1.深浅拷贝

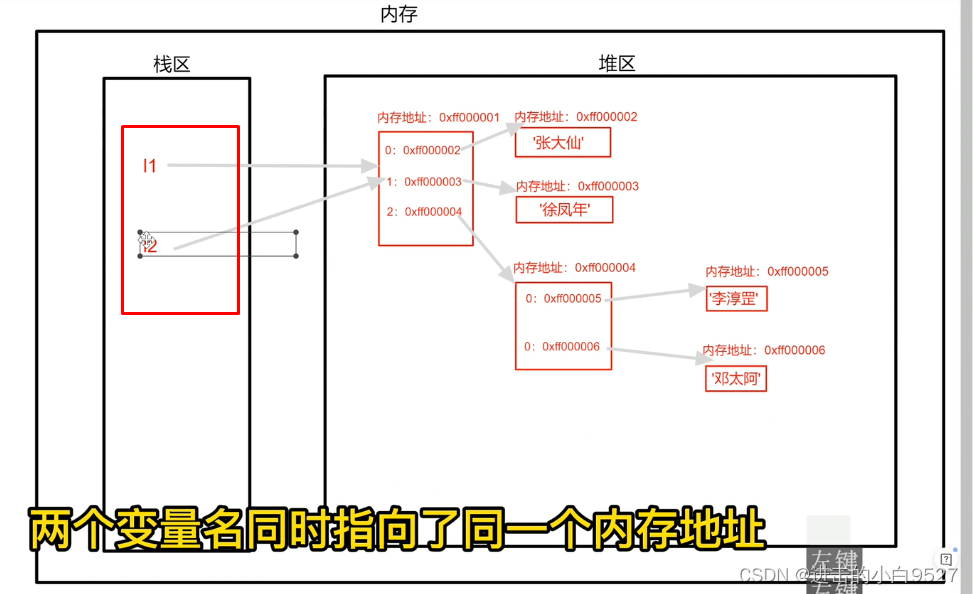
l1 = ["张大仙","徐凤年",["李淳刚","邓太阿"]]
# 变量名对应的就是内存地址,这里就是将l1的内存地址给了l2
# 现在两个变量指向同一个内存地址,l1变化l2也会变化
l2 = l1现在的需求是l2是l1的拷贝版本,但是两者是完全分割开来的,l2修改之后不能影响我l1的数据
1.1 浅拷贝
l3 = l1.copy()
l1和l3 列表的id不一样但是里面存储内容的id却是一样的
拷贝的列表只是拷贝的容器本身,只是产生了一个新的容器,但是里面的数据还是原来的数据
l1 = ["张大仙", "徐凤年", ["李淳刚", "邓太阿"]]
# 变量名对应的就是内存地址,这里就是将l1的内存地址给了l2
# 现在两个变量指向同一个内存地址,l1变化l2也会变化
# l2 = l1l3 = l1.copy()print(l1, id(l1)) # ['张大仙', '徐凤年', ['李淳刚', '邓太阿']] 4553523080
print(l3, id(l3)) # ['张大仙', '徐凤年', ['李淳刚', '邓太阿']] 4555309832
print(id(l1[0]), id(l1[1]), id(l1[2])) # 4353425648 4354327536 4353425224
print(id(l3[0]), id(l3[1]), id(l3[2])) # 4353425648 4354327536 4353425224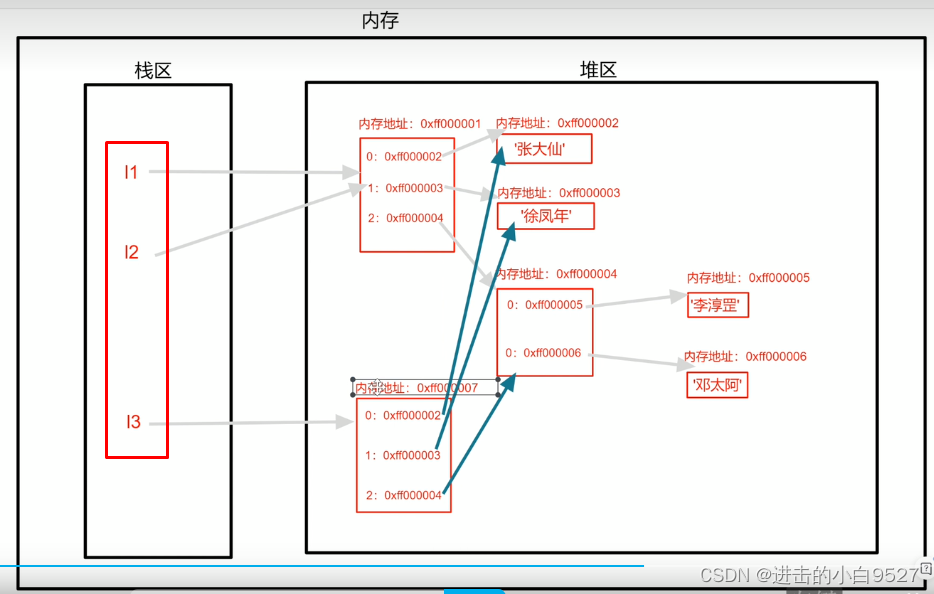
浅拷贝后,发现l3确实被改变了,但是l1的子列表也发生了变化
l1 = ["张大仙", "徐凤年", ["李淳刚", "邓太阿"]]
l3 = l1.copy()
l3[0] = "张坦克"
l3[1] = "徐晓"
l3[2][0] = "小明"
l3[2][1] = "小李"
print(l1) # ['张大仙', '徐凤年', ['小明', '小李']]
print(l3) # ['张坦克', '徐晓', ['小明', '小李']]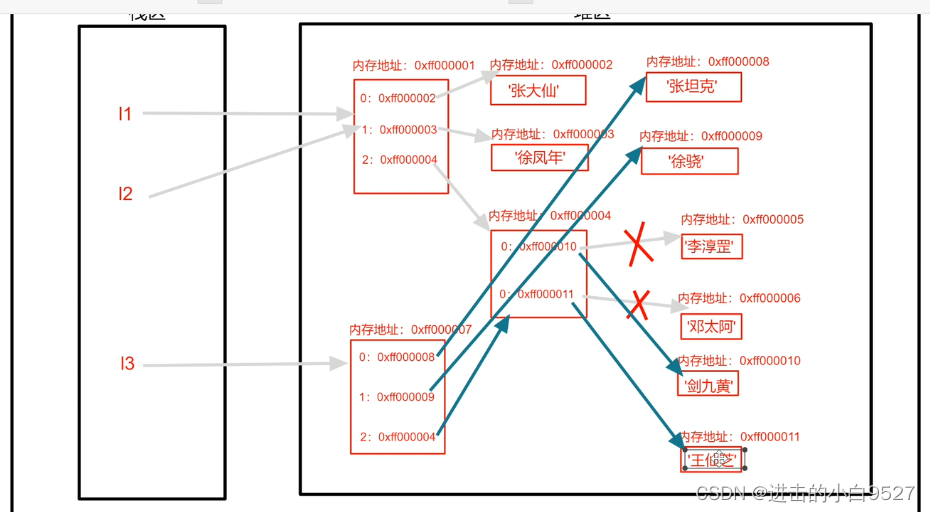
因为浅拷贝只会将原列表的第一层里面的索引和内存地址一模一样的拷贝到新的内存空间里面,由于列表里面的第一个和第二个元素是字符串,不可变类型,所以修改l3时,又会申请新的内存空间.但是由于列表是可变类型,我们修改其子列表的时候,它的内存地址是不会变的.所以l1和l3里面存的还是原来的子列表的内存地址,但是子列表的数据却被改掉了.
