目录
前言
1、存储 Bean 对象
1.1、前置工作:配置扫描路径(重要)
1.2、简单的将 bean 存储到容器
1.2.1 使用 5 大类注解实现将 bean 存储到 容器
@Controller 注解
思考一个问题
问题二:五大类注解之间有什么关系?
问题三:关于 bean id 的命名,为什么是小驼峰结构?
1.2.2 使用 方法注解 @Bean 将 bean更简单的存入容器。
2、获取 Bean 对象(对象装配)
2.1 属性注入
2.1.1 @Autowired 注解 (Spring)
2.1.2 @Resource 注解 (JDK)
2.1.3 @Autowired 搭配 @Qualifier 注解
2.2 构造方法注入
2.3 Setter 注入
拓展1:经典面试题 -> 属性注入 ,构造方法注入 和 Setter 注入 之间,有什么区别?
拓展2:@Resource VS @Autowired 的区别
总结
前言
经过前⾯的 Spring 创建 和 使⽤的博文学习,我们已经可以实现基本的 Spring 读取和存储对象的操作了。
但在操作的过程中我们发现读取和存储对象并没有想象中的那么“简单”,所以接下来我们要学习更加简单的操作 Bean 对象的⽅法。
在 Spring 中想要更简单的存储和读取对象的核⼼是使⽤注解,也就是我们接下来要学习 Spring 中的相关注解,来存储和读取 Bean 对象。
需要注意的是:
Spring 中的 注解是通用的。
即:在 Spring Boot 和 Spring MVC 中,使用 Spring 的注解。
它们 是能够完全识别并使用的。
也就是说:接下来,才是重点。
这些注解,将会是我们以后在工作中,在Spring系列的项目中,最常使用的知识!!!
这些注解的功能,必须掌握!!!
1、存储 Bean 对象
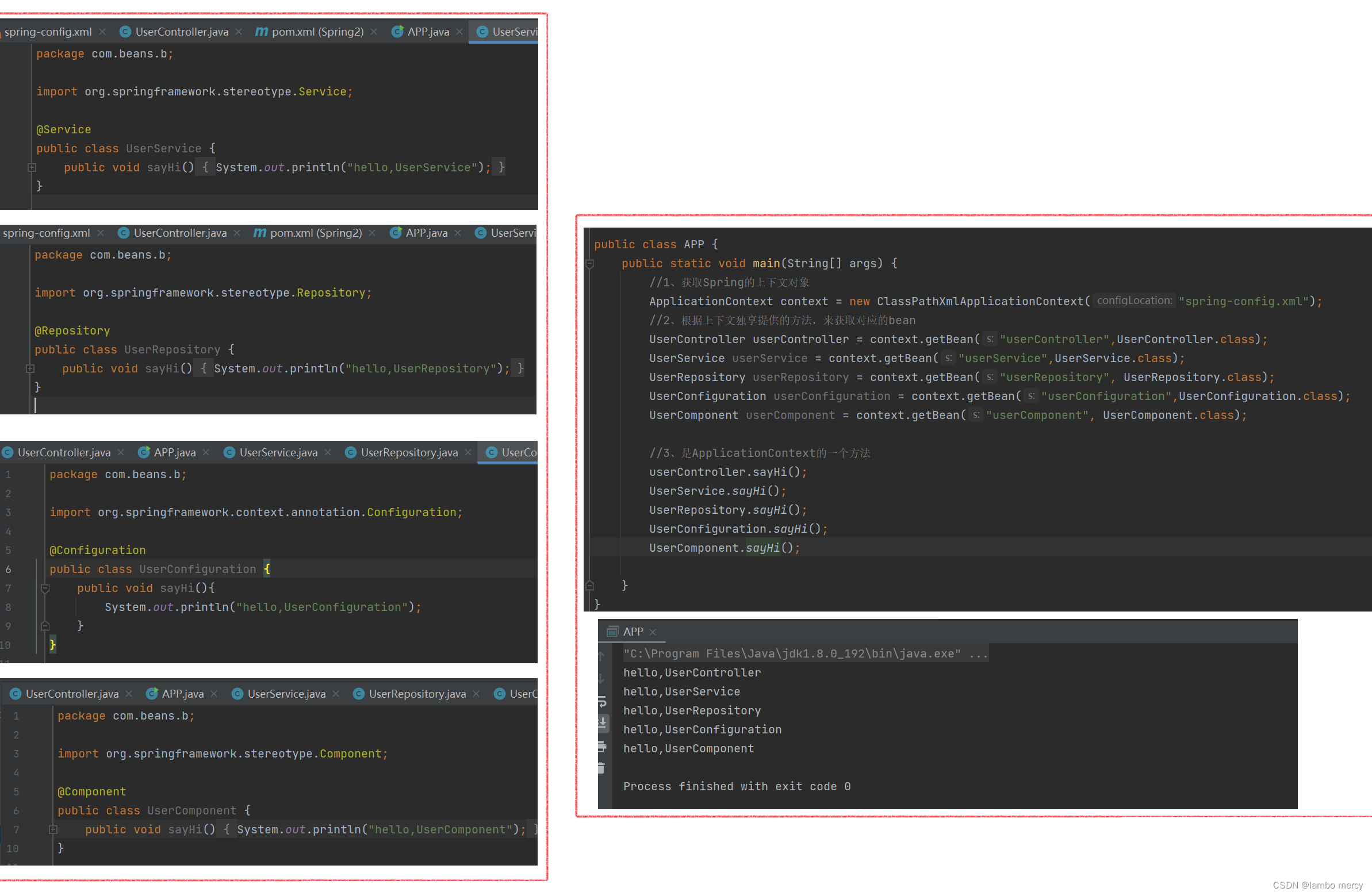
之前我们存储 Bean 时,需要在 spring-config 中添加⼀⾏ bean 注册内容才⾏,如下图所示:

这种存入 Bean 的方式,并不是很好!
1、需要手动添加 bean 对象 到 配置文件中
2、如果 是配置文件中出现了问题,不好调试。
这么说吧:如果 配置文件 出现了 问题,它是不会影响到程序的运行的。
它不会像 抛异常 一样,来 “显式” 的 打印 错误信息栈,描述具体的错误位置。
配置文件出现问题,它是“默不做声”的!【没有错误提示的】
除非你经验老道,否则你很难会想到是 它 出了问题。
⽽现在我们只需要⼀个注解就可以替代之前要写⼀⾏配置的尴尬了,不过在开始存储对象之前,我们先要来点准备⼯作。
简单来说:
就是通过利用 注解,来简化 存入 / 取出 Bean(对象)的步骤。
1.1、前置工作:配置扫描路径(重要)
如果不做这一步,后面所有的操作,都是无效的。
注意:
想要将对象成功的存储到 Spring 中,我们需要配置⼀下存储对象的扫描包路径.
只有被配置的包下的所有类,添加了注解才能被正确的识别并保存到 Spring 中。
即:注释 就像是 一个“桥梁”,将注释的 bean,“送往(存入)” Spring中。
但是!有一些步骤还是不能省略的!
