引入
看这样一段代码
1 #include<stdio.h>2 #include<unistd.h>3 #include<stdlib.h>4 5 int g_val = 100;6 int main()7 {8 pid_t id = fork();9 if(id==0)10 {11 int cnt = 0;12 while(1)13 {14 printf("child,pid:%d,ppid:%d,g_val:%d,&g_val:%p\n",getpid(),getppid(),g_val,&g_val);15 sleep(2);16 cnt++;17 if(cnt==5)18 {19 g_val = 200; 20 printf("child change g_val:100->200\n");21 }22 } 23 24 } 25 else 26 { 27 while(1) 28 { 29 printf("father,pid:%d,ppid:%d,g_val:%d,&g_val:%p\n",getpid(),getppid(),g_val,&g_val);30 sleep(2); 31 } 32 } 33 return 0;34 }
运行结果为:
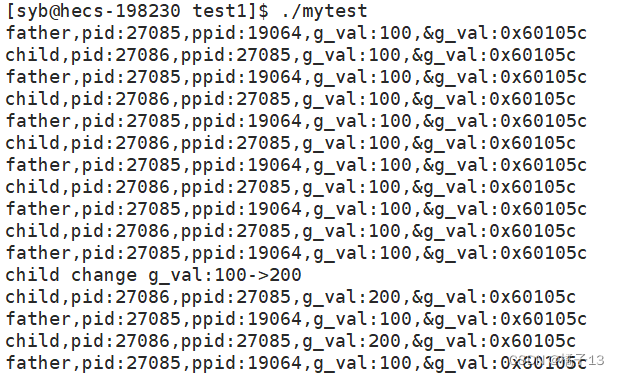
我们发现改之前父子进程的g_val的值都是100,更改之后child的g_val是100,father的g_val是200,但是&g_val的地址都是0x60105c,同一个地址怎么可能存储的值不同?
原因:这个地址一定不是物理地址!这个地址是虚拟地址。
什么是进程地址空间?
