Playwright新WEB自动化测试框架
- 一,简介
- 二,下载和安装
- 三,简单使用
- 四,定位元素
- 五,操作
- 六,等待
- 七,断言
一,简介
Playwright 官方介绍https://playwright.dev/python/
跨浏览器和平台
- 跨浏览器。Playwright 支持所有现代渲染引擎,包括 Chromium、WebKit 和 Firefox。
- 跨平台。在Windows、Linux 和 macOS 上进行本地测试或在 CI 上进行无头或有头测试。
- 跨语言。在TypeScript、JavaScript、Python、.NET、Java中使用 Playwright API 。
- 测试移动网络。适用于 Android 和 Mobile Safari 的 Google Chrome浏览器的本机移动仿真。相同的渲染引擎适用于您的桌面和云端。
稳定性
- 自动等待。Playwright 在执行动作之前等待元素可操作。它还具有一组丰富的内省事件。两者的结合消除了人为超时的需要——这是不稳定测试的主要原因。
- Web优先断言。Playwright 断言是专门为动态网络创建的。检查会自动重试,直到满足必要的条件。
- 追踪。配置测试重试策略,捕获执行跟踪、视频、屏幕截图以消除薄片。
运行机制
浏览器在不同进程中运行属于不同来源的 Web 内容。Playwright 与现代浏览器架构保持一致,并在进程外运行测试。这使得 Playwright 摆脱了典型的进程内测试运行器的限制。
- 多重一切。测试跨越多个选项卡、多个来源和多个用户的场景。为不同的用户创建具有不同上下文的场景,并在您的服务器上运行它们,所有这些都在一次测试中完成。
- 可信事件。悬停元素,与动态控件交互,产生可信事件。Playwright 使用与真实用户无法区分的真实浏览器输入管道。
- 测试框架,穿透 Shadow DOM。Playwright 选择器穿透影子 DOM 并允许无缝地输入帧。
完全隔离-快速执行
- 浏览器上下文。Playwright 为每个测试创建一个浏览器上下文。浏览器上下文相当于一个全新的浏览器配置文件。这提供了零开销的完全测试隔离。创建一个新的浏览器上下文只需要几毫秒。
- 登录一次。保存上下文的身份验证状态并在所有测试中重用它。这绕过了每个测试中的重复登录操作,但提供了独立测试的完全隔离。
强大的工具
- 代码生成器。通过记录您的操作来生成测试。将它们保存为任何语言。
- 调试。检查页面、生成选择器、逐步执行测试、查看点击点、探索执行日志。
- 跟踪查看器。捕获所有信息以调查测试失败。Playwright 跟踪包含测试执行截屏、实时 DOM 快照、动作资源管理器、测试源等等。
二,下载和安装
python 版本要求 python3.7+ 版本。
安装 playwright:
pip install playwright
安装所需的浏览器 chromium,firefox 和 webkit:
playwright install
仅需这一步即可安装所需的浏览器,并且不需要安装驱动包了(解决了selenium启动浏览器,总是要找对应驱动包的痛点)
ps:如果安装报错,提示缺少Visual C++, 解决办法: 安装Microsoft Visual C++ Redistributable 2019
https://aka.ms/vs/16/release/VC_redist.x64.exe
直接点击就可以下载了,下载后直接安装即可。
启动本地 chrome 浏览器
如果你仅仅只需要在chrome浏览器上运行你的代码,那么是不需要执行playwright install下载 chromium,firefox 和 webkit。
首先你确保在你自己本机电脑上安装了chrome浏览器,并且安装是按默认的安装路径
那么在启动的时候,只需指定channel=‘chrome’ 就可以启动本地chrome 浏览器了。
from playwright.sync_api import sync_playwright
with sync_playwright() as p:browser = p.chromium.launch(channel='chrome', headless=False)context = browser.new_context()page = context.new_page()page.goto('http://xxx.xx.com')
如果遇到以下报错,说明你浏览器没正确安装,重新安装一次chrome浏览器,按默认的路径安装即可。
playwright._impl._api_types.Error: Chromium distribution 'chrome' is not found at C:\Users\dell\AppData\Local\Google\Chrome\Application\chrome.exe
