创作不易,感谢三连!
一、容器适配器
适配器是一种设计模式(设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设计经验的总结),该种模式是将一个类的接口转换成客户希望的另外一个接口。
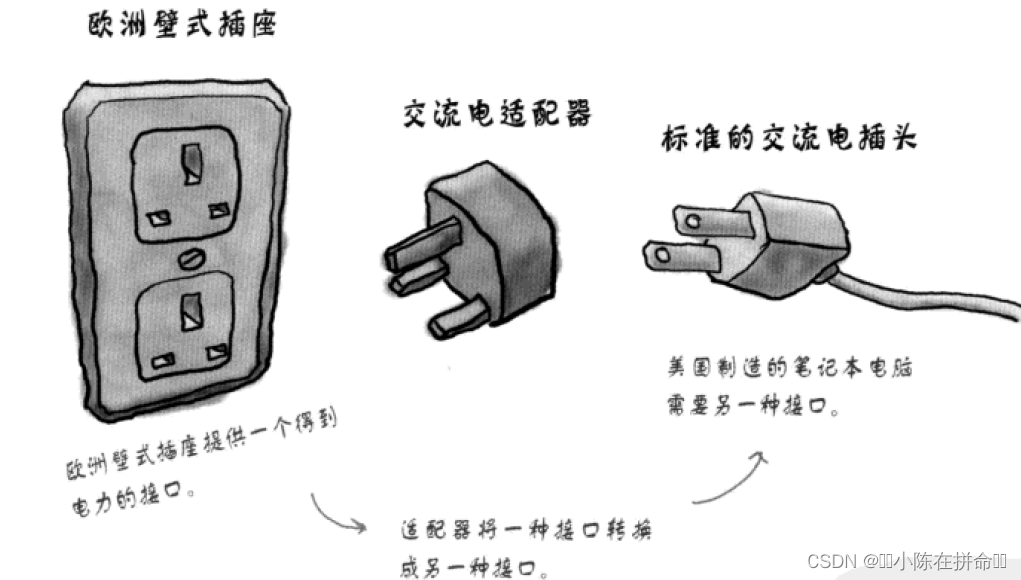
就如同是电源适配器将不适用的交流电变得适用一样,模板 B 将不适合直接拿来用的模板 A 变得适用了,因此我们可以将模板 B 称为 B 适配器。 容器适配器也是同样的道理,简单的理解容器适配器,其就是将不适用的序列式容器(包括 vector、deque 和 list)变得适用。 容器适配器的底层实现和模板 A、B 的关系是完全相同的,即通过封装某个序列式容器,并重新组合该容器中包含的成员函数,使其满足某些特定场景的需要。
二、deque的简单了解
我们知道,vector支持下标的随机访问,但是头部和中部插入删除效率低下,且需要频繁扩容,而list虽然任意位置插入删除高效,但是不支持随机访问,所以就有人在思考,能否找到一种数据结构可以替代他俩呢??于是就有了双端队列这个数据结构,但实际上双端队列并无法替代vector和list,并且后来成为了最适合stack和queue的底层容器,这就是典型的相当皇上没当成,却成了丫鬟。
deque(双端队列):是一种双开口的"连续"空间的数据结构,双开口的含义是:可以在头尾两端进行插入和删除操作,且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素;与list比较,空间利用率比较高。

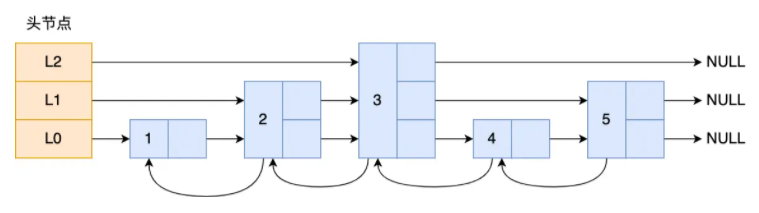
deque并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,实际deque类似于一个动态的二维数组,其底层结构如下图所示:

双端队列底层是一段假象的连续空间,实际是分段连续的,为了维护其“整体连续”以及随机访问的假象,重任落在了deque的迭代器身上。
下面我们进行总结:

