目录
一.HTTP是什么?
二.HTTP的请求和响应
a.请求:
b.响应:
三.URL
四.Header
1.Host
2. Content-Length
3. Content-Type
a. 请求
b. 响应
4. Referer
5. User-Agent
6. Cookie
一.HTTP是什么?
HTTP是一种应用层协议,其中应用层协议还有很多比如HTML,URL等
应用场景:
1.网页和后台服务器之间的交互
2.app和后台服务器之间的交互
二.HTTP的请求和响应
a.请求:
1)首行(HTTP请求的第一行,有三个部分信息,三个部分使用空格进行分割)
第一个部分信息:GET ,是HTTP 请求的“方法”
第二个部分信息:URL 唯一资源定位符,描述了一个资源在网络上的位置
第三个部分信息:版本号
2)请求头(header)
是一个键值对结构的数据,每个键值对都独占一行,键和值之间通过 :空格来区分
这里的键值对都属于标准规定的
3)空行
请求头结束的标记
4)正文( body)
正文有的有,有的没
b.响应:
1)首行(包含了版本号,状态码,状态码描述)

2)响应头(header)
也是键值对结构,每个键值对独占一行,键和值之间通过:空格来区分
此处的键值对也是有标准规定的
3)空行
响应头结束的标记
4)正文(body)
响应的正文比较多
三.URL
我们来看一下HTTP 请求首行中的URL 是这么个事
URL是统一资源定位符,描述了某个资源在网络上所属的位置

比如我在大学买凉皮
http://锦绣餐厅:8080/凉皮/火鸡面凉皮?凉面=多放&辣椒少放
服务器地址 端口 带层次的文件路径 查询字符串(query string)
query string 中的键值对都是程序猿自定义的
四.Header
我们知道Header中都是一些键值对的结构,这里介绍最重要的一些键值对。
1.Host
这个就是服务器的域名 , 就比如 www.baidu.com
2. Content-Length
这个是 body 中数据的长度
这里有个比较重要的知识点:前面涉及到的TCP 粘包问题
HTTP 在传输层 就是 基于 TCP的
如果使用同一个TCP进行连接,传输多个HTTP数据包,此时多个HTTP数据包就会在TCP的接收缓冲区中挤在一起
那么接收方进行解析的时候,该怎么样清楚 HTTP 数据包的界限?
对于GET 这种通常没有 body 的请求,直接可以使用 空行(分隔符)
对于 POST 这种有 body 的请求,就需要结合 空行和 Content-Length
3. Content-Type
body中数据 的格式是非常多的
这里分别来看 请求 和 响应 都有哪些格式
a. 请求
- json
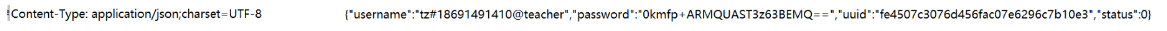
- from 表单的格式
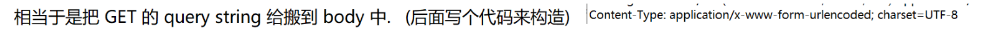
- from - data 的格式

b. 响应
- html
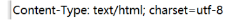
- css
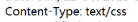
- js