进程地址空间的结构组成
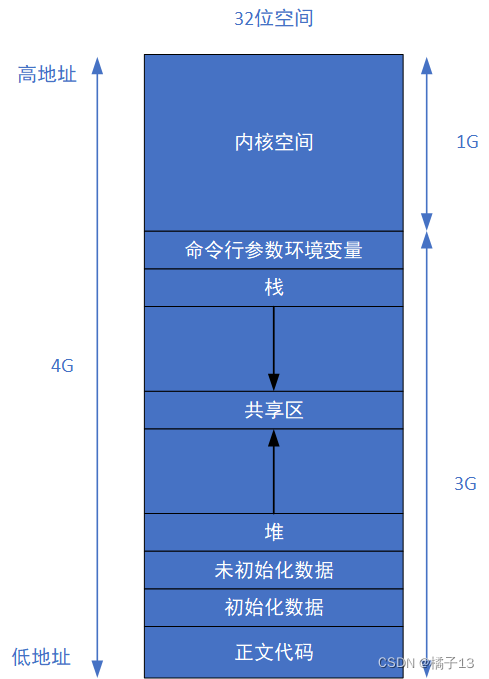
栈区:自定义的变量,指针变量,反正是各种变量都是存在栈上,但是指针变量所指向的内容不一定在栈上。
例:

堆区:通过malloc/new申请的空间,
静态区:(未初始化数据)(初始化数据)全局变量,静态变量。
例题:
int globalVar = 1;static int staticGlobalVar = 1;void Test(){static int staticVar = 1;int localVar = 1;int num1[10] = {1, 2, 3, 4};char char2[] = "abcd";char* pChar3 = "abcd";int* ptr1 = (int*)malloc(sizeof (int)*4);int* ptr2 = (int*)calloc(4, sizeof(int));int* ptr3 = (int*)realloc(ptr2, sizeof(int)*4);free (ptr1);free (ptr3);}第一组:选项: A.栈 B.堆 C.数据段(静态区) D.代码段(常量区)globalVar在哪里?__C__ staticGlobalVar在哪里?__C__staticVar在哪里?__C__ localVar在哪里?__A__num1 在哪里?__A__分析:globalVar全局变量在数据段 staticGlobalVar静态全局变量在静态区staticVar静态局部变量在静态区 localVar局部变量在栈区num1局部变量在栈区char2在哪里?