U-Net网络结构讲解视频
从零开始的U-net入门
U-Net详解
研习U-Net改进
目录
一、介绍
二、详解
1、网络结构
2、网络运行过程
3、实验现状
4、分割策略
一、介绍
U-Net是一种用于生物医学图像分割的卷积神经网络架构。它由Olaf Ronneberger等人在2015年提出,并被广泛应用于医学图像分析领域。
U-Net的设计灵感来自于生物医学图像分割任务中常见的数据不平衡问题,即前景(感兴趣区域)与背景之间的像素数量差异很大。为了解决这个问题,U-Net使用了一种称为"U"形结构的编码-解码架构,其中编码器部分用于捕捉图像的上下文信息,而解码器部分用于恢复分辨率和帮助生成准确的分割结果。
U-Net的结构如下:
-
编码器:编码器由一系列的卷积层和下采样操作(通常是最大池化层)组成。这些层逐渐减小图像的分辨率和通道数,并且通过增加感受野来捕捉更广阔的上下文信息。
-
解码器:解码器由一系列的卷积层和上采样操作(通常是反卷积层)组成。这些层逐渐恢复图像的分辨率和通道数,并通过跳跃连接将编码器中的特征图与解码器中的特征图连接起来。跳跃连接有助于传递更详细的位置和上下文信息,以生成更准确的分割结果。
-
跳跃连接:跳跃连接是U-Net的关键特性。它将编码器中的特征图与解码器中的特征图进行连接,以便将局部和全局信息相结合。这种连接不仅有助于解决数据不平衡问题,还可以避免信息在编码器和解码器之间丢失。
-
输出层:U-Net的最后一层是一个卷积层,其输出大小与输入图像的大小相同,并将每个像素分配给前景或背景。通常使用Sigmoid或Softmax激活函数来生成分割预测。
U-Net在训练过程中使用像素级别的二分类交叉熵损失函数来衡量预测结果与真实标签之间的差异,并使用常见的优化算法(如Adam)对权重进行更新。在测试阶段,根据预测的概率值计算阈值,将概率大于阈值的像素标记为前景。
U-Net的主要优点是能够准确地捕捉图像的上下文信息,对于边界清晰、大小不一的前景物体进行准确的分割。然而,它也存在一些缺点,如对于小的前景物体分割不准确,对于噪声和伪影较敏感等。因此,在实际应用中,研究者们不断改进和优化U-Net的架构,以适应不同的医学图像分割任务。
二、详解
1、网络结构

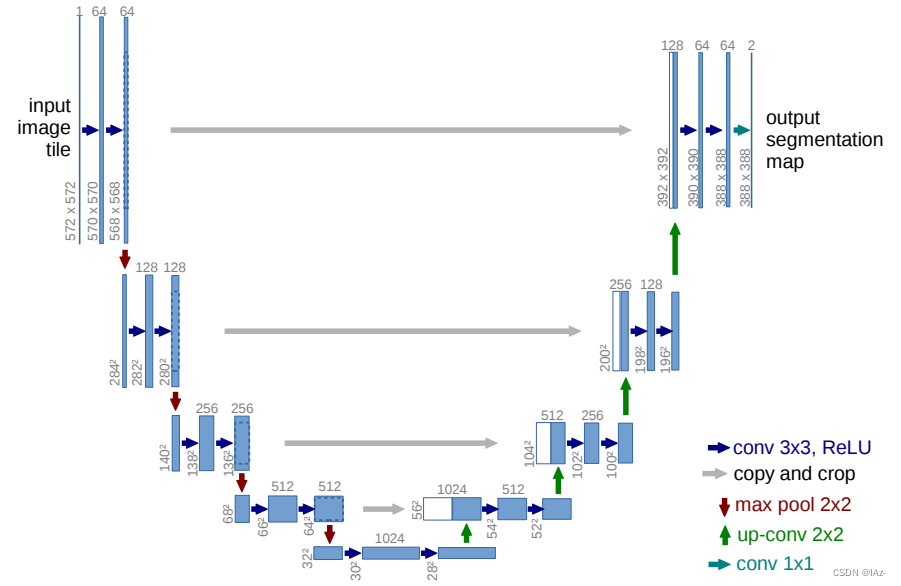
U-Net是Encoder-Decoder结构,对应于U型结构。Encoder对应于U型左边部分,也就是特征提取下采样部分,文中称之为contracting path;Decoder对应于U型右边部分,也就是上采样得到分割结果图的部分,文中称之为expansive path。
