KOA-最近邻分类预测matlab代码
开普勒优化算法(Kepler Optimization Algorithm,KOA)是一种元启发式算法,灵感来源于开普勒的行星运动规律。该算法模拟行星在不同时间的位置和速度,每个行星代表一个候选解,在优化过程中会随机更新,相对于当前找到的最佳解(太阳)。KOA通过引入多个行星候选解,实现对搜索空间更有效的探索和利用,因为这些行星在不同时间会呈现出不同的状态,有利于全局优化。
数据为Excel分类数据集数据。
数据集划分为训练集、验证集、测试集,比例为8:1:1
模块化结构:代码按照功能模块进行划分,清晰地分为数据准备、参数设置、算法处理块和结果展示等部分,提高了代码的可读性和可维护性。
数据处理流程清晰:对数据进行了标准化处理,包括Zscore标准化,将数据分为训练集、验证集和测试集,有助于保证模型训练的准确性和可靠性。
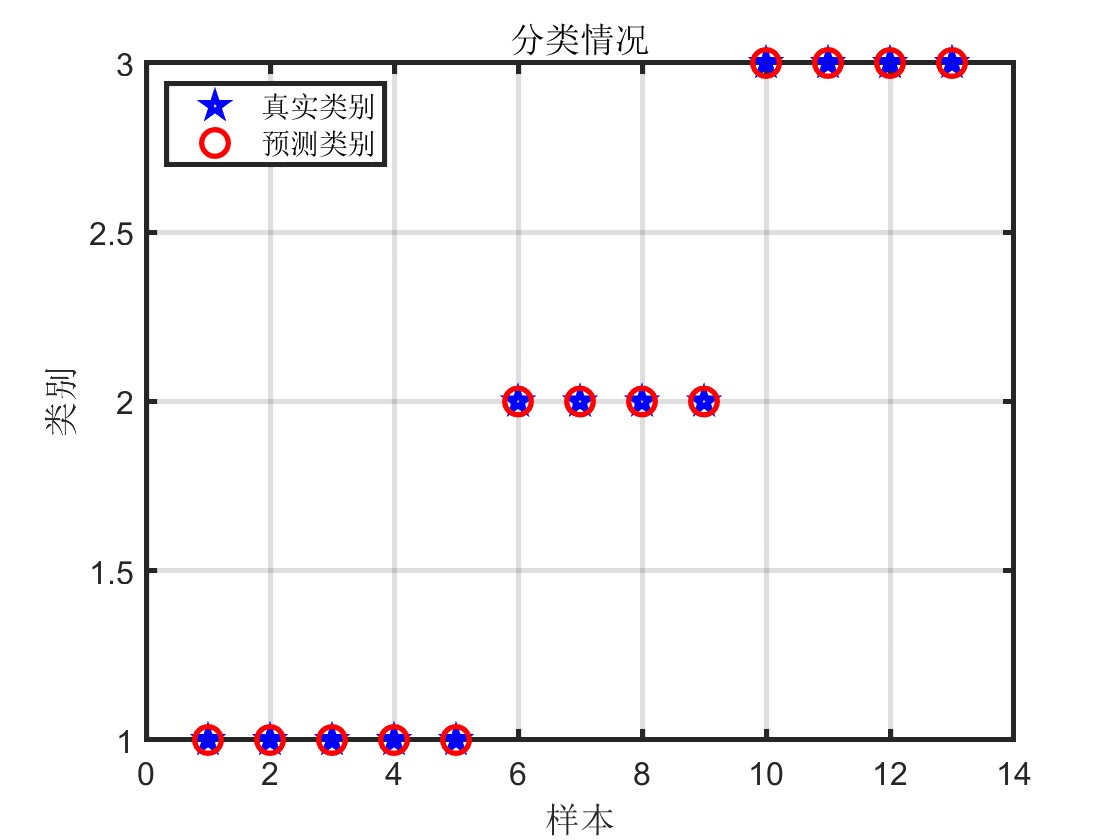
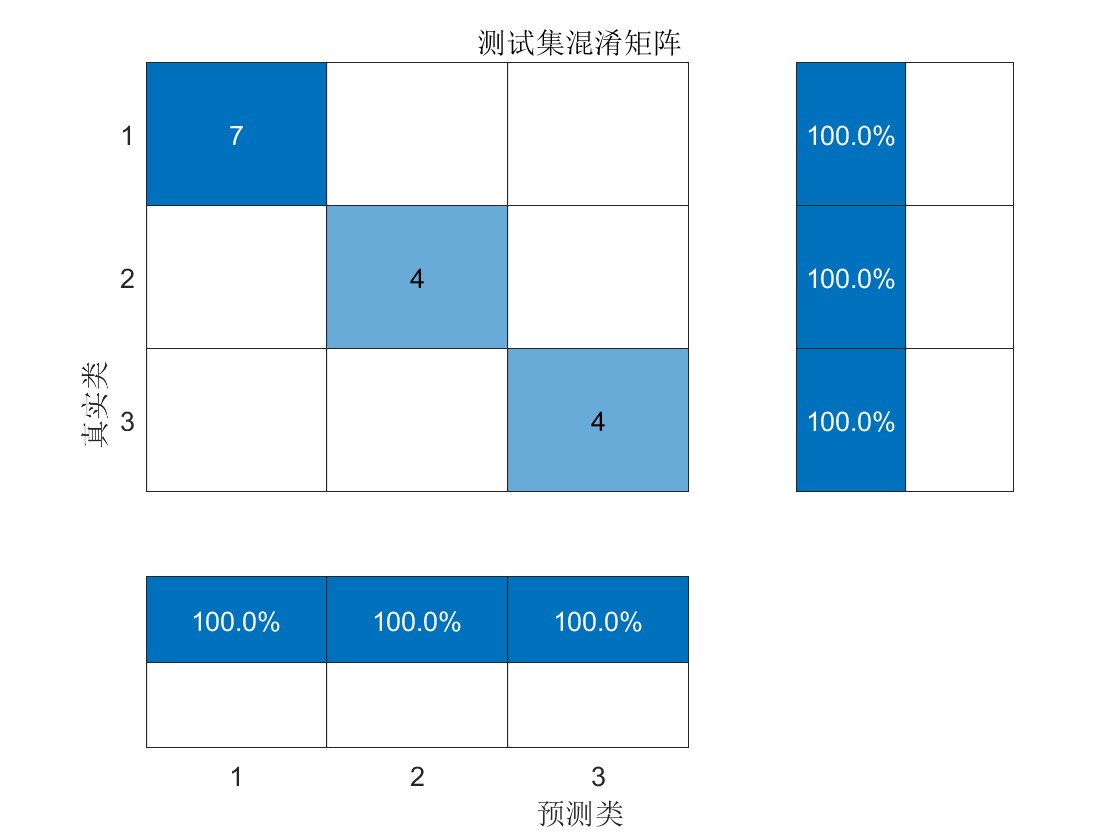
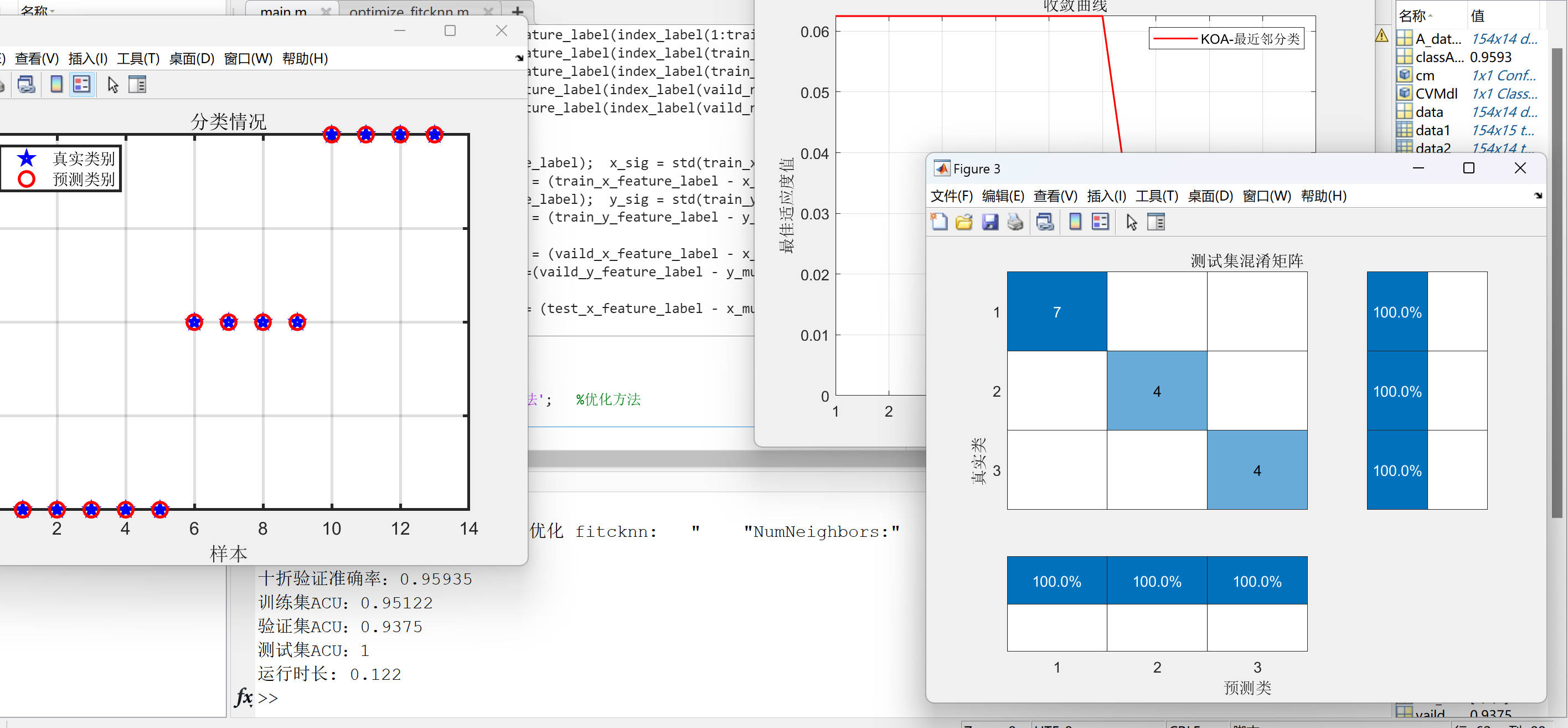
模型评估: 代码中通过十折交叉验证等方法评估了模型的性能,计算了训练集、验证集和测试集的准确率,并输出了十折验证准确率和运行时长。此外,还通过绘制分类情况图和混淆矩阵对模型的分类效果进行了可视化展示,帮助更直观地了解模型的性能和分类结果。
