本系列是算法通关手册LeeCode的学习笔记
算法通关手册(LeetCode) | 算法通关手册(LeetCode) (itcharge.cn)
目录
一,朴素匹配算法(Brute Force)
二,Rabin Karp算法
三,KMP算法
四,BM算法
坏字符规则:
好后缀规则
一,朴素匹配算法(Brute Force)
简称为 BF 算法,是暴力匹配算法。对于给定的文本串 T 与模式串 p,从文本串的第一个字符开始与模式串 p 的第一个字符进行比较,如果相等,则继续逐个比较后续字符,否则从文本串的第二个字符起重新和模式串 p 进行比较。以此类推,直到模式串 p 中每个字符依次与文本串 T 的一个连续子串相等,则匹配成功,否则匹配失败。

步骤:
对于给定的文本串 T 与模式串 p ,求出文本串的长度为 n,模式串 p 的长度为 m;
同时遍历文本串 T 和模式串 p;
如果相等,则比较下一位,直到模式串的末尾为止;
如果不相等,则将文本串移动到上次开始匹配的位置,的下一个字符位置,模式串 p 退
回到开始位置,再依次进行比较;
当遍历完文本串 T 或者模式串 p 的时候停止搜索。
代码实现
def bruteForce(T: str, p: str):n, m = len(T), len(p)i, j = 0, 0while i < n and j < m:if T[i] == p[j]:i += 1j += 1else:i = i - (j - 1)j = 0if j == m:return i - jelse:return -1BF 算法简单易理解,但是效率很低。主要是因为在匹配过程中可能会出现回溯:当遇到一对字符不同时,模式串 p 直接回到开始位置,文本串也回到匹配开始位置的下一个位置,再重新开始比较。
回溯之后,文本串和模式串中一些部分的比较时没有必要的。由于这种操作策略,导致 BF 算法的效率很低。最坏情况是每一趟比较都在模式串的最后遇到了字符不匹配的情况。最坏情况下的时间复杂度为 O(m * n)
二,Rabin Karp算法
对于给定文本串 T 与模式串 p,通过滚动哈希算法快速筛选除与模式串 p 不匹配的文本位置,然后在其余位置继续检查匹配项。
算法整体步骤:
对于给定的文本串 T 与模式串 p,求出文本串 T 的长度为 n,模式串 p 的长度为 m;
通过滚动哈希算法求出模式串 p 的哈希值 hashp;
再通过滚动哈希算法对于文本串 T 中 n - m + 1 个子串分别求哈希值 hasht;
逐个与模式串的哈希值 hashp 比较大小
如果当前子串的哈希值 hasht 与模式串的哈希值 hashp 不同,则说明两者不匹配,则继
续向后匹配;
如果当前子串哈希值 hasht 与模式串哈希值 hashp 相等,则验证每个字符是否相等;
如果当前子串与模式串的每个字符相等,则说明当前子串与模式串匹配;
如果当前子串与模式串每个字符不相等,则两者不匹配,继续向后匹配;
比较到末尾,如果仍为匹配成功,说明文本串 T 中不包含模式串 p,返回 -1.
滚动哈希算法
实现 RK 算法中的一个重要步骤是滚动哈希算法,使用其将每次计算子串哈希值的复杂度从 O(m)降到了O(1),从而提升了整个算法的效率。
这个算法思想利用了子串中每一位字符的哈希值,并且可以根据上一个子串的哈希值,快速计算相邻子串的哈希值,从而使得每次计算哈希值的时间复杂度降为了O(1)。
举个例子,假设字符串只包含 a 到 z 这26个小写字母,那么我们可以用 26 进制数来表示一个字符串,a 表示为 0,b 表示为 1,以此类推,z 用25表示。
则 “ cat ”的哈希值就可以表示为:
Hash(cat) = c * 26 *26 + a * 26 + t * 1
= 2 * 26 * 26 + 0 * 26 + 19 * 1 = 1371
在计算下一个子串时,可以使用上述结果,假设字符串为 " cate ",则要计算的下一个字串为 " ate ",此时将 c 从 cat 中去除,即 Hash(cat)- c * 26 * 26,得到Hash(at),将 at 左移一位,Hash(at) * 26 ,最后加上 e :
Hash(ate)= ( Hash(cat) - c * 26 * 26 ) * 26 + e
= ( 1371 - 2 * 26 * 26 ) * 26 + 4 * 1 = 498
可以看到计算子串的时间复杂度为 O(1)。
因为哈希值过大会造成溢出,所以我们在计算过程中需要对结果取模,取模的值应该是质数,这样可以减少哈希碰撞的概率。
代码实现
def rabinKarp(T: str, p: str, d: int, q: int) -> int:n, m = len(T), len(p)if n < m:return -1hash_p, hash_t = 0, 0h = 1for _ in range(m - 1):h = (h * d) % qfor i in range(m):hash_p = (hash_p * d + ord(p[i])) % qhash_t = (hash_t * d + ord(T[i])) % qfor i in range(n - m + 1):if hash_p == hash_t:if T[i:i+m] == p:return iif i < n - m:hash_t = ((hash_t - (ord(T[i]) * h) % q) * d + ord(T[i + m])) % qreturn -1代码中,可能会对取余的操作感到迷惑,可以这样理解,相同的字符在不同的位置对应的哈希值不同,如 “ bb " 中,左侧的 b 哈希值为 1 * 26 = 26,右侧的 b 哈希值为 1 * 1 = 1,在计算和更新 hash_t 中,应减去相同的值以保证哈希映射的一致性。
算法的整体实时间负责度为 O(n)。
三,KMP算法
对于给定的文本串 T 和 模式串 p ,当发现文本串 T 的 某个字符与模式串 p 不匹配时,可以利用匹配失败后的信息,尽量减少模式串与文本串的匹配次数,避免文本串位置的回退,以达到快速匹配的目的。
在朴素匹配算法的匹配过程中,我们分别用指针 i 和指针 j 指示文本串 T 和模式串 p 中当前正在比对的字符,当发现文本串 T 的某个字符与模式串 p 不匹配的时候,j 退回到开始位置,i 回到之前匹配开始位置的下一个位置上,然后开始新一轮的匹配

