一、背景
在大数据领域,初始阶段业务数据通常被存储于关系型数据库,如MySQL。然而,为满足日常分析和报表等需求,大数据平台采用多种同步方式,以适应这些业务数据的不同存储需求。
一项常见需求是,业务使用人员需要大数据分析平台中实时查看业务表中某一维度的相应数据数据,示例如下:
- [Mysql] 业务数据 - 假设我们有一个订单表(也称为事实表),记录了公司的销售订单信息。该表包含以下字段:订单ID、客户ID、产品ID、销售日期、销售数量和销售额等。:
| 订单ID | 客户ID | 产品ID | 销售日期 | 销售数量 | 销售额 |
|---|---|---|---|---|---|
| 1 | 1001 | 2001 | 2022-01-01 | 3 | 150 |
| 2 | 1002 | 2002 | 2022-01-02 | 2 | 80 |
| 3 | 1003 | 2001 | 2022-01-03 | 1 | 50 |
| 4 | 1001 | 2003 | 2022-01-04 | 5 | 250 |
| 5 | 1002 | 2002 | 2022-01-05 | 4 | 160 |
- [大数据平台] - 业务人员希望按照客户ID维度聚合销售数量和销售额,以便实时分析每个客户的销售情况,如下:
| 客户ID | 销售数量总计 | 销售额总计 |
|---|---|---|
| 1001 | 8 | 400 |
| 1002 | 6 | 240 |
| 1003 | 1 | 50 |
- [Mysql] 业务数据 - 新增了两条订单数据,如下:
| 订单ID | 客户ID | 产品ID | 销售日期 | 销售数量 | 销售额 |
|---|---|---|---|---|---|
| 1 | 1001 | 2001 | 2022-01-01 | 3 | 150 |
| 2 | 1002 | 2002 | 2022-01-02 | 2 | 80 |
| 3 | 1003 | 2001 | 2022-01-03 | 1 | 50 |