Run "playwright install chrome"
离线安装chromium,firefox 和 webkit
如果你有安装chromium,firefox 和 webkit 这3个官方提供的内置浏览器的需求,那么接着往下看。
我们先看去哪里下载到这3个浏览器, 在终端执行以下命令
>playwright install --dry-run
它会根据你当前安装的playwright (我当前版本是1.32.1)版本,给出对应的浏览器最近匹配版本,以及下载地址(venv) D:\demo\down_line\down>playwright install --dry-run
browser: chromium version 112.0.5615.29Install location: C:\Users\dell\AppData\Local\ms-playwright\chromium-1055Download url: https://playwright.azureedge.net/builds/chromium/1055/chromium-win64.zipDownload fallback 1: https://playwright-akamai.azureedge.net/builds/chromium/1055/chromium-win64.zipDownload fallback 2: https://playwright-verizon.azureedge.net/builds/chromium/1055/chromium-win64.zipbrowser: firefox version 111.0Install location: C:\Users\dell\AppData\Local\ms-playwright\firefox-1391Download url: https://playwright.azureedge.net/builds/firefox/1391/firefox-win64.zipDownload fallback 1: https://playwright-akamai.azureedge.net/builds/firefox/1391/firefox-win64.zipDownload fallback 2: https://playwright-verizon.azureedge.net/builds/firefox/1391/firefox-win64.zipbrowser: webkit version 16.4Install location: C:\Users\dell\AppData\Local\ms-playwright\webkit-1811Download url: https://playwright.azureedge.net/builds/webkit/1811/webkit-win64.zipDownload fallback 1: https://playwright-akamai.azureedge.net/builds/webkit/1811/webkit-win64.zipDownload fallback 2: https://playwright-verizon.azureedge.net/builds/webkit/1811/webkit-win64.zipbrowser: ffmpegInstall location: C:\Users\dell\AppData\Local\ms-playwright\ffmpeg-1008Download url: https://playwright.azureedge.net/builds/ffmpeg/1008/ffmpeg-win64.zipDownload fallback 1: https://playwright-akamai.azureedge.net/builds/ffmpeg/1008/ffmpeg-win64.zipDownload fallback 2: https://playwright-verizon.azureedge.net/builds/ffmpeg/1008/ffmpeg-win64.zip
以 chromium 安装为例,先下载 https://playwright.azureedge.net/builds/chromium/1055/chromium-win64.zip 下载后是一个chromium-win64.zip压缩包。
接着看Install location 安装位置:C:\Users\dell\AppData\Local\ms-playwright\chromium-1055 按照这个路径依次创建文件夹,把压缩包放到chromium-1055下解压即可
python+playwright 学习-42 离线安装 playwright 环境_chrome_04
还有个 ffmpeg 包也需要按上面的路径正确解压,此包跟录制视频有关。