这样,在 BF 算法中,i 是指向文本串 T 的指针,如果从 T[ i ] 位置开始的一轮字符串比较失败了,假设在 模式串的 p[ j ]位置失败了,则此时指针 i 已指向 i + j 的位置,算法会回到 i + 1的位置开始下一轮匹配,即在文本串 T 上的 i 指针发生了回退,而这也造成了对文本串 T 的多次遍历。
KMP算法的改进
如果我们可以通过每一次的失配而得到一些信息,并且这些信息可以帮助我们跳过那些不可能匹配成功的位置,那么我们就能大大减少模式串与文本串的匹配次数,从而达到快速匹配的目的。
每次失配告诉我们的信息是:主串的某一个子串等于模式串的某一个前缀。
这个信息的意思是,如果文本串 T[ i: i + m ] 与模式串 p 的失配是在下标位置 j 上发生的,那么文本串 T 从下标位置 i 开始连续的 j - 1 个字符,一定与模式串 p 的前 j - 1 个字符一摸一样,即“
T[ i: i + j ] = p[0: j ]
例如上图的朴素匹配算法中:

文本串与模式串在第 6 个字符的位置失配了,根据我们上面的结论,可以知道,文本串中的这个长度为 5 的子串是模式串中的一个前缀。明确了这个信息,我们把注意力集中到这段相同的串中。
ABCAB
我们不难发现,后两个字符 AB 与前两个字符 AB 相同。
如果把这段子串放入文本串中,我们可以知道 T[i + 3: i + 5] = AB
如果把这段前缀放入模式串中,我们可以知道 p[0: 2] = AB
所以我们可以知道 T[i + 3: i + 5] = p[0: 2]
便可以不退回文本串中的 i ,将模式串中相同前缀的后一个字符对准失配位置继续进行比较
判断 p[ 2 ] == T[ i + 5]

而这样做为什么是安全移动,不会错过中间可能匹配的串呢?
其实在上一步找文本串中子串的后缀与模式串中相同的前缀的过程中,我们已经保证了不会有可能匹配的串。
在上述安全移动的过程中,模式串 p 只用到了前五个字符的部分,毕竟如果前五个字符都不能匹配成功,其他位置就不用考虑了。
我们暂时换一个例子来考虑:
如果模式串的前六位是 AABABD,
完成匹配的文本串为 AABABC
在第六位上发生失配,此时 AABAB 中,前缀与后缀不匹配,根据KMP算法,可以将整段模式串移到失配位置,即判断模式串的 p[0] == 文本串的 T[i + 6],因为在已匹配的 AABAB 中,不存在前缀 AA (失配后模式串要移动,此时不再考虑 AABAB本身),既然不存在AA,所以包含ABAB为开头的子串一定不匹配,可以安全移动。
让我们回到图中的例子,

