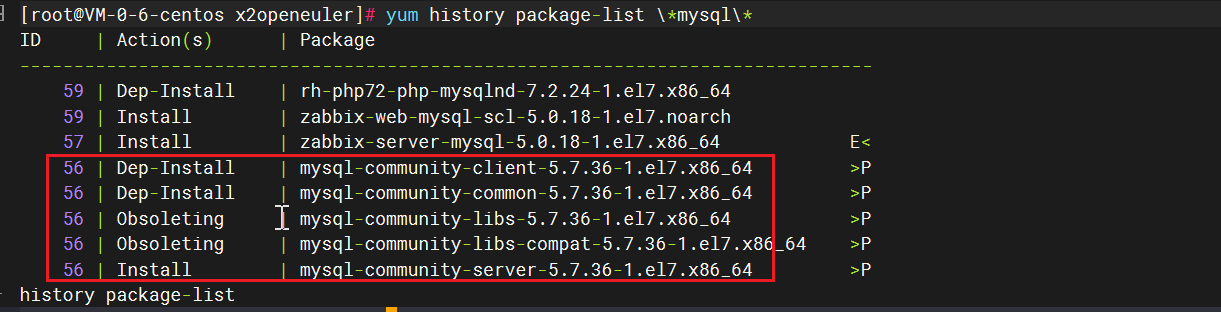
以下是对 MySQL 中这些重要概念的详细整理:
1. Delete、Drop 和 Truncate
- Delete
- 概念:是一条 DML(数据操作语言)语句,用于删除表中的一行或多行数据。它逐行删除数据,并且会触发相应的事务日志记录,支持使用
WHERE子句来指定删除条件。 - 示例:
DELETE FROM students WHERE age > 20;该语句会删除students表中年龄大于 20 的所有记录。
- 概念:是一条 DML(数据操作语言)语句,用于删除表中的一行或多行数据。它逐行删除数据,并且会触发相应的事务日志记录,支持使用
- Drop
- 概念:是一条 DDL(数据定义语言)语句,用于删除数据库、表、视图等数据库对象。执行
DROP操作后,该对象及其所有相关的数据和结构信息都会被永久删除,无法恢复。 - 示例:
DROP TABLE students;此语句会删除students表及其所有数据。
- 概念:是一条 DDL(数据定义语言)语句,用于删除数据库、表、视图等数据库对象。执行
- Truncate
- 概念:也是一条 DDL 语句,用于快速清空表中的所有数据。与
DELETE不同,TRUNCATE操作不会逐行删除数据,而是直接释放表所占用的数据页,因此速度通常比DELETE快。但它不能使用WHERE子句指定删除条件。 - 示例:
TRUNCATE TABLE students;会清空students表中的所有数据。
- 概念:也是一条 DDL 语句,用于快速清空表中的所有数据。与
2. MyISAM 与 InnoDB
- MyISAM
- 概念:是 MySQL 早期的一种存储引擎,不支持事务、外键,只支持表级锁。它的索引和数据是分开存储的,在处理大量读操作时性能较好,但在写操作时可能会因为表级锁而导致并发性能下降。
- 适用场景:适用于对事务要求不高、读多写少的场景,如日志记录、数据仓库等。
- InnoDB
- 概念:是 MySQL 5.5 版本之后的默认存储引擎,支持事务、外键和行级锁。它采用聚簇索引的方式存储数据,索引和数据是存储在一起的,因此在处理并发事务和写操作时性能较好。
- 适用场景:适用于对事务要求较高、读写操作较为频繁的场景,如在线交易系统、用户信息管理系统等。
3. Join 语句
- 概念:用于将多个表中的数据根据指定的条件进行连接,从而获取更全面的信息。常见的
JOIN类型有内连接(INNER JOIN)、左连接(LEFT JOIN)、右连接(RIGHT JOIN)和全连接(FULL JOIN,MySQL 中使用UNION模拟)。 - 示例
- 内连接:
SELECT * FROM students INNER JOIN scores ON students.id = scores.student_id;该语句会返回students表和scores表中id和student_id相等的所有记录。 - 左连接:
SELECT * FROM students LEFT JOIN scores ON students.id = scores.student_id;会返回students表中的所有记录,以及与之匹配的scores表中的记录,如果没有匹配的记录,scores表的字段值为NULL。
- 内连接:
4. 分页查询优化
- 概念:在处理大量数据时,为了减少单次查询的数据量,提高查询性能,通常会采用分页查询的方式。但当分页到较深的页码时,查询性能可能会下降,因此需要进行优化。
- 优化方法
- 使用索引:确保查询语句中涉及的列有索引,例如
LIMIT语句中的排序字段。 - 记录上次查询的最大 ID:通过记录上次查询的最大 ID,下次查询时直接从该 ID 之后开始查询,避免从表的开头开始扫描。
- 示例:
- 使用索引:确保查询语句中涉及的列有索引,例如
-- 普通分页查询
SELECT * FROM students LIMIT 10000, 10;
-- 优化后的分页查询
SELECT * FROM students WHERE id > 10000 LIMIT 10;
5. 事务
- 概念:是一组不可分割的数据库操作序列,这些操作要么全部成功执行,要么全部失败回滚。事务可以保证数据的一致性和完整性。
- 示例:
START TRANSACTION;
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
COMMIT; -- 如果执行过程中出现错误,可使用 ROLLBACK 回滚事务
6. ACID
- 概念:是事务的四个特性,确保数据库事务处理的可靠性。