浅拷贝会把原列表第一层存的索引和内存地址完全拷贝一份给新的列表,如果原列表存储的都是不可变类型,浅拷贝就可以正常使用,新列表改动之后就会产生新的值,不会影响原来的列表.但是一旦包含了可变类型浅拷贝的原列表就没办法和原列表完全分开.
1.2 深拷贝
深拷贝针对不可变对象,第一层的索引和内存地址是一模一样的,但是对于可变对象,深拷贝会产生一个新的内存地址,但是还是使用的是原来的值
深拷贝针对可变类型会产生新的容器,可对不可变类型则是仍然使用原值

l1 = ["张大仙", "徐凤年", ["李淳刚", "邓太阿"]]
import copyl3 = copy.deepcopy(l1)print(l1, id(l1)) # ['张大仙', '徐凤年', ['李淳刚', '邓太阿']] 4325347208
print(l3, id(l3)) # ['张大仙', '徐凤年', ['李淳刚', '邓太阿']] 4327146568print(id(l1[0]), id(l1[1]), id(l1[2])) # 4479013104 4479914992 4479012680
print(id(l3[0]), id(l3[1]), id(l3[2])) # 4479013104 4479914992 4480805448
print(id(l1[2][0]), id(l1[2][1])) # 4470445136 4470445232
print(id(l3[2][0]), id(l3[2][1])) # 4470445136 4470445232l3[0] = "张坦克"
l3[1] = "徐晓"
l3[2][0] = "小明"
l3[2][1] = "小李"print(l1) # ['张大仙', '徐凤年', ['李淳刚', '邓太阿']]
print(l3) # ['张坦克', '徐晓', ['小明', '小李']]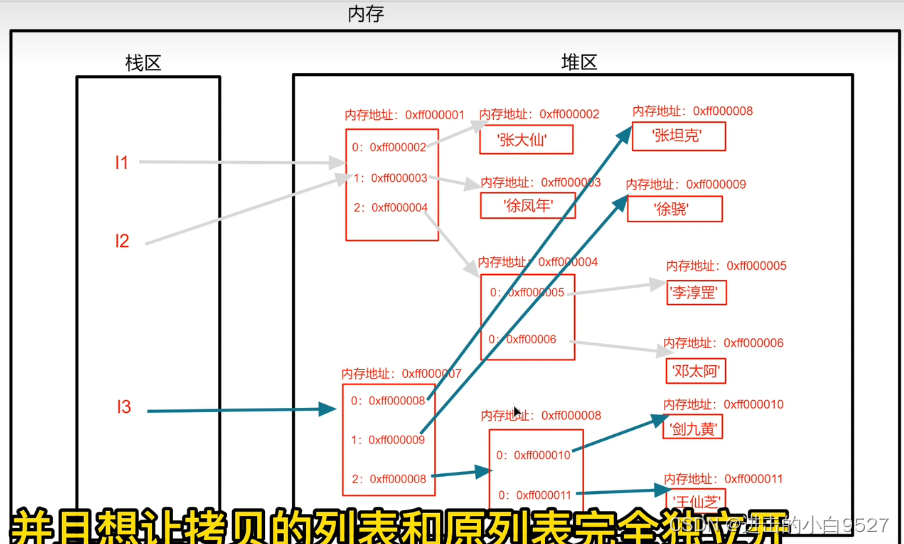
2.变量
2.0 储存
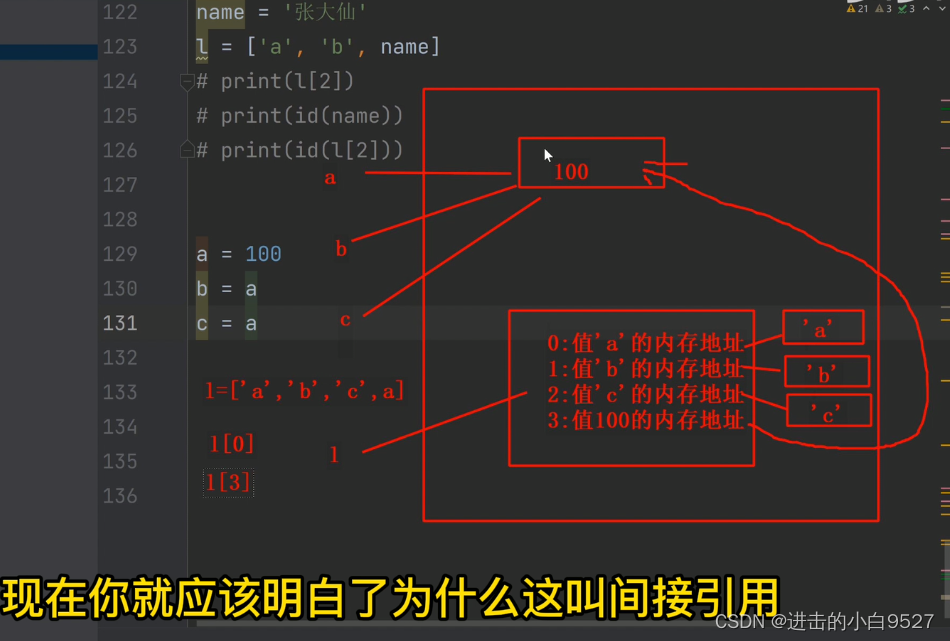
图
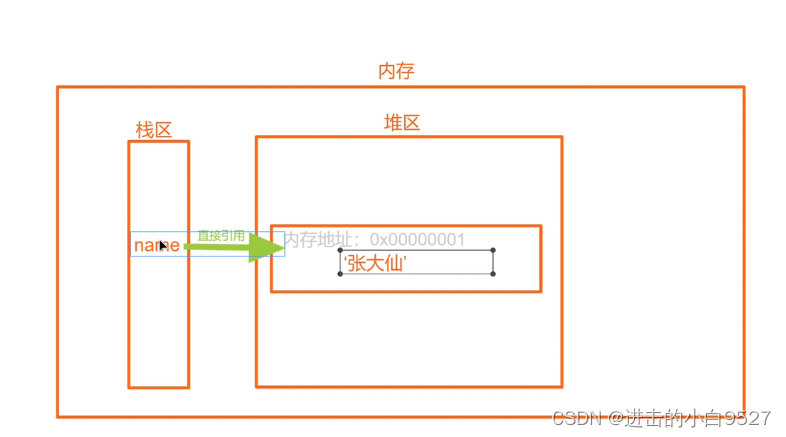
我们在定义一个变量的时候,它有两部分需要储存.一部分是变量名,一部分是变量值.在内存里面也是对应两块内存空间栈区是专门用来存放变量名的,堆区则是专门用来存放变量值的当定义一个name="张大仙"的时候,会先在堆区里面申请一块内存空间,把值张大仙存储进去.对应一个内存地址.在栈区里面放一个name,对应上刚刚的内存地址.当堆区的内存地址引用计数为0被清除的时候,对应栈区的变量名也会被清除
2.1 内存管理
定义变量就是在内存里面开辟了一个内存空间,然后将一个空间的内存地址捆绑给了变量名,通过这个变量名,我们就可以找到这个对应的值在哪.我们知道定义变量是要占用内存空间的,但是内存空间的大小是有限的.这时候就有一个问题,就是你申请的内存空间,不用了一定要及时的释放出来.否则的话,你将内存撑爆了的话就会导致内存溢出的问题,这个操作就叫做内存管理.