结果可视化: 通过绘制通过绘制KOA寻优过程收敛曲线、分类情况图和混淆矩阵,直观展示了模型的分类效果,有助于对模型性能进行直观分析和比较。
输出定量结果如下:
十折验证准确率:0.95935
训练集ACU:0.95122
验证集ACU:0.9375
测试集ACU:1
运行时长: 0.122
代码有中文介绍。
代码能正常运行时不负责答疑!
代码运行结果如下:

部分代码如下:
% 清除命令窗口、工作区数据、图形窗口、警告
clc;
clear;
close all;
warning off;
load('data.mat') data1=readtable('分类数据集.xlsx'); %读取数据
data2=data1(:,2:end);
data=table2array(data1(:,2:end));
data_biao=data2.Properties.VariableNames; %数据特征的名称
A_data1=data;
data_select=A_data1; %% 数据划分
x_feature_label=data_select(:,1:end-1); %x特征
y_feature_label=data_select(:,end); %y标签
index_label1=randperm(size(x_feature_label,1));
index_label=G_out_data.spilt_label_data; % 数据索引
if isempty(index_label) index_label=index_label1;
end
spilt_ri=G_out_data.spilt_rio; %划分比例 训练集:验证集:测试集
train_num=round(spilt_ri(1)/(sum(spilt_ri))*size(x_feature_label,1)); %训练集个数
vaild_num=round((spilt_ri(1)+spilt_ri(2))/(sum(spilt_ri))*size(x_feature_label,1)); %验证集个数
%训练集,验证集,测试集
train_x_feature_label=x_feature_label(index_label(1:train_num),:);
train_y_feature_label=y_feature_label(index_label(1:train_num),:);
vaild_x_feature_label=x_feature_label(index_label(train_num+1:vaild_num),:);
vaild_y_feature_label=y_feature_label(index_label(train_num+1:vaild_num),:);
test_x_feature_label=x_feature_label(index_label(vaild_num+1:end),:);
test_y_feature_label=y_feature_label(index_label(vaild_num+1:end),:);