__A__ *char2在哪里?__A__pChar3在哪里?__A__ *pChar3在哪里?__D__ptr1在哪里?__A__ *ptr1在哪里?__B__分析:char2局部变量在栈区 char2是一个数组,把后面常量串拷贝过来到数组中,数组在栈上,所以*char2在栈上pChar3局部变量在栈区 *pChar3得到的是字符串常量字符在代码段ptr1局部变量在栈区 *ptr1得到的是动态申请空间的数据在堆区第二组:sizeof(num1) = __40__;//数组大小,10个整形数据一共40字节sizeof(char2) = __5__;//包括\0的空间strlen(char2) = __4__;//不包括\0的长度sizeof(pChar3) = __4__;//pChar3为指针strlen(pChar3) = __4__;//字符串“abcd”的长度,不包括\0的长度sizeof(ptr1) = __4__;//ptr1是指针进程地址空间的本质
进程地址空间的本质是数据结构,具体到进程中就是特定的数据结构对象。
想象中:
实际中:
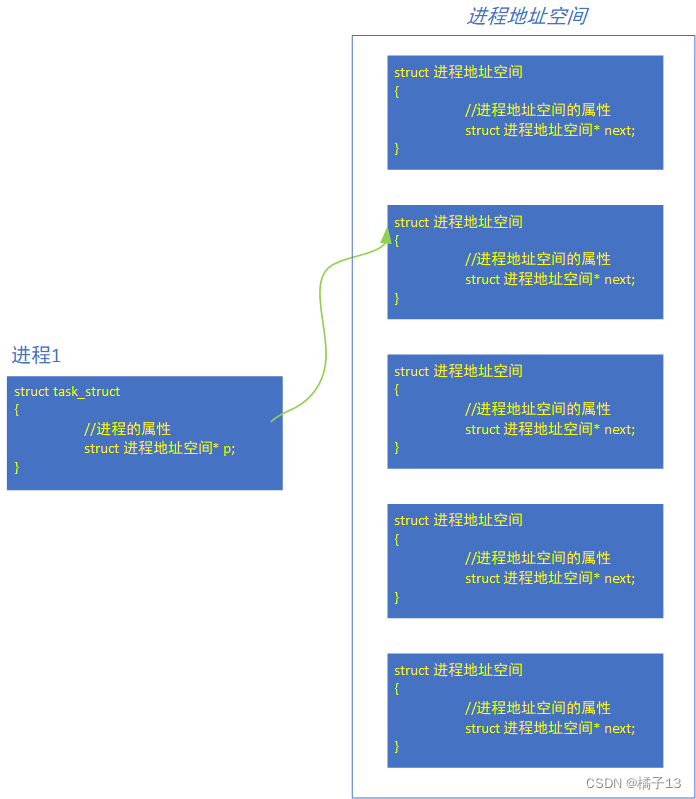
本质上就是进程地址空间就是一个个结构体连接,每个结构体被赋予了一个十六进制的地址,而进程的PCB属性中有指向进程地址结构体的指针。
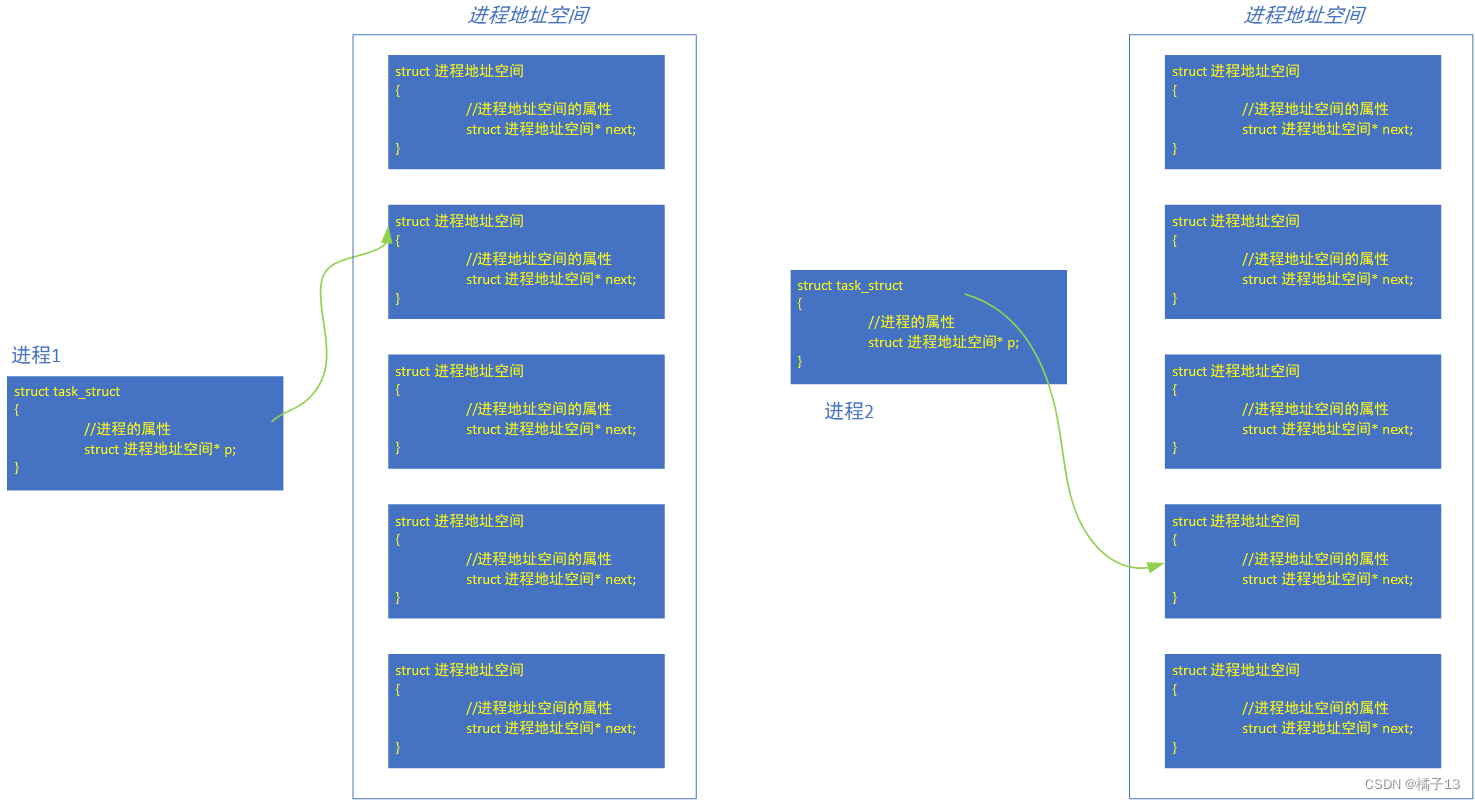
每一个进程都存在一个进程地址空间(如上图),4GB(32位平台),操作系统的真实物理空间是4GB,操作系统给每个进程都“画了一张大饼”,给每个进程都分配了4GB的虚拟地址空间。
如何理解分区?