而python推出了一个内存管理机制,被叫做"垃圾回收机制",垃圾回收机制就是用来回收这种没有关联任何变量名的值.而这也涉及到一个概念叫做"引用计数",也就是一个内存空间身上捆绑了几个变量名.引用计数变为0的时候它就是一个垃圾
2.2 垃圾回收机制
2.2.1 引用计数的增加
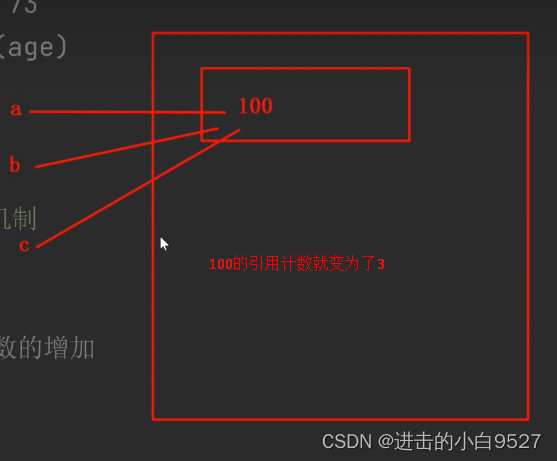
a =100
申请一个内存空间将100 存进去,然后给这个内存空间绑定一个变量名叫a,a指向的就是100的内存地址
b = a
将a的内存地址给b,这时候a和b指向的就是同一个内存地址
c = a
现在 a b c指向的都是同一个内存地址
2.2.2 引用计数的减少
del a
表面上看是删除a,实际上是解除a与100身上的绑定关系
a = 100
b = a
c = a
del a
print(a)
del b
c = 123 # c会和100的绑定关系解除,重新指向123的内存地址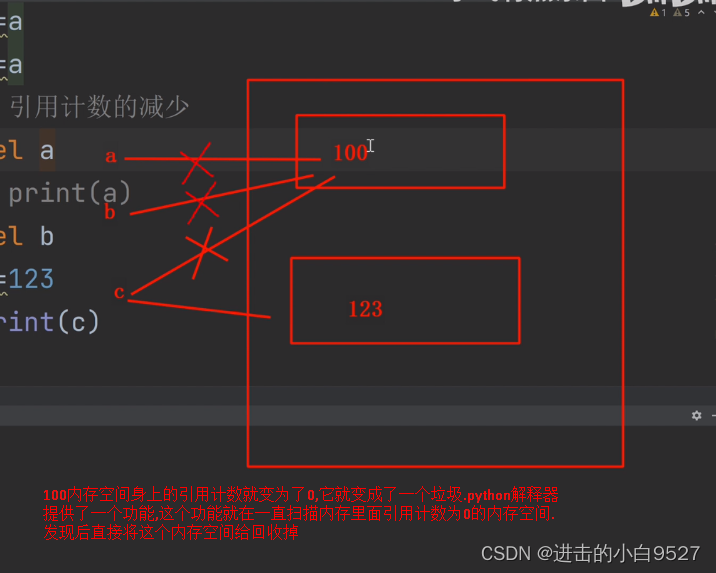
2.3 变量值特征
1) id: 根据变量值的内存地址所计算出来的一个id号码,类似于内存地址的映射.变量值的内存地址不一样,id就会不一样
2) type:查看变量值的类型
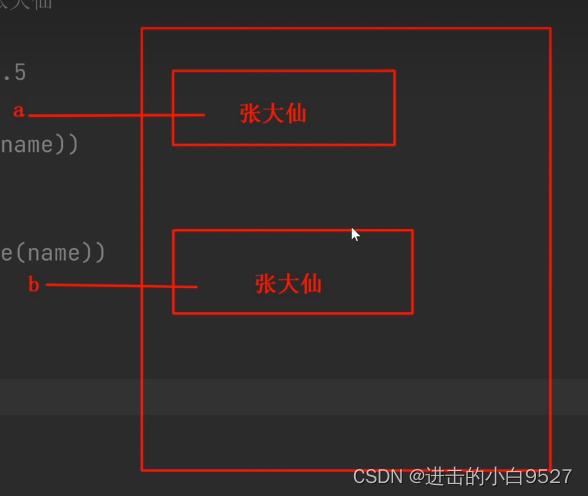
2.4 is和==的区别
1) is叫做身份运算,是用来比较左右两个值的身份是否相等的,而变量值的身份证号就是id号,所以is就是用来比较两个变量值的id是否相等的
2) == 是用来比较左右变量的值是否是相等的
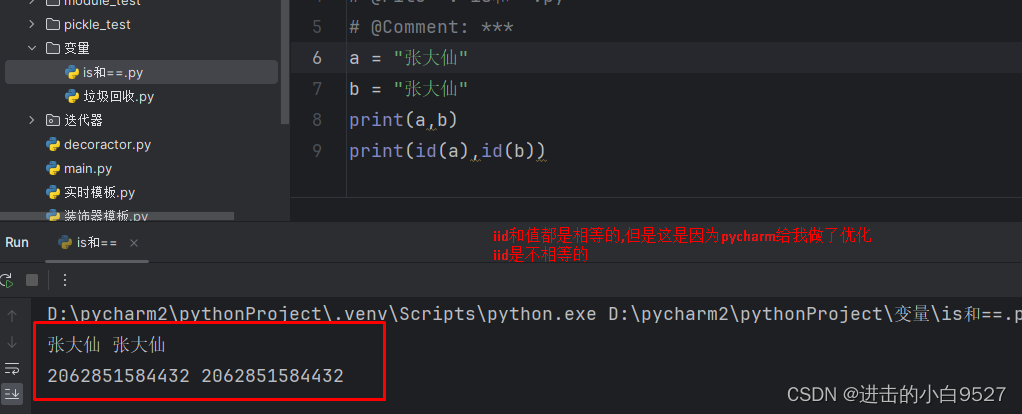
将代码直接使用python解释器来运行
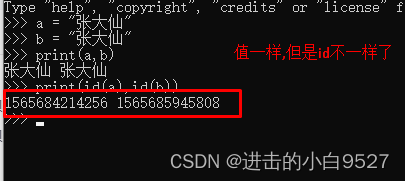
所以只要是赋值操作,产生新的值的时候,都会申请一块新的内存空间,只要是申请了新的内存空间,它的内存地址就会不一样,id就会不一样.
