成了原本应该被更新为12的点赞数仍为11,造成了数据的错误。虽然mysql中读操作是一个原子操作,写操作也是一个原子操作。但是读后写入并不是一个原子操作。所以就导致了这样的错误。redis中虽然没有事务,但是redis中的所有操作都是线程安全的,这样也就保证了对点赞数的每次操作,数据都是正确的。
Redis是数据库,mysql也是数据库,什么时候用redis,什么时候用mysql?
- 我们引入redis做缓存的目的是为了减缓mysql数据库的压力。所以在mysql数据库有压力的情景下我们使用redis,也就是在大数据量和访问频繁的情况下去使用redis。
- 而缓存如何去规划要取决于我们的业务本身。业务=数据结构+算法,根据业务来选取适合业务场景的数据结构,来将数据存放到redis,作缓存。
Redis和mysql的索引的底层区别
mysql索引相当于字典的目录,通过增加索引可以很快的提高MySQL的查询性能。mysql的索引也是存在内存里的,但是和redis也有区别。比如说有一个主键索引,相当于mysql将所有的id都以B+树的数据结构存储到内存当中,当我们根据id想要去查询一条数据时,有了索引的存在我们不用全表扫描一页一页的去查,而是根据索引去查。但是redis比加了索引的mysql还要快,因为redis中的数据以键值对的形式存储,和java中的map同理。map的时间复杂度为O(1),而B+树的时间复杂度要比O(1)要高。
数据库可视化软件
Redis DeskTopManager
redis存储的数据类型
redis的存储是以key-value的键值对的形式存储的,其中key都是String类型,value常见的就是以下的5种:String,Hash,List,Set,SortedSet。
String
字符串类型,可以包含任何数据,最大可以是512MB,内部的实现结构和ArrayList类似,采用内分配冗余的形式,来减少内存的频繁分配(降低CPU压力)
常用语句
set name zhangsan --存放字符串键值对
mset name zhangsan age 18 --批量存放键值对
SETNX name zhangsan --如果不存在key为name,那么就设置value(分布式锁的原理)
get name -- 获取key
mget name age --批量获取key
DEL key -- 删除key
expire key 60 --设置过期时间,单位为秒
INCR key -- 将key中存储的数字加1
DECR key -- 将key中存储的数字减1
INCRBY key 2 --将key中存储的值都加上2
DECRBY key 2 --将key中存储的值都减去2ps:尽量避免同时操作大批量的key,比如给所有的key设置过期时间,因为redis是单线程的,如果操作耗费太多时间,会造成redis的假死(暂时不对外提供服务)。
使用场景
1,不需要持久化的数据或者频繁更新的数据,比如验证码,点赞数
2,对象缓存。可以通过序列化工具类,来缓存java对象,比如将某个对象序列化为json,需要用的时候再取出来,反序列化。常见的使用方式有mybatis二级缓存,接口级别缓存等等。
3,使用setnx来实现分布式锁,(使用分布式锁时一定要设置过期时间,防止不能释放锁,造成死锁)
4,可以用incr,decr来实现点赞数
5.分布式全局id:在一个大型的系统下,如果涉及到分库分表后,mysql 的自增id,肯定满足不了需要,如果用户量不大,可以每次从redis 这里通过自增获取id,但是如果用户量大,每次都拿肯定会给redis造成压力,可以一次取1000个,放本地缓存里,等用完了再去取。
Hash
是一个key-value的键值对,和java里的hashMap相似,当数据量较小是采用的是ziphash(默认),当数据量较大时采用hashtable。至于什么转换可以在配置文件进行配置。
