数据库demo
数据库RUNOOB
表Websites
元素:
创建
- 创建数据库 create database xxx
Create database school
- 创建数据表 create table xxx
create table student
- 数据表插入记录 insert into
- 第一种形式无需指定要插入数据的列名,只需提供被插入的值即可:
INSERT INTO table_name
VALUES (value1,value2,value3,...);
- 第二种形式需要指定列名及被插入的值:
INSERT INTO table_name (column1,column2,column3,...)
VALUES (value1,value2,value3,...);
- 更新表中的记录 update
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
- 删除表中的行 delete
DELETE FROM table_name
WHERE condition;
Delete和drop的区别:DELETE用于删除行级别的记录,而DROP用于删除表级别的对象。DELETE只会删除表中的特定记录,而DROP将删除整个表及其关联的数据和对象。
6、复制表 select into (从一个表复制信息到另一个表)
创建 Websites 的备份复件:
SELECT *
INTO WebsitesBackup2016
FROM Websites;
只复制一些列插入到新表中:
SELECT name, url
INTO WebsitesBackup2016
FROM Websites;
只复制中国的网站插入到新表中:
SELECT *
INTO WebsitesBackup2016
FROM Websites
WHERE country='CN';
复制多个表中的数据插入到新表中:
SELECT Websites.name, access_log.count, access_log.date
INTO WebsitesBackup2016
FROM Websites
LEFT JOIN access_log
ON Websites.id=access_log.site_id;
7、复制并插入表 insert select into (从一个表复制数据,然后把数据插入到一个已存在的表中)
复制 "apps" 中的数据插入到 "Websites" 中:
INSERT INTO Websites (name, country)
SELECT app_name, country FROM apps;
只复 id=1 的数据到 "Websites" 中:
INSERT INTO Websites (name, country)
SELECT app_name, country FROM apps
WHERE id=1;
8、约束 (可以在创建表时规定(通过 CREATE TABLE 语句),或者在表创建之后规定(通过 ALTER TABLE 语句))
- not null - 指示某列不能存储 NULL 值。
- unique - 保证某列的每行必须有唯一的值。
- primary key ( NOT NULL 和 UNIQUE 的结合)。主键,确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
主键必须包含唯一的值。
主键列不能包含 NULL 值。
每个表都应该有一个主键,并且每个表只能有一个主键。
- foreign key 外键。保证一个表中的数据匹配另一个表中的值的参照完整性。
一个表中的 FOREIGN KEY 指向另一个表中的 UNIQUE KEY(唯一约束的键)。
- check - 保证列中的值符合指定的条件。
- default - 规定没有给列赋值时的默认值。
9、新记录自动生成 identity(初始值,增幅) (auto increment会在新记录插入表中时生成一个唯一的数字)
CREATE TABLE Persons
(ID int IDENTITY(1,1) PRIMARY KEY)
IDENTITY 的开始值是 1,每条新记录递增 1
10、创建索引 create index (在不读取整个表的情况下,索引使数据库应用程序可以更快地查找数据)
CREATE INDEX index_name
ON table_name (column_name)
11、撤销/删除 drop (撤销索引、撤销表以及撤销数据库)
- 删除索引
DROP INDEX table_name.index_name
- 删除表
drop table table_name
- 删除数据库
drop database database_name
- 如果我们仅仅需要删除表内的数据,但并不删除表本身,使TRUNCATE TABLE语句:
TRUNCATE TABLE table_name
12、修改表 alter (用于在已有的表中添加、删除或修改列)
如需在表中添加列,请使用下面的语法:
ALTER TABLE table_name
ADD column_name datatype
如需删除表中的列,请使用下面的语法(请注意,某些数据库系统不允许这种在数据库表中删除列的方式):
ALTER TABLE table_name
DROP COLUMN column_name
要改变表中列的数据类型,请使用下面的语法:
ALTER TABLE table_name
ALTER COLUMN column_name datatype
13、视图 view
CREATE VIEW view_name AS
SELECT column_name(s)
FROM table_name
WHERE condition
14、日期 data
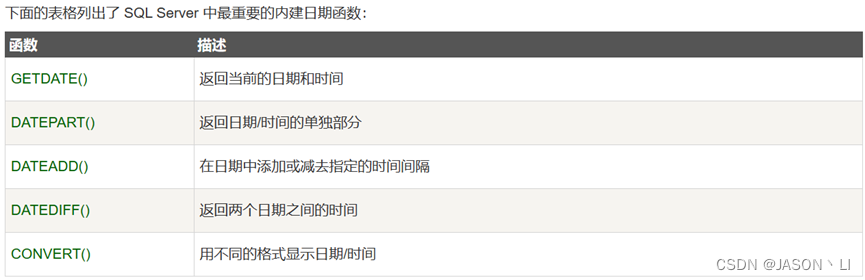
15、触发器 trigger
create trigger trigger_insert_score
on score
after insert
as
begin
if not exists
(select* from student where sno in (select sno from inserted)
)
begin
rollback transaction
begin transaction
end
endcreate trigger trigger_delete_student
on student
for delete
as
begin
delete from score
where sno in(select sno from deleted)
endcreate trigger trigger_protect_grade
on score
for update
as
begin
rollback transaction
begin transaction
end
查询
1、元素不重复distinct
SELECT DISTINCT column1, column2, ...
FROM table_name;
2、元素过滤(选择) where
SELECT column1, column2, ...
FROM table_name
WHERE condition;
3、元素与和或条件 and & or
SELECT * FROM Websites
WHERE country='CN'
AND alexa > 50;
SELECT * FROM Websites
WHERE country='USA'
OR country='CN';
4、元素排序 order by(默认升序)
SELECT column1, column2, ...
FROM table_name
ORDER BY column1, column2, ... ASC|DESC;
ASC:表示按升序排序。
DESC:表示按降序排序。
5、规定要返回的记录的数目(返回前几条)top
SELECT TOP number|percent column_name(s)
FROM table_name;
number:表示返回前几个数
percent:表示返回前百分之几
6、搜索列中的指定模式 like
SELECT * FROM Websites
WHERE name LIKE 'G%';
7、通配符(与LIKE 操作符一起使用)
SQL 通配符 | 菜鸟教程 (runoob.com)
8、在where子句中规定多个值 in
SELECT * FROM Websites
WHERE name IN ('Google','菜鸟教程');
9、选取介于两个值之间的数据范围内的值 between
SELECT * FROM Websites
WHERE alexa BETWEEN 1 AND 20;
10、别名 as
SELECT column_name AS alias_name
FROM table_name;
11、连接 join(LEFT JOIN、RIGHT JOIN、INNER JOIN、OUTER JOIN)默认inner
SELECT column1, column2, ...
FROM table1
JOIN table2 ON condition;