| 4 | 1001 | 2003 | 2022-01-04 | 5 | 250 |
| 5 | 1002 | 2002 | 2022-01-05 | 4 | 160 |
| 6 | 1003 | 2001 | 2022-01-06 | 1 | 50 |
| 7 | 1004 | 2001 | 2022-01-06 | 1 | 50 |
加粗为更新/新增数据
- [大数据平台] - 此时每个客户的销售情况,如下:
| 客户ID | 销售数量总计 | 销售额总计 |
|---|---|---|
| 1001 | 8 | 400 |
| 1002 | 6 | 240 |
| 1003 | 2 | 100 |
| 1004 | 1 | 50 |
加粗为更新/新增数据
根据上述需求,我们可以得出需要构建实时切片表以满足业务数据的实时分析需求。
切片表也叫维度表,是根据基础表(事实表)某个维度或多个维度对事实数据进行汇总计算,并展示为一个交叉分析的表格。与事实表相比,切片表的数据更加聚合,只包含某些维度或者满足某些特定条件的数据。
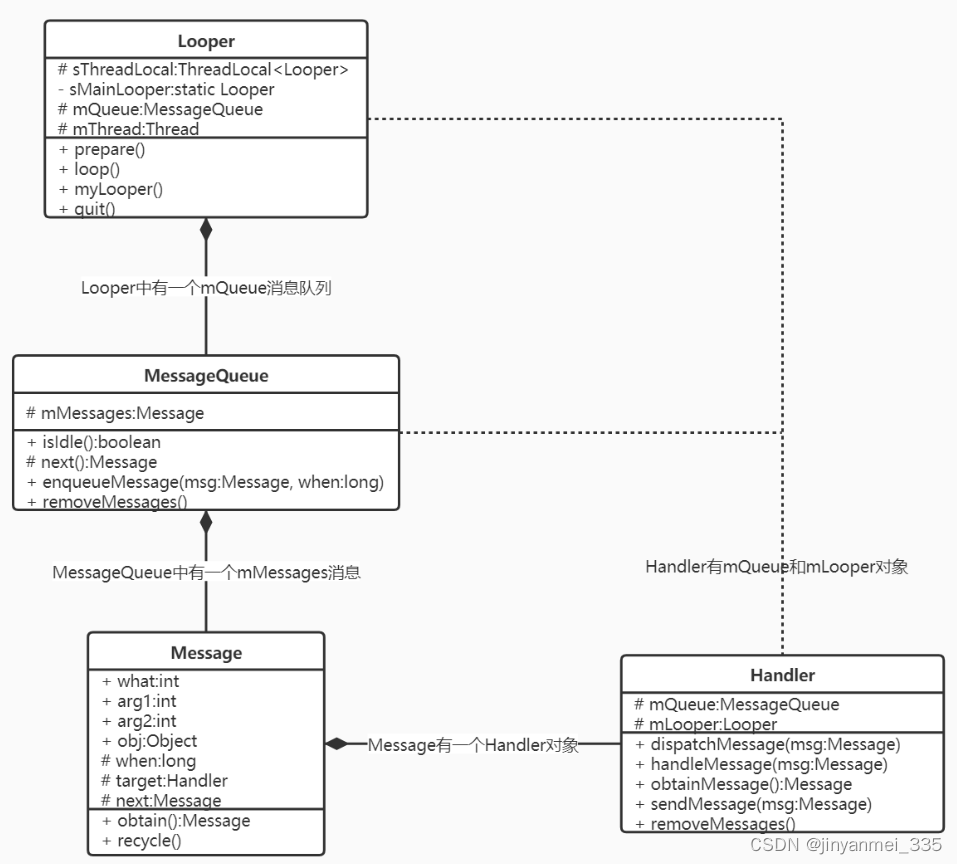
二、技术架构
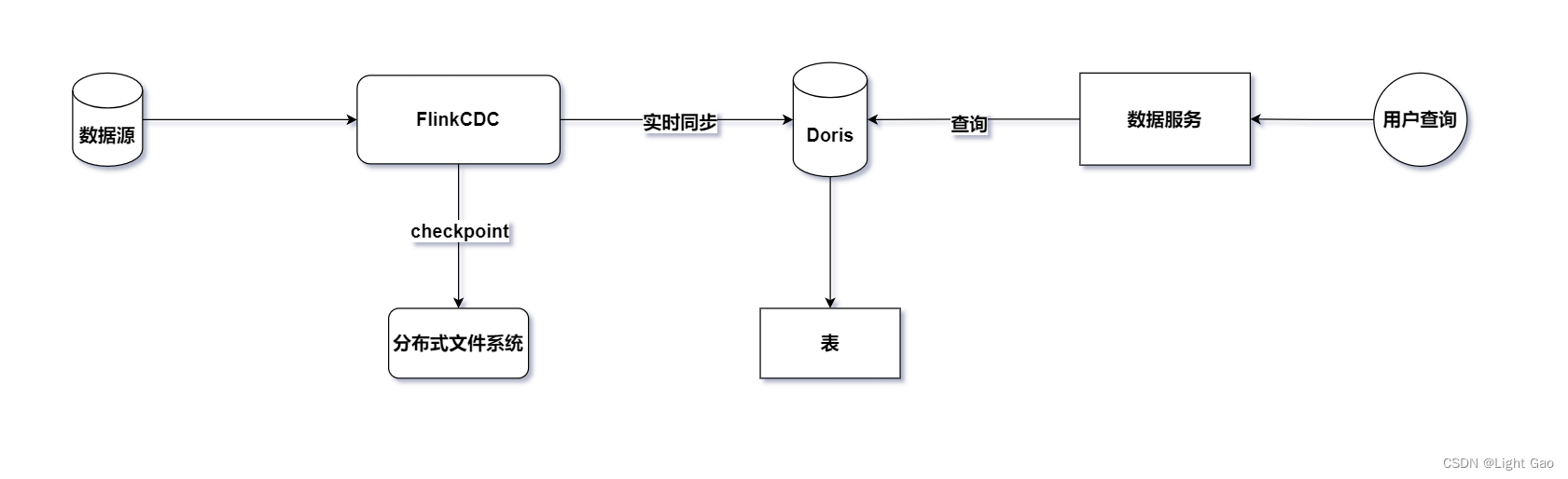
为了实现上述需求,我们可以利用实时同步任务将业务数据实时同步至下游的 MPP(Massively Parallel Processing)库,从而构建切片表。结合市场上常见的技术组件,本文选择了实时引擎 FlinkCDC 和 Doris(MPP)库作为实时同步技术架构。整体架构如下:
三、设计方案
从背景需求不难看出只需实现切片表即可满足需求,但是在flink + Mpp库中却可以有多种方案,可分为三种,具体如下:
3.1、FlinkCDC + FlinkSQL状态计算
该方案利用了FlinkCDC实时捕获业务数据,并在Flink内部进行有状态的计算,例如聚合查询等操作。这种方法依赖于Checkpoint分布式快照,确保精确一次性的处理。最终,计算得到的聚合结果会实时地下沉到下游MPP库中,使业务人员能够直接查询切片表数据。示例如下:
