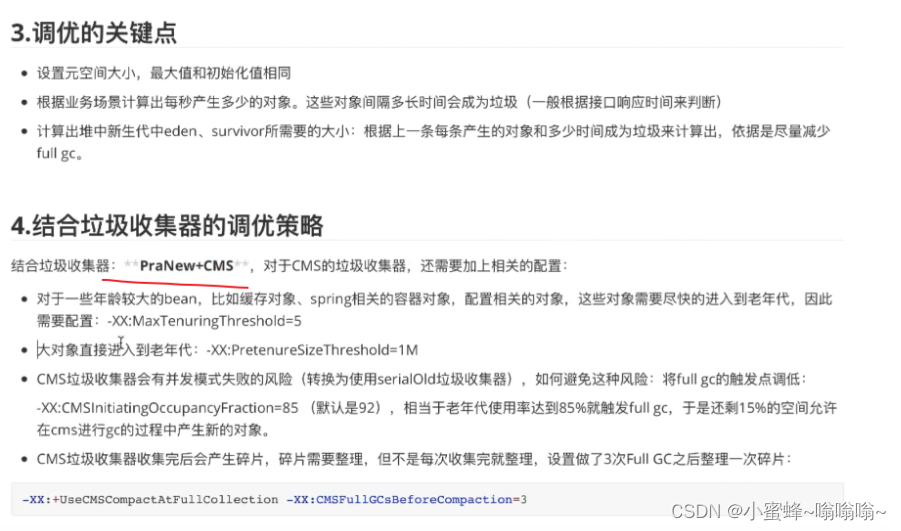
前言:本篇没有任何建设性的想法,只是我很早之前在学JVM时记录的笔记,只是想从个人网站迁移过来。文章其实就是对《深入理解JVM虚拟机》的提炼,纯基础知识,网上一搜一大堆。
一、知识点脑图
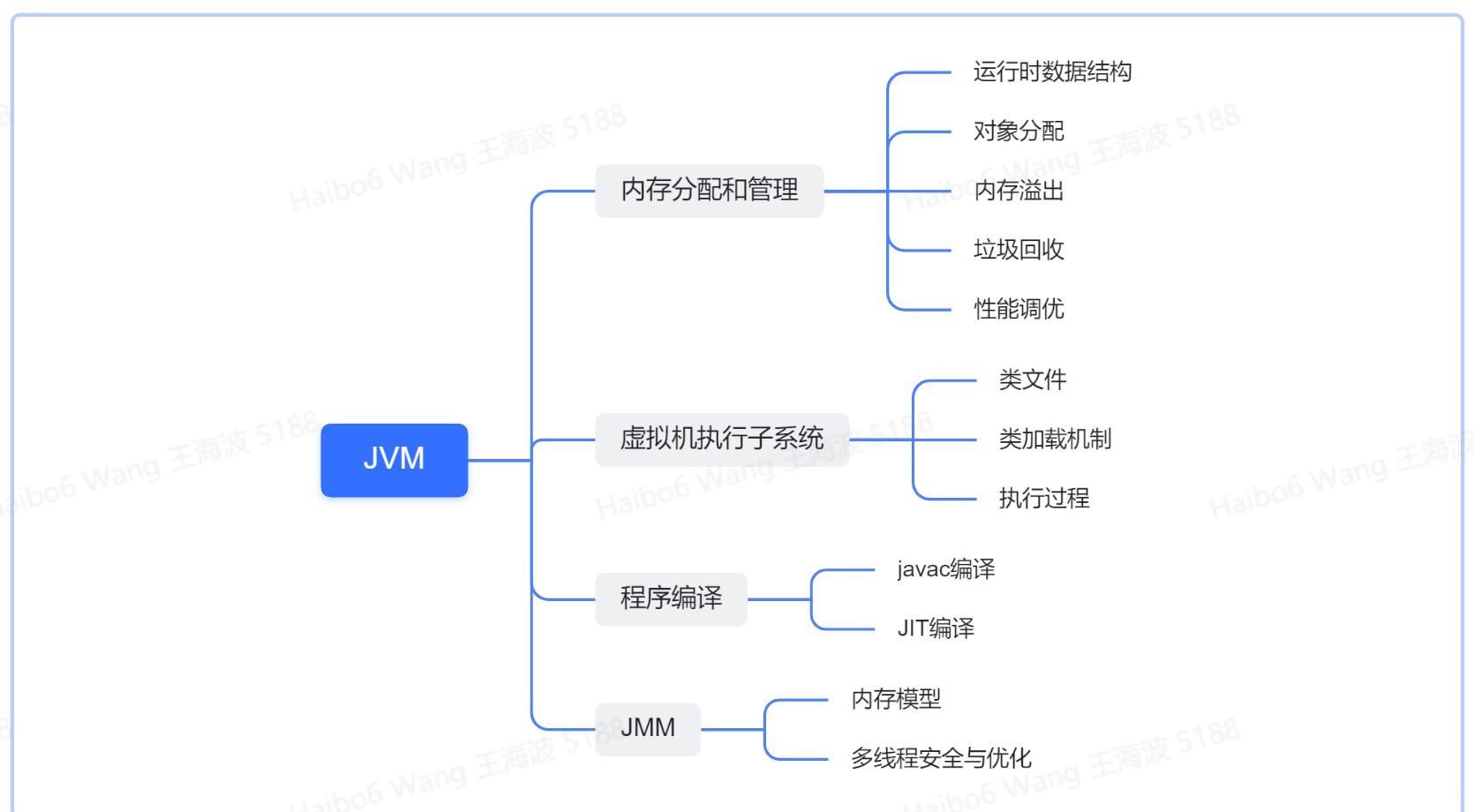
本文只谈论HotSpots虚拟机。
二、内存管理
1、运行时内存区域

在JDK1.8中,元空间取代了永久代,是方法区新的实现方式。其中之前的静态变量、字符串常量池存储在堆中,元空间存储了类的元信息。
堆空间:线程共享的,存储了对象和数组。但不是所有的对象都一定是在堆上分配,如果开启了逃逸分析,如果不会逃逸出局部函数或方法,则直接在栈上分配。由于开发者创建的对象多数都分配在这里,因此堆是JVM进行垃圾回收的重点区域。其中分为新生代和老年代,默认比例是1:2,新生代又划分为Eden、suvivor1、suvivor2三个部分,默认比例是8:1:1(不一定严格是这个比例)。
虚拟机栈:由栈帧组成,是线程私有的。栈帧是由局部变量表、动态连接、操作数栈方法出口地址等信息组成,随着函数的创建而产生,函数的结束而销毁。局部变量表存储的是方法参数和内部定义的局部变量;操作数栈就是在方法执行时入栈和出栈数据,比如进行整数加法运算时,就通过操作数栈完成;方法出口地址就是函数的返回地址,要返回到被调用的地方。动态连接是指需要在运行时转换为直接引用的符号引用。其中一些是在类加载过程中的解析阶段就确定好的,比如静态方法,私有方法、init方法等等,但诸如公有方法可能因为继承,需要在运行时确定。