- 原子性(Atomicity):事务中的所有操作要么全部成功,要么全部失败回滚,就像一个不可分割的原子一样。
- 一致性(Consistency):事务执行前后,数据库的状态必须保持一致,即数据的完整性约束不能被破坏。
- 隔离性(Isolation):多个事务之间相互隔离,一个事务的执行不会受到其他事务的干扰。
- 持久性(Durability):一旦事务提交,其对数据库的修改将永久保存,即使系统出现故障也不会丢失。
7. 数据并发产生的问题
- 脏读(Dirty Read):一个事务读取了另一个未提交事务修改的数据。例如,事务 A 修改了某条记录但未提交,事务 B 读取了该修改后的数据,随后事务 A 回滚,导致事务 B 读取的数据是无效的。
- 不可重复读(Non - Repeatable Read):在一个事务中,多次读取同一数据却得到不同的结果。例如,事务 A 第一次读取某条记录,然后事务 B 修改了该记录并提交,事务 A 再次读取该记录时得到了不同的值。
- 幻读(Phantom Read):在一个事务中,按照相同的查询条件多次查询,却发现查询结果的数量发生了变化。例如,事务 A 第一次查询满足某个条件的记录有 10 条,然后事务 B 插入了一条满足该条件的记录并提交,事务 A 再次查询时发现有 11 条记录。
8. 事务隔离级别
- 读未提交(Read Uncommitted):允许一个事务读取另一个未提交事务修改的数据,会出现脏读、不可重复读和幻读问题。
- 读已提交(Read Committed):一个事务只能读取另一个已提交事务修改的数据,避免了脏读,但仍可能出现不可重复读和幻读问题。
- 可重复读(Repeatable Read):在一个事务中,多次读取同一数据的结果是一致的,避免了脏读和不可重复读,但仍可能出现幻读问题。
- 串行化(Serializable):所有事务依次顺序执行,避免了脏读、不可重复读和幻读问题,但并发性能最差。
9. MySQL 默认隔离级别为什么是可重复读(RR)
- 数据一致性和并发性能的平衡:可重复读隔离级别在保证数据一致性的同时,也能提供较好的并发性能。它避免了脏读和不可重复读问题,在大多数业务场景下可以满足数据一致性的要求,同时又不会像串行化隔离级别那样严重影响并发性能。
- MVCC 机制的支持:MySQL 的 InnoDB 存储引擎在可重复读隔离级别下使用了 MVCC(多版本并发控制)机制,通过维护数据的多个版本,使得事务可以在不锁定数据的情况下实现可重复读,提高了并发性能。
10. 为什么大家将隔离级别设为读已提交(RC)
- 减少锁的持有时间:读已提交隔离级别下,事务只在读取数据时持有锁,读取完成后立即释放锁,减少了锁的持有时间,从而提高了并发性能。
- 避免长事务的影响:在一些业务场景中,长事务可能会导致大量的锁等待和性能问题。读已提交隔离级别可以减少长事务对其他事务的影响,提高系统的整体性能。
- 对幻读的容忍度:在某些业务场景下,幻读问题并不是非常严重,对数据的一致性影响较小,因此可以选择读已提交隔离级别来提高并发性能。
11. 事务实现原理
- 日志机制:MySQL 使用重做日志(Redo Log)和回滚日志(Undo Log)来实现事务的原子性和持久性。重做日志记录了事务对数据库的修改操作,当系统崩溃时,可以通过重做日志将未完成的事务重新执行;回滚日志记录了事务修改前的数据,当事务需要回滚时,可以通过回滚日志将数据恢复到修改前的状态。
- 锁机制:通过锁机制来实现事务的隔离性,确保多个事务之间相互隔离,避免数据冲突。例如,行级锁和表级锁可以控制对数据的并发访问。
12. MVCC(多版本并发控制)
- 概念:是一种用于提高数据库并发性能的技术,通过维护数据的多个版本,使得不同事务可以同时访问数据的不同版本,从而避免了锁的竞争,提高了并发性能。
13. 快照读与当前读
- 快照读:是一种基于 MVCC 的读操作,它读取的是数据的快照版本,而不是最新版本。在可重复读隔离级别下,一个事务中的所有快照读操作都会读取事务开始时的数据快照,从而实现可重复读。例如,
SELECT语句默认是快照读。 - 当前读:读取的是数据的最新版本,会对读取的数据加锁,以保证数据的一致性。例如,
SELECT ... FOR UPDATE、INSERT、UPDATE、DELETE等语句都是当前读。
14. Undo Log 版本链
- 概念:InnoDB 存储引擎通过 Undo Log 来记录数据的旧版本,每个数据行的多个旧版本通过指针连接成一个版本链。当一个事务需要读取数据时,会根据事务的隔离级别和版本链来确定读取哪个版本的数据。
15. ReadView
- 概念:是 MVCC 中的一个重要概念,它是一个事务在执行快照读操作时生成的一个视图,用于判断哪些版本的数据对当前事务是可见的。ReadView 包含了当前活跃事务的信息,通过比较事务 ID 和 ReadView 中的信息,可以确定数据的可见性。