-- flink cdc 读取订单表
create table mysql_order(
# ...
) WITH (
# ...
);-- flink sql doris
create table doris_order(
# ...
) WITH (
# ...
);-- flink sql
insert into doris_order select 客户ID, sum(销售数量), sum(销售额) from mysql_order group by 客户ID;
- 优点:
- 实现了实时捕获和处理业务数据,保证了数据的准确性和实时性。
- 利用了Flink的状态计算能力,使得处理逻辑更加灵活和高效。
- 缺点:
- 下游Doris表结构固定,无法灵活满足用户对不同维度的查询需求。
3.2、FlinkCDC + Doris Aggregate 模型
这种方法利用了Doris Aggregate聚合模型,实现了切片表的功能。在Doris Aggregate聚合模型中,数据会在每批次导入时进行内部聚合,从而无需上游有状态计算。只需将聚合后的数据下沉至Doris数据库即可。
以下是一个示例的Doris建表语句:
-- Doris aggregate 建表语句
CREATE TABLE IF NOT EXISTS example_db.example_order_agg
(`客户ID` LARGEINT NOT NULL COMMENT "客户ID",`销售数量总计` BIGINT SUM DEFAULT "0" COMMENT "销售数量总计",`销售额总计` BIGINT SUM DEFAULT "0" COMMENT "销售额总计"
)
AGGREGATE KEY(`客户ID`)
DISTRIBUTED BY HASH(`客户ID`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
更多信息:Doris Aggregate 模型
- 优点:
- 通过FlinkCDC实现了实时捕获和处理业务数据,确保了数据的准确性和实时性。
- 利用了Doris aggregate模型进行聚合查询,将聚合压力下沉至下游。
- 缺点:
- 下游Doris表结构固定,无法灵活满足用户对不同维度的查询需求。
3.3、FlinkCDC + 实时表 + OLAP查询
这种方案充分利用了Doris的OLAP能力,只需建立一个实时表,业务人员便可根据需要自定义查询语句进行查询。
以下是一个示例的实现:
-- flink cdc 读取订单表
create table mysql_order(
# ...
) WITH (
# ...
);-- flink sql doris
create table doris_order(
# ...
) WITH (
# ...
);-- flink sql 实时同步
insert into doris_order select * from mysql_order;-- 业务人员查询
select 客户ID, sum(销售数量), sum(销售额) from doris_order group by 客户ID;
对于实时表的具体实现,可参考笔者另一篇文章:Flink实时数仓同步:实时表实战详解
- 优点:
- 利用 FlinkCDC 实现了实时捕获和处理业务数据,确保了数据的准确性和实时性。
- 借助 Doris 的 OLAP查询能力,将聚合压力下沉至下游,提高了系统的性能和稳定性。
- 无需固定 Doris 表结构,可以灵活满足用户对不同维度的查询需求。
- 缺点:
- 当数据量巨大时可能存在一定查询延迟问题。
- 可能存在并发查询效率降低问题,需要合理规划和调整查询策略。
3.4、总结
针对不同的需求场景,我们需要选择最合适的实现方案。通常情况下,对于固定的聚合查询需求,比如定期汇总统计,FlinkCDC + Doris Aggregate 模型 和 FlinkCDC + FlinkSQL状态计算 是更为合适的选择。而对于需要更灵活查询的情况,FlinkCDC + 实时表 则更加适用。
然而,最终的选择取决于具体的业务需求和场景特点。结合以上几种实现设计,笔者更倾向于 FlinkCDC + 实时表 这种方式。我已经在另一篇博客中详细描述了该实现方式:Flink实时数仓同步:实时表实战详解。
故本文将采用FlinkCDC + FlinkSQL有状态计算实现设计,旨在给读者带来不同的体验。
四、实现方式
设计方案确定后我们还需要考虑实现方式,FlinkCDC 提供了三种实现方式,具体如下:
- Flink run jar 模式: 这种模式适用于处理复杂的流数据。当使用简单的 Flink SQL 无法满足复杂业务需求时(例如拉链表等),可以通过编写自定义逻辑的方式,将其打包成 Jar 包并运行。以下是一个示例:
// 示例代码
public class MySqlSourceExample {public static void main(String[] args) throws Exception {// 配置数据源和处理逻辑...// 实时任务启动env.execute("Print MySQL Snapshot + Binlog");}
}
更多信息:MysqlCDC connector
- sql脚本模式:
bin/sql-client -f file,这种模式适用于简单的流水任务,例如实时表同步等简单的 ETL 任务。你可以通过编写 SQL 文件并使用 Flink SQL 客户端执行,而无需编写额外的 Java 代码。以下是一个示例:
-- 示例 mysql2doris SQL 文件
set 'execution.checkpointing.interval'='30000';create table mysql_order(
# ...
) WITH (
# ...
);create table doris_order(
# ...
) WITH (
# ...
);insert into doris_order select 客户ID, sum(销售数量), sum(销售额) from mysql_order group by 客户ID;
执行如下:
$> bin/sql-client.sh --file /usr/local/flinksql/mysql2doris
更多信息:FlinkSQL 客户端
- FlinkCDC Pipeline: 这是 FlinkCDC 3.0 版本引入的全新功能,旨在通过简单的配置即可实现数据同步,无需编写复杂的 Flink SQL。缺点是需要使用 Flink 版本 1.16 或更高版本。以下是一个示例:
# 示例配置文件
source:type: mysqlname: MySQL Sourcehostname: 127.0.0.1port: 3306username: adminpassword: passtables: adb.\.*, bdb.user_table_[0-9]+, [app|web].order_\.*server-id: 5401-5404sink:type: dorisname: Doris Sinkfenodes: 127.0.0.1:8030username: rootpassword: passpipeline:name: MySQL to Doris Pipelineparallelism: 4
执行如下:
$> bin/flink-cdc.sh mysql-to-doris.yaml
更多信息:FlinkCDC Pipeline
这三种方式各有优劣,可以根据具体需求和场景选择合适的实现方式。考虑到前几篇 Flink 实时数仓同步相关博客都采用了 Jar 包形式,为了给读者带来不同的体验,本文采用 sql脚本模式 模式来实现背景需求。
五、FlinkCDC + FlinkSQL状态计算实现
5.1、Doris切片表设计
由于FlinkSQL完成聚合计算,因此在Doris中设计表结构时采用了Unique数据模型。建表语句如下:
CREATE TABLE `example_order_slice`
(`user_id` INT NOT NULL COMMENT '客户id',`sale_count` BIGINT NULL COMMENT '销售数量总计',`sale_total` BIGINT NULL COMMENT '销售金额总计'
) ENGINE=OLAP
UNIQUE KEY(`user_id`)
COMMENT '订单切片表'
DISTRIBUTED BY HASH(user_id) BUCKETS AUTO;
关于mysql type 转换 doris type 可参考 Doris 源码内置转换工具
5.2、实时同步逻辑
-
首先,由于实时流水表同步使用Flink-cdc读取关系型数据库,flink-cdc提供了四种模式: “initial”,“earliest-offset”,“latest-offset”,“specific-offset” 和 “timestamp”。本文使用的Flink-connector-mysq是2.3版本,这里简单介绍一下这四种模式:
initial(默认):在第一次启动时对受监视的数据库表执行初始快照,并继续读取最新的 binlog。earliest-offset:跳过快照阶段,从可读取的最早 binlog 位点开始读取latest-offset:首次启动时,从不对受监视的数据库表执行快照, 连接器仅从 binlog 的结尾处开始读取,这意味着连接器只能读取在连接器启动之后的数据更改。specific-offset:跳过快照阶段,从指定的 binlog 位点开始读取。位点可通过 binlog 文件名和位置指定,或者在 GTID 在集群上启用时通过 GTID 集合指定。timestamp:跳过快照阶段,从指定的时间戳开始读取 binlog 事件。
-
本文采用
initial模式同步任务 -
编写mysql2doris SQL文件,这里需要注意的是类型转换:由于 mysql2doris 是 Flink SQL 文件,故需要将 mysql type -> flink type 以及 doris type -> flink type,示例如下:
set 'execution.checkpointing.interval'='30000';
set 'state.checkpoints.dir'='file:///home/finloan/flink-1.16.1/checkpoint/mysql2doris';create table mysql_order(`id` INT,`user_id` INT,`sale_id` INT,`sale_time` TIMESTAMP(0),`sale_quantity` BIGINT,`sales_volume` BIGINT,PRIMARY KEY(id) NOT ENFORCED
