论文《Exploring CLIP for Assessing the Look and Feel of Images》阅读
- 论文概述
- Preliminary
- 方法论
- Experiments
- 结论
论文概述
今天带来的是论文《Exploring CLIP for Assessing the Look and Feel of Images》,论文主要通过 CLIP 模型来完成图像的质量(how it looks,即quality perception)和情感(how it feels, 即abstract perception)评分。
论文由南洋理工S-Lab完成,论文内容相对简单。整体来讲就是在 vision-language 跨模态大模型训练的时候将原始的prompt改为形容词及其反义词的二元组prompt,以减小表达中的歧义。
论文发表在AAAI 2023上,模型取名为CLIP-IQA。
Preliminary
下面介绍一下一些基本术语:
IQA: Image Quality Assessment 图像质量评价
CLIP:a Vision-Language Pre-Training SOTA model,主要完成跨模态对齐(Cross-modal Alignment, CMA)
方法论
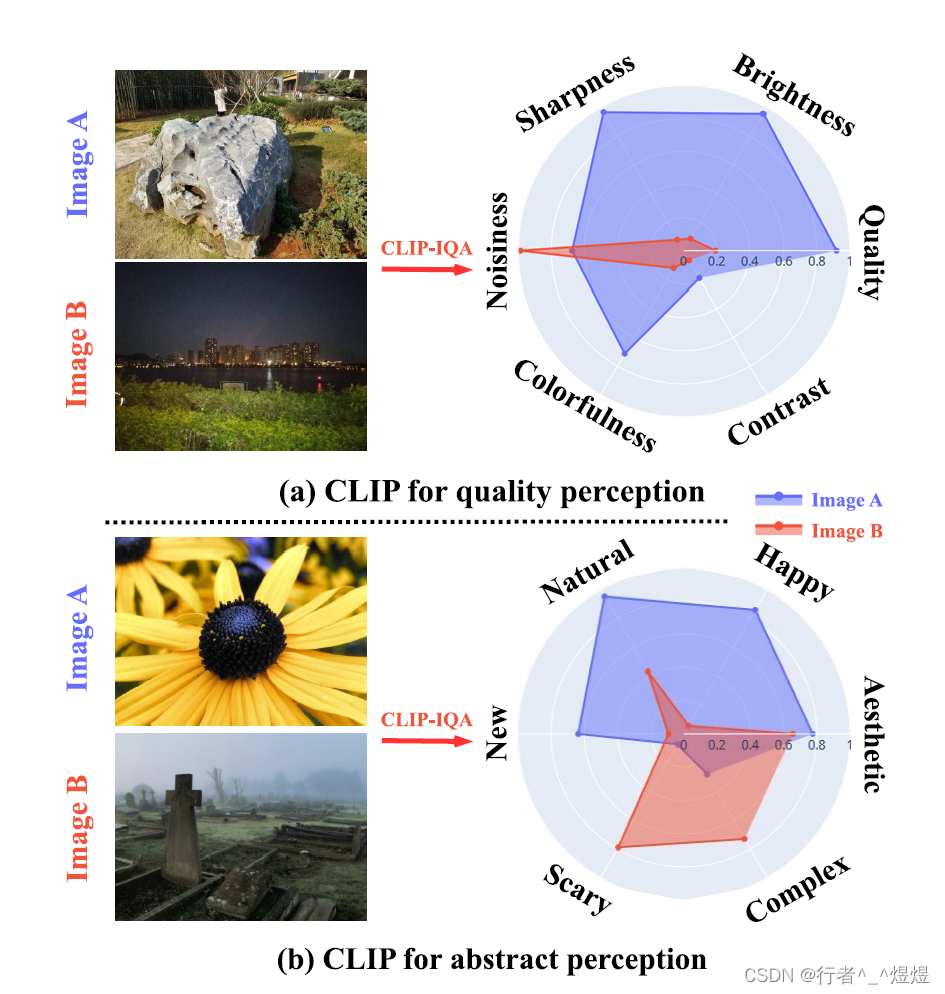
本文主要聚焦于IQA中关于look和feel的评价,其实也就是客观质量评价和主观质量评价,分别(1)关注图片质量(look)如何(粗粒度讲分为“好”/“不好”;细粒度讲包括“噪声”、“明亮度”、“对比度”、“色彩”等(非CV方向,可能翻译不太准));(2)关注图像内容蕴含的抽象感受(例如“恐怖”、“自然”、“快乐”、“复杂”等)。