这样你本地就有了对应的chromium,firefox 和 webkit 环境。
在ms-playwright 目录下有以下四个文件

三,简单使用
Playwright 支持2种运行方式:同步和异步。以下为同步:
from playwright.sync_api import sync_playwrightwith sync_playwright() as p:browser = p.chromium.launch(headless=False, slow_mo=500, args=['--start-maximized']) # 启动 chromium 浏览器,slow_mo每步操作延迟500毫秒context = browser.new_context(no_viewport=True) # 创建上下文,no_viewport默认窗口最大化,需与上面的args配合使用page = context.new_page() # 打开一个标签页page.goto("https://www.baidu.com") # 打开百度地址print(page.title()) # 打印当前页面titlebrowser.close() # 关闭浏览器对象
如果不习惯with语句,也可以用start() 和stop() 的方式:
from playwright.sync_api import sync_playwright
playwright = sync_playwright().start()browser = p.chromium.launch(headless=False, slow_mo=500, args=['--start-maximized']) # 启动 chromium 浏览器,slow_mo每步操作延迟500毫秒
context = browser.new_context(no_viewport=True) # 创建上下文,no_viewport默认窗口最大化,需与上面的args配合使用
page = context.new_page() # 打开一个标签页
page.goto("https://www.baidu.com/")browser.close()
playwright.stop()
四,定位元素
playwright 可以通过 CSS selector, XPath selector, HTML 属性(比如 id, data-test-id)或者是 text 文本内容定位元素。
- Selector 选择器
操作元素,可以先定位再操作
# 先定位再操作
page.locator('#kw').fill("playwright")
page.locator('#su').click()
也可以直接调用fill 和 click 方法,传Selector选择器
page.fill('#kw', "playwright")
page.click('#su')
- CSS 或 XPath 选择器
可以使用xpath 和 css 元素
# CSS and XPath
page.fill('css=#kw', "playwright")
page.click('xpath=//*[@id="su"]')
当 DOM 结构发生变化时,这些选择器可能会中断。长 CSS 或 XPath 链是导致测试不稳定。
- text 文本选择器
文本选择器是一个非常实用的定位方式,根据页面上看到的text文本就可以定位了,比如我们经常在selenium中使用xpath 的文本选择器定位
完全匹配文本 //[text()=“百度一下”]
包含某个文本 //[contains(text(),“百度一下”)]
playwright 封装了text文本定位的方式,也可以支持2种文本定位方式
page.click("text=百度一下") # 模糊匹配
page.click("text='百度一下 '") # 完全匹配
ps:text=百度一下和 text=‘百度一下’ 的区别:
text=百度一下 没有加引号(单引号或者双引号),模糊匹配,对大小写不敏感
text=‘百度一下’ 有引号,精确匹配,对大小写敏感
- Selector 选择器组合定位
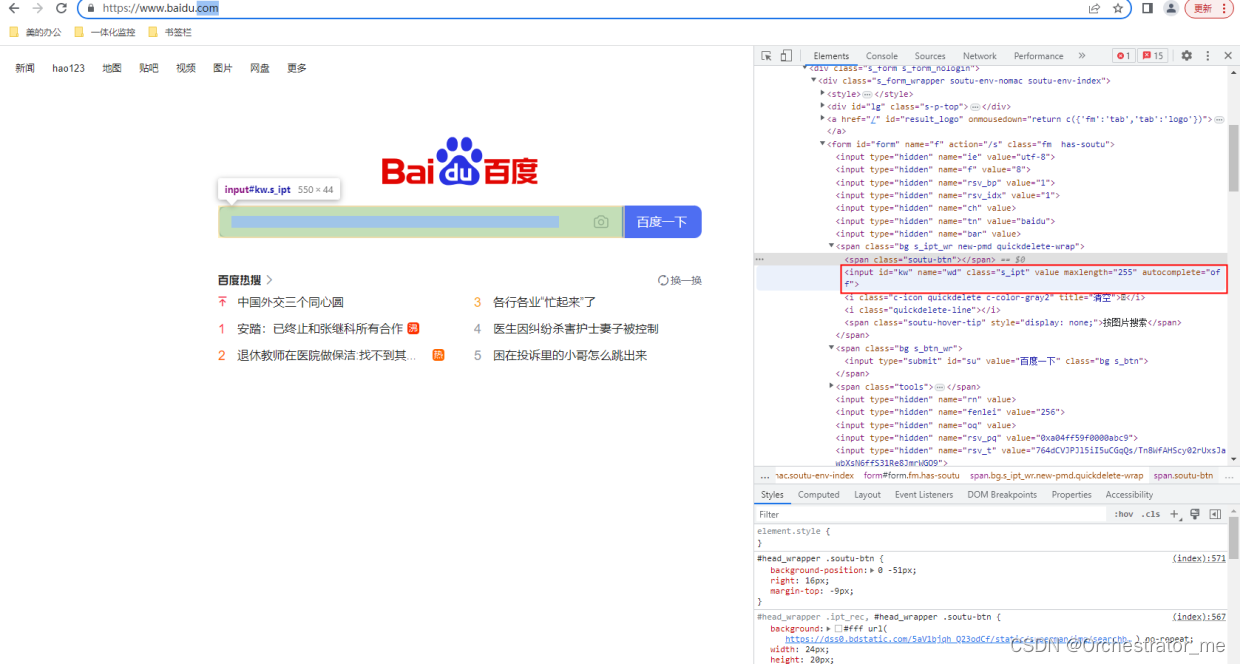
不同的selector可组合使用,用>>连接
form >> [name=“wd”] 定位方式等价于
page.locator("form").locator('[name="wd"]')
- 内置定位器
这些是 playwright 推荐的内置定位器。
page.get_by_role()通过显式和隐式可访问性属性进行定位。
page.get_by_text()通过文本内容定位。
page.get_by_label()通过关联标签的文本定位表单控件。
page.get_by_placeholder()按占位符定位输入。