2.5 小整数池的概念
申请内存空间将值存进去,这就是一种写操作,IO操作,不管是往硬盘里面读写还是往内存读写数据,这都是IO操作.这都是耗时的,python给我们做了优化,叫做小整数池.为了避免因创建相同的值,而重复申请内存空间带来的效率问题,python解释器会在启动的那一刻创建出小整数池(-5,256).就是python解释器一启动就立刻申请一堆内存空间,把这些值放进去,这个范围内的整数被重复使用时就不会再申请新的内存空间,而且这些小整数也永远不会被垃圾回收机制回收.

3. 列表在内存中的存储方式
直接引用:创建内存空间,将数值放进去,变量名直接指向内存地址
间接引用:列表是间接引用
开辟内存空间,存一个0号索引,对应值a的内存地址;1号索引,对应值b的内存地址;2号索引,对应值c的内存地址;a的内存地址再指向一个内存空间里面存放的才是a这个值,b,c同理.也就是说列表不会存放真正的值,只会存放索引和值的内存地址.而值会存放在单独的内存空间

4 内存管理
4.1 循环引用之内存泄露问题
前面说过不管是直接引用还是间接引用,只要引用计数为0时,它就会被垃圾回收机制回收.但是这种工作方式是有问题的
# _*_ coding utf-8 _*_
# george
# time: 2024/3/7上午9:21
# name: store.py
# comment:
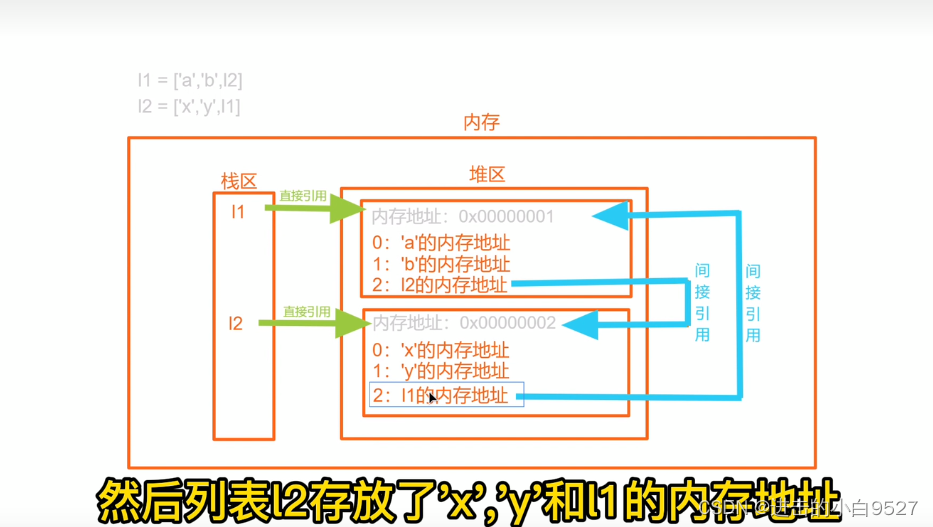
l1 = ["a", "b"]
l2 = ["x", "y"]
l1.append(l2)
print(id(l2), id(l1[2])) # 4410818440 4410818440
l2.append(l1)
print(l2) # ['x', 'y', ['a', 'b', [...]]]
print(id(l1), id(l2[2])) # 4355399496 4355399496
"""
现在l1存储了l2的内存地址,l2也存储了l1的内存地址,这两个列表中存在一种相互引用的关系,也就是循环引用.
循环引用会导致非常致命的问题
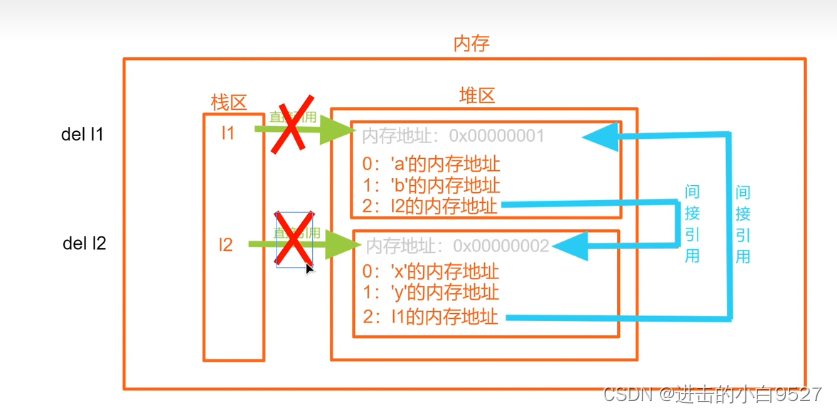
我现在解除了l1,l2的直接引用,但是他们的引用计数并没有变为0,它们身上只有他们相互之间的间接引用,我们再也没办法取到这两个表
垃圾回收机制会回收引用计数为0的内存空间,但是这两个列表变成了永远回收不了的垃圾,永远占据这两个内存空间,这就叫内存泄露
"""
del l1
del l2
print(l1,l2) # NameError: name 'l1' is not defined
现在l1存储了l2的内存地址,l2也存储了l1的内存地址,这两个列表中存在一种相互引用的关系,也就是循环引用.
循环引用会导致非常致命的问题 我现在解除了l1,l2的直接引用,但是他们的引用计数并没有变为0,它们身上只有他们相互之间的间接引用,我们再也没办法取到这两个表 垃圾回收机制会回收引用计数为0的内存空间,但是这两个列表变成了永远回收不了的垃圾,永远占据这两个内存空间,这就叫内存泄露.而循环引用就会导致内存泄露问题.python提供了一个补充解决方法叫做标记清除.
4.2 标记清除机制
标记清除会在python程序内存空间不够用的时候,将整个程序暂停下来,扫描栈区.把通过栈区所能够引用到的值不管是直接引用还是间接引用到的,全都标记为存活状态.一旦发现有通过栈区引用不到的值,都标记为死亡状态.死亡状态的值会被直接清理掉.就算它身上的引用计数不为0,只要我们访问不到它了,标记清除就会将它标记为垃圾,然后回收掉.
4.3 分代回收机制
前面说的引用计数和标记清除已经可以实现回收所有的垃圾了.但是现在垃圾回收机制还是有一个弊端.就是基于引用计数的垃圾回收机制,每次回收内存都需要把所有对象的引用计数全部都遍历一遍.当我们申请的变量很多的时候,每次都要将所有的变量全都扫描一边,这样的效率是非常低的.
分代回收机制的核心是:对象存在的时间越长,是垃圾的可能性就越小,应该尽量不对这样的对象进行垃圾回收。CPython将对象分为三种世代分别记为0、1、2,每一个新生对象都在第0代中,如果该对象在一轮垃圾回收扫描中存活下来,那么它将被移到第1代中,存在于第1代的对象将较少的被垃圾回收扫描到;如果在对第1代进行垃圾回收扫描时,这个对象又存活下来,那么它将被移至第2代中,在那里它被垃圾回收扫描的次数将会更少。
垃圾回收机制主要是引用计数来扫描并且回收垃圾,用标记清除解决引用计数回收不了的垃圾,用分代回收解决引用计数扫描效率的问题
5.可变与不可变类型
可变类型
值改变的情况下,id不变,说明改变的是原值,这里的值指的是堆区里面的内容.