本质上还是结构体对数据区域进行了划分,结构体中的属性对分区的开始与结束进行了标记。

我们的地址空间不具备对我们的代码和数据的保存的能力,它们是保存在物理内存空间的,将进程地址空间上的地址(虚拟地址)转化到物理内存中,进程提供一张映射表——页表。
这张表保存的是地址与地址之间的映射关系,CPU中的CR3通过映射关系来将虚拟地址映射到物理地址。
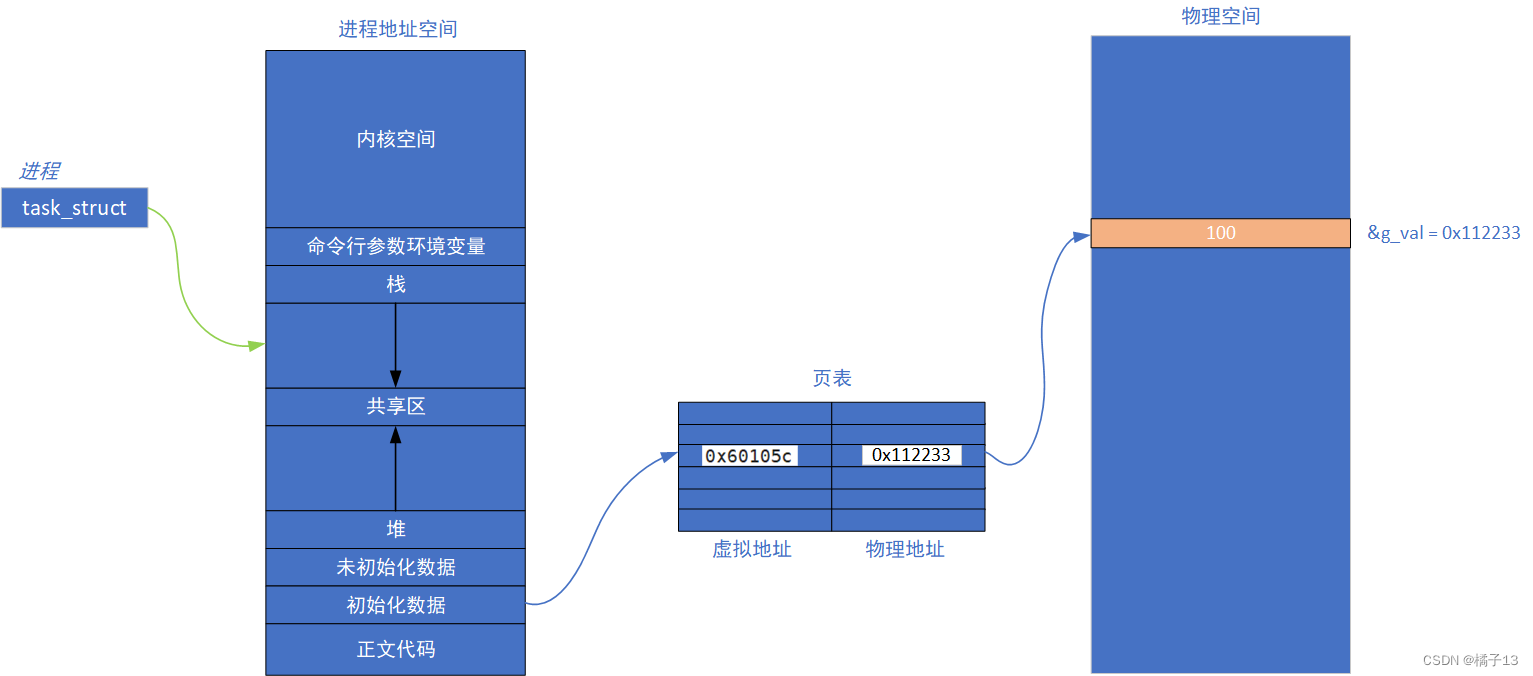
引入中的问题
这样我们就可以理解一开始访问地址相同但是访问的数据不同的问题。
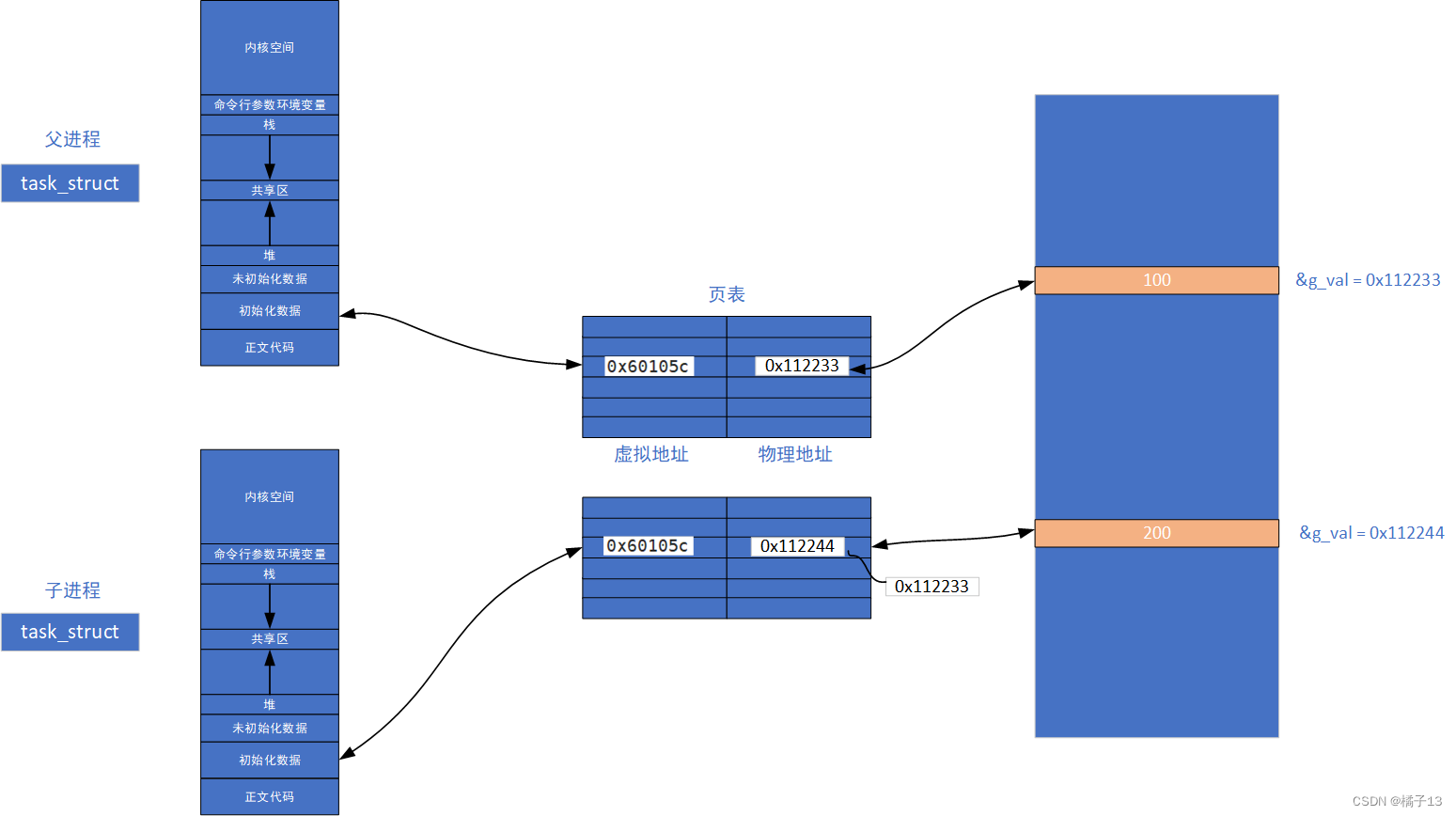
原因就是进程之间具有独立性,访问的虚拟地址相同但是它们虚拟地址空间与物理地址空间直接产生映射的页表不同(映射关系不同),导致了访问地址相同但是访问的数据不同的问题。