page.get_by_alt_text()通过替代文本定位元素,通常是图像。
page.get_by_title()通过标题属性定位元素。
page.get_by_test_id()根据data-testid属性定位元素(可以配置其他属性)
五,操作
- fill() 输入文字
- Type 输入
一个字符一个字符地输入字段,就好像它是一个使用locator.type()的真实键盘的用户。
page.locator('#kw').type('playwright')
- 鼠标点击 click()
执行简单的人工点击。
# Generic click
page.get_by_role("button").click()# Double click
page.get_by_text("Item").dblclick()# Right click
page.get_by_text("Item").click(button="right")# Shift + click
page.get_by_text("Item").click(modifiers=["Shift"])# Hover over element
page.get_by_text("Item").hover()# Click the top left corner
page.get_by_text("Item").click(position={ "x": 0, "y": 0})
在幕后,这个和其他与指针相关的方法:
- 等待具有给定选择器的元素出现在 DOM 中 (不用自己去写轮询等待了)
- 等待它显示出来,即不为空,不display:none,不visibility:hidden (这个太人性化了,不用去判断元素是否隐藏)
- 等待它停止移动,例如,直到 css 转换完成
- 将元素滚动到视图中 (这个太人性化了,不用自己去滚动了)
- 等待它在动作点接收指针事件,例如,等待直到元素变得不被其他元素遮挡
- 如果元素在上述任何检查期间分离,则重试
由此可见,click() 方法优化了selenium 点击元素的遇到的一些痛点问题,比如元素遮挡,不在当前屏幕,元素未出现在DOM中或隐藏不可见等不可点击的状态。
- 文件上传
(1)您可以使用locator.set_input_files()方法选择要上传的输入文件。
它期望第一个参数指向类型为 的输入元素"file"。数组中可以传递多个文件。
如果某些文件路径是相对的,则它们将相对于当前工作目录进行解析。空数组清除所选文件。
# Select one file
page.get_by_label("Upload file").set_input_files('myfile.pdf')# Select multiple files
page.get_by_label("Upload files").set_input_files(['file1.txt', 'file2.txt'])# Remove all the selected files
page.get_by_label("Upload file").set_input_files([])# Upload buffer from memory
page.get_by_label("Upload file").set_input_files(files=[{"name": "test.txt", "mimeType": "text/plain", "buffer": b"this is a test"}],
)
(2)如果不是input输入框,必须点开文件框的情况
可以使用page.expect_file_chooser() 监听到弹出框,在弹出框上输入文件路径
with self.page.expect_file_chooser() as fc_info:self.page.get_by_placeholder("请选择文件").click()
file_chooser = fc_info.value
file_chooser.set_files("Upload file")
几个操作方法
file_chooser.element 返回与此文件选择器关联的输入元素。
file_chooser.is_multiple() 返回此文件选择器是否接受多个文件。
file_chooser.page 返回此文件选择器所属的页面。
设置与此选择器关联的文件输入的值。如果其中一些filePaths是相对路径,那么它们将相对于当前工作目录进行解析。对于空数组,清除所选文件。
file_chooser.set_files(files)
file_chooser.set_files(files, **kwargs)
几个参数
files pathlib.Path no_wait_after
启动导航的操作正在等待这些导航发生并等待页面开始加载。您可以通过设置此标志来选择退出等待。您仅在特殊情况下才需要此选项,例如导航到无法访问的页面。默认为false.