列表,字典,集合这种容器类型都是可变类型
不可变类型
值改变的情况下下,id也发生了变化
所有的赋值操作都会申请新的内存空间,产生新的值
整型,浮点型,字符串,布尔值类型,元组
6.函数
6.1 函数的定义和调用
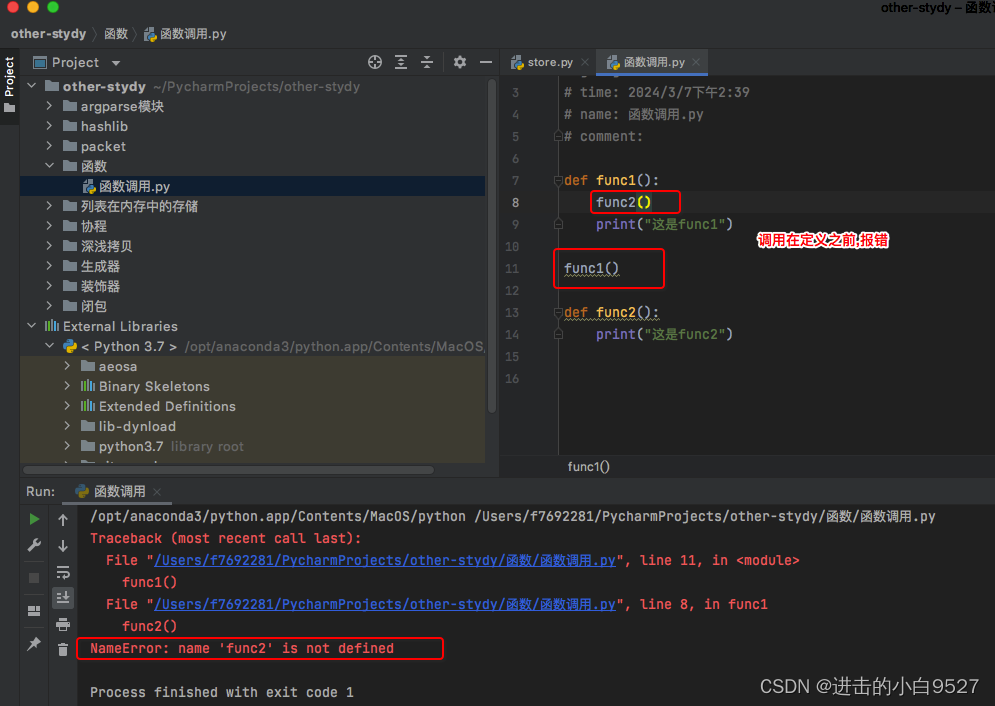
函数需要先定义,再调用
定义函数会申请内存空间,将函数的子代码存进去,然后将这个内存地址绑定给函数名,所以说函数名指向的就是函数的内存地址.并且在定义阶段,不会执行函数的子代码,必须要调用函数才会执行.
函数的定义阶段: 不会执行函数的子代码,但是会检测函数子代码的语法
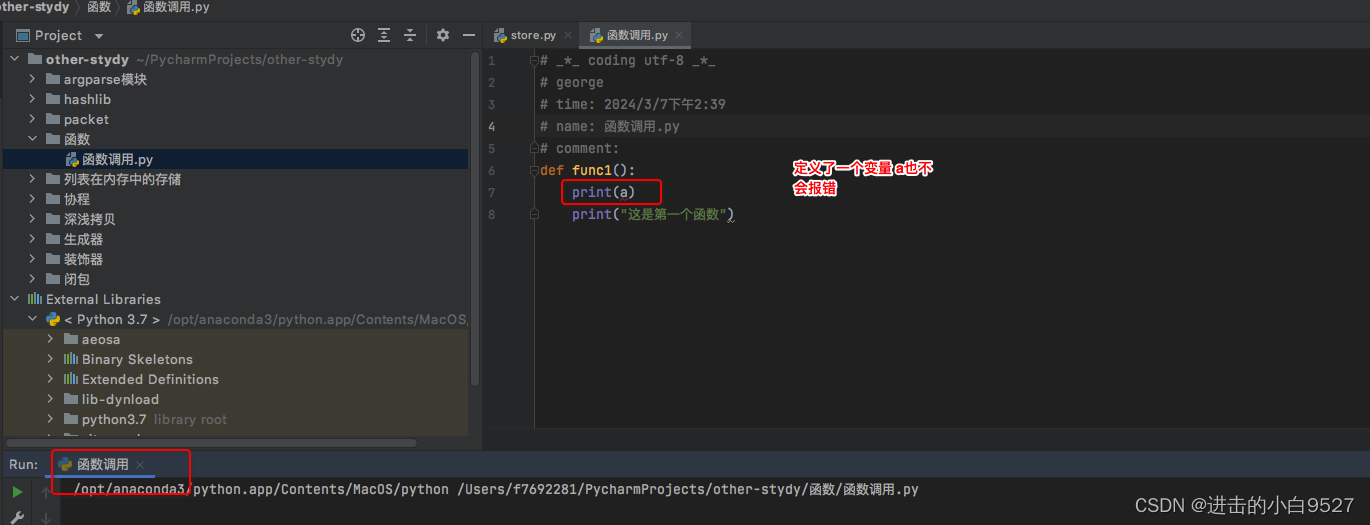
函数的调用阶段,调用其实背后做了两件事情1)通过函数名找到函数的内存地址,在函数的内存地址后面加上(),触发函数子代码的运行
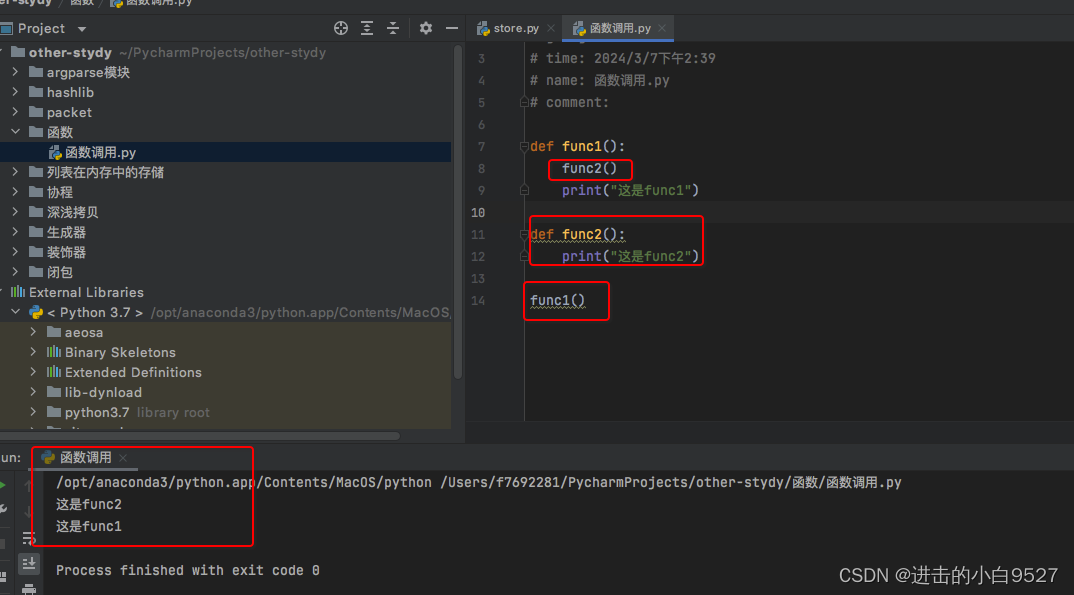
 函数的定义阶段只会检测语法,不会执行代码.func1是没有语法错误的,func2的语法也是没有错误的
函数的定义阶段只会检测语法,不会执行代码.func1是没有语法错误的,func2的语法也是没有错误的
定义函数就是开辟内存空间,把函数子代码丢到内存空间里面去,然后将函数地址绑定给函数名.
