文章目录
- UniSA:统一的情感分析生成框架
- 文章信息
- 研究目的
- 研究内容
- 研究方法
- 1.总体架构图
- 2.基准数据集SAEval
- 3.Task-Specific Prompt
- 4.Modal Mask Training
- 5.Pre-training Tasks
- 5.1Mask Context Modeling
- 5.2Sentiment Polarity Prediction
- 5.3Coarse-grained Label Contrast Learning
- 5.4Cross-task Emotion Prediction
- 结果与讨论
- 代码和数据集
UniSA:统一的情感分析生成框架
总结:原理=>所有子任务整合起来,数据集就变得很大了,让模型学习这些所有的数据,模型的情感能力就上去了,关键在于怎么整合?训练好之后,不管是情感分析的什么任务(输入都会被Task-Specific Prompt统一,输出都有四个标签,一个真实标签,三个伪标签),通过这个框架都可以实现不错的结果。
文章信息
作者:Zaijing Li,Fengxiao Tang
单位:Central South University(中南大学)
会议/期刊:Proceedings of the 31st ACM International Conference on Multimedia(MM 2023)(CCF A)
题目:UniSA: Unified Generative Framework for Sentiment Analysis
年份:2023
研究目的
探究情感分析的多任务统一建模,将情感分析的子任务整合到一个单一的模型中,来提高模型的情感能力。
【对情感分析的所有子任务进行统一建模存在三个主要挑战:1.每个子任务的输入和输出形式各不相同。2.多模态的模态对齐问题。3.数据集注释偏差。
- 引入了特定任务提示方法,将所有子任务视为生成任务并进行联合训练,来统一不同子任务的输入和输出形式。
- 通过扩展生成式Transformer(基础的Transformer模型)去处理多模态数据,提出了一种模态掩码训练方法学习模态间的关系,来解决模态对齐的问题。
- 引入数据集嵌入消除不同数据集之间的注释偏差。】
研究内容
-
提出了一个多模态生成框架 UniSA,重新耦合情感分析的各个子任务(对话中的情感识别 (ERC)、基于方面的情感分析 (ABSA) 和多模态情感分析 (MSA)),实现多任务统一建模。
-
提出了一种新颖的情感相关预训练任务(Pre-training Tasks),让模型能够学到跨子任务的通用情感知识。
-
构建了一个基准数据集 SAEval,以统一的格式包含了各种情感分析子任务的基准数据集。
研究方法
1.总体架构图
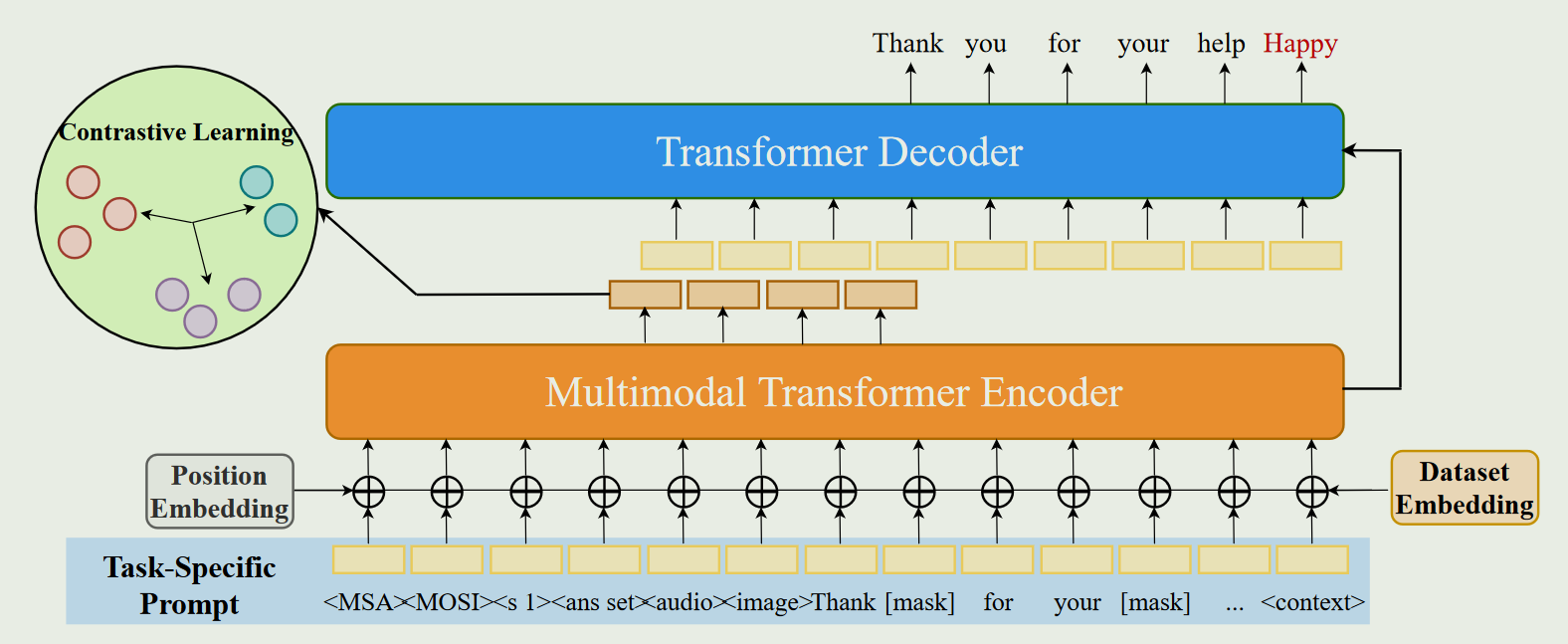
为了处理视觉、声学和文本的跨模态输入,将原始的Transformer编码器修改为多模态编码器,并引入了模态掩码训练方法(该方法使得模型能够有效地学习到不同模态之间的关系)。通过任务特定提示( Task-Specific Prompt )方法来规范所有子任务的输入格式。为了解决数据集之间的偏差,在输入中嵌入了一个数据集,以区分不同的数据集。