比如创建项目,引入 Spring 框架的支持。
1、创建一个普通的 Maven 项目 (这个和之前的一样)
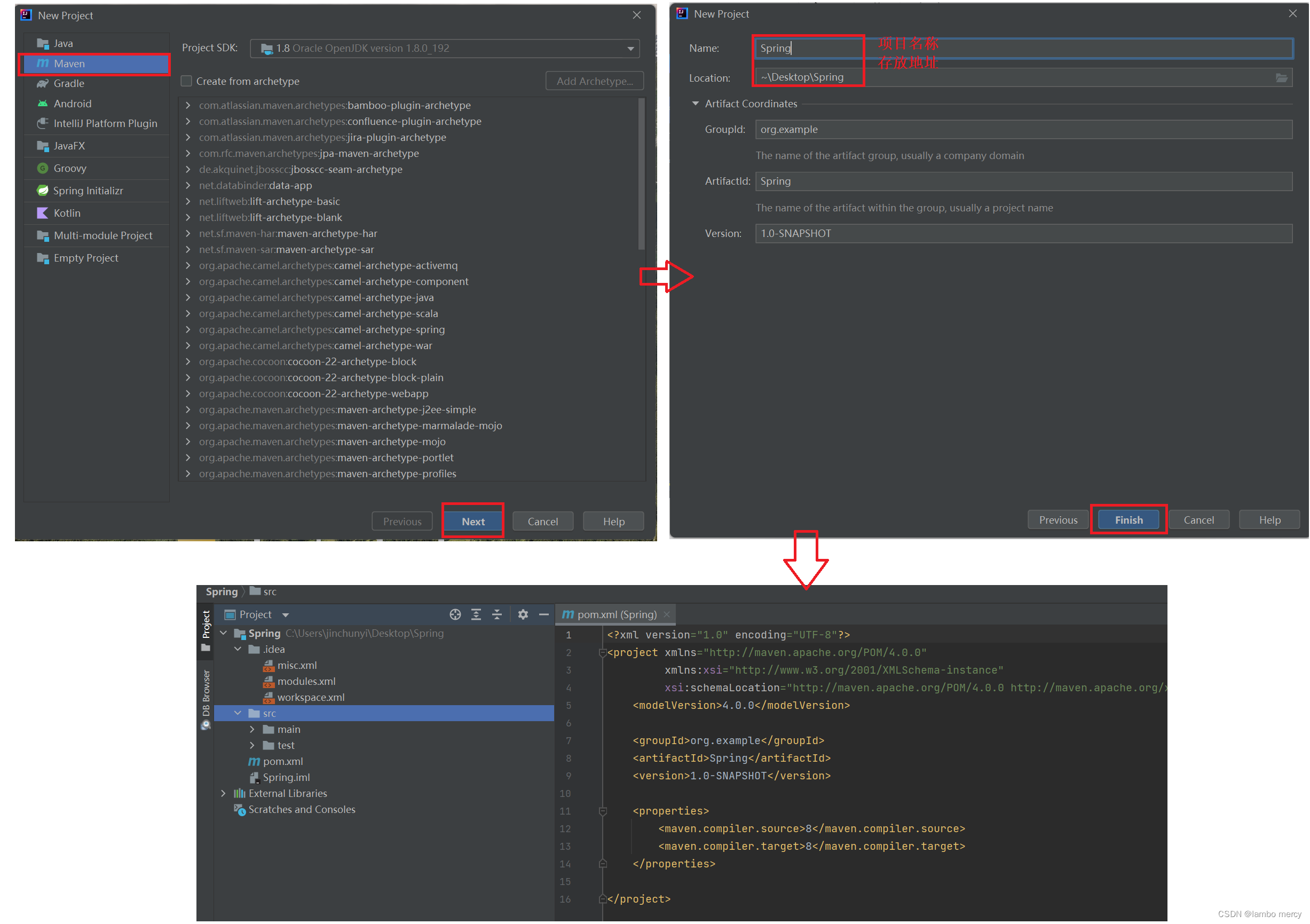
创建一个启动类 和 main 方法。
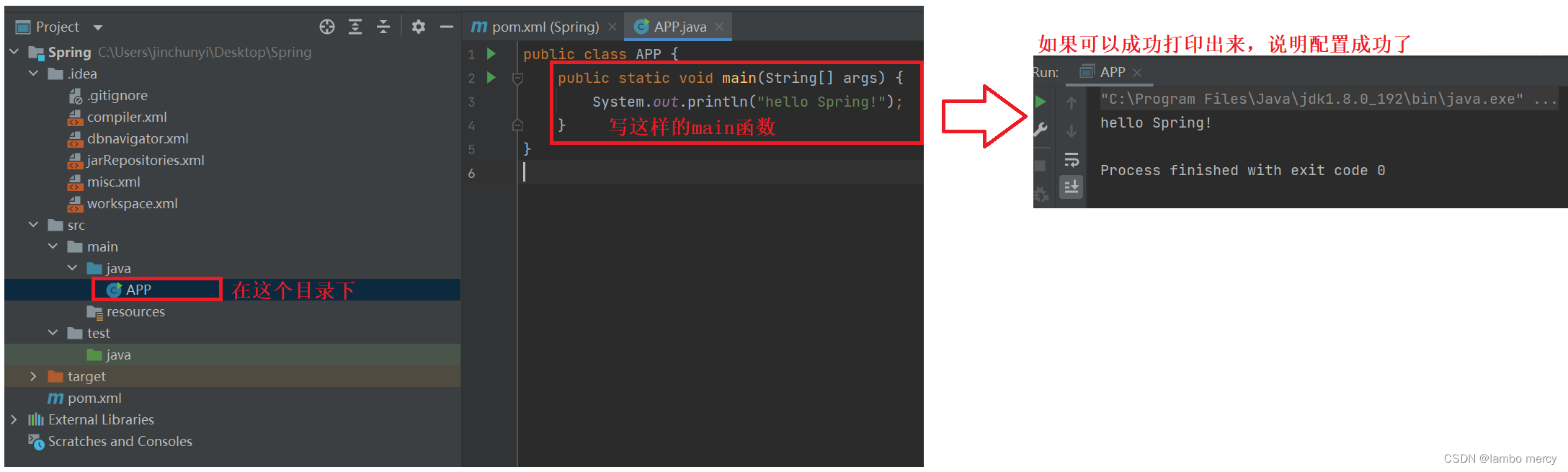
2、引入 Spring 框架的支持 (这个和之前的一样)
将下面我给的 依赖,复制粘贴到 pom.xml 中。
就是一开始进入项目,显示页面文件
<dependencies><dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version>5.2.3.RELEASE</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-beans</artifactId><version>5.2.3.RELEASE</version></dependency>
</dependencies>
在resources 目录下,创建一个 spring-config.xml 的配置文件。
我们配置扫描路径,就是在这里配置的。
将我们下面给的 配置内容,拷贝我们创建的 配置文件中。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:content="http://www.springframework.org/schema/context"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"><content:component-scan base-package=""></content:component-scan>
</beans>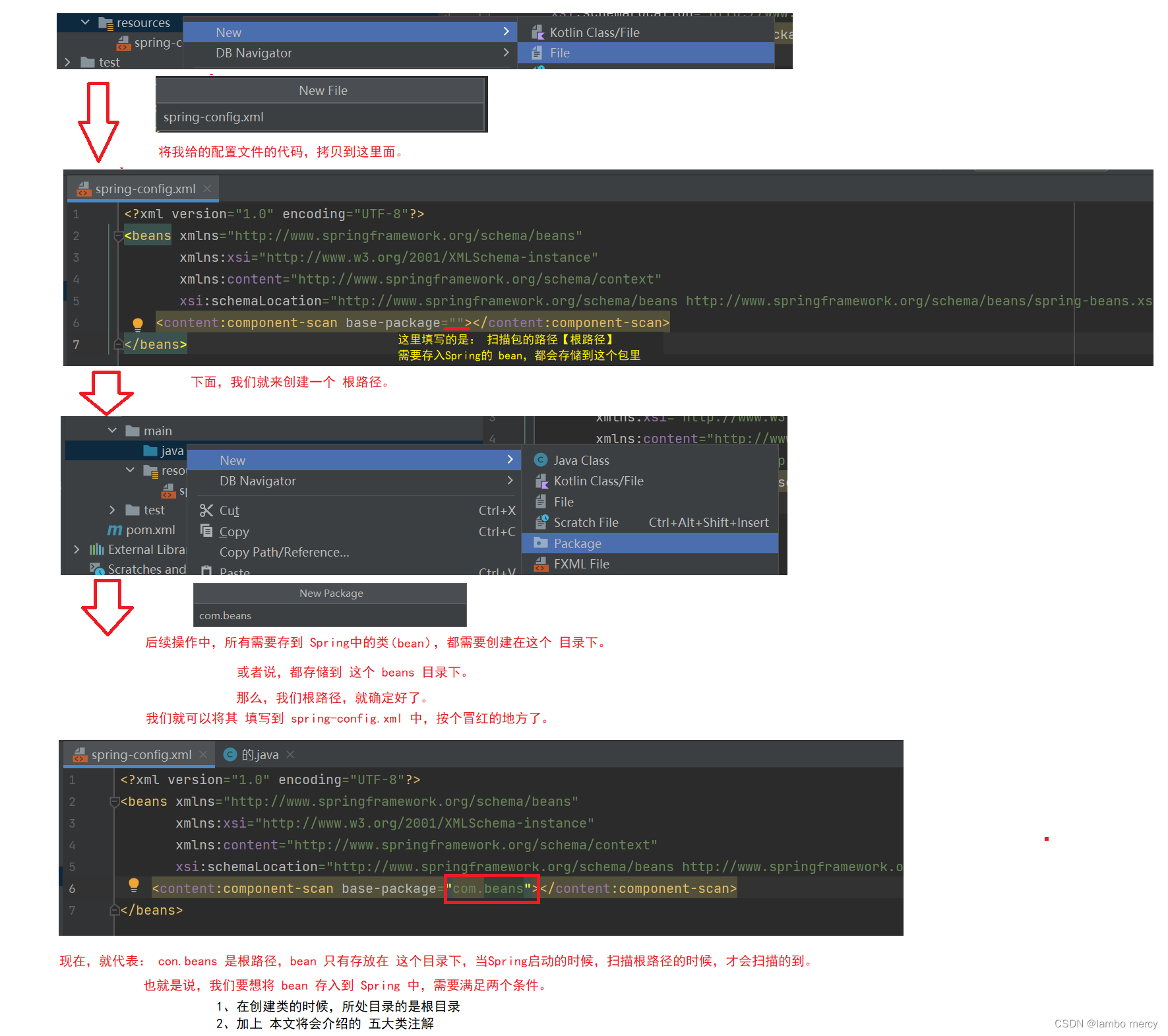
准备工作,到此就结束!
下面,我们就可以开始尝试:使用更简单的方式(使用注解) 来 存储/取出 bean。
1.2、简单的将 bean 存储到容器
一共有两者方法:
1、使用 5 大类注解实现
- @Controller 【Controller - 控制器】
- @Service 【service - 服务】
- @Repository 【repository - 仓库】
- @Configuration 【configuration - 配置/布局】
- @Component 【component - 组件】
通过上述五大类注解中的任何一个,都可以将 bean 存储到 Spring 中。
2、通过 方法注解@Bean ,也可以将 一个 bean 存储到 Spring 中。
1.2.1 使用 5 大类注解实现将 bean 存储到 容器
@Controller 注解
为了验证 注解 的 效果,我们先来在 beans 目录中,创建一个 User 类。
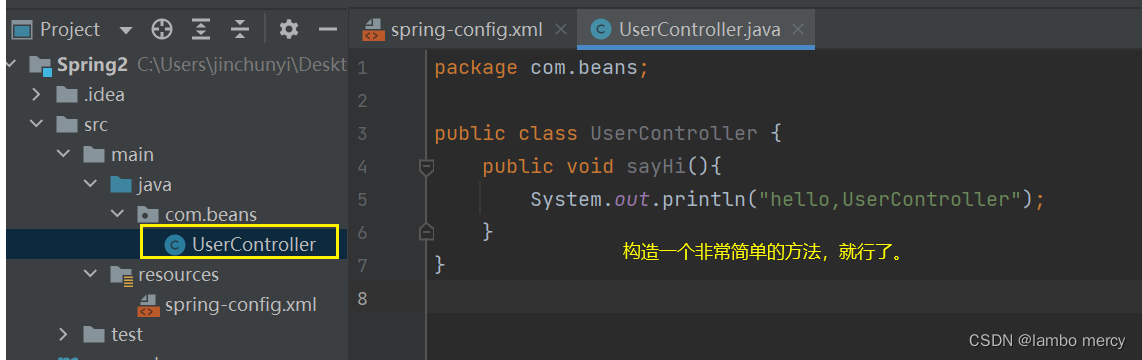

由此,不难得出结论:要存入 Spring 中的 bean,必须处于 根目录下,而且注解不可省略!
思考一个问题
为什么?我们的 Spring 一定要有下面这个配置呢?