本地方法栈:和虚拟栈类似,只是执行的是计算机的本地方法;
程序计数器:是线程私有的,如果你接触过操作系统的计数器应该知道器作用,主要是用于记录代码执行地址,用于线程间切换可以继续沿着上次执行位置继续执行。
方法区:存储了静态变量、类信息、常量池等信息。jdk1.8中使用元空间存储类的元信息,运行时常量池,字符串常量池和静态变量存储在堆中。
直接内存:这个是jdk1.4之后才有的,自引入了NIO之后,通过DirectByteBuffer会在操作系统上直接申请一块内存,其使用不当也会出现OOM,避免频繁创建DIrectByteBuffer对象。JVM参数也不要DiasableExplitGC,避免无法调用System.gc()。
2、对象分配
对象内存分配的方式包括空闲列表和指针碰撞两种,其中根据逃逸分析来决定对象是在堆上还是栈上分配。不过逃逸分析不是默认打开的。
由于对象的实例化要经过对象创建、内存分配、初始化零值、设置头对象、init方法执行、指针引用等过程。所以在多线程下会造成不安全。想解决该问题,JVM通过CAS锁来解决并发创建的问题(另外的一个并发问题是一个单例模式的使用,即著名的DCL问题,那个的问题主要是因为指令重排序导致的);此外,JVM引入了一个TLAB(Thread-Local Allocation Buffers)的概念,他为每个线程在堆上都申请一块内存,不同线程之间是相互独立的,在对象分配内存时尽量在TLAB上分配,不足时再到普通的堆上分配。