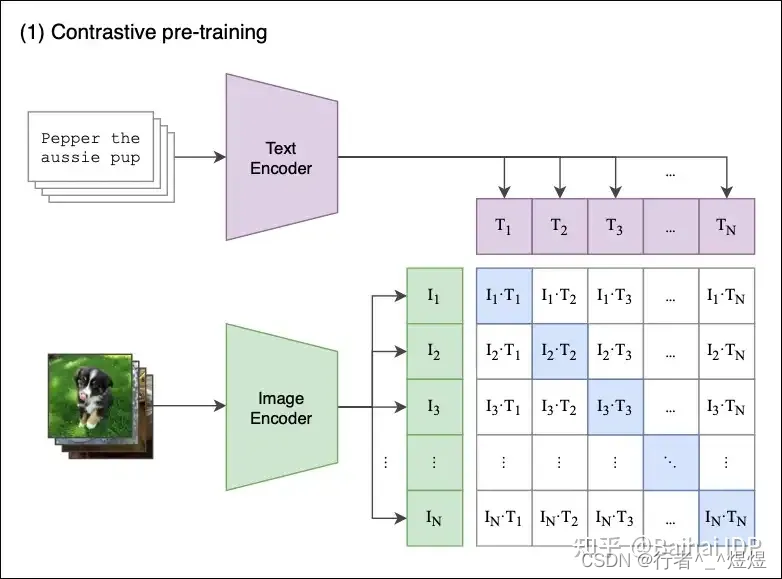
随着大模型的火热,现阶段主要基于CLIP完成跨模态语义对齐,分别通过NLP token 和 CV images 的 描述,将图像和文本语义在空间中的描述进行统一,最终完成语义的挖掘。
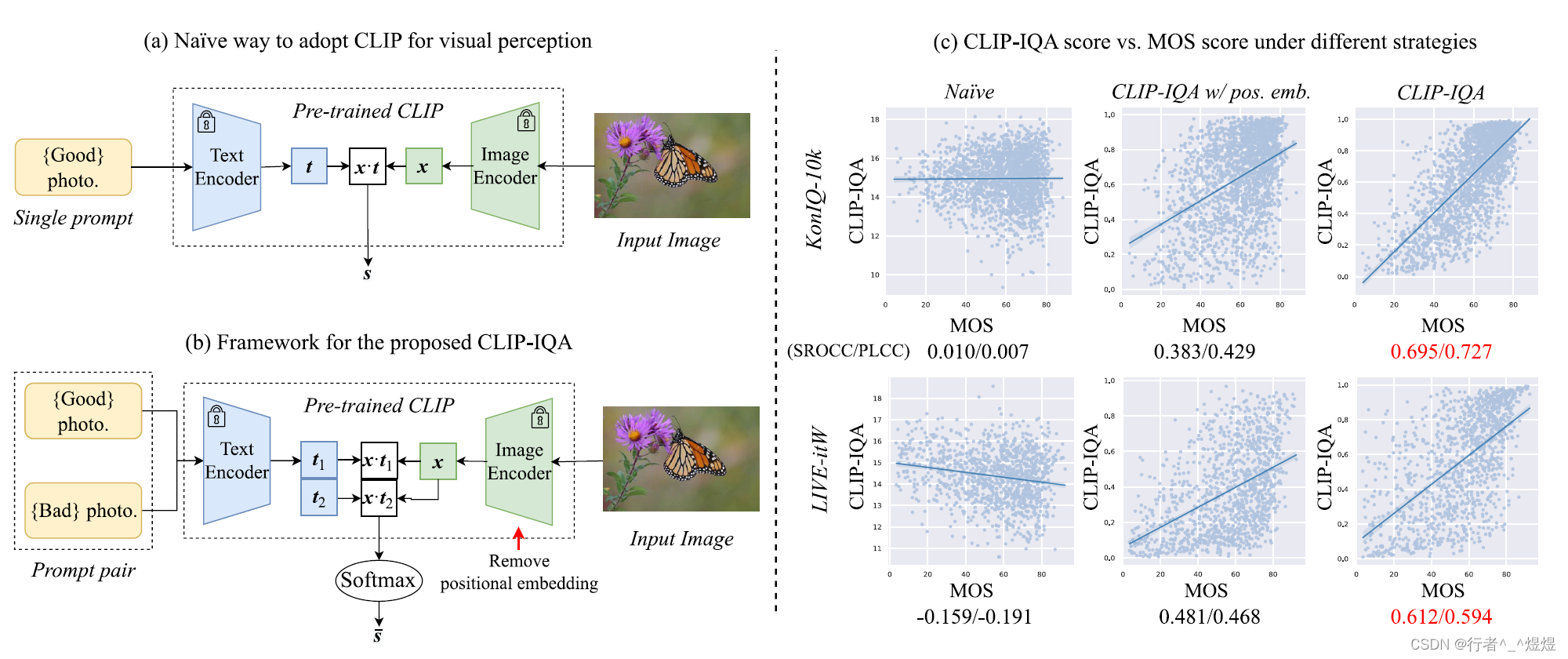
作者认为当前主要问题是文本和图像可能存在偏差,具体而言就是文本描述存在歧义,使得无法真正做到文本和图像的一一对应。
作者怎么做的呢?其实就是把原来的文本换成二元组,加上文本描述的反义词,通过反义词从而消除文本的歧义,分别和图像生成的embedding做相似性比较,然后两个相似性分数通过softmax,得到最终的分类预测分数。即,
s = x ⊙ t ∥ x ∥ ⋅ ∥ t ∥ . (1) s=\frac{\boldsymbol{x} \odot \boldsymbol{t}}{\|\boldsymbol{x}\| \cdot\|\boldsymbol{t}\|}. \tag{1} s=∥x∥⋅∥t∥x⊙t.(1)
将原来CLIP中的对比学习求相似度部分改为下面:
s i = x ⊙ t i ∥ x ∥ ⋅ ∥ t i ∥ , i ∈ { 1 , 2 } (2) s_i=\frac{\boldsymbol{x} \odot \boldsymbol{t}_i}{\|\boldsymbol{x}\| \cdot\left\|\boldsymbol{t}_i\right\|}, \quad i \in\{1,2\} \tag{2} si=∥x∥⋅∥ti∥x⊙ti,i∈{1,2}(2)