2.基准数据集SAEval
基准数据集SAEval的构建是将来自不同情感分析子任务的多个数据集统一以字典格式存储。(该词典包括"Task Type"、"Dataset ID "、“Text”、“Audio”、“Image"等关键词。对于ERC数据集,额外的信息如” Context “,” Speaker ID “和” Utterance index "被包含来确定当前查询的会话信息。)数据集示例:

3.Task-Specific Prompt
通过任务特定提示(Task-Specific Prompt)统一所有子任务的输入流,并将所有子任务转化为生成任务来统一子任务的输出形式。【作用就是统一输入与输出】

任务特定提示包括三个组成部分:任务标识符Z、答案集Y和输入流X。
- 标识符Z由特殊的标记组成(包括Task type,Data id ,Speaker id)。
- 答案集Y是每个数据集的特定标签集合,用于指导模型生成预期结果。
- 输入流X代表输入的文本、声音、视觉和上下文。
L = { Z , Y , X } L=\{Z,Y,X\} L={Z,Y,X}
4.Modal Mask Training
当给定一个多模态输入 I i = I i t , I i a , I i v I_{i}=I_{i}^{t},I_{i}^{a},I_{i}^{v} Ii=Iit,Iia,Iiv时( I i m , m ∈ t , a , v I_i^m,m\in{t,a,v} Iim,m∈t,a,v代表时间 i i i的单模态输入),要掩蔽一个或多个模态的输入,这样将产生七种模态设置,即, I i t , I i a , I i v , I i a + I i v , I i t + I i a , I i t + I i v I_i^t,I_i^a,I_i^v,I_i^a+I_i^v,I_i^t+I_i^a,I_i^t+I_i^v Iit,Iia,Iiv,Iia+Iiv,Iit+Iia,Iit+Iiv与 I i t + I i a + I i v I_i^t+I_i^a+I_i^v Iit+Iia+Iiv。由于文本模态很重要,所以只使用其中的四种设置,也就是 I i t , I i t + I i a , I i t + I i v , I i t + I i a + I i v . I_{i}^{t},I_{i}^{t}+I_{i}^{a},I_{i}^{t}+I_{i}^{v},I_{i}^{t}+I_{i}^{a}+I_{i}^{v}. Iit,Iit+Iia,Iit+Iiv,Iit+Iia+Iiv.通过这样的方式,多模态数据在训练阶段就有了四种不同的输入形式,扩展了训练数据的模态多样性,并可以有效应对实际场景中多种数据中某些模态的缺失。
5.Pre-training Tasks
预训练分为两个阶段:
-
第一阶段是粗粒度情感感知预训练(coarse-grained emotion perception pre-training),包括掩码上下文建模、情感极性预测和粗粒度标签对比学习。第一阶段是为了让模型获得初步的情感分类能力。(情感是极性不变,组合具有相同情感极性的查询(即相同情感极性的样本)不会改变两者。因此,根据情感极性将所有数据集划分为不同的数据池。然后,我们从同一个数据池中随机抽取两个查询组合成一个新的查询,用于预训练阶段一)