同样的道理,在失配之后,剩余的字符串 BCAB中,BC 并不匹配模式串前缀 AB,因此可以安全移动到相同后缀的位置,然后继续进行比对。
我们用一个表来存储安全移动的信息,也叫做前缀表,在KMP算法中使用 next 数组存储。
next[ j ] 的含义是:记录下标 j 之前(包括 j )的模式串 p 中,最长相等前后缀的长度。
简单来说,就是求:模式串 p 的子串 p[0: j + 1] 中,使得【前 k 个字符】 恰好等于 【后 k 个字符】 的【最长的 k】,子串本身不参与比较。
如 ABCABD 的 next = 000120
我们可以通过递推的方式构造 next 数组:
把模式串 p 拆分为 left,right两部分,left 表示前缀串开始所在的下标位置,right 表示后
缀串开始所在的下标位置,起始时 left = 0,right = 1,表示排除子串本身;
通过 p[left] 和 p[right] 比较前缀串和后缀串是否相等:
如果 p[ left ] != p[ right ] ,说明当前的前后缀不相同,则让后缀开始位置 k 不动,
前缀串不断回溯到 next[ left - 1 ] 位置(next 数组的意义就是这样),直到 left = 0 或
p[ left ] = p[ right ] 为止;
如果 p[ left ] == p[ right] 。说明当前前后缀相同,则可以先让 left += 1,这样 left 即
是前缀下一次进行比较的位置,又是当前最长前后缀的长度;
记录下标 right 之前的模式串 p 中,最长相等前后缀的长度 left,即 nexr[right] = left
算法整体步骤:
生成前缀表 next;
使用两个指针 i,j 分别指向文本串和模式串中当前匹配的位置,初始 i = 0, j = 0;
循环判断模式串前缀是否匹配成功
如果失配,将模式串退回 j = next[j - 1],直到 j = 0 或匹配成功;
如果成功,i += 1,j+= 1;
如果完全匹配成功,则返回模式串 p 在文本串 T 中的开始位置,return i - j + 1;
如果遍历完文本串仍未成功,返回 -1.
实现代码:
def generateNext(p: str):m = len(p)next = [0 for _ in range(m)]left = 0for right in range(1, m):while left > 0 and p[left] != p[right]:left = next[left - 1]if p[left] == p[right]:left += 1next[right] = leftreturn nextdef kmp(T: str, p: str):n, m = len(T), len(p)next = generateNext(p)j = 0for i in range(n): # 可充分体现 i 不退回的特点while j > 0 and T[i] != p[j]:j = next[j - 1]if T[i] == p[j]:j += 1 # i += 1 在循环中if j == m:return i - j + 1return -1构造 next 时间复杂度为 O(m);
整个算法时间复杂度为 O(n + m)。
四,BM算法
对于给定的文本串 T 与模式串 p ,先对模式串 p 进行预处理,然后在匹配过程中当发现文本串 T 的某个字符与模式串 p 不匹配时,根据启发策略,能够尽可能地跳过一些无法匹配地情况。
BM算法地精髓在于使用了两种不同的启发策略来计算后移位数,分别是【坏字符规则 The Bad Character Rule】和【好后缀规则 The Good Suffix Shift Rule】。这两种启发式策略的计算过程只与模式 p 相关,而与文本串 T 无关。因此在对模式串 p 进行预处理时,可以预先生成两张相应的后移表,在匹配过程中,只需要比较一个两种策略最大后移位数进行后移即可。
与先前不同的是,BM算法在比较时,是从右向左基于后缀进行比较的。
坏字符规则:
当文本串 T 中的某个字符与模式串 p 的某个字符失配时,文本串 T 中的这个失配字符为坏字符,此时模式串可以快速向右移动。
Case 1:坏字符出现在模式串 p 中:
这种情况下,可将模式串 p 中最后一次出现的坏字符与文本串 T 中的坏字符对齐;
移动位数:在模式串中的失配位置 - 在模式串中最后一次出现位置。
PS: 因为是基于后缀搜索,坏字符前面的字符都是未知,所以要尽可能要对齐模式串
中最后一次出现的位置,以继续从右向左匹配。

Case2:坏字符没有出现在模式串 p 中:
这种情况下,包含坏字符的所有子串都不可能匹配成功,模式串右移到失配位置之后;
移动位数:在模式串中的失配位置 + 1