16. MVCC 整体操作流程
- 当一个事务开始时,会生成一个唯一的事务 ID。
- 当执行快照读操作时,会生成一个 ReadView。
- 从数据的版本链中找到满足 ReadView 可见性条件的版本,并返回给事务。
17. MVCC 幻读被彻底解决了嘛
- 在 MySQL 的可重复读隔离级别下,MVCC 并没有彻底解决幻读问题。虽然 MVCC 可以保证快照读的一致性,避免了不可重复读问题,但对于当前读操作,仍然可能会出现幻读问题。例如,在一个事务中,第一次使用当前读查询满足某个条件的记录有 10 条,然后另一个事务插入了一条满足该条件的记录并提交,当该事务再次使用当前读查询时,会发现有 11 条记录,这就是幻读问题。为了解决幻读问题,可以使用串行化隔离级别或者使用间隙锁。
18. 索引
- 概念:是一种数据库对象,用于提高数据库查询的性能。它通过对表中的某些列建立索引结构,使得数据库可以更快地定位到满足查询条件的数据行,而不需要全表扫描。
- 常见类型
- 普通索引:最基本的索引类型,没有任何限制。例如,
CREATE INDEX idx_name ON students(name); - 唯一索引:要求索引列的值必须唯一,但允许有空值。例如,
CREATE UNIQUE INDEX idx_email ON students(email); - 主键索引:是一种特殊的唯一索引,不允许有空值,每个表只能有一个主键索引。例如,在创建表时指定
id为主键:CREATE TABLE students (id INT PRIMARY KEY, name VARCHAR(50)); - 全文索引:用于在文本类型的列上进行全文搜索。例如,
CREATE FULLTEXT INDEX idx_content ON articles(content);
- 普通索引:最基本的索引类型,没有任何限制。例如,
通过以上对 MySQL 各个概念的详细解释和示例说明,你可以更全面地理解 MySQL 的工作原理和使用方法。
索引讲解:
好的,我将详细讲解 MySQL 索引的核心概念、作用、类型、使用场景及优化技巧,结合例子说明:
一、索引是什么?
作用:
索引是数据库中用于快速定位数据的“数据结构”,类似于书籍的目录。通过索引,查询可以直接定位到目标数据,避免全表扫描。
类比:
想象在图书馆找书:
- 无索引:逐行查看每本书的标题(全表扫描)。
- 有索引:通过书名目录直接找到对应书架(索引查询)。
二、索引的优缺点
优点:
- 加速查询:减少磁盘 I/O,提升查询速度。
- 强制唯一性:唯一索引(如主键)可保证数据唯一性。
缺点:
- 存储空间开销:索引本身需要额外存储。
- 写入性能下降:插入、更新、删除时需维护索引。
三、索引的类型
1. B-tree 索引(最常用)
- 结构:类似多层目录,每层节点存储索引值和指针。
- 适用场景:
- 等值查询(如
WHERE id=10)。 - 范围查询(如
WHERE age>20)。 - 排序和分组(如
ORDER BY name)。
- 等值查询(如
2. 哈希索引
- 结构:通过哈希函数将索引值映射到哈希表。
- 适用场景:
- 等值查询(如
WHERE status=1)。
- 等值查询(如
- 缺点:无法处理范围查询和排序。
3. 全文索引
- 作用:用于全文搜索(如文章内容、评论)。
- 适用场景:
MATCH AGAINST语法。
4. 覆盖索引
- 作用:查询所需的所有数据都包含在索引中,无需回表。
- 示例:
CREATE INDEX idx_user_email ON user(email); -- 查询 email 时直接命中索引,无需访问数据行。 SELECT email FROM user WHERE email='test@example.com';
5. 复合索引
- 作用:多个字段组合的索引。
- 规则:
- 遵循“最左匹配原则”。
- 优先将查询条件中最常用的字段放在前面。
- 示例:
CREATE INDEX idx_order_user_status ON order(user_id, status); -- 可加速以下查询: SELECT * FROM order WHERE user_id=100 AND status=2; SELECT * FROM order WHERE user_id=100; -- 部分匹配
四、索引的使用场景
- 经常查询的字段:如
WHERE、JOIN、ORDER BY涉及的字段。 - 唯一性约束:如主键、唯一标识(如身份证号)。
- 数据量大的表:小表全表扫描更快,无需索引。
五、如何创建索引?
