Netty系列整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】深入理解网络通信基本原理和tcp/ip协议 | https://zhenghuisheng.blog.csdn.net/article/details/136359640 |
| 【二】深入理解Socket本质和BIO | https://zhenghuisheng.blog.csdn.net/article/details/136549478 |
深入理解socket本质和bio底层实现
- 一, Socket本质和初识BIO
- 1,Socket
- 2,BIO
- 2.1,单线程场景
- 2.2,多线程场景
一, Socket本质和初识BIO
在上一篇中,讲解了网络通信的基本原理,以及tcp/ip层与应用层之间的关系,可以得知在 OSI 七层模型中,数据需要先通过应用层将数据转成报文,然后将报文从应用层中传向传输层,封装成报文段,依次将数据封装到网络层,数据链路层,物理层,最后再通过以太网,光纤将数据传到到对应的主机上。
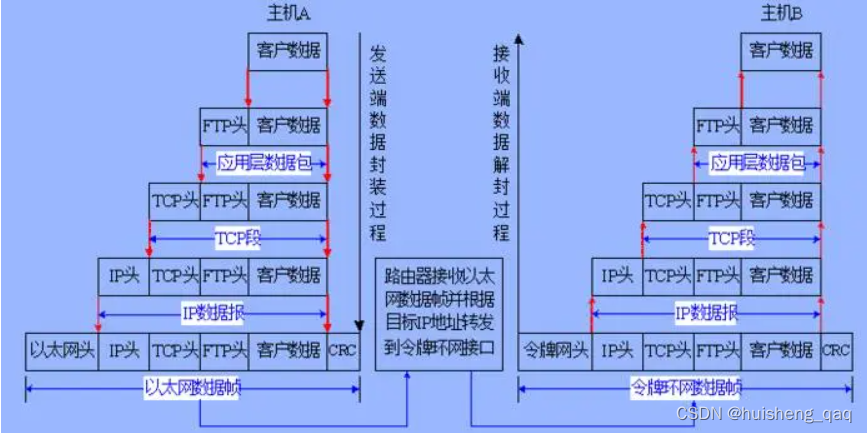
在网络编程中,由于tcp和ip已经有了对应的协议,因此在tcp层往下只需遵守对应的协议即可,因此在实际开发中,只需要将数据从应用层发送到传输层即可。
因此在操作系统的底层,封装了一个Socket,类似于一个中间件,用于应用层和传输层的TCP/IP协议族之间的通信,该中间层将所有与传输层连接的注意事项全部封装好,让开发者在开发无需关心底层的具体实现,更加的关注业务即可。如一些数据丢包的网络重传,滑动窗口等数据都会提前封装好。socket类似于sqlSession的功能,是一个门面模式,主要用于接收和转发,不做具体的执行功能。
在linux操作系统的源码中,会有一个 socket.c 的文件。在该文件中,里面已经封装了了应用层和tcp协议之间的细节,如如何建立连接,如何接受连接,如何监听,如何绑定等等都已经实现。因此对于网络应用程序来说,只需要与Socket进行交互即可。
1,Socket
客户端发送一条 hello word 到另一个客户端的流程如下,数据从客户端A的应用层再到传输层,再到网络层,再到数据链路层,再到物理层进行层层封包,通过以太网到客户端B的物理层,数据链路层,网络层,传输层,应用层进行层层解析,才能将数据进行解析出来
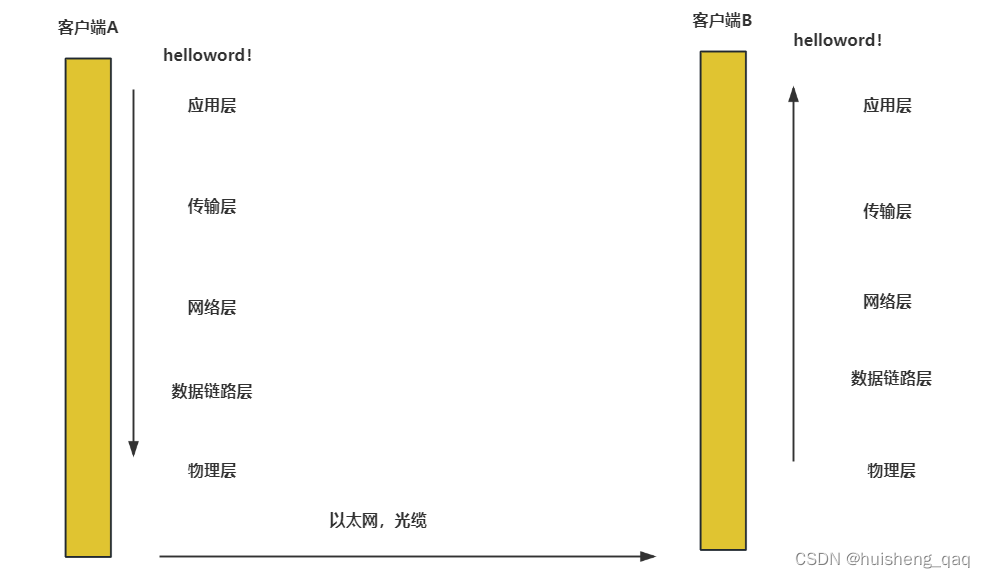
对于开发人员来说要实现层层的细节,肯定是不友好的。因此在操作系统底部,就为我们封装了一套socket,内部已经帮我们实现了tcp等协议的细节,让开发者更加的注重于业务上面的开发,其流程可以简化如下
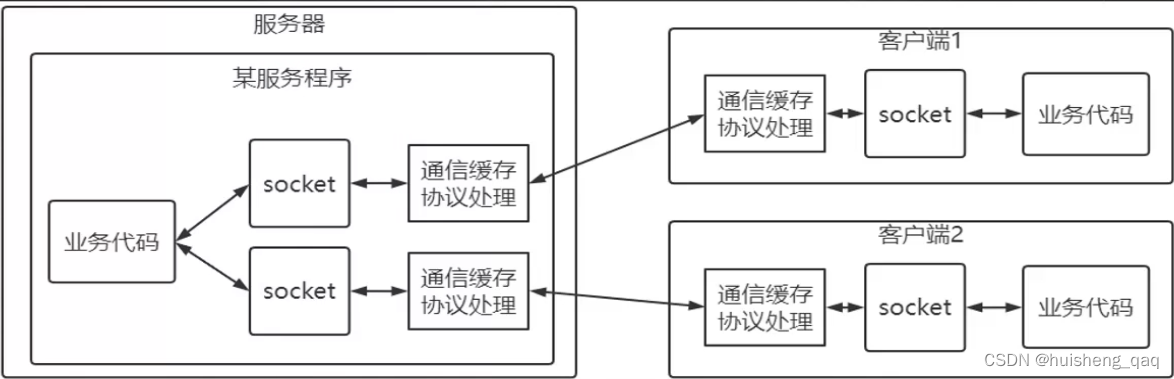
让开发者只需考虑应用层的业务代码实现,不需要考虑底层的实现细节。因此在网络编程中只需要关注三件事,就是客户端和服务端的连接、读网络数据、写网络数据
2,BIO
2.1,单线程场景
在原生网络编程中,使用BIO编程的比较多,BIO指的是 Blocking IO 阻塞式io,顾名思义,就是在进行io时,会出现阻塞的情况。
先看一段原生通过BIO来实现网络编程的代码,来了解BIO的基本使用和被阻塞的时机,先看一段服务端的代码。改代码中创建一个serverSocket,用于实现应用层和tcp层之间的交互,随后绑定了一个端口8089,当有客户端来访问这个服务的这个端口时,就会做出响应
package com.zhs.netty.bio;import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.net.InetSocketAddress;
import java.net.ServerSocket;