好后缀规则
当文本串 T 根模式串 p 发生失配时,称文本串 T 中已经匹配好的字符串为【好后缀】,此时模式串 p 可以向右移动。
Case1:模式串中有子串匹配上好后缀:
这种情况下,移动模式串,让该子串和好后缀对齐即可,如果超过一个子串匹配上好后
缀,则选择最右侧的子串对齐。
移动位数:好后缀最后一个字符在模式串中的位置 - 匹配子串最后一个字符出现的位置

Case2:模式串中无子串匹配上好后缀,但是有最长前缀匹配好后缀的后缀:
这种情况下,我们需要在模式串的前缀中寻找一个最长前缀,该前缀等于好后缀的后缀
找到该前缀后,让该前缀和好后缀的后缀对齐。
移动位数: 好后缀的后缀的最后一个字符在模式串中的位置 - 最长前缀的最后一个字符
出现的位置

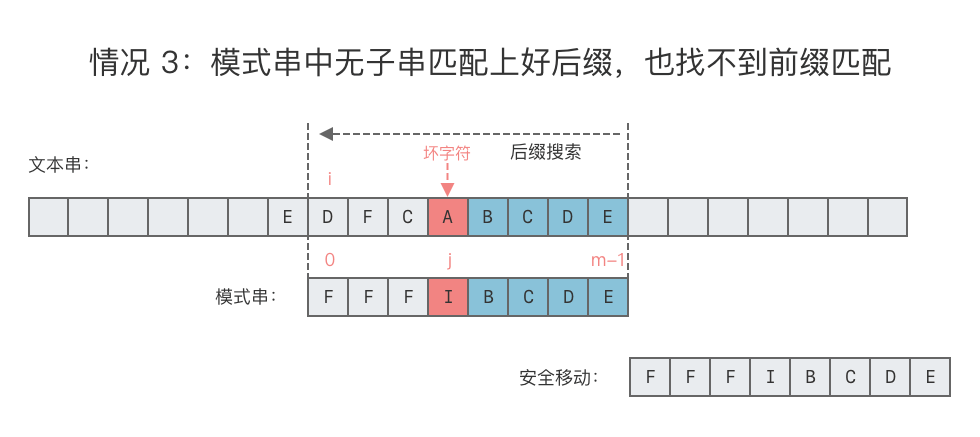
Case3:模式串中无子串匹配上好后缀,也找不到前缀匹配:
可将模式串整个右移;
移动位数:模式串的长度;
算法步骤:
计算出文本串 T 和模式串 p 的长度为 n,m;
先对模式串 p 进行预处理,生成坏字符移位表 bc_table 和好后缀移位表 gs_table;
将文本串模式串头部对齐,i 指向开始位置,j 指向模式串末尾位置,i = 0, j = m - 1
从模式串末尾位置开始比较:
如果文本串对应位置 T[i + j ] = p[ j ],则继续比较前一位字符。如果全部匹配完毕,则返
回 p 在文本串中的开始位置 i;
如果发生失配,则计算在坏字符规则下的移位 bad_move 和在好后缀规则下的
good_move。取两者的最大值移动,i += max(bad_move, good_move)
如果移动到末尾也没有找到匹配位置,则返回 -1。
代码实现
def boyerMoore(T: str, p: str):n, m = len(T), len(p)bc_table = generateBadCharTable(p)gs_list = generateGoodSuffixList(p)i = 0while i <= n - m:j = m - 1while j > -1 and T[i + j] == p[j]:j -= 1if j < 0:return ibad_move = j - bc_table.get(T[i + j], -1)good_move = gs_list[j]i += max(bad_move, good_move)return -1def generateBadCharTable(p: str):bc_table = dict()for i in range(len(p)):bc_table[p[i]] = ireturn bc_tabledef generateGoodSuffixList(p: str):m = len(p)gs_list = [m for _ in range(m)]suffix = generateSuffixArray(p)j = 0for i in range(m - 1, -1, -1):if suffix[i] == i + 1:while j < m - 1 - i:if gs_list[j] == m:gs_list[j] = m - 1 - ij += 1for i in range(m - 1):gs_list[m - 1 - suffix[i]] = m - 1 - ireturn gs_listdef generateSuffixArray(p: str):m = len(p)suffix = [m for _ in range(m)]for i in range(m - 2, -1, -1):start = iwhile start >= 0 and p[start] == p[m - 1- i + start]:start -= 1suffix[i] = i - startreturn suffix算法时间复杂度为 O( n + a ) 其中 a 为字符集大小。
算法通关手册(LeetCode) | 算法通关手册(LeetCode)
原文内容在这里,如有侵权,请联系我删除。