常用语句
hset hash name zhangsan --设置值,
hget hash name -- 获取值
hmset hash name zhangsan age 18 --批量设置
hmget hash name age --批量获取
hgetall hash 获取key的所有值
hkeys hash 获取hashmap中所有的key
hvals hash 获取hashmap中所有的value使用场景
1,可以用于存储系统中对象的数据。
2,也可以用于做缓存,来解决数据一致性的问题(不推荐)。
List
redis的list为quickList(快速链表)即多个ziplist(压缩链表)组合起来的。如图所示:

ziplist;当数组容量较小的时候,会开辟一个连续的内存空间,只有当数组容量过多的时候,才会改为quickList,这样做的好处就是,如果采用普通的链表,当我们节点只存int类型的数据,还需要开辟两个指针,连接节点的上一个元素和下一个元素,会比较浪费空间。所以采用了quickList的方式,既能满足快速插入删除性能,又不会出现太大的空间浪费。
这么做也有缺点,就是当我们的list要变动时,肯定会涉及到内存重新分配和数据拷贝,这个是很影响性能的,list越大,修改元素的代价越大,所以一般我们不会存储过多元素。
redis的list是按插入顺序排序的,可以添加的一个节点到链表的头部(头插)或者尾部(尾插),是一个双向链表,对两端的操作性能会比较高,对中间节点的操作性能相对来说较差(因为得通过指针对遍历对应的节点)。
常用语句
rpush myList valu5e1 --向 list 的头部(右边)添加元素
rpush myList value2 value3 --向list的头部(最右边)添加多个元素
lpop myList # 将 list的尾部(最左边)元素取出
rpop myList2 value1 --尾插使用场景
可以实现栈和队列,需要注意的是,push和pop的操作是原子性的,所以操作redis的时候,直接用就行了,不要把list读出来,通过java修改,再放回去,这样不能保证数据一致性。(先读先写或先读后写)
实现队列
rpush queue001 q1
rpush queue001 q2
rpush queue001 q3
lpop queue001
lpop queue001
lpop queue001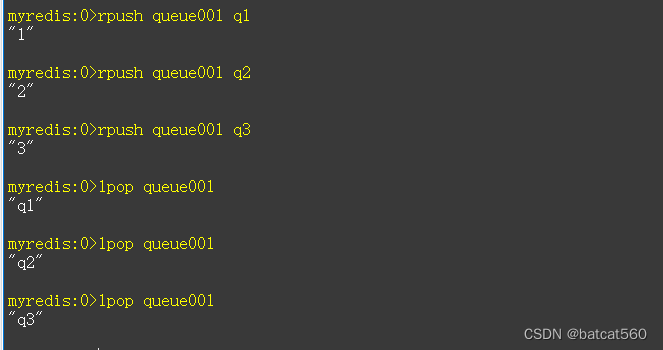
实现栈
rpush stack001 t1
rpush stack001 t2
rpush stack001 t3
rpop stack001
rpop stack001
rpop stack001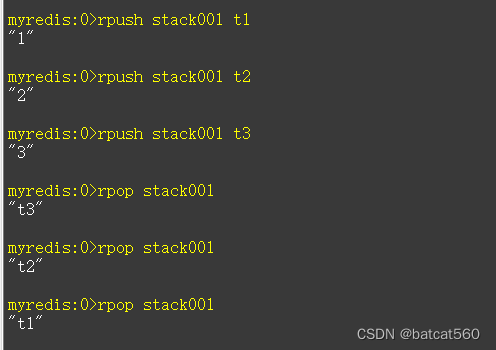
Set
redis的set和list相似,只不过可以自动去重。(java的set也可以自动去重)。
当你需要存储一个没有重复数据的列表时就可以选择set,同时set也可以判断某个数据在不在集合里面。
set的底层结构是一个value为null的哈希表,也就意味着他的时间复杂度为O(1),也就意味着即使数据再多,查找的时间也是一样的。
使用场景
可以用来计算多个数据源的交集或并集
SortedSet
和set很相似,sortedSet是一个有序不重复的列表。SortedSet里面的每个节点都关联了一个权重,用来排序。(集合里的每个节点是唯一的,但是评分却可以是相同的),利用这个特性我们可以利用redis来实现排行榜。也可以很快速的获取到一个区间内的节点。
SortedSet的底层是hash和跳表(一个很典型的数据机构,牺牲空间来换取时间)。hash的作用是存储每个节点和权重,跳表的作用是用来快速获取一个区间里的节点。