以下用图来说明:
一开始都是同样的映射关系,同一个虚拟地址对应了同一个地址空间。
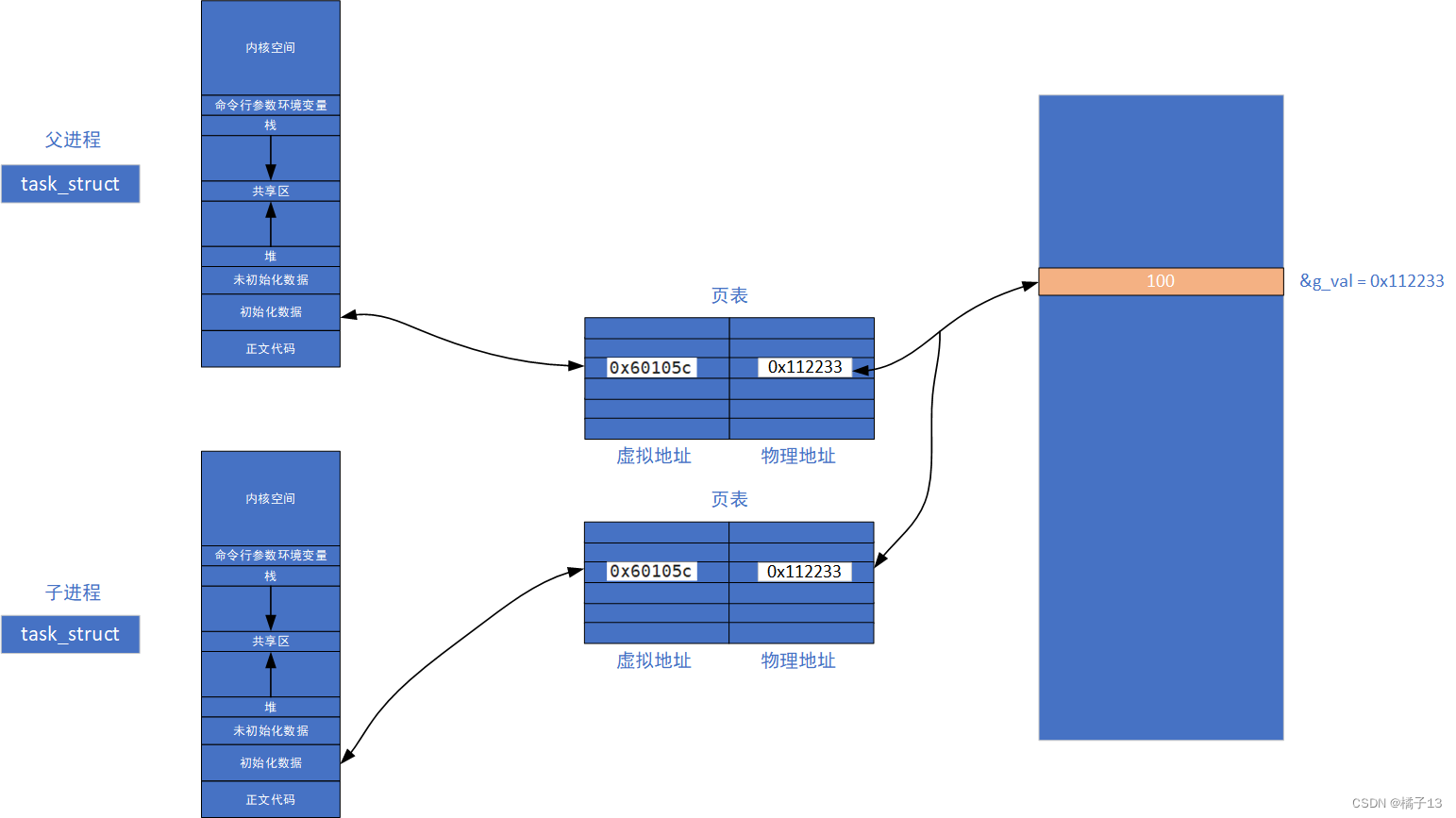
但是当子进程写入数据,这时发生了写时拷贝,复制一份数据并修改,这时虽然父和子的虚拟地址不同但是父和子的映射关系改变了,所以读到的数据不同。
为什么要有进程地址空间?(进程地址空间存在的意义)
1.将物理内存从无序变成有序。让进程统一的视角,看待内存。
说明:对于进程在虚拟地址空间中的排布是十分清晰的(不同的数据在不同的分区有序排列),但是在物理空间中的排布是不得而知的,是混乱的,这时通过页表将虚拟地址空间与物理空间建立起联系,这时我们只用关注虚拟地址空间即可,至于物理空间交给操作系统通过页表进行操作。
2.将进程管理和内存管理进行解耦合。
说明:OS对物理空间进行管理,进程对自己的虚拟地址空间进行管理,而物理空间和进程地址空间通过一张页表进行映射,这样进程就不会对物理空间进行干扰,它们之间互不干扰!
这也说明了进程之间是具有独立性的,一个进程的崩溃不会影响其他进程。
解释一些事情:
malloc/new申请内存
1.申请的内存,本质是在哪里申请的?
进程的虚拟地址空间中申请。
2.申请的内存会直接使用吗?
不一定,申请了的内存只是虚拟地址空间,当要写入时,操作系统先进行阻拦(缺页中断),去建立虚拟地址空间和物理地址空间的映射放入页表(真正的申请空间),这时操作系统放开阻拦,允许写入。

![[C语言]——分支和循环(1)](https://img-blog.csdnimg.cn/direct/05096fe7a61043ba92a528252102243b.png)