1) 所以此时func1的子代码已经被放进了内存里,并且内存地址绑定给了func1
2) 检测func2也没有语法错误,func2的代码也丢到了内存里面,同时内存地址也绑定给了func2
到现在还没有执行任何函数子代码,但是内存里面已经存在了func1和func2的子代码
所以此时调用func1就不会报错
将函数的调用作为函数的参数来使用,本质上其实是将函数的返回值作为参数使用.
6.2 return
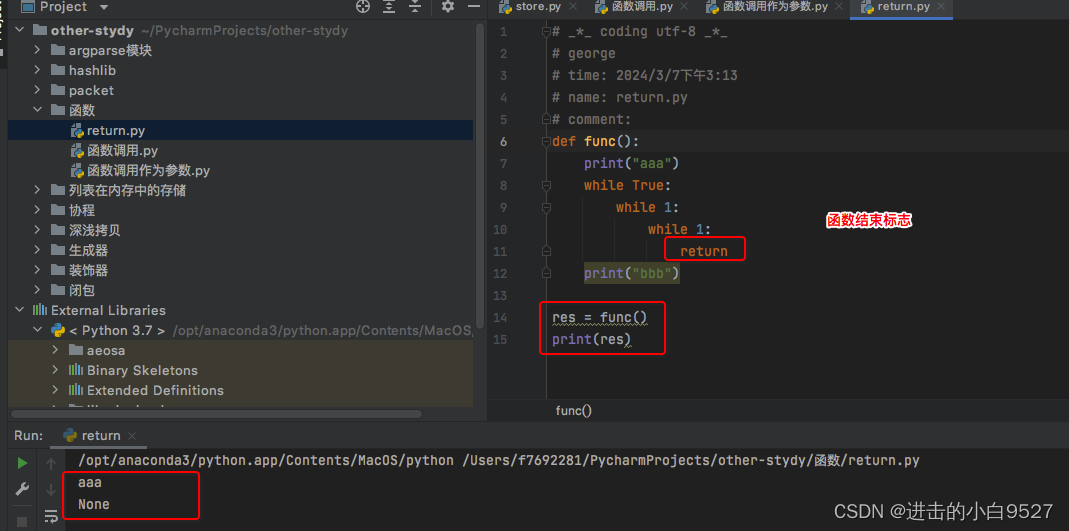
return就是函数结束的标志,只要函数子代码遇到return,就会立刻结束函数的运行,并且将return后面的值当做本次运行结果返回.如果我们返回多个值,就会被处理成为元祖
6.3 参数
函数的参数从定义阶段和调用阶段可以分为两部分
定义阶段:形式参数,简称形参
调用阶段:实际参数,简称实参
形参和实参在定义阶段是没有任何关系的,只有在调用阶段,实参才会绑定给形参,就是变量值绑定给变量名(变量值的内存地址,绑定给了变量名)
6.3.1 位置参数
位置参数就是按照从左到右的顺序,依次定义的参数.
位置形参:定义函数的时候,从左到右.依次定义的形参.必须传值,不能多也不能少
位置实参:在调用函数的时候,从左往右依次传入的值
def func(x, y, z):print(x, y, z)func(1, 2, 3) # 1 2 36.3.2 关键字参数(关键字实参)
可以不按照顺序,而是以key=value的形式进行传值,key必须是定义函数的时候指定好的形参名
def func(x, y, z):print(x, y, z)# 位置实参
# func(1, 2, 3) # 1 2 3# 关键字实参
func(z=3, x=1, y=2) # 1 2 3关键字实参和位置实参进行混用,但是必须遵循一个原则:位置实参一定要放在关键字实参之前
def func(x, y, z):print(x, y, z)# 位置实参
# func(1, 2, 3) # 1 2 3# 关键字实参
# func(z=3, x=1, y=2) # 1 2 3# 混用
func(1, 2, z=3) # 1 2 3
func(x=1, 2, 3) # SyntaxError: positional argument follows keyword argument6.3.4 默认参数(默认形参)
在定义阶段,就为其赋了默认值的形参.定义默认形参就意味着,在调用函数的时候可以不用为其传值.
定义的时候,默认形参必须放在位置形参之后
# 默认形参
def func(x, y=2):print(x, y)func(2) # 2 2
func(1, 3) # 1 3默认参数的值是在函数定义阶段被赋值的
# 默认形参
a = 2def func(x, y=a): # 其实就是y指向2的内存地址,3指向a的内存地址print(x, y)a = 3
func(1) # 1 2a = [2, 3]def func(x, y=a): # y指向[2,3]的内存地址print(x, y)a.append(4) # 列表为可变数据类型,增加值时,内存地址不改变
func(1) # => 1 [2, 3, 4]
python里面所有的值的传递,都是内存地址的传递,内存地址是对值的引用.
python里面所有的值传递,都是引用传递
虽然函数默认参数的值可以指定成为任意类型数据,但是不建议指定成为可变类型.因为一个函数的输出结果最好,只和函数的调用和函数的本身有关系.就是我传递什么参数,调用时就会得到什么结果,不会受到外界代码的影响.
# 之前说过尽量不要将默认形参的值设置成可变类型,虽然现在定义的形参不能被外界改变,用起来也没有问题
# 但是从规范层面上面来说我们不应该这么做
def my_append(x, y, l=[]):l.append(x)l.append(y)print(l)l = [3,4]
my_append(1,2,[3,4]) # [3, 4, 1, 2]def my_append(x, y, l=None):if l is None: # 因为None也是小整数池里面的,None指向的都是同一个内存地址l = []l.append(x)l.append(y)print(l)l = [3, 4]
my_append(1, 2, [3, 4]) # => [3, 4, 1, 2]
6.3.4 可变长参数
可变长参数是指在调用函数的时候,传入的参数个数是不固定的
6.3.4.1 可变长度的位置参数
用法: *形参名,形参名就可以用来接收多出来的位置实参
*在形参中
# 可变长度的位置参数
def func(x, y, *z): # 将*处理成为元祖,然后赋值给z,z=(3,4,5)print(x, y, z)func(1, 2, 3, 4, 5) # => 1 2 (3, 4, 5)# 求和
def func(*args):sum = 0for i in args:sum += ireturn sumres = func(1, 2, 3, 4)
print(res) # => 10
res1 = func(1, 2, 3, 4, 5)
print(res1) # => 15* 在实参
def func(x, y, z):print(x, y, z)# *会将后面的多个值打散,打散成为位置实参,相当于func(1,2,3)
func(*[1, 2, 3]) # => 1 2 3*在形参中表示可变长度的位置参数,它会把多个值处理成为元祖.然后赋值给后面的形参名.