-- 单列索引
CREATE INDEX idx_user_age ON user(age);-- 唯一索引
CREATE UNIQUE INDEX idx_user_email ON user(email);-- 复合索引
CREATE INDEX idx_order_user_status ON order(user_id, status);-- 主键自动创建索引
CREATE TABLE user (id INT PRIMARY KEY AUTO_INCREMENT,name VARCHAR(50)
);
六、索引优化技巧
1. 分析查询计划
使用 EXPLAIN 查看索引是否被命中:
EXPLAIN SELECT * FROM user WHERE age=25;
- 关键指标:
key:显示使用的索引。rows:扫描的行数(越小越好)。
2. 避免索引失效
- 错误写法:
SELECT * FROM user WHERE LEFT(name, 3)='Tom'; -- 函数导致索引失效 SELECT * FROM user WHERE age+1=25; -- 计算导致索引失效 SELECT * FROM user WHERE name LIKE '%test'; -- 前缀模糊查询(索引部分失效) - 正确写法:
SELECT * FROM user WHERE name LIKE 'test%'; -- 后缀模糊查询(索引有效)
3. 选择合适字段
- 避免对低选择性字段加索引(如性别字段,只有男/女)。
- 优先对高选择性字段加索引(如身份证号)。
4. 分页查询优化
- 问题:
LIMIT 1000000, 10会导致全表扫描。 - 优化:利用索引覆盖,记录最后一条数据的位置:
SELECT * FROM user WHERE id > 1000000 LIMIT 10; -- 假设 id 是主键
七、索引的维护
- 定期重建索引:
ALTER TABLE user REBUILD INDEX idx_user_age; - 分析索引使用情况:
SHOW INDEX_STATISTICS FROM user;
八、总结
- 索引是数据库性能的关键,但需权衡查询速度与写入开销。
- 合理设计复合索引,遵循“最左匹配原则”。
- 避免过度索引,定期分析和优化。
通过以上方法,可以显著提升 MySQL 的查询效率。
为什么使用 B+ 树而不使用跳表?
在数据库索引中,B+树被广泛使用而跳表(Skip List)较少被采用,主要原因在于两者的设计目标和适用场景不同。以下是详细对比:
1. 磁盘访问效率
- B+树
- 按块存储:B+树的每个节点对应一个磁盘块(通常为4KB或8KB),通过一次I/O读取整个节点,大幅减少磁盘随机访问次数。
- 高扇出:B+树的节点存储大量键值(如3阶B+树每个非叶子节点最多存3个键),树的高度低(例如百万级数据仅需3层),查询时I/O次数少。
- 跳表
- 链式结构:跳表的每个节点通过指针连接,数据分布在不同内存或磁盘位置,随机访问时需要多次I/O,效率较低。
- 内存友好:跳表更适合内存数据库(如Redis的有序集合),但在磁盘存储场景下性能劣势明显。
2. 范围查询支持
- B+树
- 叶子节点链表:B+树的叶子节点通过双向链表连接,范围查询(如
BETWEEN)可直接遍历链表,时间复杂度为O(n)。
- 叶子节点链表:B+树的叶子节点通过双向链表连接,范围查询(如
- 跳表
- 逐层遍历:跳表需要从最高层逐步向下查找范围,虽然时间复杂度也是O(log n),但实际效率低于B+树的线性遍历。
3. 数据存储密度
- B+树
- 非叶子节点无数据:非叶子节点仅存储键,叶子节点存储数据,减少了冗余存储,提高磁盘利用率。
- 跳表
- 每个节点存键和数据:跳表的每个节点(包括高层索引)都存储完整键值对,占用更多空间,尤其在磁盘存储时会增加I/O成本。
4. 并发控制
- B+树
- 细粒度锁:数据库可通过行锁、页锁等机制对B+树的局部节点加锁,减少并发冲突。
- 跳表
- 锁粒度大:跳表的插入、删除可能需要锁定多个节点或整个链表,并发性能较差。
5. 实现复杂度
- B+树
- 复杂:需处理节点分裂、合并、平衡调整等操作,实现难度高。
- 跳表
- 简单:代码量少,易于实现和调试,适合内存场景(如Redis)。
总结:为何选择B+树?