如果没有这个配置,意味着什么??
大家可以想象一下:
一个 Spring 项目中,我们的类可分两种类型:
- 需要 进行 控制反转的类,将类的“生命周期”交给 Spring 来管理的类。【比如:这里的UserController】
- 不需要存入 Spring 中的 类。
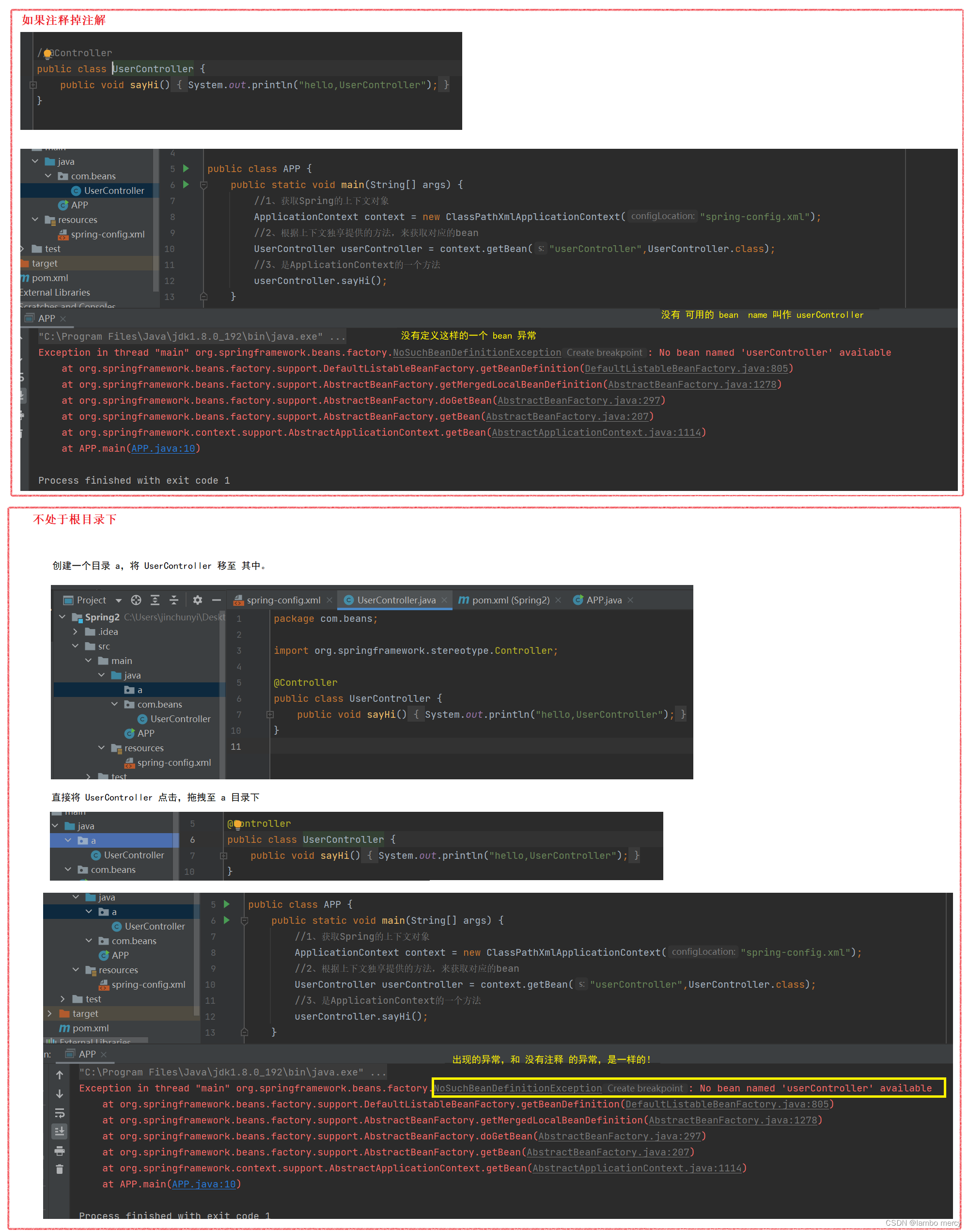
假设,我们有一个大型项目,需要存入 Spring 的 类 和 不需要存入 Spring 中的类,个数占比是五五开的。这就会存在问题了!
如果我们没有 描述 根目录 的 这一行代码,Spring 就会去扫描 所有的类,但是!项目中 需要存入 Spring 中的类,只占 50 %。即:Spring 要浪费一倍的时间,去排查 不需要 存入 Spring 中的类。所以,Spring 为了 提升效率,你必须要给我指定扫描的目录。保证该目录下,一定是需要存入 Spring中的类。这样 Spring就只需要扫描 对应目录中的类,就可以了!

再思考一个问题:
如果 根目录“beans”下面,还有子目录b。
我们将 UserController 类 存放到 b 中,会不会被加载呢?

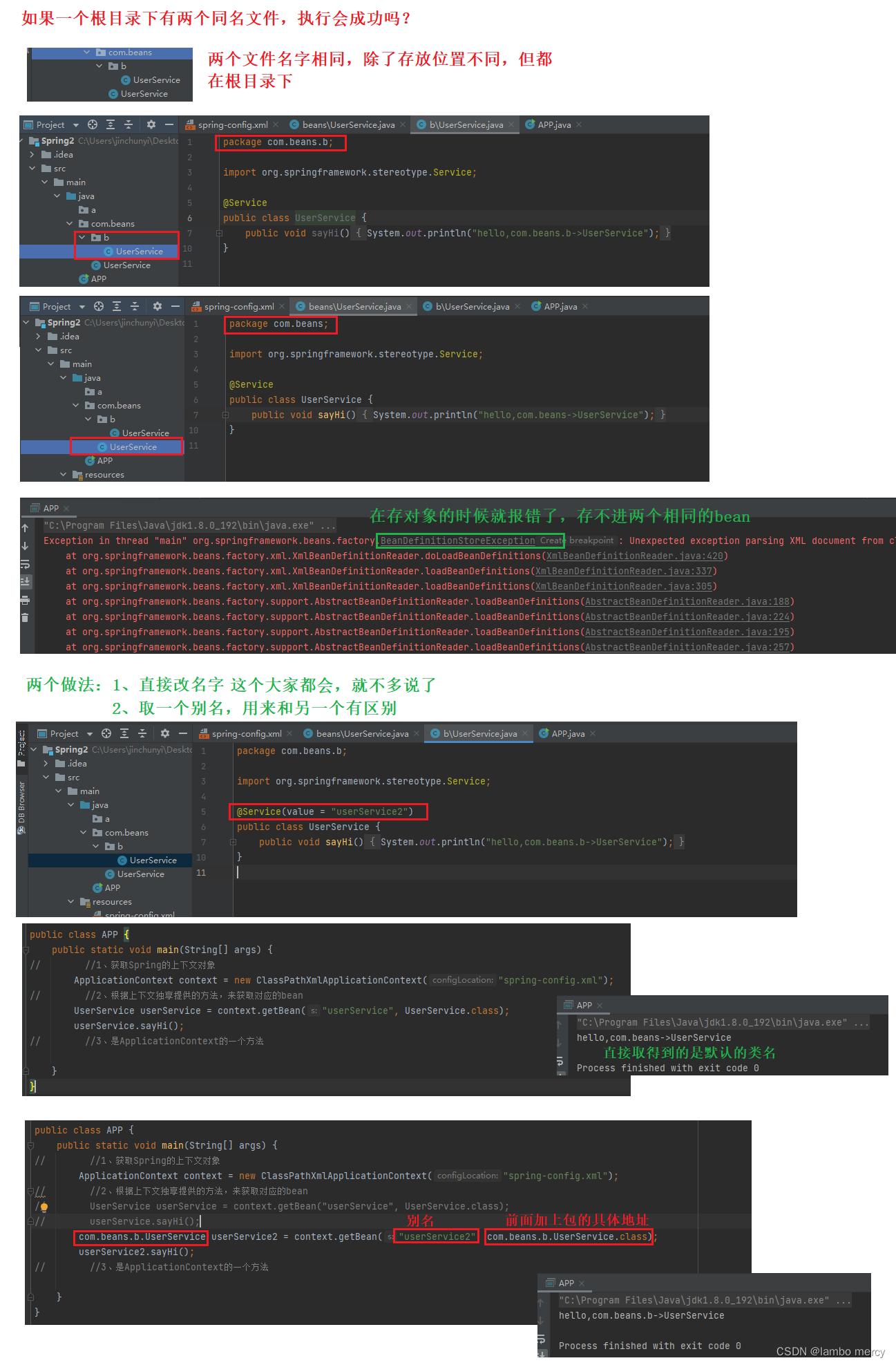
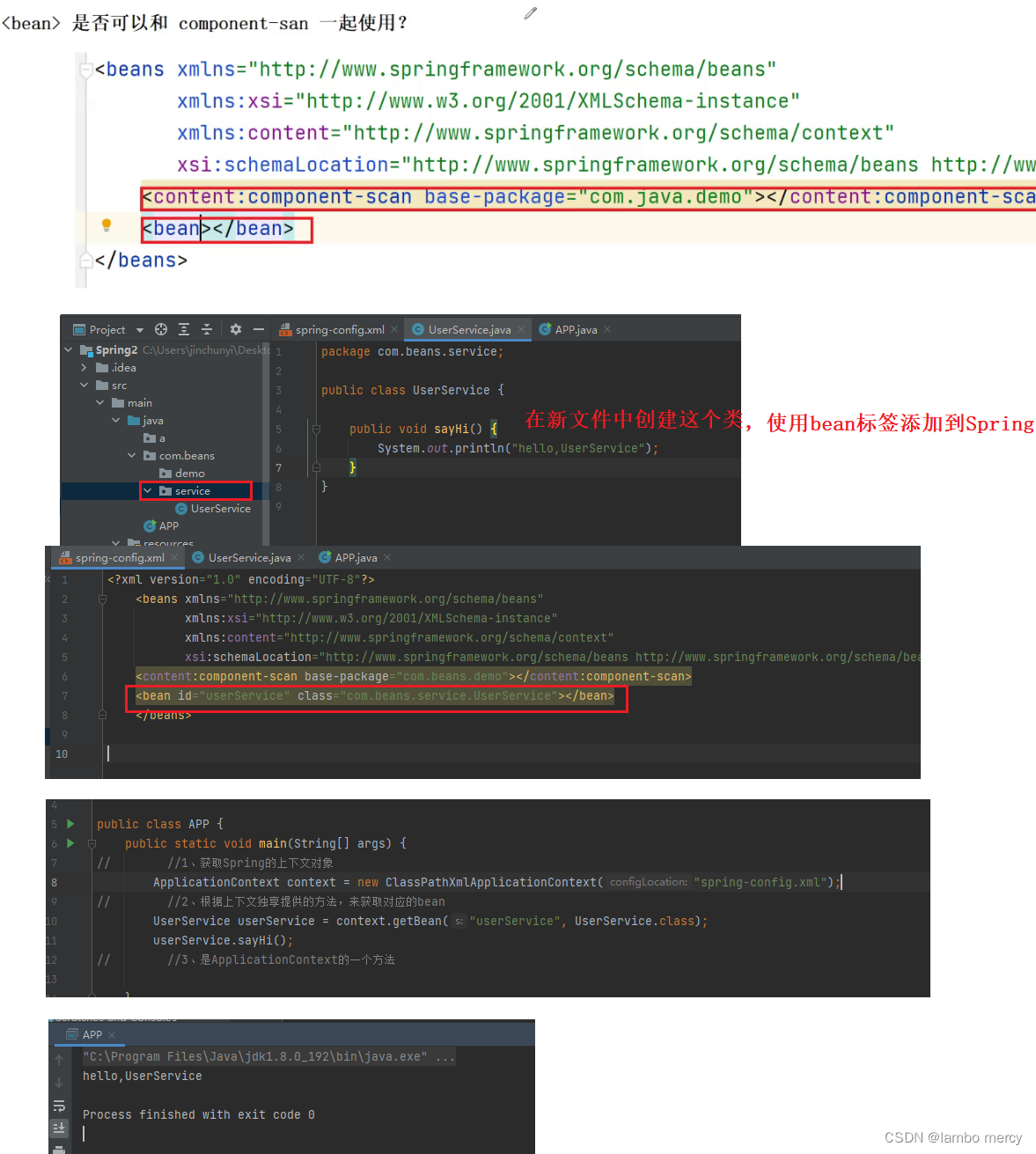 虽然bean标签用起来比较的麻烦,但有些类确实不合适用注解,这个时候就可以用bean标签的方式来补充。所以允许两种方法一起使用。
虽然bean标签用起来比较的麻烦,但有些类确实不合适用注解,这个时候就可以用bean标签的方式来补充。所以允许两种方法一起使用。
剩下四个注解,与上面一样的配方
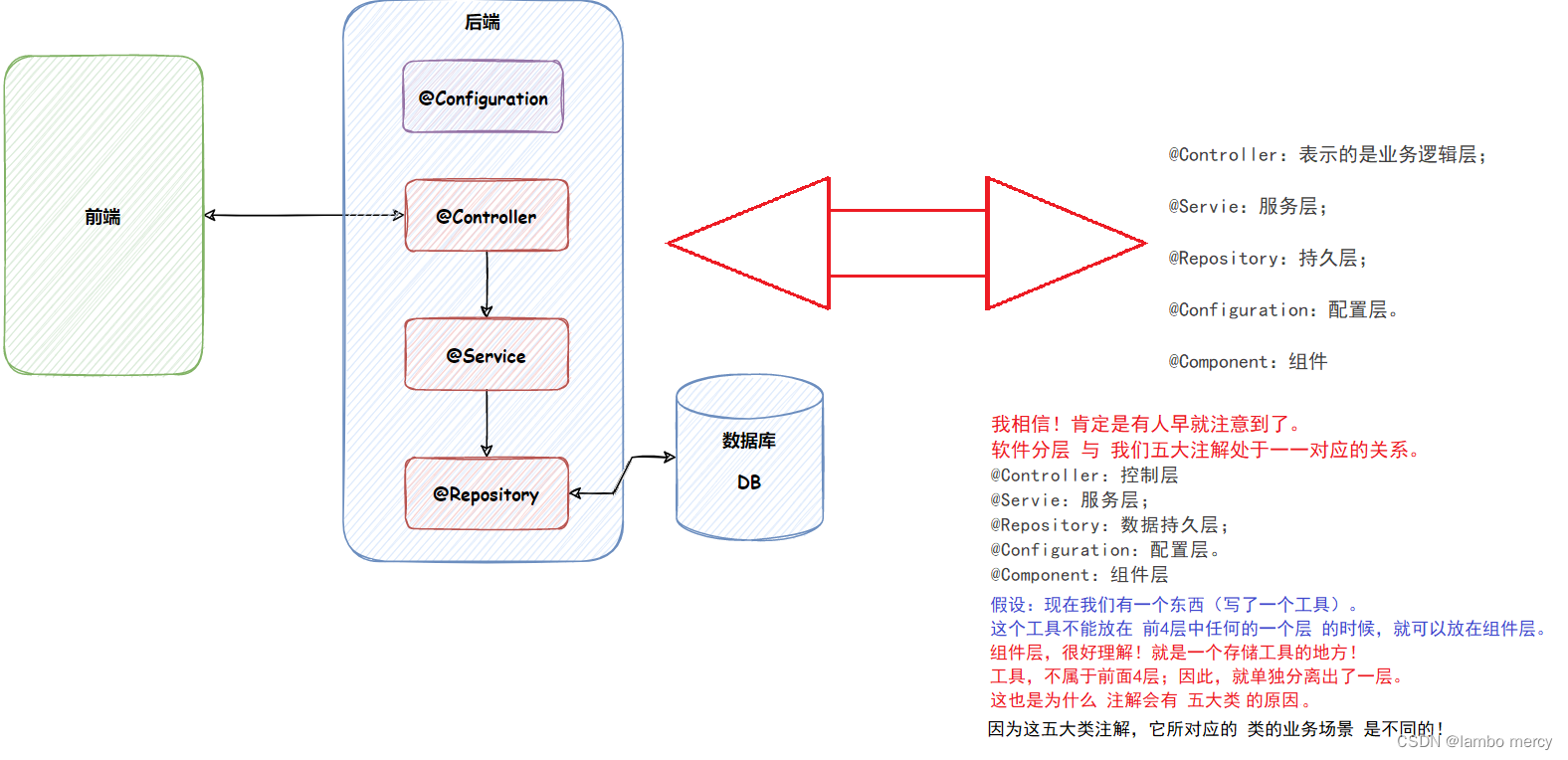
问题一:为什么需要五大类注解?
这就涉及到 软件工程方面的知识了!

之所以讲这个 关于“软件分层” 的定义呢,就是为了 后面讲解 “为什么要有五大注解类” 做铺垫!
那么,问题来了,为什么不直接弄一个 “集大成者” 的注解呢?