- json

- 图片

4. Referer
Referer描述了当前页面是从那个页面跳转过来的
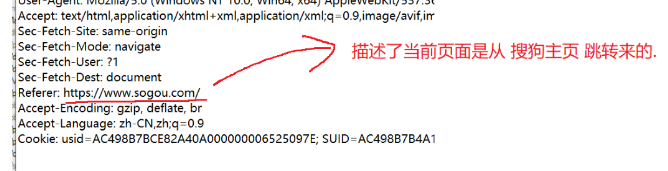
通常用于广告网页计费,在广告界面,可以进行抓包,看到这个广告网页时从什么网站跳转过来的
5. User-Agent
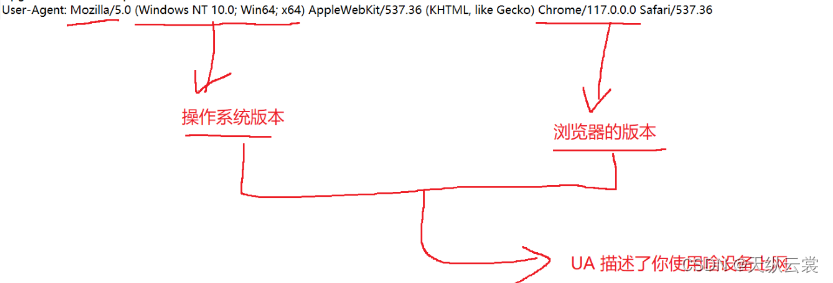
UA 主要是用来区分 PC 端 还是移动端
在很久之前,网页很简单就是仅支持文字,浏览器的功能也很简单
后来,网页的内容开始丰富了,随之浏览器的功能也开始逐渐升级
这个升级的过程是很快的,新的浏览器诞生之后,并不是立即就占领市场,而是在相当一部分时间里,新浏览器和旧浏览器并存的。
网站的开发者就需要考虑到,我写的网页是否要兼容旧版浏览器呢?
那么就可以用 UA 来获取浏览器版本 , 来看看是否兼容
6. Cookie
Cookie可以认为是浏览器 本地存储数据的一种方式
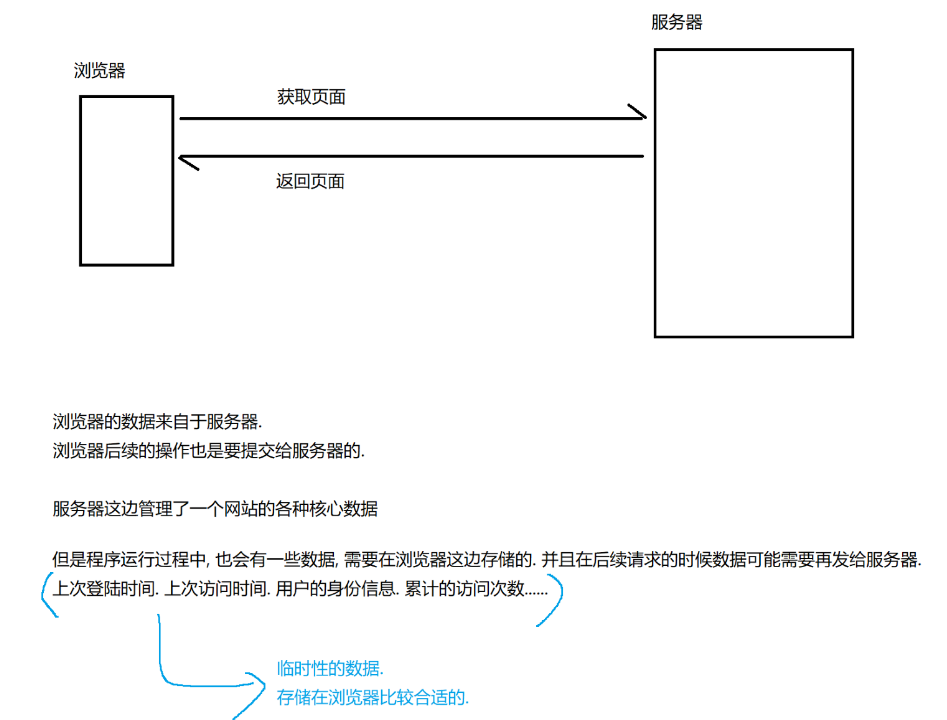
这些数据放到本地文件中更为合适
但是考虑到安全性,是进制网页直接访问电脑的文件系统的
网页代码中也就无法生成一个硬盘的文件来存储数据了。
为了保证安全性,又能进行存储数据,于是就引入了Cookie
也是按照硬盘文件的方式进行保存的,但是浏览器把操作文件进行了封装,网页只能往Cookie 中 存储键值对