timeout 以毫秒为单位的最长时间,默认为 30秒,传递0以禁用超时。可以使用browser_context.set_default_timeout()或page.set_default_timeout()方法更改默认值。
(3)高级操作-事件监听filechooser
page.on("filechooser", lambda file_chooser: file_chooser.set_files(r"D:\tou.png"))# 点击选择文件按钮,会触发 filechooser 事件
page.get_by_label("选择文件").click()
page.on(“filechooser”, ) 会自动监听filechooser 事件,只要有点击了选择文件按钮,就会自动触发。
- focus()聚焦给定元素
对于处理焦点事件的动态页面,您可以使用locator.focus()聚焦给定元素。
page.get_by_label('password').focus()
-
drag_to 拖动
您可以使用locator.drag_to()执行拖放操作。此方法将:
将鼠标悬停在要拖动的元素上。
按鼠标左键。
将鼠标移动到将接收放置的元素。
松开鼠标左键。
page.locator("#item-to-be-dragged").drag_to(page.locator("#item-to-drop-at"))
如果您想精确控制拖动操作,请使用较低级别的方法,如locator.hover()、mouse.down()、mouse.move()和mouse.up()。
page.locator("#item-to-be-dragged").hover()
page.mouse.down()
page.locator("#item-to-drop-at").hover()
page.mouse.up()
如果您的页面依赖于dragover正在调度的事件,则您至少需要移动两次鼠标才能在所有浏览器中触发它。要可靠地发出第二次鼠标移动,请重复mouse.move()或locator.hover()两次。操作顺序是:悬停拖动元素,鼠标向下,悬停放置元素,第二次悬停放置元素,鼠标向上。
六,等待
- 强制等待
time.sleep() 不再使用
Playwright 在查找元素的时候具有自动等待功能,如果你在调试的时候需要使用等待,你应该使用page.wait_for_timeout(5000) 代替 time.sleep(5)并且最好不要等待超时。
page.wait_for_timeout(5000)
- 全局等待
设置全局导航超时和全局查找元素超时:
playwright 默认全局的导航时间是30秒,查找元素超时也是30秒, 有以下几个方法设置全局超时时间:
browser_context.set_default_navigation_timeout()
browser_context.set_default_timeout()
page.set_default_navigation_timeout()
page.set_default_timeout()
导航超时设置
当访问的网页加载很慢时
from playwright.sync_api import sync_playwright, expectwith sync_playwright() as p:browser = p.chromium.launch(headless=False)context = browser.new_context()page = context.new_page() # 访问浏览器页面page.goto('https://www.cnblogs.com/')
会报一个超时的异常:TimeoutError: Timeout 30000ms exceeded.
playwright._impl._api_types.TimeoutError: Timeout 30000ms exceeded.
=========================== logs ===========================
navigating to "https://www.cnblogs.com/", waiting until "load"
============================================================
可以在goto() 访问网站的时候设置timeout超时时间
# 访问浏览器页面
page.goto('https://www.cnblogs.com/', timeout=10000)
也可以设置全局超时
from playwright.sync_api import sync_playwright, expectwith sync_playwright() as p:browser = p.chromium.launch(headless=False)context = browser.new_context() # 设置全局40秒超时context.set_default_navigation_timeout(40000)page = context.new_page() # 访问浏览器页面page.goto('https://www.cnblogs.com/')
设置全局导航超时
set_default_navigation_timeout 设置的时间只对以下方法有效:
page.go_back()
page.go_forward()
page.goto()
page.reload()
page.set_content()
page.expect_navigation()
设置全局超时有2种方式:
方式1.在context对象设置全局导航页面超时
# context
context.set_default_navigation_timeout(40000)
方式2.在page对象设置全局导航页面超时
# page 页面对象超时 20秒page.set_default_navigation_timeout(20000)
如果goto()和page对象,context 对象都有设置超时时间
from playwright.sync_api import sync_playwright, expectwith sync_playwright() as p:browser = p.chromium.launch(headless=False)context = browser.new_context()# 设置全局context 40秒超时context.set_default_navigation_timeout(40000)page = context.new_page()# page 页面对象超时 20秒page.set_default_navigation_timeout(20000)# 访问浏览器页面page.goto('https://www.cnblogs.com/', timeout=1000)
那么goto()设置的优先级大于page对象,page对象设置的大于context对象设置的超时时间。
设置操作元素超时
默认情况下,操作元素时,查找元素超时时间是30秒
# 操作元素
page.locator('text=找不到元素').click()
点击元素时,找不到会报超时异常TimeoutError: Timeout 30000ms exceeded.
playwright._impl._api_types.TimeoutError: Timeout 30000ms exceeded.