- 磁盘友好:B+树的设计天生适合磁盘存储,通过减少I/O次数提升性能。
- 范围查询高效:链表结构让范围查询更直接。
- 稳定性:平衡树结构保证查询时间复杂度稳定,适合大规模数据。
- 数据库特性适配:支持事务、锁机制、MVCC等复杂数据库功能。
跳表的适用场景
- 内存数据库:如Redis的有序集合,利用跳表的快速插入/删除和简单实现。
- 小规模数据:当数据量较小时,跳表的内存访问优势明显。
- 需要快速实现:跳表代码简单,适合对性能要求不极端的场景。
示例对比
假设数据库中有1000万条用户记录,按年龄建立索引:
- B+树:通过3层节点即可完成查询,每次查询仅需3次I/O。
- 跳表:需逐层遍历,且每个节点可能分布在不同磁盘块,I/O次数显著增加。
因此,B+树在磁盘存储和大规模数据场景下更具优势,而跳表在内存场景中更受欢迎。
为什么 Redis 有序集合底层选择跳表而非 B+树
Redis 的有序集合(Sorted Set)底层选择跳表(Skip List)而非 B+树,主要是基于内存存储特性、操作复杂度和场景需求的权衡。以下是详细分析:
1. 内存访问 vs 磁盘访问
-
Redis 的内存特性
Redis 是纯内存数据库,所有操作均在内存中完成,无需考虑磁盘 I/O 优化。- 跳表优势:跳表的链式结构在内存中可通过指针直接访问,无需按块读取,内存访问效率极高。
- B+树劣势:B+树的磁盘友好设计(如按块存储、高扇出)在内存场景下失去意义,反而增加了结构复杂度。
-
对比 MySQL
MySQL 是磁盘数据库,B+树的设计目标是减少磁盘 I/O(如一次 I/O 读取一个节点),而 Redis 无需此优化。
2. 操作复杂度与实现成本
-
跳表的简洁性
- 插入/删除:跳表的插入和删除只需修改局部指针,时间复杂度为 O(log n),且无需平衡树的旋转操作(如 B+树的节点分裂/合并)。
- 代码实现:跳表的代码量远少于 B+树,Redis 开发者更倾向于选择易于实现和维护的结构。
-
B+树的复杂性
- B+树需处理节点分裂、合并、平衡调整等复杂逻辑,实现难度高。
- Redis 作为高性能键值存储,需最小化代码复杂度以提升运行效率。
3. 并发控制需求
- Redis 的单线程模型
Redis 核心操作是单线程的(仅在 6.0+ 引入多线程 I/O 处理),无需考虑多线程并发冲突。- 跳表优势:单线程下跳表的操作无需加锁,直接通过指针修改即可,性能更优。
- B+树劣势:B+树的复杂结构在多线程环境下需精细锁控制(如行锁、页锁),但 Redis 单线程模型下此优势无用武之地。
4. 数据规模与操作类型
-
有序集合的典型场景
Redis 有序集合常用于实时排行榜、带权重的消息队列等场景,数据量通常较小(如百万级)。- 跳表优势:对于小规模数据,跳表的内存访问效率和代码简洁性更具优势。
- B+树劣势:B+树的高扇出设计在数据量较小时可能导致空间浪费(如每个节点存储大量键值)。
-
范围查询的优化
- 跳表的范围查询(如
ZRANGE)可通过层级遍历实现,虽然时间复杂度为 O(log n + k)(k 为返回元素数量),但在内存中实际性能足够。 - B+树的叶子链表虽然支持范围查询,但需额外维护链表结构,复杂度更高。
- 跳表的范围查询(如
5. 内存空间占用
- 跳表的内存开销
跳表的每个节点包含多个层级的指针(如 Redis 的跳表节点默认最多 64 层),可能占用更多内存。- Redis 的权衡:Redis 内存通常充足,且有序集合的数据量相对较小,内存开销可接受。
- 对比磁盘场景:若使用 B+树,非叶子节点不存储数据,空间利用率更高,但 Redis 无需此优化。
总结:Redis 选择跳表的原因
| 因素 | 跳表 | B+树 |
|---|---|---|
| 存储介质 | 内存友好,直接指针访问 | 磁盘友好,减少 I/O 次数 |
| 实现复杂度 | 代码简单,易于维护 | 复杂,需处理平衡调整 |
| 并发控制 | 单线程无锁操作 | 需精细锁机制(多线程场景) |
| 数据规模 | 适合中小规模数据 | 适合大规模磁盘数据 |
| 操作类型 | 快速插入/删除,简单范围查询 | 高效范围查询,稳定性强 |
为什么 MySQL 不用跳表?
- MySQL 是磁盘数据库:跳表的链式结构导致多次磁盘 I/O,无法满足性能需求。
- MySQL 数据规模大:B+树的高扇出和平衡特性更适合处理千万级以上数据。
- 事务与锁机制:B+树更易于支持事务、MVCC 等复杂功能。
Redis 跳表的优化
Redis 的跳表实现针对内存场景做了以下优化:
- 分层概率控制:节点层级随机生成,概率为 1/2,避免极端层级导致性能下降。
- 双向链表:叶子节点通过双向链表连接,支持快速前驱/后继查询。
- 结合哈希表:有序集合底层同时使用跳表和哈希表,实现 O(1) 时间复杂度的
ZSCORE操作。
结论
Redis 选择跳表而非 B+树,是因为跳表在内存环境下的高效性、实现简单性以及与单线程模型的完美适配。而 B+树更适合磁盘存储和大规模数据场景(如 MySQL)。数据结构的选择始终取决于具体场景需求,而非绝对优劣。
为什么建议使用自增 ID 为主键
在数据库设计中,建议使用自增 ID 作为主键的原因主要基于唯一性、性能优化、索引效率和数据管理便利性。以下是详细分析:
1. 确保唯一性
- 自动生成机制
自增 ID 由数据库自动生成,确保每条记录的主键唯一,避免手动维护业务字段(如订单号、用户名)作为主键时可能出现的重复风险。 - 无需额外校验