一个注解当五个用!
这和为什么每个省/市都有⾃⼰的⻋牌号是⼀样的!
⽐如:陕⻄的⻋牌号就是:陕X:XXXXXX ;北京的⻋牌号:京X:XXXXXX;甚⾄⼀个省不同的县区也是不同的。⻄安就是,陕A:XXXXX,宝鸡,陕C:XXXXXX,⼀样
这样做的好处除了可以节约号码之外,更重要的作⽤是可以直观的标识⼀辆⻋的归属地。
五大类注解,就是为了避免 混淆的情况出现,所以针对 类的不同场景,进行分层。
每个注解负责的层次,是不一样的。但是只需要处理 各自负责的事务,就可以了。这就能提高执行的效率。
可能有些人的想法比较奇特:
为什么你就不能为 每个 层次的代码,创建一个目录,把 对应的代码 都放在 对应的目录下,
等到你需要查看这个类,是属于那一层的时候。
直接访问这个类所处于的目录,看看这个类是在 哪个目录底下嘛?
不就行了嘛!
注意!这样做,会产生 2个 有难度的操作!
1、我们得去扫描项目的每个路径,来获取这个类所处的目录【层次】。
2、将本应该处于某一层的类,创建到另一层里面去了,我们还不知道,怎么办?
这是非常难以判断!你的类又没有移动!因为你直接创建到另一层中的。
如果是使用的注解,那就简单多了。
这就好比:每一辆车都有它们自己地区信息的牌照。
直接 针对 该地区中的车牌,进行查找对应的信息。
不必在全国的范围中,进行搜索。
查询的基数大大降低,查找效率大大提高!
得出结论:
使用 五大类注解,是为了让代码的可读性提高,让程序员能够更直观的判断当前类的业务用途。
问题二:五大类注解之间有什么关系?
这五个类注解实现的功能 都是一样的,只是“长得”不一样。
那么,这 五个类注解之间,有什么关系呢?

结论:Component 注解,与其它四大注解,呈 “父子” 关系。
Controller,Service, Repository,configuration注解, 都是基于 Component 注解实现的。
问题三:关于 bean id 的命名,为什么是小驼峰结构?
在我们前面演示 五大类注解 的时候,我们其实就猜出了 bean id,默认是小驼峰。
但是!这一块有一个特例!!


