文章目录
- 逻辑回归模型
- 逻辑回归对于特征处理的优势
- 逻辑回归处理特征的步骤
- GBDT算法
- GBDT+LR算法
- GBDT + LR简单代码实现
逻辑回归模型
-
逻辑回归(LR,Logistic Regression)是一种传统机器学习分类模型,也是一种比较重要的非线性回归模型,其本质上是在线性回归模型的基础上,加了一个Sigmoid函数(也就是非线性映射),由于其简单、高效、易于并行计算的特点,在工业界受到了广泛的应用。
-
使用LR模型主要是用于分类任务,通常情况下也都是二分类任务,一般在推荐系统的业务中,会使用LR作为Baseline模型快速上线。
-
从本质上来讲,逻辑回归和线性回归一样同属于广义线性模型。虽然说逻辑回归可以实现回归预测,但是在推荐算法中,我们都将其看作是线性模型并把它应用在分类任务中。
-
总结:逻辑回归实际上就是在数据服从伯努利分布的假设下,通过极大似然的方法,运用梯度下降算法对参数进行求解,从而达到二分类。
-
Q&A
- Q:为什么在推荐系统中使用逻辑回归而不是线性回归?
- A:原因主要有三点
1. 虽然两者都是处理二分类问题,但是线性回归主要是处理连续性特征,例如一个人的身高体重,而推荐系统中对于一个物品推荐给用户,物品的特征是离散的。因此不好用线性回归作为预测
2. 逻辑回归模型具有较高的可解释性,可以帮助我们更好地理解推荐系统中不同因素对推荐结果的影响,而线性回归在这一点上无法实现我们的需求。
3. 推荐系统中往往存在很多的噪音,逻辑回归可以更好地处理异常值,避免推荐结果被干扰。
逻辑回归对于特征处理的优势
- 特征选择:可以使用正则化技术来选择重要的特征,提高模型效率和准确性。
- 处理非线性特征:可以通过引入多项式和交互特征来处理非线性特征,从而预测结果更加准确。
- 处理缺失值和异常值:可以通过处理缺失值和异常值使得模型更佳健壮,从而预测结果更加准确。
- 训练模型速度:训练速度相对较快。
逻辑回归处理特征的步骤
- 特征选择:逻辑回归可以使用正则化技术(L1、L2正则化)来选择最重要的特征,从而降低维度并去除无关特征。选择相关的特征有助于提高模型的稳定性和准确性。
- 处理缺失值和异常值:逻辑回归可以使用缺失值插补和异常值检测来处理缺失值和异常值,从而避免对模型产生影响,提高模型的健壮性。
- 处理非线性特征:逻辑回归可以通过引入多项式和交互特征来处理非线性特征,从而增强模型的表现力。以多项式模型为例,逻辑回归可以使用幂函数或指数函数对特征进行转换,从而处理非线性变量。
- 特征标准化:逻辑回归可以使用特征标准化来消除特征数据值的量纲影响,避免数值范围大的特征对模型产生很大影响。
- 特征工程:逻辑回归也可以使用特征工程来创建新的特征,例如聚合或拆分现有特征、提取信号等。这有助于发现与目标变量相关的新信息,从而改进对数据的理解。
GBDT算法
- GBDT(Gradient Boosting Decision Tree)算法是一种基于决策树的集成学习算法,它的学习方式是梯度提升,它通过不断训练决策树来提高模型的准确性。GBDT在每一次训练中都利用当前的模型进行预测,并将预测误差作为新的样本权重,然后训练下一棵决策树模型来拟合加权后的新数据。
- GBDT中的B代表的是Boosting算法,Boosting算法的基本思想是通过将多个弱分类器线性组合形成一个强分类器,达到优化训练误差和测试误差的目的。具体应用时,每一轮将上一轮分类错误的样本重新赋予更高的权重,这样一来,下一轮学习就容易重点关注错分样本,提高被错分样本的分类准确率。GBDT由多棵CART树组成,本质是多颗回归树组成的森林。每一个节点按贪心分裂,最终生成的树包含多层,这就相当于一个特征组合的过程。
- 理论上来说如果可以无限制的生成决策树,GBDT就可以无限逼近由所有训练样本所组成的目标拟合函数,从而达到减小误差的目的,同样这种思想后来也被运用在了ResNet残差神经网络上。
- 在推荐系统中,我们使用GBDT算法来优化和提高个性化推荐的准确性。通过GBDT算法对用户历史行为数据进行建模和学习,可以很容易地学习到用户的隐式特征(例如品味,偏好,消费能力等)。另外,GBDT算法可以自动选择重要的特征,对离散型和连续型特征进行处理(如缺失值填充、离散化等),为特征工程提供更好的支持。
GBDT+LR算法
- 在推荐系统中使用GBDT+LR结合算法主要是用于处理点击率预估,这个也是facebook在2014年发表的论文Practical Lessons from Predicting Clicks on Ads at Facebook。根据点击率预估的结果进行排序,所以GBDT+LR用于排序层。
- GBDT+LR架构图
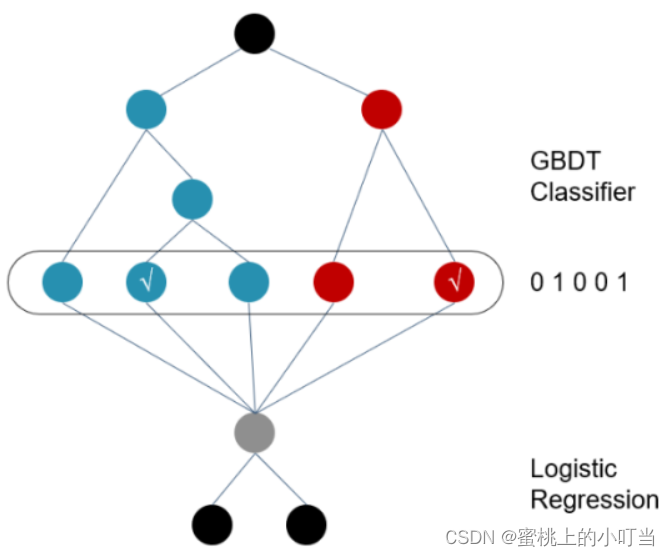
- 整个模型主要分为两个步骤,上面的GBDT和下面的LR。主要分为五个步骤:
- GBDT训练:使用GBDT对原始数据进行训练并生成特征。在训练过程中,每棵树都是基于前一棵树的残差进行构建。这样,GBDT可以逐步减少残差,生成最终的目标值。
- 特征转换:使用GBDT生成的特征进行转换。这些特征是树节点的输出,每个特征都对应于一个叶子节点。在转换过程中,每个叶子节点都会被转换为一个新的特征向量,代表这个叶子节点与其他节点的相对位置,并将这些特征向量连接起来形成新的训练集(用于下一步LR)。
- 特征归一化:对生成的特征进行归一化处理,确保不同维度的特征在训练过程中具有相等的权重。
- LR训练:使用LR对转换后的特征进行二分类或回归。特征向量被送入LR模型中进行训练,以获得最终的分类模型。在训练过程中,使用梯度下降法来更新模型参数,以最小化损失函数,损失函数的选择取决于分类问题的具体情况。
- 模型预测:训练完成后,使用LR模型对新的数据进行预测。GBDT+LR模型将根据特征生成函数和逻辑回归模型预测新数据的类别或值。