*在实参中间有打散的作用,打散成为位置实参
*在形参中也在实参中
def func(x, y, *args):print(x, y, args)func(*"愿疫情早点结束!") # 愿 疫 ('情', '早', '点', '结', '束', '!')
6.3.4.2 可变长度的关键字参数
用法:**kwargs,它就是用于接收多出来的关键字实参的,**会将多出来的关键字实参处理成字典格式.然后赋值给**后面的形参名
无论是*还是**,都是用来接收溢出的实参的,所以一定要放在参数的最后,放在位置形参和默认形参之后
def func(x, y, **kwargs): # kwargs={'a': 3, 'b': 4, 'c': 5, 'name': '张大仙'}print(x, y, kwargs) # => 1 2 {'a': 3, 'b': 4, 'c': 5, 'name': '张大仙'}func(x=1, y=2, a=3, b=4, c=5, name="张大仙")**在形参中表示可变长度的关键字参数,它会把多个值处理成为字典.然后赋值给后面的形参名.
**在实参中间有打散的作用,打散成为关键字实参
def func(x, y, z):print(x, y, z) # 1 2 3func(**{"x":1,"y":2,"z":3}) # => func(x=1,y=2,z=3)def func(x, y, **kwargs):print(x, y, kwargs) # => 1 2 {'z': 3}func(**{"x": 1, "y": 2, "z": 3}) # 等价于 func(x=1,y=2,z=3)6.3.5 可变参数混用
我们调用函数进行传参的时候,有多出来的位置实参,也有多出来的关键字实参,这个时候就涉及到*和**的混用.而此时**kwargs必须在*args之后
def func(x, y=1, *args, **kwargs):print(args) # => (1, 2, 3, 4)print(kwargs) # => {'a': 1, 'b': 2, 'c': 3}func(1, 2, 1, 2, 3, 4, a=1, b=2, c=3)6.3.6 命名关键字形参(命名关键字参数)
pass
6.4 函数重中之重
def func1(x, y, z, s):print("func1>>", x, y, z, s)# 这样就将传递给func2的参数,原封不动的传递给了func1
def func2(*args, **kwargs): # args=(1,2,3,4)func1(*args, **kwargs) # func1(1,2,3,4)func2(1, 2, 3, 4) # => func1>> 1 2 3 46.5 名称空间和作用域
名称空间就是用来存名字的.
我们定义x=5,在内存里面就涉及到两个空间,栈区和堆区.首先会在堆区里面申请一个名称空间将5存进去.并将这个内存地址绑定给栈区里面的变量名x.栈区里面就是存储名字的
名称空间其实是将栈区里面的名字做了一个分类,或者说是将栈区里面的名字分成了几块:内置名称空间,全局名称空间,局部名称空间.当栈区里面有了名称空间之后,栈区里面分成了不同的区域,不同区域里面存储相同的变量名称也不会发生冲突.
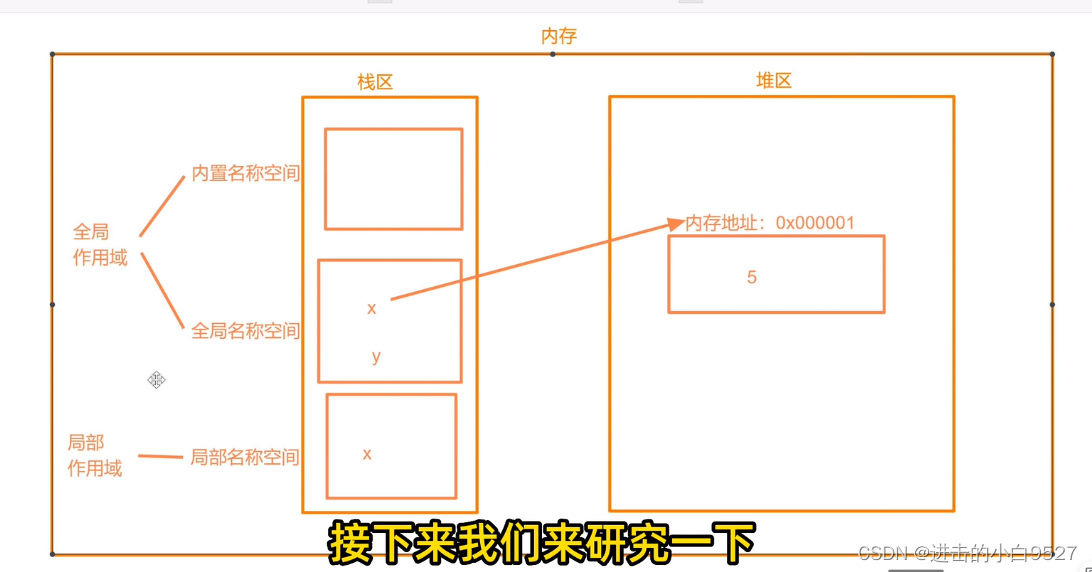
作用域:
在名称空间的基础上,按照作用范围的不同,将它们重新做了分类.内置名称空间和全局名称空间都被归为全局作用域,局部名称空间被归为局部作用域.
6.5.1 内置名称空间
存放python解释器内置名字的地方,内置名称空间只有一个内置名称空间,也就是说python解释器一启动就会创建内置名称空间.,让我们可以在任何位置使用内置名称空间里面的名字.python解释器关闭,内置的名称空间就会被销毁.
运行python程序有三个阶段
1)python解释器启动: 产生内置的名字
2)python解释器将文件内容,当做普通文本内容读入到内存.
3)识别python语法,运行代码,产生变量名产生函数名产生模块名
6.5.2 全局名称空间
全局名称空间:Python文件内定义的变量名,包括函数名,类名,以及导入的模块名.既然python里面定义的名字是存放在全局名称空间里面的,那么就是说有多个pyhton文件就会有多个全局名称空间.全局名称空间可以有多个.但是这里要排除掉函数内部定义的名字(包括函数参数)
只要不是函数内部定义的名字,也不是内置的名字,剩下的都是全局名称空间里面的名字
全局名称空间它会在python文件执行之前产生,python文件运行完毕后销毁
6.5.3 局部名称空间
函数内部定义的名字(包括函数参数)
而局部名称空间会在函数调用时产生,就是运行函数子代码的时候产生,函数调用结束后销毁.局部名称空间也可以有很多个,调用一个产生一个.
名称空间加载顺序:
python解释器启动会加载内置名称空间,python解释器将文件内容,当做普通文本内容读入到内存.然后加载全局名称空间.加载完毕,识别python语法执行代码.调用函数产生名称空间
6.6 名字查找顺序
有了名称空间之后,不同名称空间的相同名字是不会相互影响的,但是名称空间的查找优先级?