import java.net.Socket;/*** @author zhenghuisheng* @date 2024/3/7 22:31*/
public class BioServer {public static void main(String[] args) throws IOException {//创建一个socketServerSocket serverSocket = new ServerSocket();//服务端监听的端口号serverSocket.bind(new InetSocketAddress(8089));System.out.println("服务端开始监听");try{while(true){//监听事件Socket socket = serverSocket.accept();try{ObjectInputStream input = new ObjectInputStream(socket.getInputStream());ObjectOutputStream output = new ObjectOutputStream(socket.getOutputStream());//客户端传入的数据String readData = input.readUTF();System.out.println("成功接收到了数据" + readData);output.writeUTF("已经接收到了" + readData);}catch (Exception e){e.printStackTrace();}finally {socket.close();}}}catch (Exception e){e.printStackTrace();}finally {serverSocket.close();}}
}在启动这个服务端的时候,可以看出有如下信息打印,表示此时正被阻塞着,并且阻塞在这个accept的监听上
服务端开始监听
随后再编写一个客户端的代码。服务端中需要使用ServerSocket,在客户端中则需要使用Socket
package com.zhs.netty.bio;import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.net.InetSocketAddress;
import java.net.Socket;public class BioClient {public static void main(String[] args) throws IOException {//客户端启动必备Socket socket = null;//实例化与服务端通信的输入输出流ObjectOutputStream output = null;ObjectInputStream input = null;//服务器的通信地址InetSocketAddress addr = new InetSocketAddress("127.0.0.1",8089);try{socket = new Socket();socket.connect(addr);//连接服务器System.out.println("连接成功");output = new ObjectOutputStream(socket.getOutputStream());input = new ObjectInputStream(socket.getInputStream());System.out.println("Ready send message.....");/*向服务器输出请求*/output.writeUTF("zhenghuisheng");output.flush();//接收服务器的输出System.out.println(input.readUTF());}finally{if (socket!=null) socket.close();if (output!=null) output.close();if (input!=null) input.close();}}