- GBDT + LR优缺点
- 优点:
提高模型预测精度
模型具有鲁棒性和可扩展性
具有良好的可解释性 - 缺点:建模复杂度高
训练时间计算成本高
对异常值和噪声数据敏感
- 优点:
GBDT + LR简单代码实现
import pandas as pd
import numpy as np
import lightgbm as lgb
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import f1_score, accuracy_score, precision_score, recall_score
from sklearn.preprocessing import OneHotEncoder# 读取数据集
# 数据集地址https://grouplens.org/datasets/movielens/
ratings = pd.read_csv("../../data/ml-1m/ratings.dat", sep="::", header=None, names=["user_id", "movie_id", "rating", "timestamp"], encoding='ISO-8859-1', engine="python")
movies = pd.read_csv("../../data/ml-1m/movies.dat", sep="::", header=None, names=["movie_id", "title", "genres"], encoding='ISO-8859-1', engine="python")
# 将两个数据集根据movie_id合并,并去掉timestamp,title
data = pd.merge(ratings, movies, on="movie_id").drop(columns=["timestamp", "title"])
# print(data.head(50))# genres字段转换为多个二值型变量(使用pandas的get_dummies函数)
genres_df = data.genres.str.get_dummies(sep="|")
# genres_df = pd.get_dummies(data['genres'])
# print(genres_df.head(50))
data = pd.concat([data, genres_df], axis=1).drop(columns=["genres"])
# print(data.head(50))# 提取出用于训练 GBDT 模型和 LR 模型的特征和标签
features = data.drop(columns=["user_id", "movie_id", "rating"])
# print(features.head(50))
label = data['rating']# 划分训练集和测试集(8,2开)
split_index = int(len(data) * 0.8)
train_x, train_y = features[:split_index], label[:split_index]
test_x, test_y = features[split_index:], label[split_index:]# 训练GBDT模型
n_estimators=100
gbdt_model = lgb.LGBMRegressor(n_estimators=n_estimators, max_depth=5, learning_rate=0.1)
gbdt_model.fit(train_x, train_y)
gbdt_train_leaves = gbdt_model.predict(train_x, pred_leaf=True)
gbdt_test_leaves = gbdt_model.predict(test_x, pred_leaf=True)# 将GBDT输出的叶子节点ID转换为one-hot编码的特征
one_hot = OneHotEncoder()
one_hot_train = one_hot.fit_transform(gbdt_train_leaves).toarray()
one_hot_test = one_hot.fit_transform(gbdt_test_leaves).toarray()# 训练LR模型
lr_model = LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,intercept_scaling=1, l1_ratio=None, max_iter=100,multi_class='auto', n_jobs=None, penalty='l2',random_state=None, solver='lbfgs', tol=0.0001, verbose=0,warm_start=False)
lr_model.fit(one_hot_train, train_y)# 在测试集上评估模型性能
y_pred = lr_model.predict(one_hot_test)
print(f"Accuracy: {accuracy_score(test_y, y_pred)}")
print(f"Precision: {precision_score(test_y, y_pred, average='macro')}")
print(f"Recall: {recall_score(test_y, y_pred, average='macro')}")
print(f"F1-Score (macro): {f1_score(test_y, y_pred, average='macro')}")