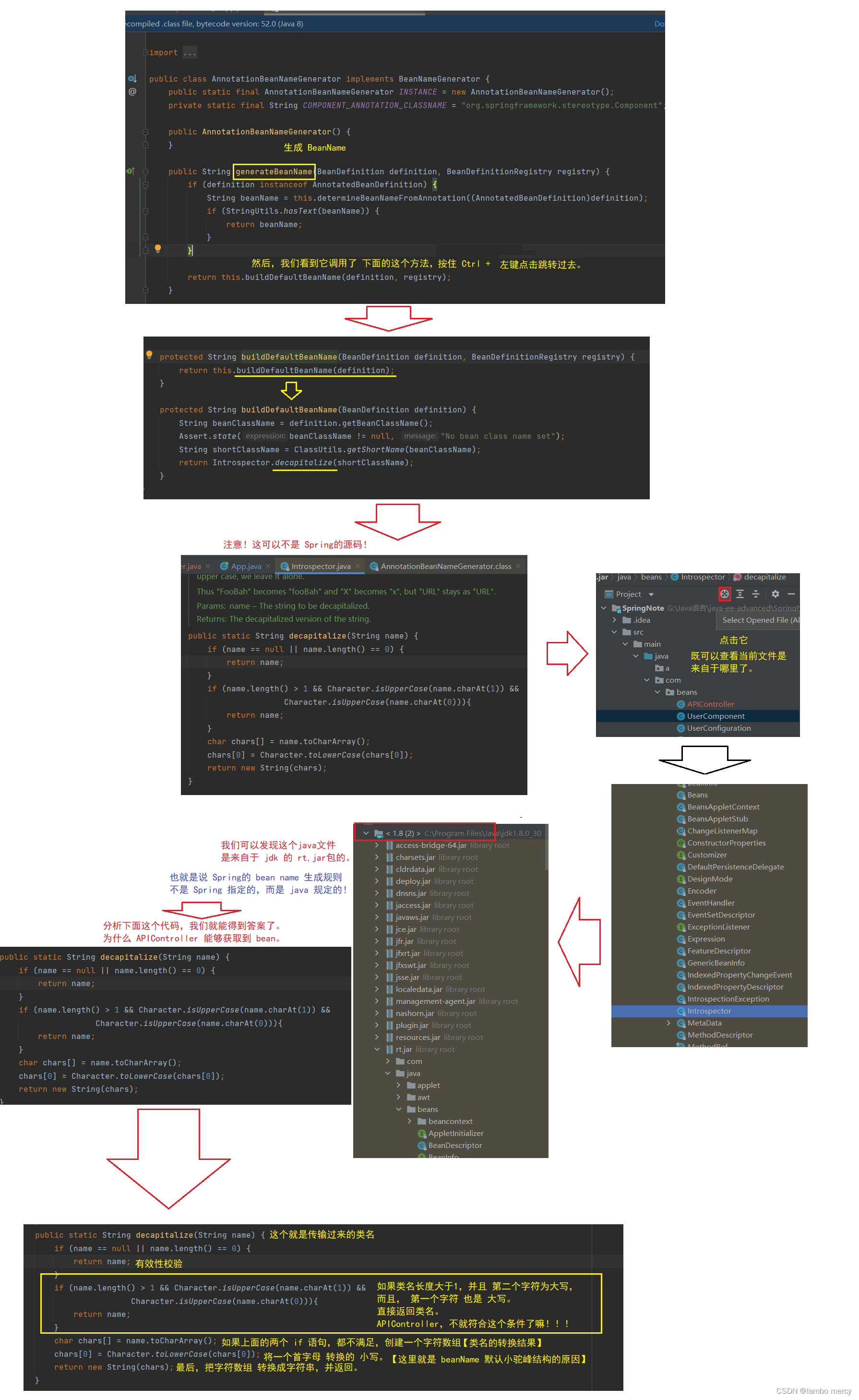
验证一下:

到这里,我们就明白了 bean 的命名规则。
但是!最好还是 不要斜侧 APIController 这种形式。
虽然能执行,但是不符合规范。
最好,还是写 UserController 这种。
生成的 bean Name 是 小驼峰,才是“正统”!
1.2.2 使用 方法注解 @Bean 将 bean更简单的存入容器。
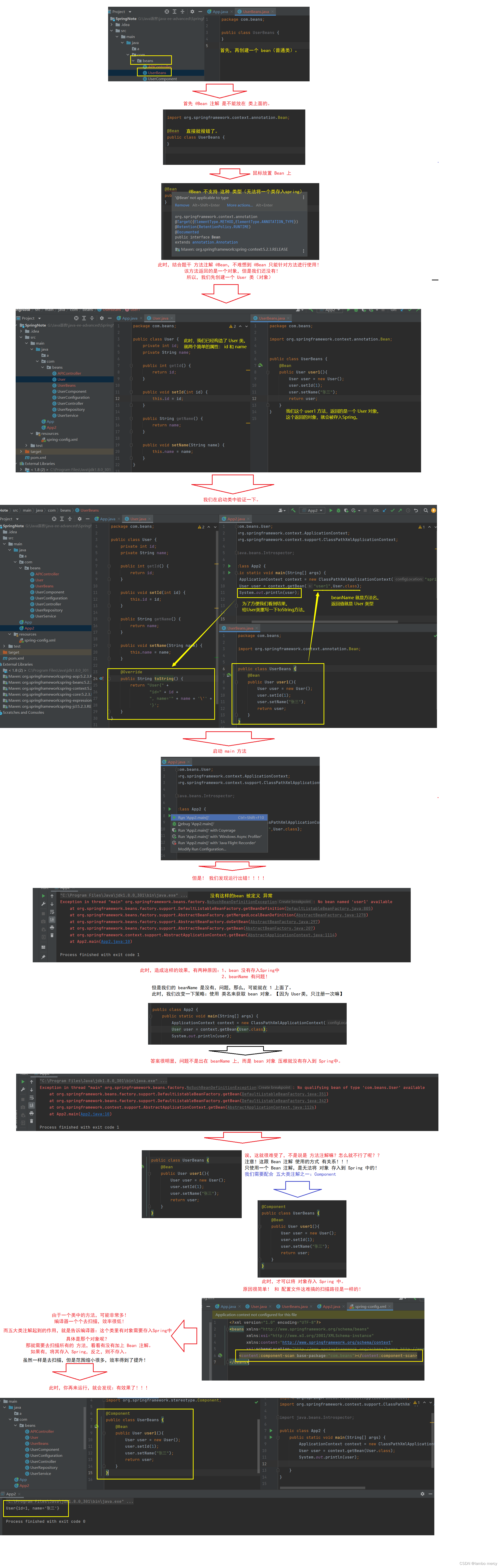 同时,我有验证了一下 beanName,发现和 beanName 是没有关系的!
同时,我有验证了一下 beanName,发现和 beanName 是没有关系的!
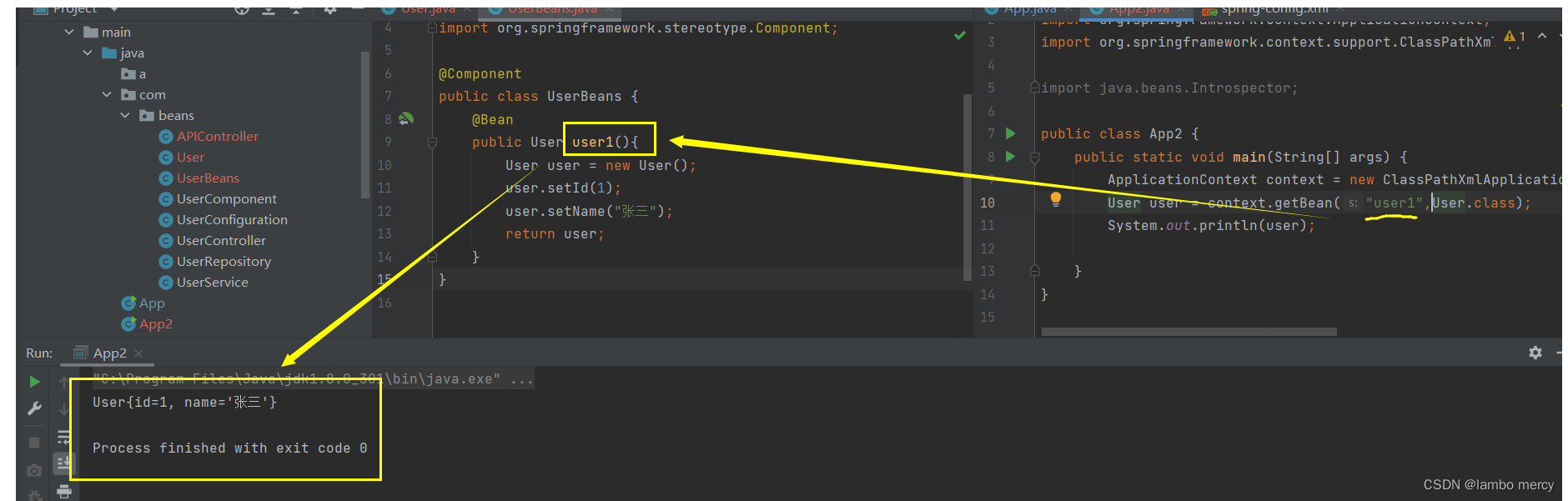
就是因为 @Bean 注解,需要搭配五大类注解 来使用。
同时,说明了 方法的 beanName 就是 方法名。
不需要 大驼峰,或者 小驼峰的格式。
直接照搬!
你们需要注意的是:方法 和 类 的命名规则,不是同一个!
因此,管你是大骆驼,还是小骆驼,都是不行滴!
只能使用 方法的原名!!!!