) WITH ('connector'='mysql-cdc','hostname'='10.185.163.177','port' = '80','username'='rouser','password'='123456','database-name' = 'database','table-name'='table'
);create table doris_order(`user_id` INT,`sale_count` BIGINT,`sale_total` BIGINT
) WITH ('password'='password','connector'='doris','fenodes'='11.113.208.103:8030','table.identifier'='database.table','sink.label-prefix'='任务唯一标识,每次启动都要更换','username'='username'
);insert into doris_order select user_id, sum(sale_quantity), sum(sales_volume) from mysql_order group by user_id;
类型转换参考:
Doris & Flink Column Type Mapping
Mysql CDC Data Type Mapping
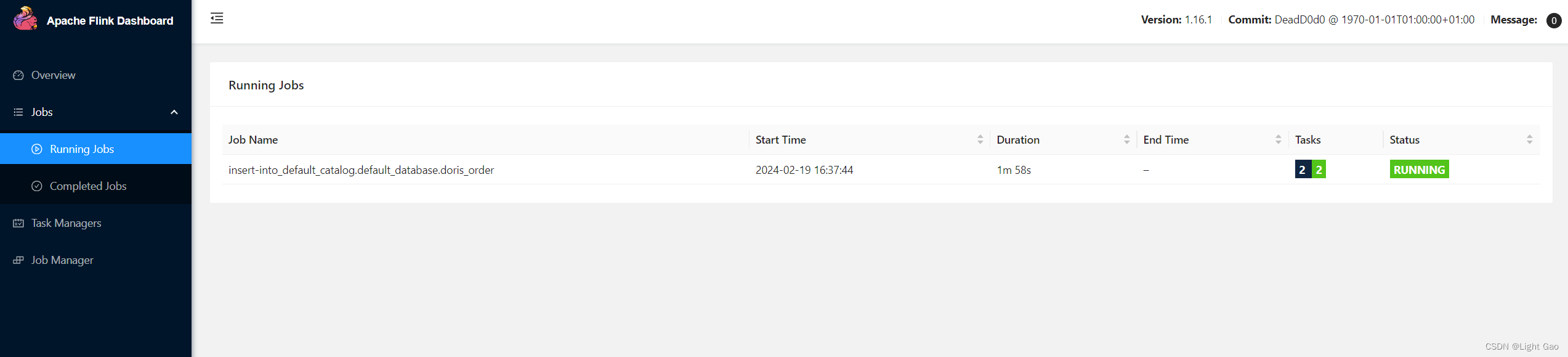
- 执行命令如下:此时任务已经提交到flink 集群,本文中使用的是Flink-Cluster 模式而非yarn模式
$> ./sql-client.sh -f ~/mysql2dorisFlink SQL> [INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 5c683fba8567e65509870a6db4e99fa5
- 登录flinkUi界面查看任务,如下所示:
- 此时Doris 切片表数据如下:
| user_id | sale_count | sale_total |
|---|---|---|
| 1001 | 8 | 400 |
| 1002 | 6 | 240 |
| 1003 | 1 | 50 |
- [Mysql]-业务数据新增了两条订单数据,如下:
| 订单ID | 客户ID | 产品ID | 销售日期 | 销售数量 | 销售额 |
|---|---|---|---|---|---|
| 1 | 1001 | 2001 | 2022-01-01 | 3 | 150 |
| 2 | 1002 | 2002 | 2022-01-02 | 2 | 80 |
| 3 | 1003 | 2001 | 2022-01-03 | 1 | 50 |
| 4 | 1001 | 2003 | 2022-01-04 | 5 | 250 |
| 5 | 1002 | 2002 | 2022-01-05 | 4 | 160 |
| 6 | 1003 | 2001 | 2022-01-06 | 1 | 50 |
| 7 | 1004 | 2001 | 2022-01-06 | 1 | 50 |
- 此时Doris 切片表数据如下:
| user_id | sale_count | sale_total |
|---|---|---|
| 1001 | 8 | 400 |
| 1002 | 6 | 240 |
| 1003 | 2 | 100 |
| 1004 | 1 | 50 |
六、总结
本文详细介绍了实时数仓同步中切片表的设计与实现。首先,分析了业务背景和需求,说明了切片表的作用和必要性。然后,介绍了基于 FlinkCDC 和 Doris 的技术架构,并比较了不同的设计方案。针对不同的需求场景,提出了三种具体的实现方案:FlinkCDC + FlinkSQL状态计算、FlinkCDC + Doris Aggregate 模型以及 FlinkCDC + 实时表,并分析了它们的优缺点。最后,为了给读者带来不同体验选择了 FlinkCDC + FlinkSQL状态计算 方案进行实现,并详细介绍了实时同步逻辑和相关的技术细节。
通过本文的阅读,读者可以了解到实时数仓同步中切片表的设计与实现方法,以及不同方案的选择和比较。同时,本文还提供了相关资料和参考链接,方便读者进一步深入学习和研究。
七、相关资料
- Flink实时数仓同步:实时表实战详解
- Doris Aggregate 模型
- Flink Doris Connector
- FlinkCDC Pipeline
- FlinkSQL 客户端
- Flink Run jar 模式
- Doris 源码内置转换工具
- Doris & Flink Column Type Mapping
- Mysql CDC Data Type Mapping