L s t a g e 1 = L M C M + L S P P + L C C L . \mathcal{L}_{stage1}=\mathcal{L}_{MCM}+\mathcal{L}_{SPP}+\mathcal{L}_{CCL}. Lstage1=LMCM+LSPP+LCCL. -
第二阶段是细粒度情感感知预训练(Pre-training Stage Two),包括掩码上下文建模和跨任务情感预测。其目的是让模型获得细粒度情感分类能力。
L s t a g e 2 = L M C M + L C E P . \mathcal{L}_{stage2}=\mathcal{L}_{MCM}+\mathcal{L}_{CEP}. Lstage2=LMCM+LCEP.
5.1Mask Context Modeling
掩码上下文建模(MCM)可以随机掩码输入的文本、声学、视觉和上下文模态中的标记,以鼓励模型学习预测被掩码的标记(token)。

L M C M ( θ ) = − ∑ m = 1 M log ( P θ ( w m ∣ w n ) ) , \mathcal{L}_{MCM}(\theta)=-\sum_{m=1}^M\log{(P_\theta(w_m|w_n))}, LMCM(θ)=−m=1∑Mlog(Pθ(wm∣wn)),
| 符号 | 含义 |
|---|---|
| 1 ≤ m ≤ M 1\le m \le M 1≤m≤M | 表示掩码索引,M是掩码标记的数量 |
| w m w_m wm | 被屏蔽的token |
| w n w_n wn | 未被屏蔽的token |
| P θ P_\theta Pθ | 模型的输出分布, θ \theta θ代表可以优化的模型参数 |
5.2Sentiment Polarity Prediction
为了鼓励模型学习区分不同的情感类别,将数据集的细粒度情感标签转换为情感极性标签,将其映射为正面、负面和中性类别。然后,在情感极性预测(SPP)任务中,训练模型预测输入的情感极性类别。
L S P P ( θ ) = − log ( P θ ( s ∣ w n ) ) . \mathcal{L}_{SPP}(\theta)=-\log{(P_{\theta}(s|w_{n}))}. LSPP(θ)=−log(Pθ(s∣wn)).
5.3Coarse-grained Label Contrast Learning
在粗粒度对比学习任务中,将编码器的输出作为每个样本的表征,并在一个批次中计算具有相同情感标签的样本之间的欧氏距离。然后,最大化具有相同情感标签的样本之间的相似性。(让模型学会区分不同的情感类别)