- 长条矩形对应一个特征图
- 箭头对应一种操作
2、网络运行过程
Encoder部分
从输入开始,输入[572x573x1]的图像,首先通过一个[3x3]卷积层和ReLu激活函数,这里的卷积层步距为1,padding为0,则通过卷积层之后高和宽都会减少。经过两个卷积层之后输出特征图为[568x568x64]。
之后通过一个Maxpool下采样,池化核大小为[2x2],步距为2,特征图的高和宽就会减半,从[568x568x64]变成[284x284x64],通道数不改变。再通过两个[3x3]卷积层,通过卷积层之后都会将特征图通道数×2,输出为[280x280x128]。
通过Maxpool下采样之后,特征图高和宽减半,变为[140x140x128],再经过两个卷积层缩小高和宽,将通道数翻倍,得到特征图[136x136x256]。
通过Maxpool下采样之后,得到特征图大小[68x68x256],经两次卷积操作得到特征图[66x66x512]。
最后一层里,通过下采样操作得到特征图[32x32x512],经两次卷积操作得到特征图[28x28x1024]。
Decoder部分
将Encoder部分得到的[28x28x1024]的特征图进行转置卷积上采样操作,转置卷积过后将特征图高和宽放大两倍,通道数会减半,得到特征图大小为[56x56x512]。注意:灰色箭头(copy and crop),表示将Encoder部分对应的特征图经由高宽裁剪之后,与Decoder部分下一层上采样得到的特征图按照通道维度Concat拼接。将Encoder部分对应的[64x64x512]的特征图进行中心裁剪,将中间[56x56x512]的部分裁剪过来,与Decoder上采样得到的蓝色部分[56x56x512]部分进行Concat拼接。拼接之后得到特征图[56x56x1024]。之后再进行两个卷积[3x3]卷积操作,得到[52x52x512]的特征图。
之后再通过上采样,将特征图的高和宽放大两倍,通道数减半,此时得到特征图[104x104x256],与Encoder部分对应的特征图进行中心裁剪,与上采样得到的特征图进行Concat拼接得到[104x104x512]的特征图。再通过两个[3x3]卷积层进一步融合,得到特征图大小[100x100x256]。
