一、定义
计算机视觉单词袋是一种描述计算图像之间相似度的技术,常用于用于图像分类当中。该方法起源于文本检索(信息检索),是对NLP“单词袋”算法的扩展。在“单词袋”中,我们扫描整个文档,并保留文档中出现的每个单词的计数。然后,我们创建单词频率的直方图,并使用此直方图来描述文本文档。在“视觉单词袋”中,我们的输入是图像而不是文本文档,并且我们使用视觉单词来描述图像。
对于任意一幅图像,视觉词袋(BoVW,Bag of Visual Words)模型模型提取该图像中的基本元素,并统计该图像中这些基本元素出现的频率,用直方图的形式来表示。通常使用“图像局部特征”来类比BoW模型中的单词,如SIFT、SURF、HOG等特征,所以也称视觉词袋模型。图像BoVW模型表示的直观示意图如图所示
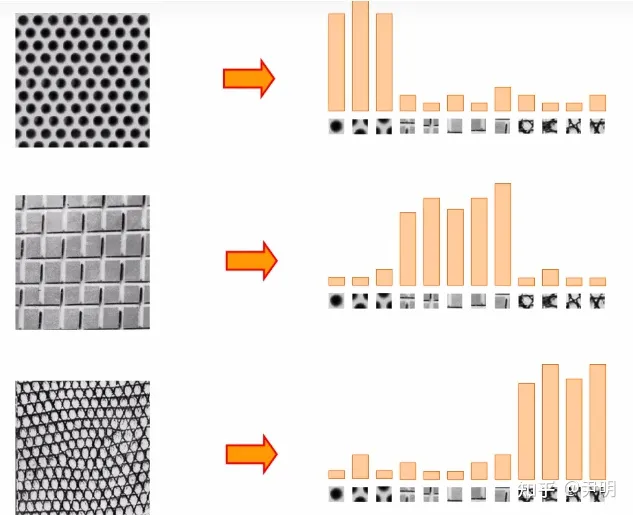
如上,每个图有不同种类的纹理,统计每个纹理的直方图(出现数量),右边这就是词袋。
二、步骤
视觉的词袋模型通常分为以下四个阶段:
-
图像预处理阶段: 在这个阶段,图像会经过一系列预处理操作,包括灰度化、尺寸调整、边缘检测等操作,以便将图像转化为计算机能够处理的形式。
-
特征提取阶段: 在这个阶段,从预处理后的图像中提取出各种特征,比如颜色直方图、边缘信息、纹理特征等,以便能够用来描述图像。
-
词袋生成阶段: 在这个阶段,将提取到的图像特征进行聚类,形成一个特征词典,然后将图像中的特征信息映射到这个词典中,形成一个特征向量。
-
训练和分类阶段: 在这个阶段,使用机器学习算法(如支持向量机、决策树等)对生成的特征向量进行训练,以便对图像进行分类和识别。
三、词袋模型的问题
- 词汇太多、太少都不好。
- 计算效率问题(K-means聚类很慢)
- 顺序、位置问题。比如:“我爱中国”与“爱我中国”,字都一样但含义不一样。
参考:
https://www.cnblogs.com/wxl845235800/p/10564121.html
视觉词袋模型简介-CSDN博客
计算机视觉CS131:专题10-识别&词袋模型 - 知乎
计算机视觉-图像检索与识别_视觉词袋模型的原理-CSDN博客
![LeetCode 刷题 [C++] 第300题.最长递增子序列](https://img-blog.csdnimg.cn/direct/1a55c8e7afa142b5a4dd669572a42cdc.png)