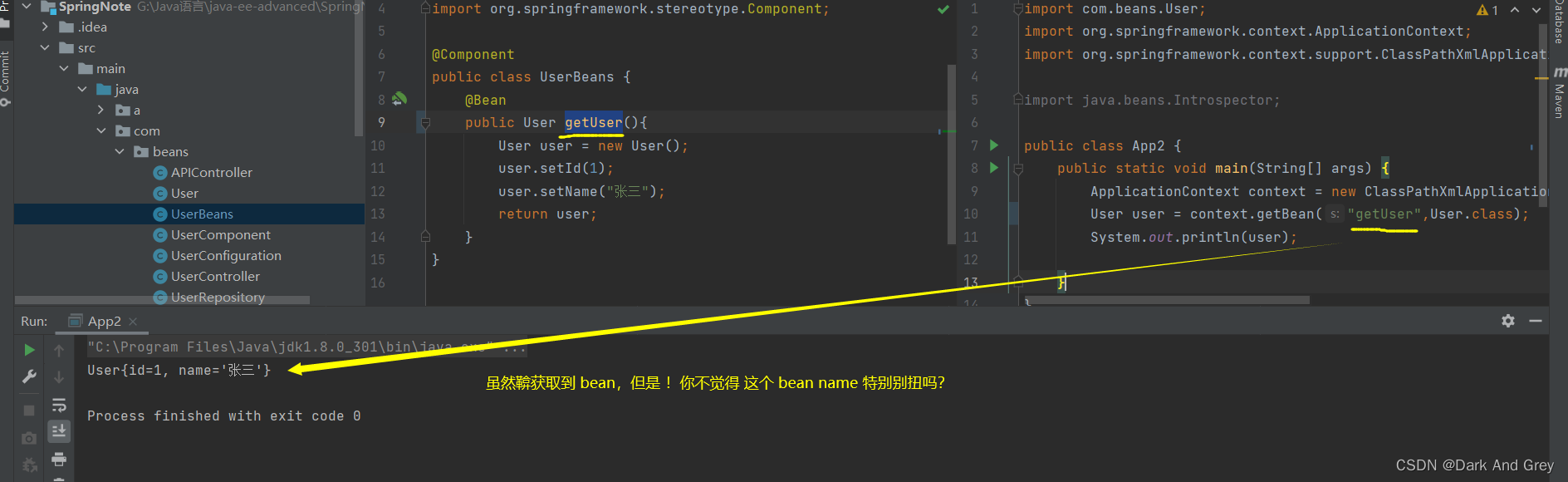
重命名 Bean
大家来思考一个问题:
真的在公司里工作,方法的名字,我们会取 像 user1 这么low的名字嘛?
答案:否定的! 公司对代码,是由规范要求的!
而且,相信大部分朋友,可能都喜欢 将其命名为 getUser.
又或者是通过某种条件,来获取对象。
比如:name 和 id,即 getUserByName,getUserById ,这种命名方式。
相信是部分朋友的“习惯”。
虽然这么命名,也能获取到对象。这么说吧:我们 想要获取的是 bean对象,你填一个 方法名,好像有点不太合适吧?
难道我们就不能使用 像类名的 命名规则 给 方法 重命名吗?
答案:有的!!!这里需要注意一点: 如果方法被重命名,原先的方法名,就没用了!
结论:
@Bean 命名规则,当没有设置 name 属性时,那么 beanName 默认就是 方法名。
反之,当设置 name 属性之后, name 属性对应的值,就是 beanName。
而且,属性的值,可以有多个,每一个都是可以使用的。
但是!此时 方法名 就不可以使用了!



2、获取 Bean 对象(对象装配)
获取 bean 对象也叫做 对象装配,是把对象取出来放到某个类中,有时候也叫 对象注⼊。
对象装配,简单来说:
就是在使用 A 的时候,需要用到 B了。
那么,你将 B 对象 注入到 A 里面来,让我来用。
因此,对象装配,又可以称为 对象注入。
更直白来说:对象装配(对象注入),就是将 bean 从 Spring 中取出来。
对象装配(对象注⼊)的实现⽅法以下 3 种:
1、 属性(字段)注⼊
2、 构造⽅法注⼊
3、 Setter 注⼊
接下来,我们分别来看。
2.1 属性注入
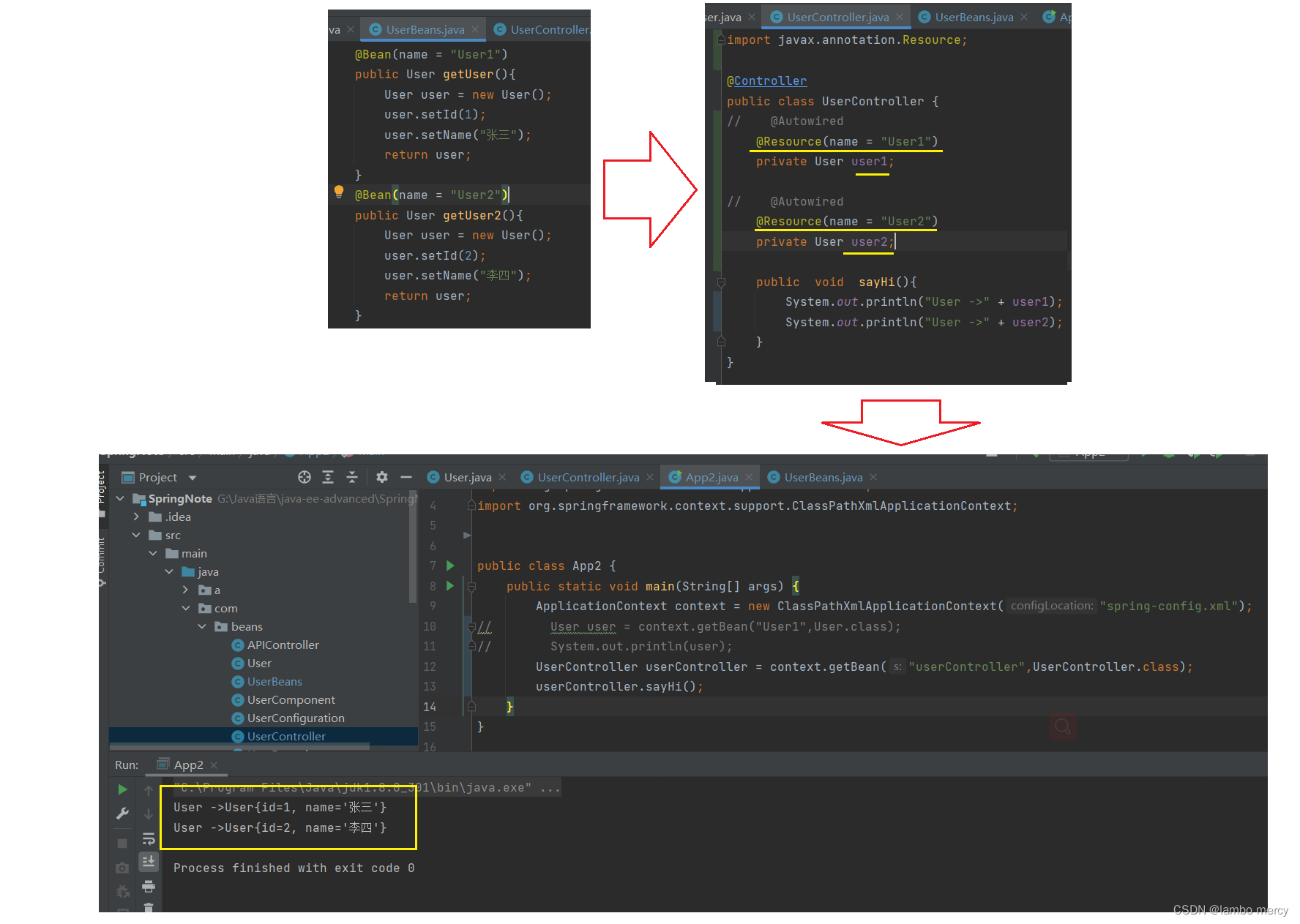
2.1.1 @Autowired 注解 (Spring)
autowired 的意思就是自动装配

因此,可以得出结论:
在使用 @Autowired 进行 属性注入的时候
如果 注入的对象,被多次 存入 Spring 中了,那么,光凭 属性的类型是找不到匹配的 bean的!需要将 属性的变量名 改成 BeanName,根据 BeanName 来找寻匹配的对象(bean)并进行 属性注入。
方法不止这一种,但是上述这种 “精确描述 bean 的名称” 的方法,是最简单高效的!
是不是很简单,不用去获取 Spring 的上下文对象 和 getBean 方法,直接通过一个注解,即可获取对应的bean(从Spring中取出 bean)。
属性注入的优点是:简单
属性注入的缺点主要包含以下三个:
1.功能性问题: 无法注入一个不可变的对象 (final 修饰的对象)
2. 兼容性问题: 只能适应于 loC 容器
3.设计原则问题:更容易违背单一设计原则
2.1.2 @Resource 注解 (JDK)
@Resource 注解,是来自于 JDK 的!【JDK 自带的注解】
而 @Autowired, 是属于 Spring的!
@Resource 注解 比 @Autowired 的 属性要强!
因为 @Resource 注解 有一个 name 属性,可以用指定 注入的 bean 的名称。
但是问题来了!如果公司强制要求 使用 @Autowired,怎么办!?