L C C L ( θ ) = ∑ j = 1 b ∑ k = 1 b ( d i s t a n c e ( j , k ) ∗ m a s k ( j , k ) ) ∑ k = 1 b d i s t a n c e ( j , k ) , \mathcal{L}_{CCL}(\theta)=\sum_{j=1}^b\frac{\sum_{k=1}^b(distance(j,k)*mask(j,k))}{\sum_{k=1}^bdistance(j,k)}, LCCL(θ)=j=1∑b∑k=1bdistance(j,k)∑k=1b(distance(j,k)∗mask(j,k)),
| 符号 | 含义 |
|---|---|
| b b b | 一个批次的大小 |
| d i s t a n c e ( j , k ) distance(j,k) distance(j,k) | 样本j和样本k之间的欧氏距离 |
| m a s k ( j , k ) mask(j,k) mask(j,k) | 当样本j和样本k具有相同的情感标签时, m a s k ( j , k ) mask( j , k) mask(j,k)为1,否则为0 |
5.4Cross-task Emotion Prediction
在跨任务情感预测(CEP )任务中,首先将编码器的输出作为每个样本的表征,并对每个子任务的样本进行聚类(每个子任务不同的标签将聚成一类)。然后,对于每个样本,计算其表征与每个子任务的每个标签簇之间的距离。将距离最小的簇对应的标签作为每个子任务样本的伪标签。
给定一个子任务集 D = { A B S A , M S A , E R C , C A } D=\lbrace ABSA,MSA,ERC,CA \rbrace D={ABSA,MSA,ERC,CA},每个样本输出将有4个标签:一个为原始标签,三个为跨任务伪标签。
L C E P ( θ ) = − ∑ D log ( P θ ( E d ∣ w m ) ) , \mathcal{L}_{CEP}(\theta)=-\sum^D\log{(P_\theta(E_d|w_m))}, LCEP(θ)=−∑Dlog(Pθ(Ed∣wm)),
E d E_d Ed表示子任务 d ∈ D d\in D d∈D中的情感标签。
结果与讨论
⚠ 斜体是消融实验
- UniSA模型在每个数据集上的表现与现有的SOTA模型相当,并且可以用相对较少的参数执行所有的情感分析子任务。
- 将提出的任务特定提示方法替换为任务令牌,证明了任务特定提示方法对模型性能的影响。
- 去掉模态掩码训练方法,验证了模态掩码的有效性。
- 通过引入了三个额外的LSTM作为音频、图像和上下文输入的编码器,探索不同输入形式对模型性能的影响,证明了Multimodal transformer encoder的有效性。
- 通过消融预训练的第一阶段与第二阶段,证明了各个预训练阶段的有效性。
- 通过从多模态信号中剔除声学和视觉模态,验证了多模态对模型性能的影响。
- 通过在情感分析的下游任务上进行实验,表明UniSA在预训练阶段学习到了跨子任务的共同情感知识,从而在不同的情感分析子任务上表现出良好的泛化性。
代码和数据集
代码:https://github.com/dawn0815/UniSA
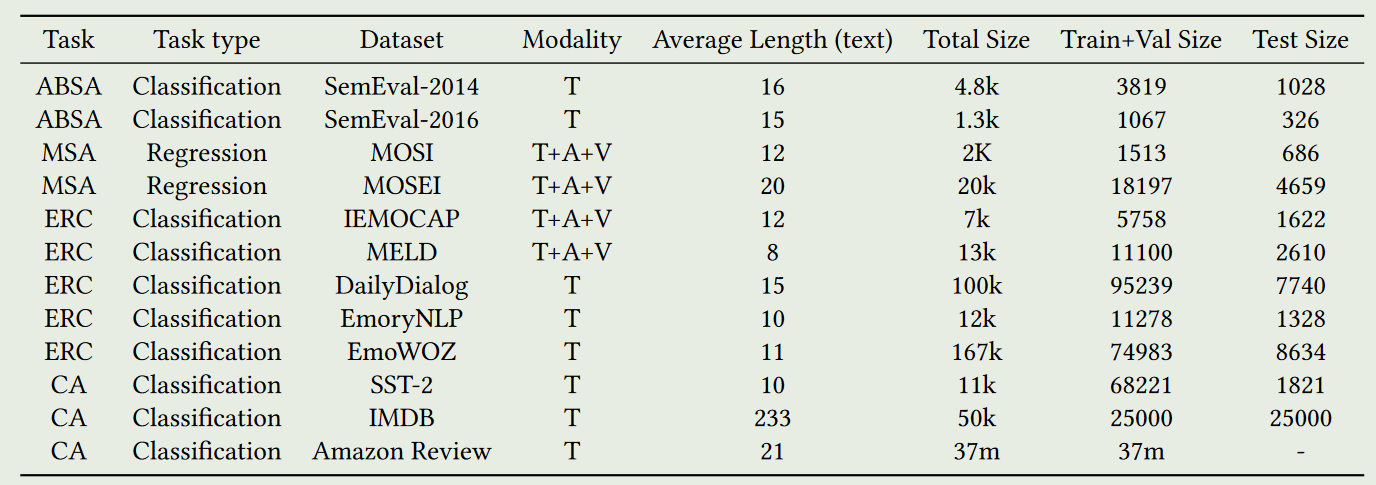
数据集:
实验环境:NVIDIA RTX V100(32G)
😃😃😃