数据库引擎(如 InnoDB)会隐式保证自增 ID 的唯一性,无需应用层编写复杂的唯一性校验逻辑。
2. 提升插入性能
- 顺序写入特性
InnoDB 引擎的主键是聚簇索引,数据按主键顺序存储。自增 ID 插入时是顺序递增的,数据会追加到当前索引页的末尾,减少页分裂(Page Split)的概率,提升写入性能。 - 对比 UUID
UUID 是随机的 128 位值,插入时会分散在不同索引页,导致频繁的页分裂和磁盘 I/O,显著降低写入效率。
3. 优化索引结构
- 整数类型优势
自增 ID 通常为整数,占用空间小(如BIGINT仅需 8 字节),且整数比较速度比字符串(如 UUID)或复合字段更快。 - 减少索引层级
B+ 树索引的层高与键值大小相关。较小的自增 ID 可减少索引层级,加快查询速度。
4. 简化外键约束
- 外键存储高效
外键引用自增 ID 时,存储的是整数而非业务字段(如用户 ID 而非用户名),节省存储空间并提升连接查询效率。 - 避免业务逻辑耦合
业务字段的变更(如用户修改用户名)不会影响主键,减少外键关联的维护成本。
5. 支持快速删除与重建
- 逻辑删除优化
若需删除大量数据(如归档旧记录),自增 ID 可快速定位连续区间,批量删除效率更高。 - 表重建便捷
当表结构变更(如添加字段)时,自增 ID 无需调整,避免业务主键可能引发的冲突。
6. 扩展性与兼容性
- 适应大数据量
自增 ID 的范围足够大(如BIGINT可支持约 90 亿条记录),适用于大多数场景。 - 兼容 ORM 框架
主流 ORM 框架(如 Hibernate、MyBatis)默认支持自增主键,简化开发流程。
例外场景与替代方案
- 分布式系统
- 自增 ID 在分布式环境下可能冲突,需使用雪花算法(Snowflake)或 UUID 等分布式 ID 生成方案。
- 业务字段天然唯一
- 若业务字段(如身份证号)具有强唯一性且不可变,可作为主键(需确保查询性能)。
- 高并发写入
- 自增 ID 可能导致锁竞争(如 InnoDB 的
auto-increment锁),可通过调整innodb_autoinc_lock_mode优化。
- 自增 ID 可能导致锁竞争(如 InnoDB 的
总结:自增 ID 的核心优势
| 维度 | 自增 ID | 业务字段/UUID |
|---|---|---|
| 唯一性 | 自动保证,无冲突风险 | 需应用层校验,复杂度高 |
| 写入性能 | 顺序写入,减少页分裂 | 随机写入,性能显著下降 |
| 索引效率 | 整数类型,索引层级少 | 字符串类型,占用空间大 |
| 维护成本 | 不可变,无需业务逻辑适配 | 业务变更可能引发主键修改 |
| 扩展性 | 支持海量数据,兼容性强 | 需特殊处理分布式场景 |
为什么 MySQL 默认推荐自增 ID?
- InnoDB 引擎特性:自增 ID 与聚簇索引的顺序写入机制高度契合。
- 历史实践验证:自增 ID 在传统关系型数据库中已被证明是稳定、高效的主键设计。
结论
自增 ID 是数据库主键的最优实践,尤其适用于单实例、业务字段无天然唯一性的场景。在分布式系统或特殊业务需求下,可选择其他方案,但需谨慎权衡性能与复杂度。
什么是索引下推ICP
索引下推(Index Condition Pushdown,ICP)是 MySQL 数据库的一项优化技术,用于在使用索引时减少回表次数,从而提升查询性能。以下是关于 ICP 的详细解析:
1. 核心原理
- 索引过滤前置
在传统查询流程中,存储引擎通过索引定位到数据行后,需将整行数据回表到主存储(如 InnoDB 的聚簇索引)进行过滤。ICP 允许存储引擎在索引遍历阶段提前过滤部分条件,减少不必要的回表操作。 - 条件拆分
将查询条件分为两部分:- 索引可过滤条件:与索引列相关的条件(如
WHERE a=1 AND b>2中的a=1)。 - 回表后过滤条件:与非索引列或需更复杂判断的条件(如
c='test')。
- 索引可过滤条件:与索引列相关的条件(如
2. 工作流程
以 SELECT * FROM table WHERE a=1 AND b>2 AND c='test' 为例(假设索引为 (a, b)):
- 传统流程
- 存储引擎通过索引找到所有
a=1的条目,回表读取完整数据行。 - 在主存储中过滤
b>2和c='test'的条件。
- 存储引擎通过索引找到所有
- ICP 优化后流程
- 存储引擎在索引遍历阶段,先过滤
a=1和b>2的条件。 - 仅对满足条件的索引条目回表,再过滤
c='test'。
- 存储引擎在索引遍历阶段,先过滤
3. 支持的存储引擎与版本
- 支持引擎:InnoDB、MyISAM(需 MySQL 5.6+)。
- 版本要求:MySQL 5.6 及以上版本默认启用。
- 禁用方式:通过
optimizer_switch变量关闭index_condition_pushdown。
4. 适用场景
- 复合索引场景:当查询条件包含索引的部分列时,ICP 可提前过滤部分条件。
- 范围查询优化:例如
WHERE a=1 AND b BETWEEN 10 AND 20,ICP 能在索引层过滤b的范围。 - 非覆盖索引查询:当查询需要回表获取非索引列时,ICP 可减少回表次数。
5. 优势与局限性
| 优势 | 局限性 |
|---|---|
| 减少 I/O 操作(回表次数) | 对覆盖索引查询无效 |