s ˉ = e s 1 e s 1 + e s 2 . (3) \bar{s}=\frac{e^{s_1}}{e^{s_1}+e^{s_2}}. \tag{3} sˉ=es1+es2es1.(3)
这里,我们附上CLIP的大概原理图:
另外,在上面的基础上,作者提出对于CLIP中的图像编码器来讲,针对于质量评价任务,positional embedding是多余的。例如,对于分辨率评价来讲,如果对图片进行裁剪,就无法判断原图的分辨率是否达到要求(这里作者讲的模型是ResNet-50-based CLIP,不知道是不是笔误,不应该是ViT-based CLIP吗?ResNet 有设计到 positional embedding的部分吗?不都是直接卷积移动吗?了解不深,欢迎评论区讨论)。
作者对 image encoder 采用了ResNet variant(具体是何变种没有提及),取消了positional embedding 的设计。
Experiments
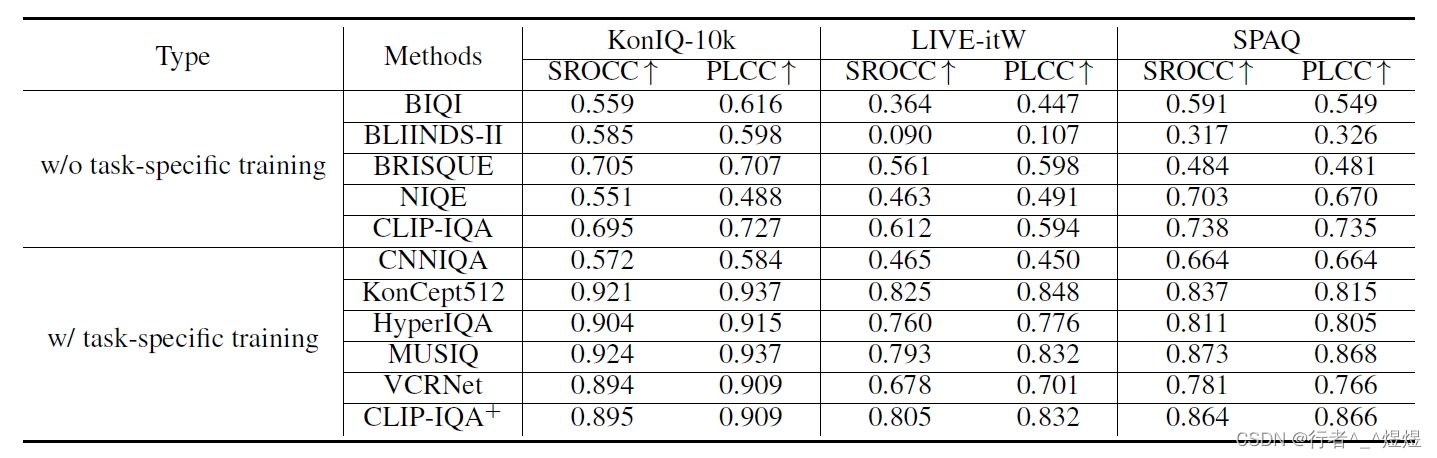
可以看到,CLIP-IQA 在 无精调情况下,表现基本持平或小幅度劣于BRISQUE。这里的最好表现的baseline BRISUQE(2012),不知道这个BRISQUE属不属于SOTA方法。
在有精调的情况下,CLIP-IQA不那么好。
结论
本文创新性可能略低,同时实验部分表现好像也不那么好。在实验部分的结果展示中,使用了太多的可视化展示,而没有具体的数字呈现,总给人一种遮遮掩掩的感觉。甚至还加了一个人工识别(25个人)与模型结果的比较部分,挺迷的。