其实还有第三种方法:
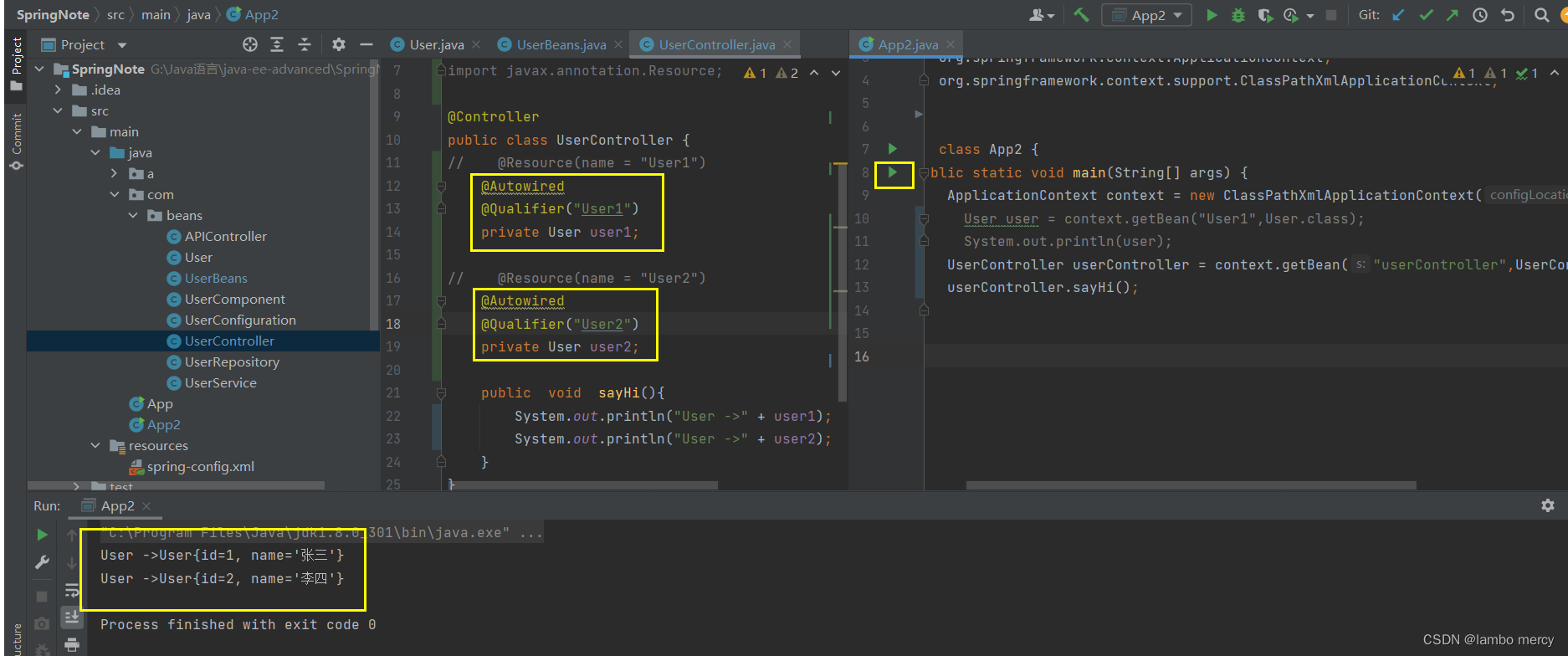
2.1.3 @Autowired 搭配 @Qualifier 注解
Qualifier - 限定符 :解决注入迷失问题的。
你可以将 @Qualifier 注解 认为是 一个筛选器。
我们不是通过@Autowired注解 获得了 User1,User2,两个 bean 嘛。
此时,我们就可以通过 @Qualifier 注解,对齐搜索结果,进行筛选!
那么,怎么去使用 @Qualifier 注解呢?
很简单!给 @Qualifier 一个参数(限定符 / beanName),根据 这个参数,对 @Autowired注解 查询的结果,进行筛选!
其实 @Qualifier 和 @Resource 的 name属性类似的!
为什么这么说?
因为 @Qualifier,其实调用了 自身的 value 属性。(隐式的调用 / 默认调用)
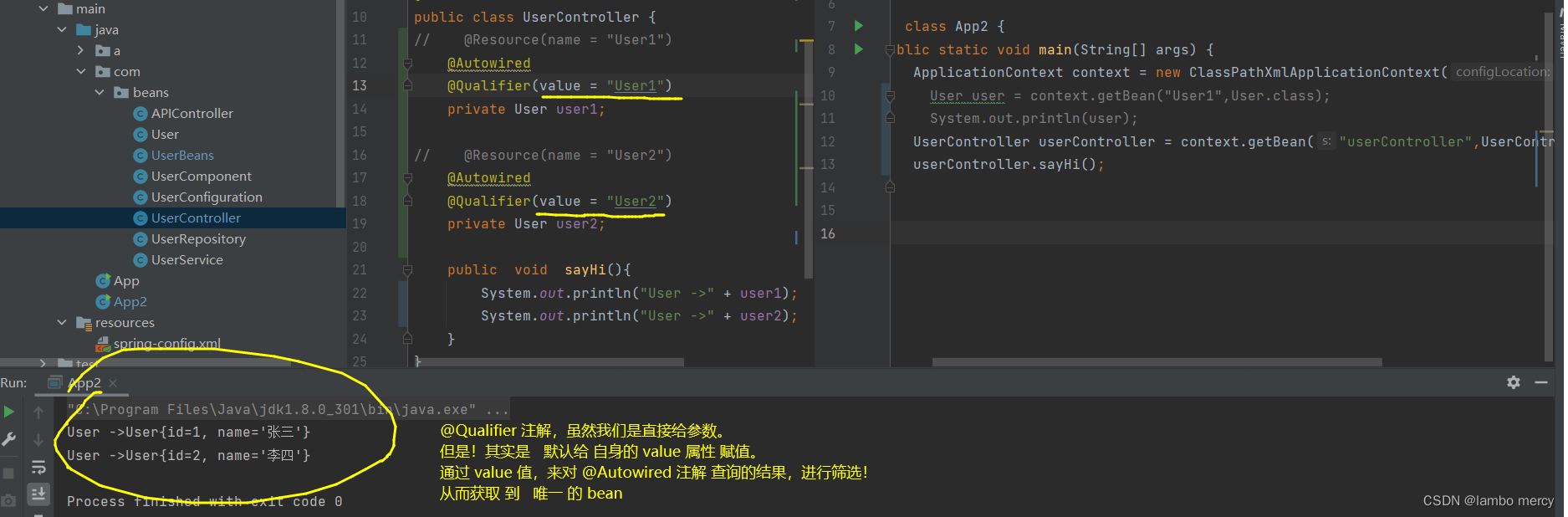
虽然 @Qualifier 的属性 可以省略。
但是!指不定 那次版本更新,就删除(或修改)了这一机制。
要求我们必须显式的 给 value 属性 赋值(或者,默认调用的属性,不再是 value了)。
因此,最好还是 显式 的 给 value 赋值。
通过 这种写法,我们的属性名可以随便取自己喜欢的名称。
不用去刻意的修改成 对应的beanName。
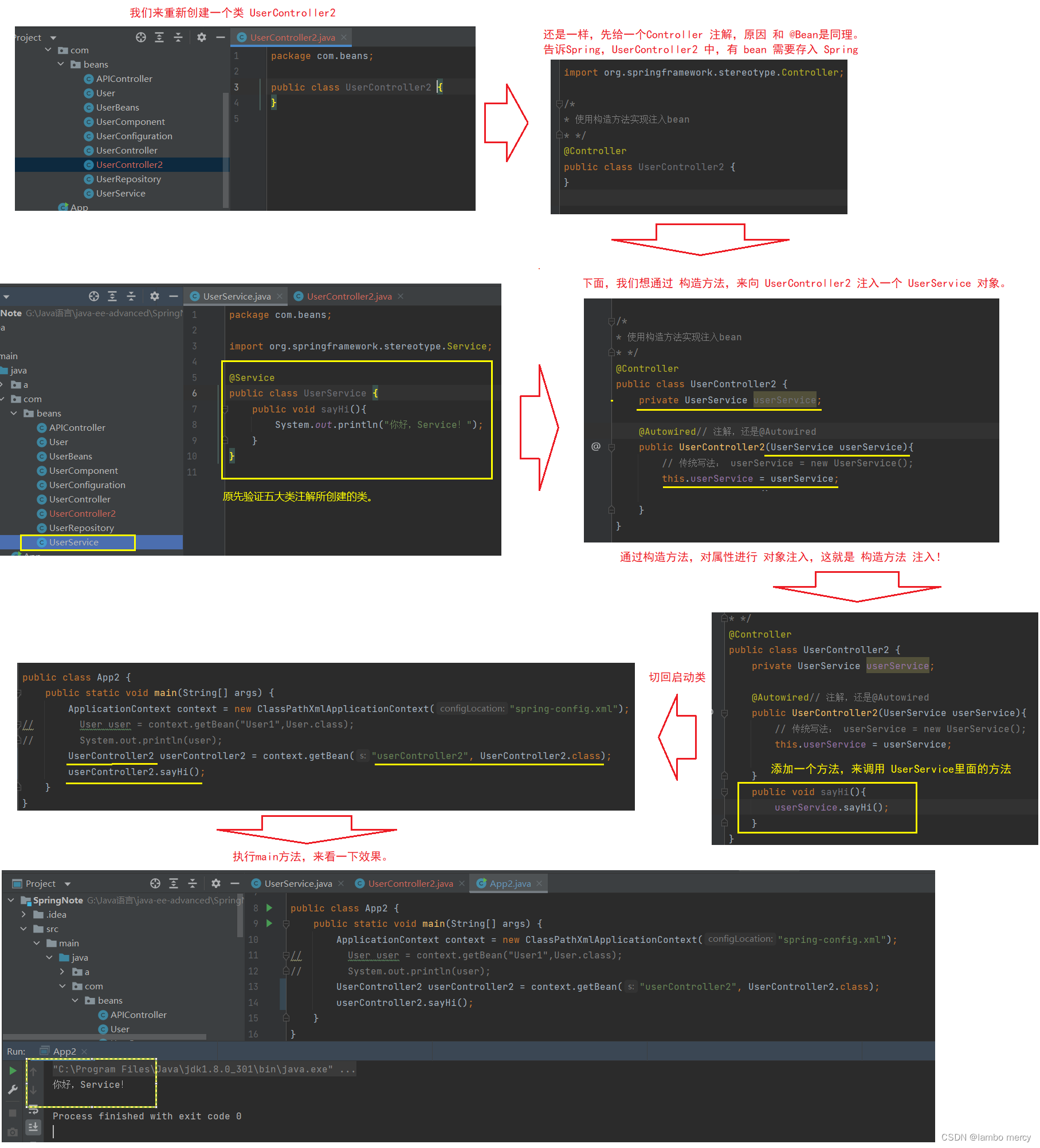
2.2 构造方法注入
还是使用 @Autowired 来注解来实现。
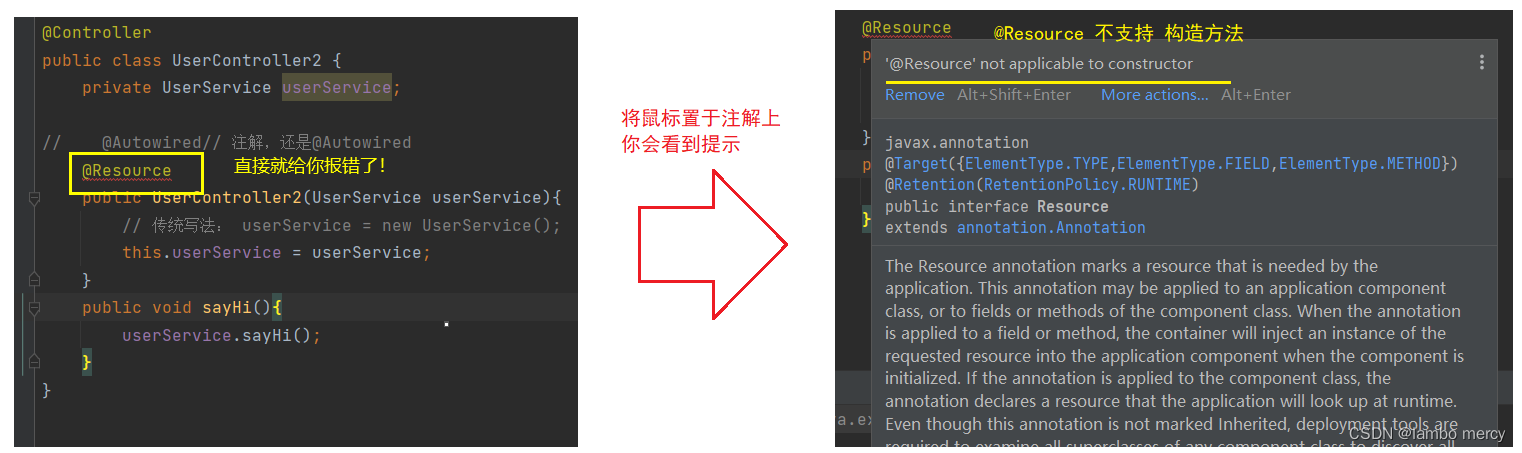
需要注意的是 @Resource 注解,是不支持 构造方法注入的!