=========================== logs ===========================
waiting for locator("text=找不到元素")
============================================================
可以针对单次操作click() 方法传timeout 参数
page.locator('text=找不到元素').click(timeout=1000)
设置全局操作元素timeout 超时
context = browser.new_context()
context.set_default_timeout(3000)
page = context.new_page()
page.set_default_timeout(2000)
与前面设置导航超时时间一样,也是可以在context 和page对象设置timeout。
优先级:单次操作设置的timeout > page.set_default_timeout() > context.set_default_timeout()
需注意的是:set_default_timeout设置的时间不仅仅对操作元素有效,对前面的页面导航也会生效。
set_default_timeout 与 set_default_navigation_timeout 优先级:
page.set_default_navigation_timeout() > page.set_default_timeout() > browser_context.set_default_navigation_timeout() > browser_context.set_default_timeout()
七,断言
- 通用断言assert
# 获取文本内容,进行断言content = page.text_content('[target="_blank"]:first-child')assert content == "新闻"# 获取内部文字,进行断言text = page.inner_text('[target="_blank"]:first-child')assert text == "新闻"# 获取属性值,进行断言attribute = page.get_attribute('#su', 'value')assert attribute == "百度一下"# 复选框状态,进行断言page.hover('//*[@id="u1"]/*[text()="设置"]')page.click('//*[@id="s-user-setting-menu"]//*[text()="搜索设置"]')checked = page.is_checked('//*[text()="全部语言"]')assert checked# JS表达式,进行断言js_content = page.locator('[data-index="4"]>a>[class="title-content-title"]').text_content()assert js_content == "长津湖超战狼2成中国影史票房冠军"
- expect断言
| 断言(真) | 断言(假) | 描述 |
|---|---|---|
| expect(locator).to_be_checked() | expect(locator).not_to_be_checked() | 复选框已/未选中 |
| expect(locator).to_be_disabled() | expect(locator).not_to_be_disabled() | 元素已/未禁用 |
| expect(locator).to_be_editable() | expect(locator).not_to_be_editable() | 元素是可/不可编辑的 |
| expect(locator).to_be_empty() | expect(locator).not_to_be_empty() | 容器为空/非空 |
| expect(locator).to_be_enabled() | expect(locator).not_to_be_enabled() | 元素已/未启用 |
| expect(locator).to_be_focused() | expect(locator).not_to_be_focused() | 元素已/未聚焦 |
| expect(locator).to_be_hidden() | expect(locator).not_to_be_hidden() | 元素不可见/可见 |
| expect(locator).to_be_visible() | expect(locator).not_to_be_visible() | 元素可见/不可见 |
| expect(locator).to_contain_text() | expect(locator).not_to_contain_text(expected ) | 元素包含/不包含文本 |
| expect(locator).to_have_attribute() | expect(locator).not_to_have_attribute(name, value ) | 元素具有/无 DOM 属性 |
| expect(locator).to_have_class() | expect(locator).not_to_have_class(expected ) | 元素具有/无类属性 |
| expect(locator).to_have_count() | expect(locator).not_to_have_count(count ) | 列表包含/不包含确切的孩子数 |
| expect(locator).to_have_css() | expect(locator).not_to_have_css(name, value ) | 元素具有/无 CSS 属性 |
| expect(locator).to_have_id() | expect(locator).not_to_have_id() | 元素具有/无 ID |
| expect(locator).to_have_js_property() | expect(locator).not_to_have_js_property(name, value) | 元素具有/无 JavaScript 属性 |
| expect(locator).to_have_text() | expect(locator).not_to_have_text(expected ) | 元素匹配/不匹配文本 |
| expect(locator).to_have_value() | expect(locator).not_to_have_value(value ) | 输入具有/无值 |
| expect(locator).to_have_values() | expect(locator).not_to_have_values(values ) | 选择已/未选择的选项 |
| expect(page).to_have_title() | expect(page).not_to_have_title() | 页面有/无标题 |
| expect(page).to_have_url() | expect(page).not_to_have_url() | 网页包含/不包含网址 |
| expect(api_response).to_be_ok() | expect(api_response).not_to_be_ok() | 响应具有/无“正常”状态 |
自定义预期消息
可以将自定义错误消息指定为函数的第二个参数,例如:expect
expect(page.get_by_text("Name"), "should be logged in").to_be_visible()
设置自定义超时
可以为全局断言或按断言指定自定义超时。默认超时为 5 秒。
全局超时
conftest.py
from playwright.sync_api import expectexpect.set_options(timeout=10_000)
每个断言超时
test_foobar.py
from playwright.sync_api import expectdef test_foobar(page: Page) -> None:expect(page.get_by_text("Name")).to_be_visible(timeout=10_000)


![[C++]类和对象,explicit,static,友元,构造函数——喵喵要吃C嘎嘎4](https://img-blog.csdnimg.cn/direct/488a74bb97bf4690b065600fd08fc5a4.png)