11-1、内连接 inner join(INNER JOIN 与 JOIN 是相同的。)
SELECT column_name(s)
FROM table1
INNER JOIN table2
ON table1.column_name=table2.column_name;

11-2、左连接 left join (从左表(table1)返回所有的行,即使右表(table2)中没有匹配。如果右表中没有匹配,则结果为 NULL)
SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name=table2.column_name;

11-3、右连接 right join (从右表(table2)返回所有的行,即使左表(table1)中没有匹配。如果左表中没有匹配,则结果为 NULL)
SELECT column_name(s)
FROM table1
RIGHT JOIN table2
ON table1.column_name=table2.column_name;

11-4、满连接 full outer join (只要左表(table1)和右表(table2)其中一个表中存在匹配,则返回行)[结合了 LEFT JOIN 和 RIGHT JOIN 的结果]
SELECT column_name(s)
FROM table1
FULL OUTER JOIN table2
ON table1.column_name=table2.column_name;

12、合并查询union (合并两个或多个 SELECT 语句的结果)
SELECT column_name(s) FROM table1
UNION
SELECT column_name(s) FROM table2;
注释:默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
SELECT column_name(s) FROM table1
UNION ALL
SELECT column_name(s) FROM table2;
SQL Server 数据类型
String 类型:
| 数据类型 | 描述 | 存储 |
| char(n) | 固定长度的字符串。最多 8,000 个字符。 | Defined width |
| varchar(n) | 可变长度的字符串。最多 8,000 个字符。 | 2 bytes + number of chars |
| varchar(max) | 可变长度的字符串。最多 1,073,741,824 个字符。 | 2 bytes + number of chars |
| text | 可变长度的字符串。最多 2GB 文本数据。 | 4 bytes + number of chars |
| nchar | 固定长度的 Unicode 字符串。最多 4,000 个字符。 | Defined width x 2 |
| nvarchar | 可变长度的 Unicode 字符串。最多 4,000 个字符。 | |
| nvarchar(max) | 可变长度的 Unicode 字符串。最多 536,870,912 个字符。 | |
| ntext | 可变长度的 Unicode 字符串。最多 2GB 文本数据。 | |
| bit | 允许 0、1 或 NULL | |
| binary(n) | 固定长度的二进制字符串。最多 8,000 字节。 | |
| varbinary | 可变长度的二进制字符串。最多 8,000 字节。 | |
| varbinary(max) | 可变长度的二进制字符串。最多 2GB。 | |
| image | 可变长度的二进制字符串。最多 2GB。 |
Number 类型:
| 数据类型 | 描述 | 存储 |
| tinyint | 允许从 0 到 255 的所有数字。 | 1 字节 |
| smallint | 允许介于 -32,768 与 32,767 的所有数字。 | 2 字节 |
| int | 允许介于 -2,147,483,648 与 2,147,483,647 的所有数字。 | 4 字节 |
| bigint | 允许介于 -9,223,372,036,854,775,808 与 9,223,372,036,854,775,807 之间的所有数字。 | 8 字节 |
| decimal(p,s) | 固定精度和比例的数字。 允许从 -10^38 +1 到 10^38 -1 之间的数字。 p 参数指示可以存储的最大位数(小数点左侧和右侧)。p 必须是 1 到 38 之间的值。默认是 18。 s 参数指示小数点右侧存储的最大位数。s 必须是 0 到 p 之间的值。默认是 0。 | 5-17 字节 |