再进行上采样,特征图变成[200x200x128],Encoder对应特征图进行中心裁剪之后进行拼接,得到特征图[200x200x256]。经由两次[3x3]卷积操作,得到特征图[196x196x128]。、
最后进行上采样,特征图尺寸变为[392x392x64],与Encoder对应特征图处理过后进行拼接,得到[392x392x128]特征图,进行两次[3x3]卷积处理进一步融合,得到[388x388x64]的特征图。
最后,特征图通过一个[1x1]卷积层,卷积核个数为num_cls个,在文中类别只分为前景和背景,所以num_cls=2。输出的分割图为[388x388x2]。需要注意的是,该[1x1]卷积层没有ReLu激活函数。
3、实验现状
需要注意的是输入的原图大小为[572x572]大小的,但是最终得到的分割图是[388x388]大小的,只保留了中间[388x388]区域的特征图。
 如果按照原论文的方法实现网络之后,输入的图像区域为蓝色框区域,那么最终所得到的分割图像实际只有黄色框中的部分。原论文中提到,若是需要获得边界部分的区域分割结果,可以使用镜像的策略,通过按照黄色框的边界作为对称轴将原图进行镜像操作扩大输入图像大小,以获得边界分割效果。
如果按照原论文的方法实现网络之后,输入的图像区域为蓝色框区域,那么最终所得到的分割图像实际只有黄色框中的部分。原论文中提到,若是需要获得边界部分的区域分割结果,可以使用镜像的策略,通过按照黄色框的边界作为对称轴将原图进行镜像操作扩大输入图像大小,以获得边界分割效果。
现如今比较主流的实现方法并不是完全按照原论文中给出的方法去实现的,会在特征图经过[3x3]卷积中加入一个padding,这样卷积操作并不会改变特征图的大小,并且在卷积与ReLu函数之间加上BN层。这样做的好处是在Decoder部分进行上采样之后,由于[3x3]卷积操作不会改变特征图大小,在上采样的特征图与Encoder部分对应特征图Concat拼接时不需要进行中心裁剪操作。这样最终得到的特征图的高和宽与原输入图像的高和宽一致。
4、分割策略
如果针对非常高分辨率的图片进行分割任务的话,直接将图片放入模型进行预测可能会导致显存占用太大影响效率。
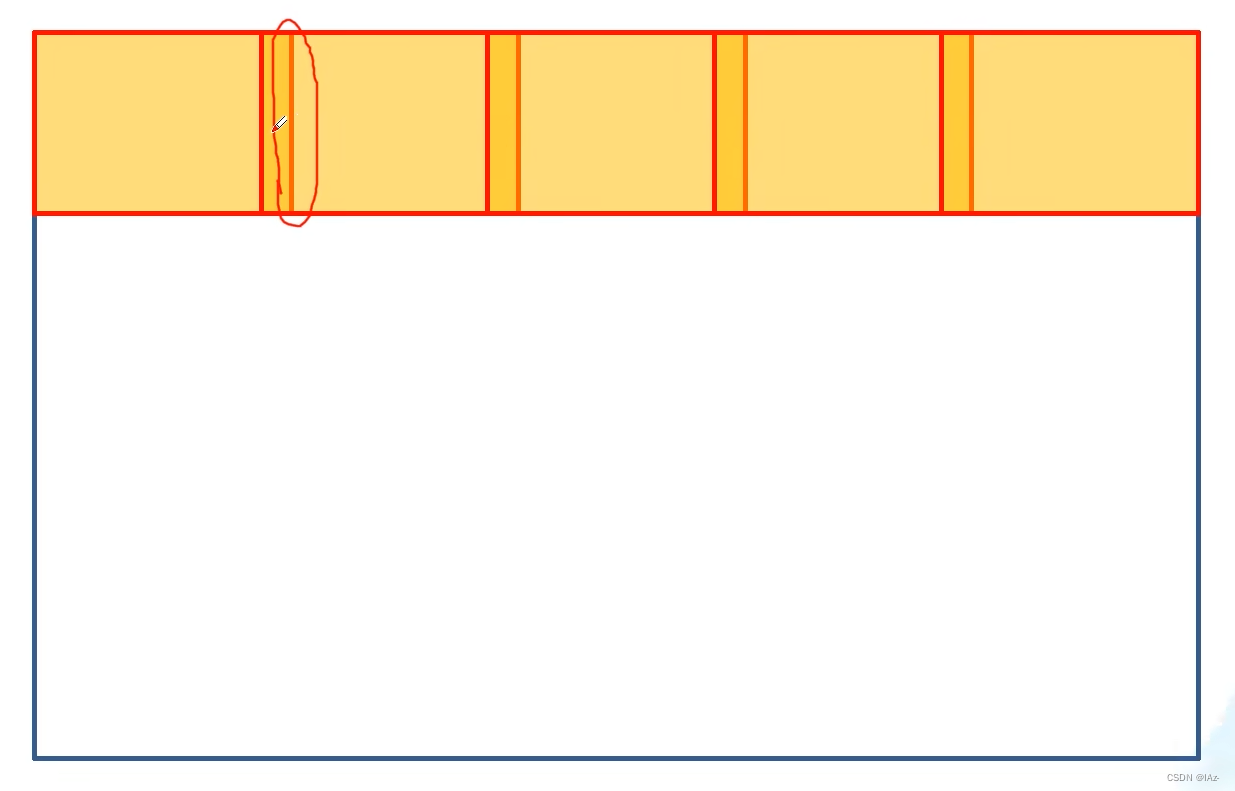
较为常见的策略是每次只分割一小块区域patch,但是相邻两个区域之间会有一个重叠区域,这样的目的是能够更好的利用到边界部分的左右邻近区域,使得分割patch的边界区域效果更好。通过这个方法就可以获得较为好的分割效果。