另外,在补充一个细节:
当 类里面只有一个构造方法的时候,@Autowired 是可以省略的!
优点:(官方推荐)
1.可注入不可变对象;
2.注入对象不会被修改;
3.注入对象会被完全初始化;
4.通用性更好。

2.3 Setter 注入
这个也是一样的,还是通过 @Autowired 实现 Setter 注入。
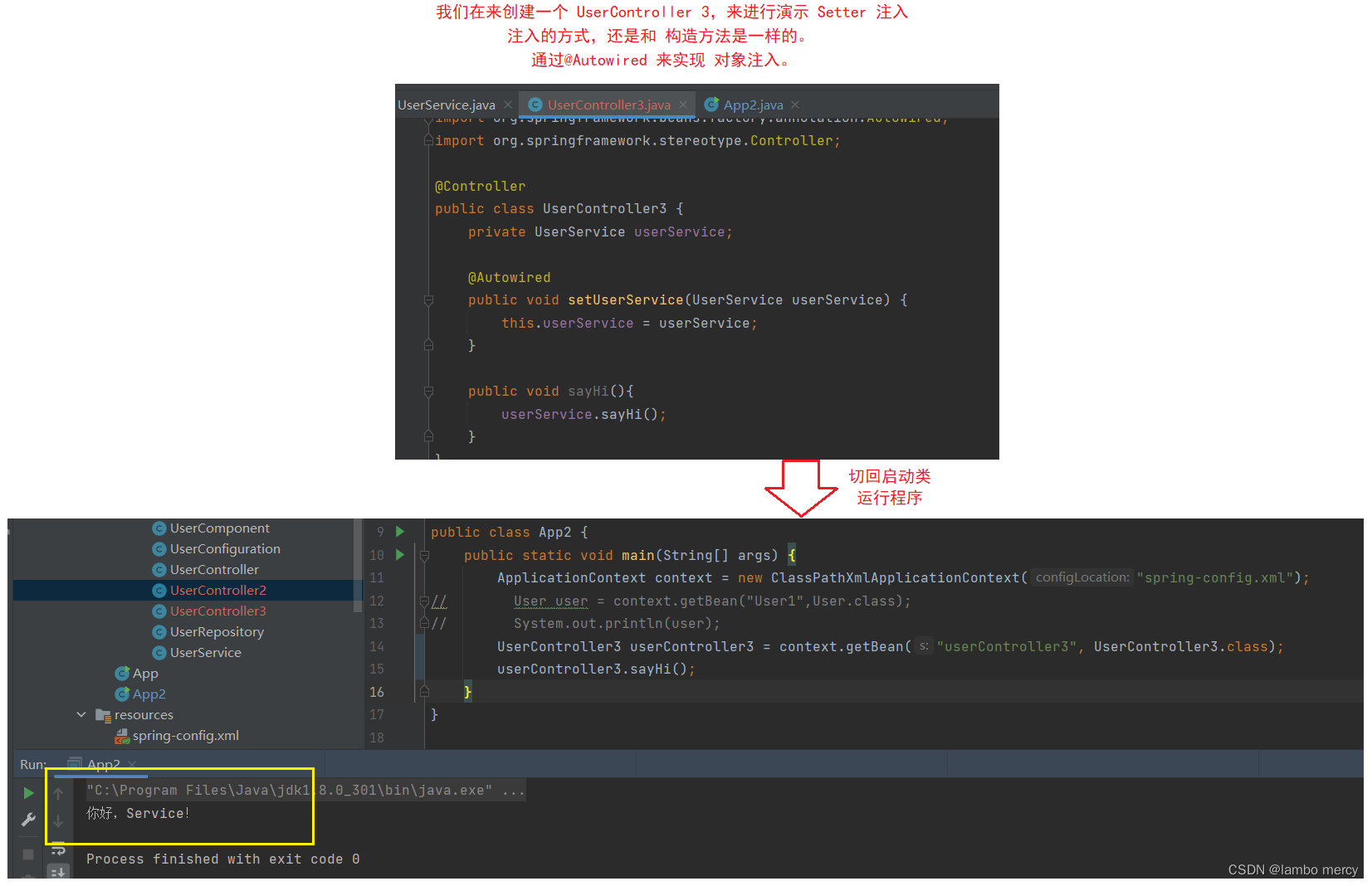
另外,@Resource也支持 Setter 注入。

Setter的优点:符合单一设计原则(每个方法只传递一个对象)
缺点:1.不能注入不可变对象 (final 修饰的对象) ;2.注入的对象可被修改
拓展1:经典面试题 -> 属性注入 ,构造方法注入 和 Setter 注入 之间,有什么区别?

拓展2:@Resource VS @Autowired 的区别
1、用法不同
@Autowired,支持 属性注入,构造方法注入,Setter 方法注入。
@Resource:支持 属性注入,Setter方法注入。不支持 构造方法注入。
2、@Resource 的 属性注入 比 @Autowired 的 属性注入,使用的更舒服。 因为 @Resource 有很多的属性可以设置;而 @Autowired 只有一个 value 属性。
有很多的属性,即意味着可以使用很多其它的功能。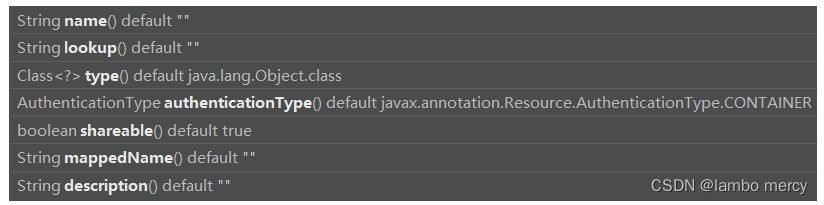
比如: @Resource 的 name 属性,
那么,可以利用 name 属性可以用来指定 beanName,从而注入对应的 bean。
而 @Autowired 需要将属性变量名修改成对应的 beanName,才能获取对应的bean。
又或者,通过搭配 @Qualifier 注解 来获取对应的bean。
至于其它的,@Autowired 都没有属性了,还怎么对比。。
所以,关于 属性注入方面, @Resource 注解 更好用!
3、出身不同
@Autowired 是 Spring 框架 提供的。
@Resource 是 JDK 提供的。
这么说吧:
如果使用的是 @Resource,转移平台的时候(框架改变了),只要对方也是基于Java实现的,程序是能够使用的。
反之,如果使用的 @Autowired,它是只支持 spring 。
换了一个框架,就不可以用了。
庆幸的是:Spring 占据中国市场的份额,几乎是 100% !
因此,这个问题可以不用担心!
知道有这件事就行。
总结
1、将对象存储奥 Spring 中
1、使用五大类注解:@Controller,@Service,@Reposity,@Configuration,@Component【@Component 是 其余四大类注解的 “父” 级】
2、使用 方法注解 @Bean
【注意事项:@Bean 必须搭配五大类注解才能使用】
2、Bean的命名规则:
需要存入Spring中的类,其类名的第二个字母非大写,在没有指定 beanName 的情况下,默认生成的 beanName 是 类名的首字母小写 的状态(小驼峰)
反之,如果类名的 首字母 和 第二个字母 都是大写的,在没有指定 BeanName 的情况下,默认生成的 BeanName 就是 类的原名。
3、从 Spring 中获取对象
1、属性注入
1.1、使用 @Autowired注解实现(属性的变量名 和 【bean id / bean name】 相同)
1.2、使用 @Resource 注解 实现。(添加一个name 属性,其name的值是 bean id)
1.3、使用 @Autowired 的同时,搭配 @Qualifier 注解。【通过 指定 @Qualifier 的 value 属性值(值为 bean id),】
2、Setter 注入
3、构造方注入 【官方推荐,但是它自己却用的很少】
4、注入的关键字有
1、@Autowired
2、@Resource
5、@Autowired 和 @Resource
1、出身不同【@Autowired 是 Spring 提供的,@Resource 是 JDK 提供的】
2、使用的属性不同【@Autowired 只有一个 value 属性,@Resource 除了name,还有很多】
3、用法不同
【@Autowired 支持 属性注入,构造方法注入,Setter 注入】
【@Resource 支持 属性注入,Setter 注入】
6、解决同一类型多个Bean的报错
1、使用 @Resource(name =“bean id”)
2、使用 @Autowired + @Qualifier(value=“bean id”)