| 降低 CPU 消耗(减少数据处理) | 对等值查询优化效果有限 |
| 提升复杂查询性能 | 需索引列包含部分过滤条件 |
6. 验证是否启用 ICP
使用 EXPLAIN 命令查看执行计划:
EXPLAIN SELECT * FROM table WHERE a=1 AND b>2 AND c='test';
- 启用标志:
Extra列显示Using index condition。 - 未启用情况:若索引已覆盖所有条件(覆盖索引),则显示
Using index。
7. 示例对比
假设表 user 有索引 (age, name),查询 SELECT * FROM user WHERE age=20 AND name LIKE 'J%' AND email='xxx@example.com':
- 无 ICP:通过索引找到所有
age=20且name LIKE 'J%'的条目,回表后过滤email。 - 启用 ICP:在索引层过滤
age=20和name LIKE 'J%',仅对匹配的条目回表检查email。
8. 与其他优化的协同
- 覆盖索引:若查询条件完全包含在索引中,ICP 不会生效,但覆盖索引本身已避免回表。
- 索引条件优化:ICP 与
WHERE子句的条件下推结合,进一步减少数据处理量。
总结:何时使用 ICP?
- 推荐场景:非覆盖索引查询、复合索引过滤、范围查询。
- 不适用场景:覆盖索引查询、简单等值查询(如
a=1直接命中索引)。 - 最佳实践:在设计索引时,尽可能将常用过滤条件包含在索引中,以充分发挥 ICP 的优化效果。
通过合理利用 ICP,可显著提升 MySQL 查询性能,尤其在复杂条件和大数据量场景下效果更明显。
什么是索引合并
索引合并(Index Merge)是 MySQL 数据库的一种优化策略,用于在单个查询中同时利用多个索引的条件,通过合并多个索引的检索结果来提升查询效率。以下是关于索引合并的详细解析:
1. 核心原理
- 多索引协作
当查询条件涉及多个独立的索引列(如WHERE a=1 OR b=2,且a和b分别有索引),MySQL 可能通过索引合并策略:- 分别使用每个索引找到符合条件的行。
- 将这些结果合并(取交集、并集或排序合并),最终返回符合条件的数据。
- 适用场景
当单个索引无法覆盖所有查询条件,且多个索引的条件可以通过逻辑关系(如AND、OR)组合时。
2. 索引合并的类型
MySQL 支持三种索引合并策略:
(1)Intersection(交集合并)
- 适用条件:多个索引条件需同时满足(
AND逻辑)。 - 示例:
WHERE a=1 AND b=2,且a和b各有独立索引。 - 流程:
- 使用索引
a找到所有a=1的行。 - 使用索引
b找到所有b=2的行。 - 取两者的交集(同时满足
a=1和b=2的行)。
- 使用索引
(2)Union(并集合并)
- 适用条件:多个索引条件只需满足其一(
OR逻辑)。 - 示例:
WHERE a=1 OR b=2,且a和b各有独立索引。 - 流程:
- 使用索引
a找到a=1的行。 - 使用索引
b找到b=2的行。 - 合并两个结果集(去重)。
- 使用索引
(3)Sort-Union(排序并集合并)
- 适用条件:与 Union 类似,但结果需按主键排序。
- 优化点:通过预排序减少合并时的排序开销。
3. 工作流程
以 SELECT * FROM table WHERE a=1 OR b=2(a 和 b 有独立索引)为例:
- 传统流程:
- 若未使用索引合并,可能选择其中一个索引(如
a),扫描数据后回表过滤b=2,或直接全表扫描。
- 若未使用索引合并,可能选择其中一个索引(如
- 索引合并流程:
- 分别通过索引
a和b获取符合条件的行。 - 合并结果(去重并排序),减少全表扫描。
- 分别通过索引
4. 适用场景
- 多列独立索引:查询条件涉及多个独立索引列(如
a和b无关联)。 - 逻辑组合条件:条件包含
AND、OR或IN等逻辑操作符。 - 无法覆盖索引:单个索引无法覆盖所有查询条件,需回表多次。
5. 优势与局限性
| 优势 | 局限性 |
|---|---|
| 利用多个索引减少扫描量 | 合并操作可能增加 CPU 开销 |
| 避免全表扫描 | 对复合索引(如 (a,b))优化有限 |
| 适用于复杂条件组合 | 需 MySQL 5.0+ 版本支持 |
6. 验证是否启用索引合并
使用 EXPLAIN 命令查看执行计划:
EXPLAIN SELECT * FROM table WHERE a=1 OR b=2;
- 启用标志:
Extra列显示Using intersect(...)、Using union(...)或Using sort_union(...)。 - 未启用情况:若优化器选择全表扫描或单个索引,则不会出现上述提示。
7. 示例对比
假设表 user 有索引 (age) 和 (name),查询 SELECT * FROM user WHERE age=20 OR name='John':
- 无索引合并:可能选择
age索引,扫描后回表过滤name,或全表扫描。 - 启用索引合并:
- 通过
age索引找到age=20的行。
2.通过name索引找到name='John'的行。
3.合并结果集并去重。
- 通过
8. 与其他优化的协同
- 覆盖索引:若单个索引能覆盖所有查询条件,索引合并不会生效。
- 索引下推(ICP):索引合并与 ICP 可结合使用,进一步减少回表次数。
总结:何时使用索引合并?
