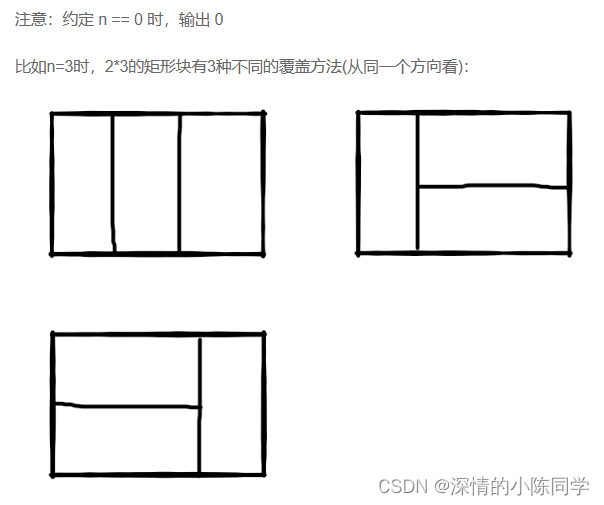
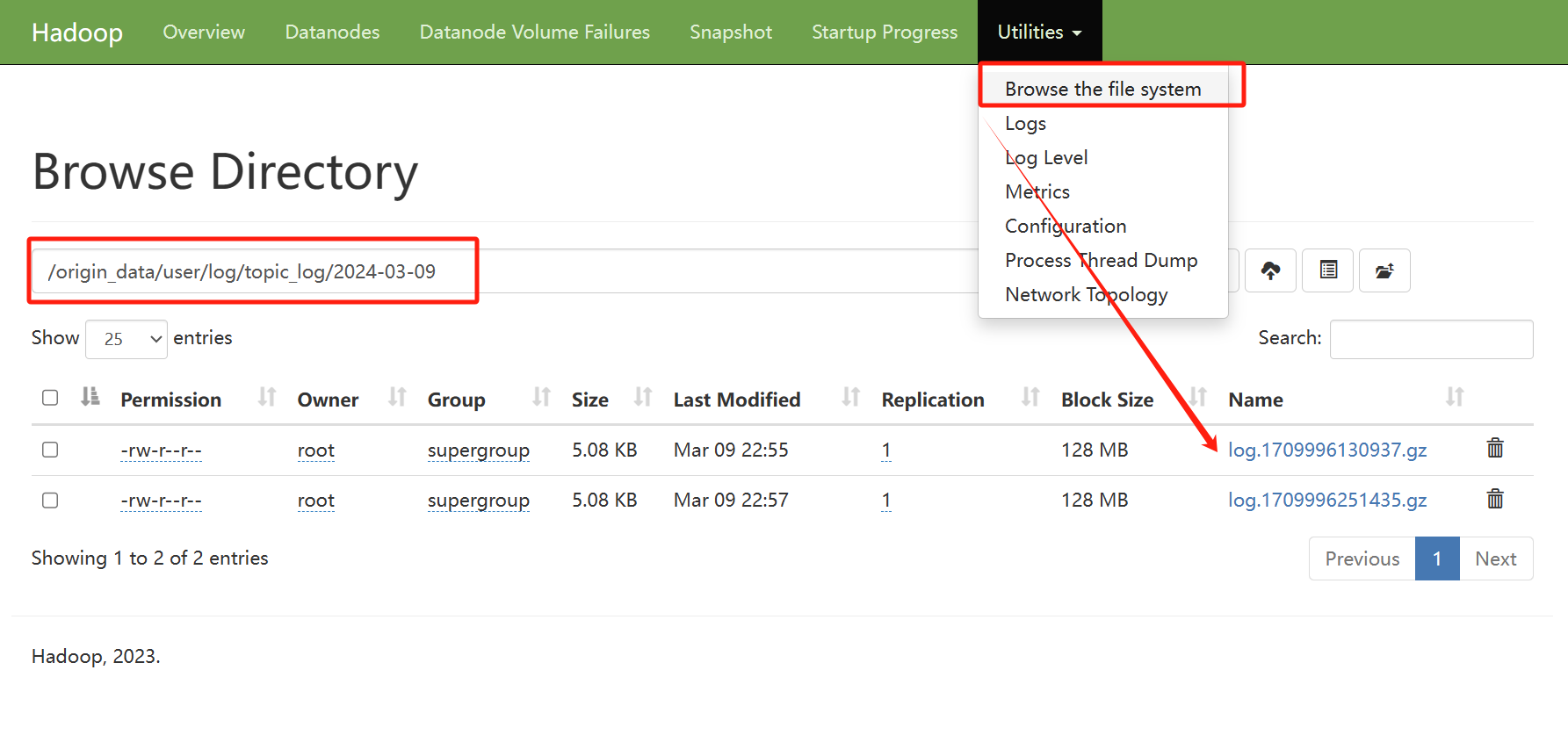
将LLM集成到项目所花费的成本主要是我们通过API获取LLM返回结果的成本,而这些成本通常是根据处理的令牌数量计算的。我们如何预估我们的令牌数量呢?Tokeniser包可以有效地计算文本输入中的令牌来估算这些成本。本文将介绍如何使用Tokeniser有效地预测和管理费用。

大语言模型(如GPT)中的"tokens"是指模型用来处理和理解文本的基本单位。令牌是语言模型处理文本时的基本单位,可以是单词、子词(subwords)、字符或者其他更小的文本单元。所以我们在计算令牌时不能简单的将单词按照空格分隔,而将一段文本分解成令牌的过程称为"tokenization",这是预处理文本的重要步骤。
大语言模型中一般都会使用子词作为令牌,这对于处理词汇表中未见过的单词很有帮助。例如,“unhappiness"可能被分解成"un”, “happi”, "ness"这三个子词。
Tokeniser是一个轻量级、高效的Python包,使用正则表达式进行计数,这样可以在不加载复杂的NLP模型时进行快速的估计:
importtokenisertext="Hello, World!"token_count=tokeniser.estimate_tokens(text)print(f"Number of tokens: {token_count}")
这个包对于估计输入提示和来自LLM模型的预期响应中的令牌数量特别有用。假设输入提示包含60个令牌,期望的响应长度为150个令牌,那么每个请求的令牌总数为210
有了总令牌计数,就可以根据GPT或其他LLM服务的定价来估计成本。例如,如果服务每1000个令牌收费0.02美元:
每次请求费用: 210/1000∗0.02=0.0042
我们可以将上面的工作封装成一个函数进行总成本预测:
importtokeniserdefestimate_cost_with_tokeniser(prompt, max_response_length, cost_per_thousand_tokens):input_tokens=tokeniser.estimate_tokens(prompt)total_tokens=input_tokens+max_response_lengthcost_per_request= (total_tokens/1000) *cost_per_thousand_tokensreturncost_per_request# Example usageprompt="Write a concise guide on estimating GPT and LLM query costs."max_response_length=150# Desired response length in tokenscost_per_thousand_tokens=0.02# Cost per 1,000 tokensestimated_cost=estimate_cost_with_tokeniser(prompt, max_response_length, cost_per_thousand_tokens)print(f"Estimated cost per request: ${estimated_cost:.4f}")
把它放到我们的工具类中,这样就可以在任何需要的时候直接调用了
总结
Tokeniser包为开发人员提供了一种实用而有效的方法来估计GPT和LLM查询令牌数,这对于管理和预测使用成本至关重要。通过将简单的令牌计数合并到成本估算过程中,可以确保项目更有效的预算管理。
https://avoid.overfit.cn/post/064552e1902b468d834e7d65399dcd04
作者:Eugene Evstafev