3、内存溢出
运行时数据区域只有程序计数器不存在溢出问题,其他空间都会出现内存溢出的可能。
堆溢出:如果创建的对象存在内存泄漏(没有准确地回收),随着对象堆积,可能造成内存溢出;
栈溢出:栈溢出体现在不断地创建栈帧,比如函数无限递归调用,最后可能超出栈最大深度,导致出现栈溢出;
元空间:如果元空间不设置,则默认使用计算机内存,会导致整个系统的内存溢出;如果设置了元空间的最大喝初始值,也会由于不断地创建类导致元空间内存溢出。
内存溢出的两种类型:StackOverFlowError和OutofMemoryError。
StackOverFlowError主要是发生在栈中,当栈深度超过了虚拟机为线程所分配的栈的大小,就会发生该错误。
OutofMemoryError在内存不足时会出现,包括堆、方法区和栈。栈发生该错误的场景是当对栈进行扩容时,无法申请到足够的内存。
4、垃圾回收
和C语言,C++不同,Java开发者自己并不需要进行内存的分配和释放,不用调用malloc等操作。但内存是有限的,因此必须要进行内存淘汰,从而避免系统出现OOM,这部分工作由JVM来完成。类似其他语言,如Python,PHP等都由虚拟机来完成垃圾回收,开发者不必关系。但是,这也不能说明Java开发者可以滥用,随意编写代码,否则还是会出现OOM的。
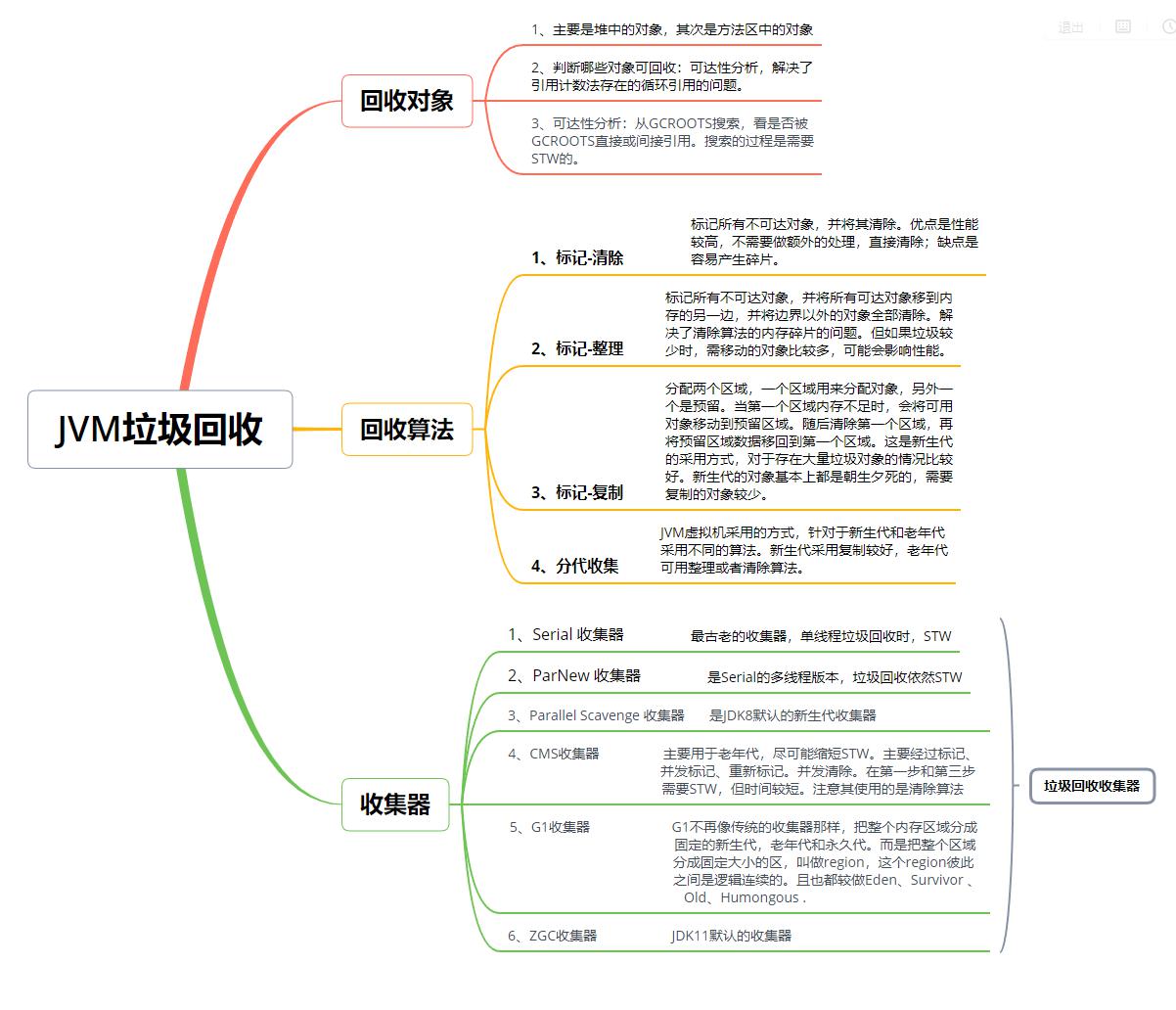
垃圾回收主要包括两大部分,一是基础的垃圾回收算法,二是不同的垃圾收集器。
1)垃圾回收算法
目前存在的GC算法:
-
标记-整理算法;
