DataX及使用
- 【一】DataX概述
- 【二】DataX架构原理
- 【1】设计理念
- 【2】框架设计
- 【3】运行流程
- 【4】调度决策思路
- 【5】DataX和Sqoop对比
- 【三】DataX部署
- 【四】DataX上手
- 【1】使用概述
- 【2】配置文件格式
- 【3】同步Mysql数据到HDFS
- 【五】DataX整合Springboot
【一】DataX概述
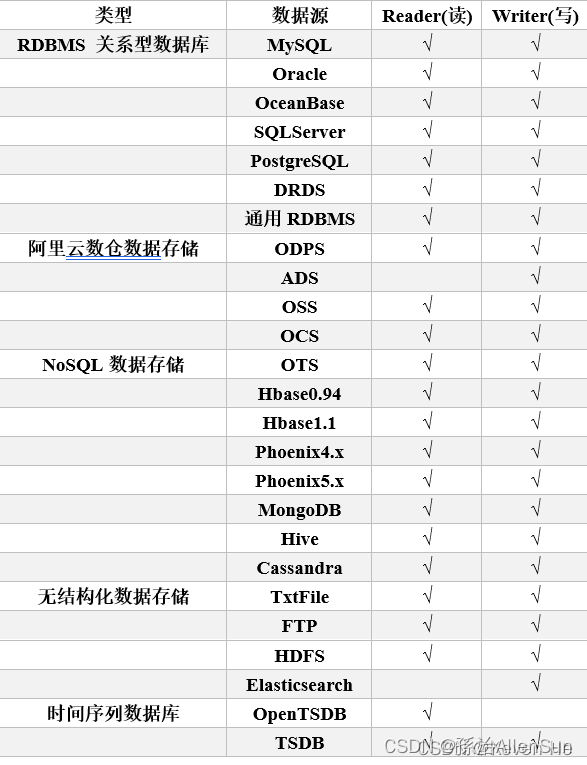
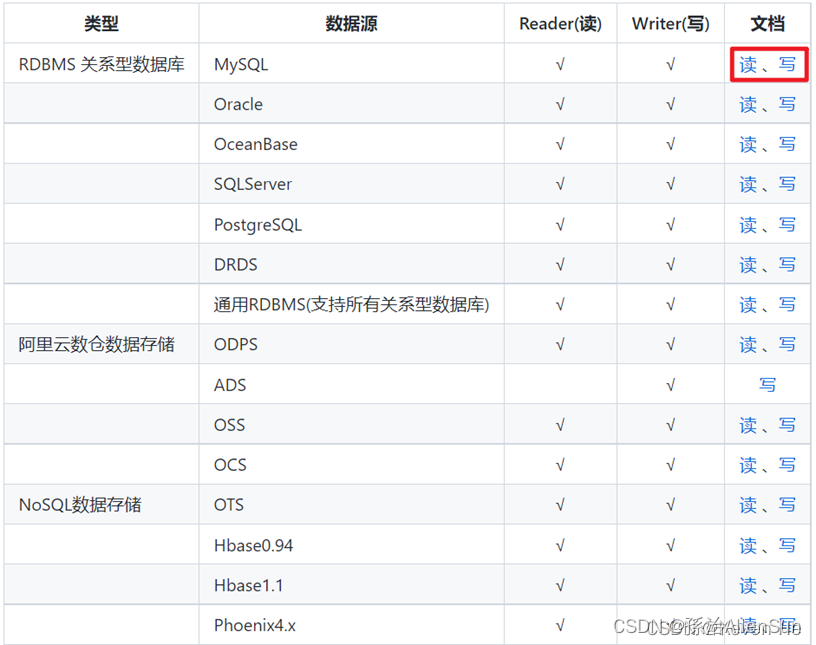
DataX是阿里巴巴开源的一个异构数据源离线同步工具,用于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
支持的数据源如下:
【二】DataX架构原理
【1】设计理念
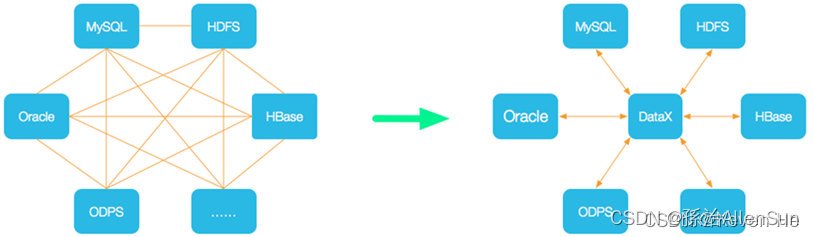
为了解决异构数据源同步问题,DataX把复杂的网状的同步链路变成了星型数据链路,DataX作为重甲传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要把此数据源对接到DataX,就能跟已有的数据源做到无缝数据同步。
【2】框架设计
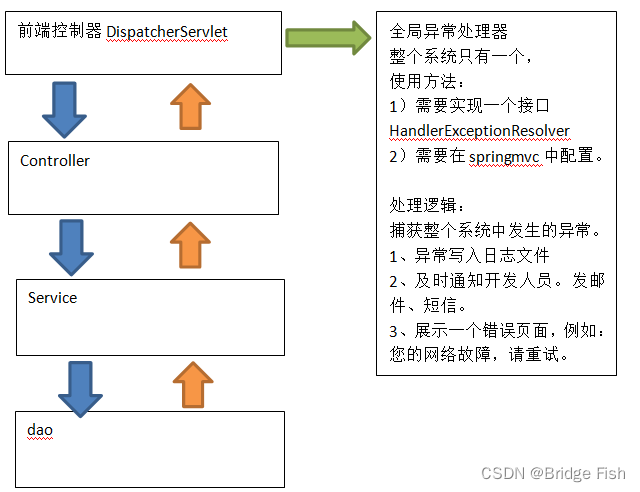
DataX本身作为离线数据同步框架,采用Framework+Plugin架构构建,把数据源读取和写入抽象成Reader/Writer插件,纳入到整个同步框架中。
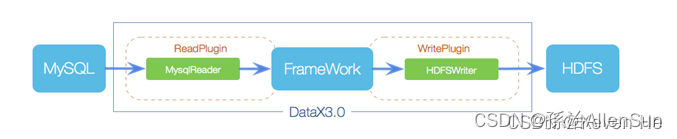
(1)Reader:数据采集模块,负责采集数据源的数据,把数据发给Framework
(2)Writer:数据写入模块,负责不断地向Framework取数据,并把数据写入到目的端
(3)Framework:用于连接Reader和Writer,作为两者的数据传输通道,并处理缓存、流控、并发、数据转换等核心问题
【3】运行流程
用一个DataX作业生命周期的时序图说明DataX的运行流程、核心概念和每个概念之间的关系
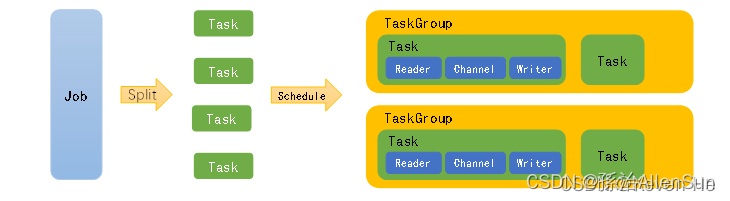
(1)Job:单个作业同步的作业,称为一个job,一个job启动一个进程
(2)Task:根据不同数据源切分策略,一个job会切分为多个task,task是DataX作业的最小单元,每个Task负责一部分数据的同步工作。
(3)TaskGroup:Scheduler调度模块对Task进行分组,每个Task组叫做一个Task Group,每个Task Group负责以一定的并发度运行其分得得Task,单个Task Group的并发度为5。
(4)Reader->Channel->Writer:每个Task启动后,都会固定启动Reader->Channel->Writer的线程来完成同步工作。
【4】调度决策思路
例子:用户提交了一个DataX作业,并且配置了总的并发度为20,目的是对一个有100张分表的mysql数据源进行同步。DataX的调度决策思路是:
(1)DataX Job根据分库分表切分策略,将同步工作分成100个Task。
(2)根据配置的总的并发度20,以及每个Task Group的并发度5,DataX计算共需要分配4个TaskGroup。
(3)4个TaskGroup平分100个Task,每一个TaskGroup负责运行25个Task。
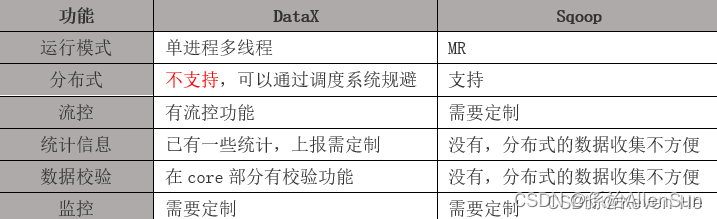
【5】DataX和Sqoop对比
【三】DataX部署
1)下载DataX安装包并上传到hadoop102的/opt/software
下载地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
2)解压datax.tar.gz到/opt/module tar -zxvf datax.tar.gz -C /opt/module
3)自检,执行如下命令python /opt/module/datax/bin/datax.py /opt/module/datax/job/job.json
出现如下内容,则表明安装成功
……
2021-10-12 21:51:12.335 [job-0] INFO JobContainer -
任务启动时刻 : 2021-10-12 21:51:02
任务结束时刻 : 2021-10-12 21:51:12
任务总计耗时 : 10s
任务平均流量 : 253.91KB/s
记录写入速度 : 10000rec/s
读出记录总数 : 100000
读写失败总数 : 0
【四】DataX上手
【1】使用概述
任务提交命令:用户需要根据同步数据的数据源和目的地选择相应的Reader和Writer,并将Reader和Writer的信息配置在一个json文件中,然后执行命令提交数据同步任务即可。python bin/datax.py path/to/your/job.json
【2】配置文件格式
查看DataX配置文件模板:python bin/datax.py -r mysqlreader -w hdfswriter
json最外层是一个job,job包含setting和content两部分,其中setting用于对整个job进行配置,content用户配置数据源和目的地。

Reader和Writer的具体参数参考官方文档:
https://github.com/alibaba/DataX/blob/master/README.md
https://gitee.com/mirrors/DataX/blob/master/README.md
【3】同步Mysql数据到HDFS
使用一个栗子来完成同步MySQL数据->HDFS的应用
要求:同步gmall数据库中base_province表数据到HDFS的/base_province目录
分析:需选用MySQLReader和HDFSWriter,MySQLReader具有两种模式分别是TableMode和QuerySQLMode,前者使用table,column,where等属性声明需要同步的数据;后者使用一条SQL查询语句声明需要同步的数据。