局部名称空间>全局名称空间>内置名称空间
def func():print(x)x = 10
func() # => 10加载内置名称空间->加载全局名称空间->将func丢入全局(函数在定义阶段只会检测语法,不会执行函数子代码)将x=10丢入全局,调用func时,全局存在x.
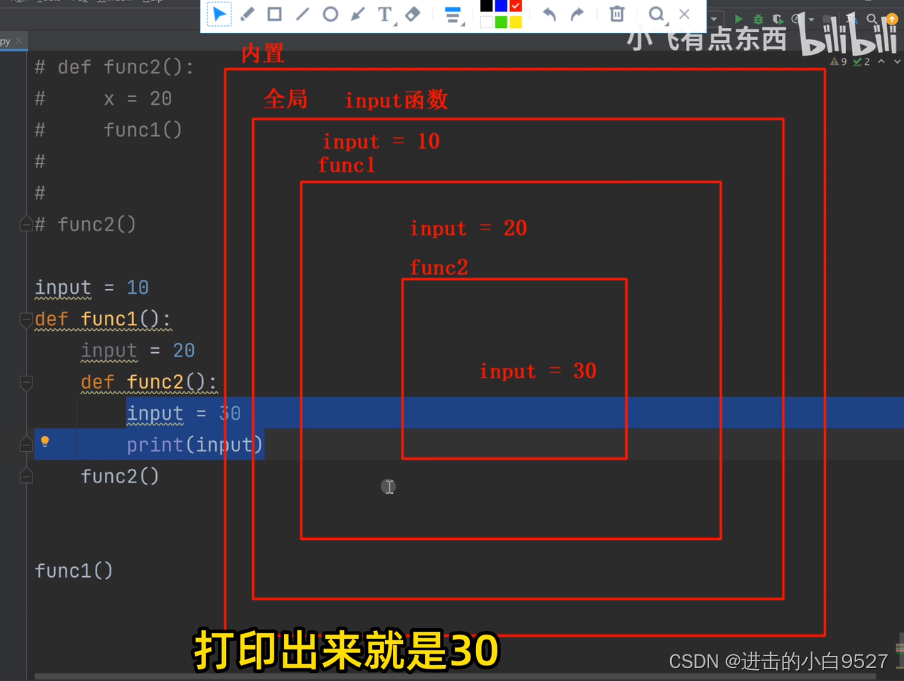
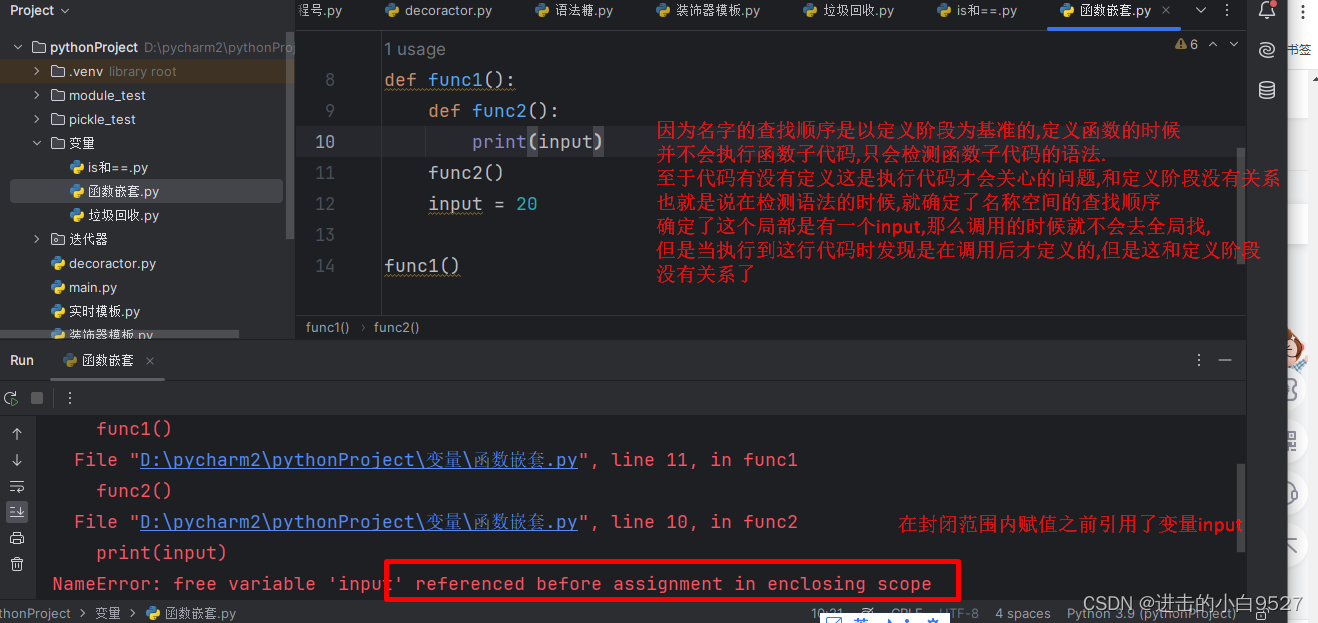
x = 10def func1():print(x)def func2():# print(x)x = 20func1()func2() # => 10名称空间的查找顺序是以定义阶段为基准的,和调用的位置没有任何关系
6.7 函数的嵌套
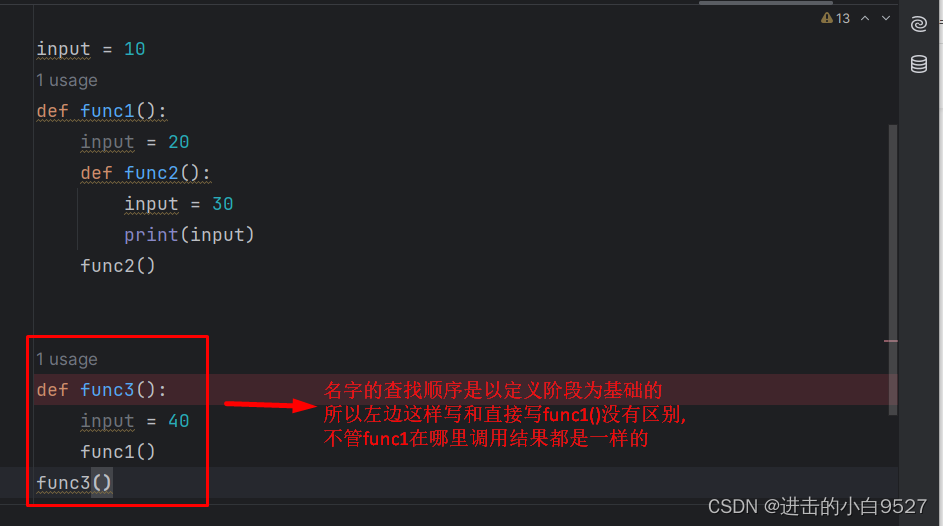
名字的查找是以定义阶段为基准的




![[PTA] 分解质因子](https://img-blog.csdnimg.cn/direct/703cbe5c7bd74448a861542e13fb0208.png)