}在启动完客户端之后,可以发现客户端打印的信息如下
连接成功
而在服务端中,由于接收到了客户端的请求,在服务端中也会将阻塞的代码继续往下执行
服务端开始监听
成功接收到了数据zhenghuisheng
除了服务端没有客户端来连接时会阻塞之外,在已经有一个客户端来连接且没释放,再来一个客户端进行连接时,此时的客户端也会出现阻塞的情况,假设在服务端刚开启之后,第一个客户端进行连接时在以下的代码处打一个debug断点阻塞在哪
output.writeUTF("zhenghuisheng");
此时第二个客户端来建立连接的代码如下,客户端这边不需要绑定具体的端口号,可以直接由操作系统进行分配即可,服务器的通信地址为刚刚设置的ip地址和端口号,目前设置的ip最地址为本地地址
package com.zhs.netty.bio;import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.net.InetSocketAddress;
import java.net.Socket;public class BioClient2 {public static void main(String[] args) throws IOException {//客户端启动必备Socket socket = null;//实例化与服务端通信的输入输出流ObjectOutputStream output = null;ObjectInputStream input = null;//服务器的通信地址InetSocketAddress addr = new InetSocketAddress("127.0.0.1",8089);try{socket = new Socket();socket.connect(addr);//连接服务器System.out.println("连接成功");output = new ObjectOutputStream(socket.getOutputStream());input = new ObjectInputStream(socket.getInputStream());System.out.println("Ready send message.....");/*向服务器输出请求*/output.writeUTF("zhenghuisheng2号");output.flush();//接收服务器的输出System.out.println(input.readUTF());}finally{if (socket!=null) socket.close();if (output!=null) output.close();if (input!=null) input.close();}}
}此时客户端2打印的信息如下,就是处于连接成功的状态
连接成功
但是在服务端这边,并不能够感知到第二个服务端来连接,也不能够做出响应。由于双端都是通过socket来进行数据的传输,包括三次握手等等,而客户端2可以连接成功,表示客户端2的socket和服务端的socket已经连接成功了,但是socket是操作系统的资源,由于服务器与一个客户端连接的socket还未释放连接,因此此时的服务端还没有来得及去处理第二个socket,当第一个socket正式的处理完数据传输以及响应,完成四次挥手之后,才可以去处理第二个建立的socket
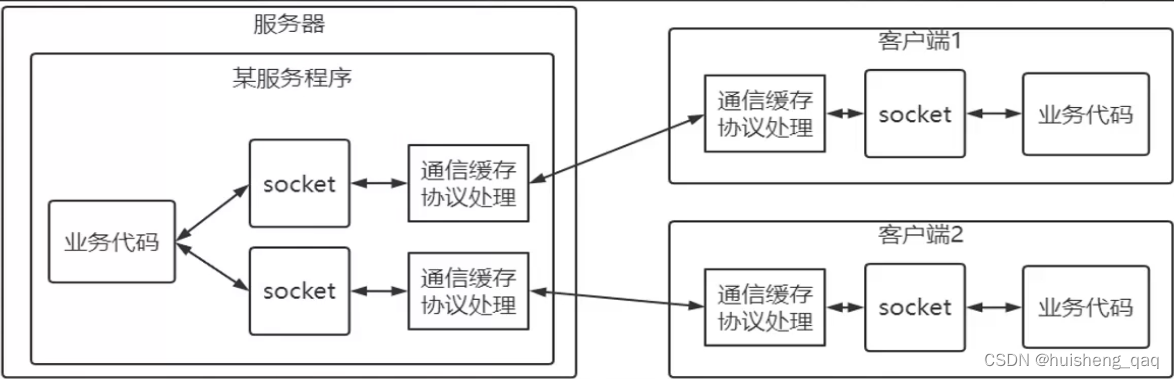
因此bio的阻塞就两个地方:
- 服务端没有接收到客户端请求时会阻塞
- 已有客户端再进行连接未释放时,新来的客户端连接也会被阻塞
2.2,多线程场景