| numeric(p,s) | 固定精度和比例的数字。 允许从 -10^38 +1 到 10^38 -1 之间的数字。 p 参数指示可以存储的最大位数(小数点左侧和右侧)。p 必须是 1 到 38 之间的值。默认是 18。 s 参数指示小数点右侧存储的最大位数。s 必须是 0 到 p 之间的值。默认是 0。 | 5-17 字节 |
| smallmoney | 介于 -214,748.3648 与 214,748.3647 之间的货币数据。 | 4 字节 |
| money | 介于 -922,337,203,685,477.5808 与 922,337,203,685,477.5807 之间的货币数据。 | 8 字节 |
| float(n) | 从 -1.79E + 308 到 1.79E + 308 的浮动精度数字数据。 n 参数指示该字段保存 4 字节还是 8 字节。float(24) 保存 4 字节,而 float(53) 保存 8 字节。n 的默认值是 53。 | 4 或 8 字节 |
| real | 从 -3.40E + 38 到 3.40E + 38 的浮动精度数字数据。 | 4 字节 |
Date 类型:
| 数据类型 | 描述 | 存储 |
| datetime | 从 1753 年 1 月 1 日 到 9999 年 12 月 31 日,精度为 3.33 毫秒。 | 8 字节 |
| datetime2 | 从 1753 年 1 月 1 日 到 9999 年 12 月 31 日,精度为 100 纳秒。 | 6-8 字节 |
| smalldatetime | 从 1900 年 1 月 1 日 到 2079 年 6 月 6 日,精度为 1 分钟。 | 4 字节 |
| date | 仅存储日期。从 0001 年 1 月 1 日 到 9999 年 12 月 31 日。 | 3 bytes |
| time | 仅存储时间。精度为 100 纳秒。 | 3-5 字节 |
| datetimeoffset | 与 datetime2 相同,外加时区偏移。 | 8-10 字节 |
| timestamp | 存储唯一的数字,每当创建或修改某行时,该数字会更新。timestamp 值基于内部时钟,不对应真实时间。每个表只能有一个 timestamp 变量。 |
其他数据类型:
| 数据类型 | 描述 |
| sql_variant | 存储最多 8,000 字节不同数据类型的数据,除了 text、ntext 以及 timestamp。 |
| uniqueidentifier | 存储全局唯一标识符 (GUID)。 |
| xml | 存储 XML 格式化数据。最多 2GB。 |
| cursor | 存储对用于数据库操作的指针的引用。 |
| table | 存储结果集,供稍后处理。 |
SQL 函数
SQL 拥有很多可用于计数和计算的内建函数。
SQL Aggregate 函数
SQL Aggregate 函数计算从列中取得的值,返回一个单一的值。
有用的 Aggregate 函数:
- AVG() - 返回平均值
- COUNT() - 返回行数
- FIRST() - 返回第一个记录的值
- LAST() - 返回最后一个记录的值
- MAX() - 返回最大值
- MIN() - 返回最小值
- SUM() - 返回总和
SQL Scalar 函数
SQL Scalar 函数基于输入值,返回一个单一的值。
有用的 Scalar 函数:
- UCASE() - 将某个字段转换为大写
- LCASE() - 将某个字段转换为小写
- MID() - 从某个文本字段提取字符,MySql 中使用
- SubString(字段,1,end) - 从某个文本字段提取字符
- LEN() - 返回某个文本字段的长度
- ROUND() - 对某个数值字段进行指定小数位数的四舍五入
- NOW() - 返回当前的系统日期和时间
- FORMAT() - 格式化某个字段的显示方式
特别说明函数:
1、GROUP BY 语句(GROUP BY 语句用于结合聚合函数,根据一个或多个列对结果集进行分组。)
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;
2、HAVING 子句 (在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。HAVING 子句可以让我们筛选分组后的各组数据。)
SELECT column1, aggregate_function(column2)
FROM table_name
GROUP BY column1 HAVING condition;
3、EXISTS 运算符 (EXISTS 运算符用于判断查询子句是否有记录,如果有一条或多条记录存在返回 True,否则返回 False。)
SELECT column_name(s)
FROM table_name
WHERE EXISTS
(SELECT column_name FROM table_name WHERE condition);