我们可以看到:
1、与vector比较,deque的优势是:头部插入和删除时,不需要搬移元素,效率特别高,而且在扩容时,也不需要搬移大量的元素,因此其效率是必vector高的。
2、与list比较,其底层是连续空间,空间利用率比较高,不需要存储额外字段。
3、但是,deque有一个致命缺陷:不适合遍历,因为在遍历时,deque的迭代器要频繁的去检测其是否移动到某段小空间的边界,导致效率低下,而序列式场景中,可能需要经常遍历,因此在实际中,需要线性结构时,大多数情况下优先考虑vector和list。
4、deque的应用并不多,但我们发现他的头插头删和尾插尾删的效率特别高,所以目前能看到的一个应用就是,STL用其作为stack和queue的底层数据结构。
5、还有第二个缺陷就是:
(1)如果我们假定buff每个数组大小一样大,那么随机访问的效率就会高,因为我们减掉该层的当前元素,然后/10可以跳层,再%10就可以跳到该层对应的位置,但是需要中间的插入和删除的话,那么为了维持每层的数组大小,就可能需要挪动一堆数据。
(2)如果我们假定每个buff数组的大小不一样大,那么如果中间的插入删除就不需要挪数据了,效率会提高,但是随机访问的效率就会变低了,因为不知道每层有多少元素,所以无法直接跳层,而是要一个个去遍历才能访问到某个元素。
因此各有利弊不可兼得,在SGI版本下选择的是buff数组固定大小,所以他的迭代器设置得非常复杂。
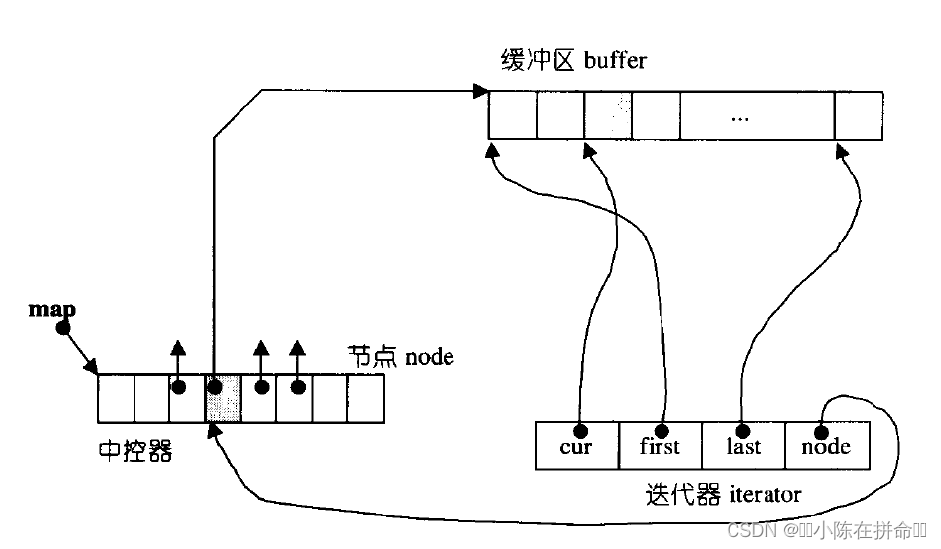
那deque是如何借助其迭代器维护其假想连续的结构呢?

三、Stack介绍
Stack文档介绍
1. stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中,其只能从容器的一端进行元素的插入与提取操作。
2. stack是作为容器适配器被实现的,容器适配器即是对特定类封装作为其底层的容器,并提供一组特定的成员函数来访问其元素,将特定类作为其底层的,元素特定容器的尾部(即栈顶)被压入和弹出。
3. stack的底层容器可以是任何标准的容器类模板或者一些其他特定的容器类,这些容器类应该支持以下操作:
empty:判空操作
back:获取尾部元素操作
push_back:尾部插入元素操作
pop_back:尾部删除元素操作
4. 标准容器vector、deque、list均符合这些需求,默认情况下,如果没有为stack指定特定的底层容器,默认情况下使用deque。


四、Queue介绍
Queue文档介绍
1. 队列是一种容器适配器,专门用于在FIFO上下文(先进先出)中操作,其中从容器一端插入元素,另一端提取元素。
2. 队列作为容器适配器实现,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特定的成员函数来访问其元素。元素从队尾入队列,从队头出队列。
3. 底层容器可以是标准容器类模板之一,也可以是其他专门设计的容器类。该底层容器应至少支持以下操作:
empty:检测队列是否为空
size:返回队列中有效元素的个数
front:返回队头元素的引用
back:返回队尾元素的引用
push_back:在队列尾部入队列
pop_front:在队列头部出队列
4. 标准容器类deque和list满足了这些要求。默认情况下,如果没有为queue实例化指定容器类,则使用标准容器deque。


五、为什么选择deque作为stack和queue的底层默认容器
stack是一种后进先出的特殊线性数据结构,因此只要具有push_back()和pop_back()操作的线性结构,都可以作为stack的底层容器,比如vector和list都可以;queue是先进先出的特殊线性数据结构,只要具有push_back和pop_front操作的线性结构,都可以作为queue的底层容器,比如list。但是STL中对stack和queue默认选择deque作为其底层容器,主要是因为:
1. stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进行操作。
2. 在stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的元素增长时,deque不仅效率高,而且内存使用率高。
所以结合了deque的优点,而完美的避开了其缺陷。
六、适配器模式下的stack模拟实现
using namespace std;
namespace cyx
{template<class T,class Container=deque<T>>// 可以用vectoe list deque作为适配器class stack{public:bool empty() const{return _con.empty();}size_t size() const{return _con.size();}const T& top() const{return _con.back();}T& top(){return _con.back();}void push(const T&val) {_con.push_back(val);}void pop(){_con.pop_back();}void swap(stack<T> &s){_con.swap(s._con);}private:Container _con;//适配器};七、适配器模式下的queue模拟实现
namespace cyx
{template<class T,class Container=deque<T>>//该适配器可以用list deque 如果是用vector不太合适,因为不支持头删class queue{public:bool empty() const{return _con.empty();}size_t size(){return _con.size();}T& front(){return _con.front();}const T& front() const {return _con.front();}T& back(){return _con.back();}const T& back() const{return _con.back();}void push(const T&val){_con.push_back(val);}void pop(){_con.pop_front();}void swap(queue<T> &q){_con.swap(q._con);}private:Container _con;};八、遍历的一般形式
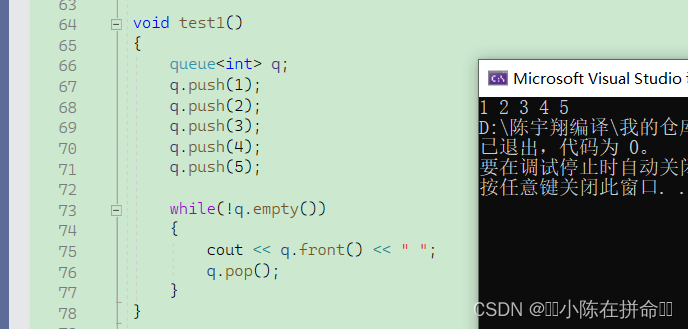
stack

queue