- 推荐场景:
- 查询条件包含多个独立索引列的
AND/OR组合。 - 无法通过单个索引覆盖所有条件,且全表扫描成本高。
- 查询条件包含多个独立索引列的
- 不适用场景:
- 复合索引(如
(a,b))已覆盖所有条件。 - 合并操作的开销超过全表扫描。
- 复合索引(如
- 最佳实践:优先设计复合索引覆盖查询条件,索引合并作为补充优化手段。
合理使用索引合并可提升复杂查询性能,但需结合执行计划评估实际效果。
索引失效的情况有哪些
在数据库操作中,索引失效会使查询无法利用索引来提高效率,进而导致查询性能下降。以下是一些常见的导致索引失效的情况:
1. 对索引列进行函数操作
- 原因:对索引列使用函数会改变索引列的原始值,数据库无法直接通过索引定位数据,只能进行全表扫描。
- 示例:
-- 假设在age列上有索引
SELECT * FROM users WHERE YEAR(birth_date) = 1990;
上述查询中对 birth_date 列使用了 YEAR 函数,会导致索引失效。可以改为直接比较日期范围来使用索引:
SELECT * FROM users WHERE birth_date BETWEEN '1990-01-01' AND '1990-12-31';
2. 索引列上使用表达式计算
- 原因:对索引列进行表达式计算,如加减乘除等,会使数据库无法利用索引快速定位数据。
- 示例:
-- 假设在salary列上有索引
SELECT * FROM employees WHERE salary + 1000 > 5000;
这里对 salary 列进行了加法计算,导致索引失效。可以将表达式变形为 salary > 5000 - 1000 来使用索引。
3. 模糊查询以通配符开头
- 原因:当
LIKE查询以通配符%开头时,数据库无法通过索引确定匹配的起始位置,只能全表扫描。 - 示例:
-- 假设在name列上有索引
SELECT * FROM customers WHERE name LIKE '%Smith';
此查询会导致索引失效。若改为 LIKE 'Smith%',则可以使用索引。
4. 类型不匹配
- 原因:如果查询条件中的数据类型与索引列的数据类型不一致,数据库可能会进行隐式类型转换,从而导致索引失效。
- 示例:
-- 假设id列是整数类型且有索引
SELECT * FROM products WHERE id = '123';
这里将字符串类型的值与整数类型的索引列进行比较,会发生隐式类型转换,使索引失效。应确保查询条件的数据类型与索引列一致。
5. 复合索引不满足最左匹配原则
- 原因:对于复合索引,数据库会按照索引列的顺序依次使用索引。如果查询条件不满足最左匹配原则,就无法充分利用复合索引。
- 示例:
-- 假设创建了复合索引 (col1, col2, col3)
SELECT * FROM orders WHERE col2 = 'value2';
该查询没有从复合索引的最左列 col1 开始,会导致索引失效。如果查询条件为 WHERE col1 = 'value1' AND col2 = 'value2',则可以使用复合索引。
6. 使用 OR 连接索引列和非索引列
- 原因:当使用
OR连接索引列和非索引列时,数据库无法同时利用索引进行查询,通常会选择全表扫描。 - 示例:
-- 假设在col1列上有索引,col2列无索引
SELECT * FROM table_name WHERE col1 = 'value1' OR col2 = 'value2';
这种情况下,索引会失效。可以考虑将 OR 条件拆分成多个查询,使用 UNION 连接。
7. IS NULL 和 IS NOT NULL 操作
- 原因:部分情况下,数据库对于
IS NULL和IS NOT NULL操作无法有效使用索引。 - 示例:
-- 假设在email列上有索引
SELECT * FROM users WHERE email IS NULL;
不同数据库对于这种情况的处理不同,有些数据库可能会使用索引,有些则可能会全表扫描。
8. 统计信息不准确
- 原因:数据库的查询优化器会根据统计信息来选择执行计划。如果统计信息不准确,可能会导致优化器选择不使用索引。
- 解决方法:可以通过更新统计信息(如 MySQL 中的
ANALYZE TABLE语句)来解决。
9. 索引被禁用或损坏
- 原因:如果索引被手动禁用或者索引文件损坏,数据库将无法使用该索引。
- 解决方法:可以重新启用索引或重建索引来解决。
了解这些导致索引失效的情况,有助于在数据库设计和查询优化中避免这些问题,提高数据库的查询性能。
参考文档:https://www.cnblogs.com/zhzcc/p/18425960