如果仅仅只是在单线程中用BIO,那么拿过存在多个客户端连接服务端时,那么就会存在没被连接的客户端全部都被阻塞着,此时就是完全变成了串行执行,效率极其低下。但是也可以通过多线程去解决这个问题,每当一个客户端与服务端进行连接时,服务端就开启一个子线程去响应客户端的请求,而在实际开发中,一般都会通过线程池的方式去代替多线程,从而达到线程更好的管理和复用
如下面这段利用线程池的代码,每当一个客户端来进行连接时,就会通过线程池中的线程去执行这些任务
package com.zhs.netty.bio;import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.net.InetSocketAddress;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;public class ServerPool {private static ExecutorService executorService= Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());public static void main(String[] args) throws IOException {//服务端启动必备ServerSocket serverSocket = new ServerSocket();//表示服务端在哪个端口上监听serverSocket.bind(new InetSocketAddress(10001));System.out.println("Start Server ....");try{while(true){executorService.execute(new ServerTask(serverSocket.accept()));}}finally {serverSocket.close();}}//每个和客户端的通信都会打包成一个任务,交个一个线程来执行private static class ServerTask implements Runnable{private Socket socket = null;public ServerTask(Socket socket){this.socket = socket;}@Overridepublic void run() {//实例化与客户端通信的输入输出流try(ObjectInputStream inputStream =new ObjectInputStream(socket.getInputStream());ObjectOutputStream outputStream =new ObjectOutputStream(socket.getOutputStream())){//接收客户端的输出,也就是服务器的输入String userName = inputStream.readUTF();System.out.println("Accept client message:"+userName);//服务器的输出,也就是客户端的输入outputStream.writeUTF("Hello,"+userName);outputStream.flush();}catch(Exception e){e.printStackTrace();}finally {try {socket.close();} catch (IOException e) {e.printStackTrace();}}}}
}
但是也会出现一个问题,就是最大的连接数就是和核心线程数以及阻塞队列,核心线程数有关,根据io密集型和cpu密集型去考虑核心线程数的大小,而为了不丢失连接,阻塞队列肯定是越大越好,因此一般这种情况的最大连接数就是核心线程的个数,在一定的并发上会有一定的限制。
并且如果是io密集型的传输,如涉及大文件的io传输这种,那么整体效率就会底下,严重影响客户端的体验
由于BIO会存在着阻塞的缺陷以及并发量小的缺陷,因此随着网络编程的不断发展,BIO这种阻塞的方式使用的频率逐渐变小。