-
标记-清除算法;
-
标记-复制算法;
三种算法在Java中都有涉及,但不是单纯采用某种算法,因为这三种算法都存在一定程度的缺点。JVM将内存划分成新生代和老年代,分代进行垃圾回收,也就是著名的分代收集算法,其本质上并不属于一种算法,更确切的说是上面三种算法的不同场景的应用。具体的垃圾回收算法可以参考《深入理解Java虚拟机》一书。
JVM的GC回收对象主要是堆,有些收集器还会回收Metaspace,比如G1和CMS,但元空间的内存超过了最 大限制,会触发Full GC,但GC只有在Metaspace中元数据对应的类加载器被回收,元数据才会被回收。这里主要说堆。
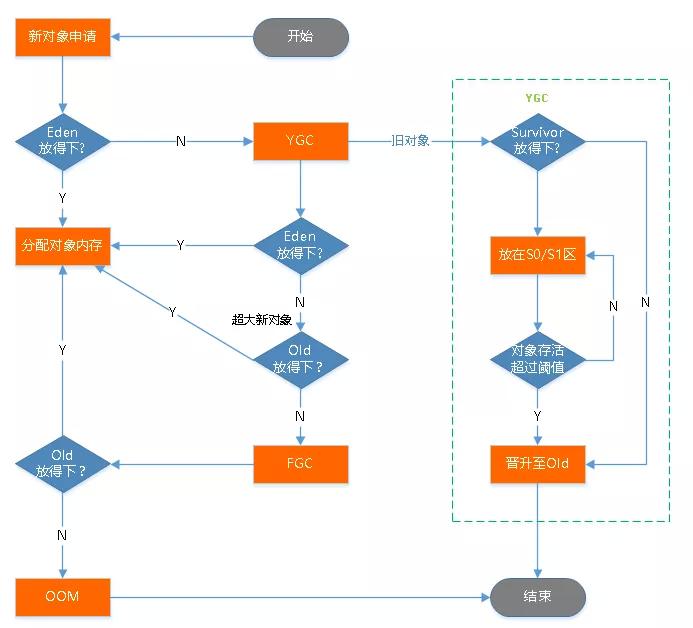
堆主要分成两大部分,新生代和老年代,任何的对象在创建时优先进入新生代,但如果对象较大,则直接进入老年代,新生代和老年代的比例时1:2,这个比例也可以调,通过–XX:NewRatio。
简单说下,哪些对象会进入老年代:
1、大对象,会直接进入老年代;
2、拿到阈值年龄的对象,会进入老年代,一般默认是15岁。每经历一次MinorGC且没被回收的,都会增长一岁。
3、在Survivor空间中相同对象年龄的所有对象的大小之和超过了整个Survivor空间的一半,那么所有大哥这个年两的对象都会放到老年代中。
新生代又划分为Eden,suvivor1,suvivor2三个部分,之所以这样做是因为多数对象都是朝身夕灭,都不会存活太久,GC时不会立即放到老年代,而是经过复制,从Eden复制到suvivor中。
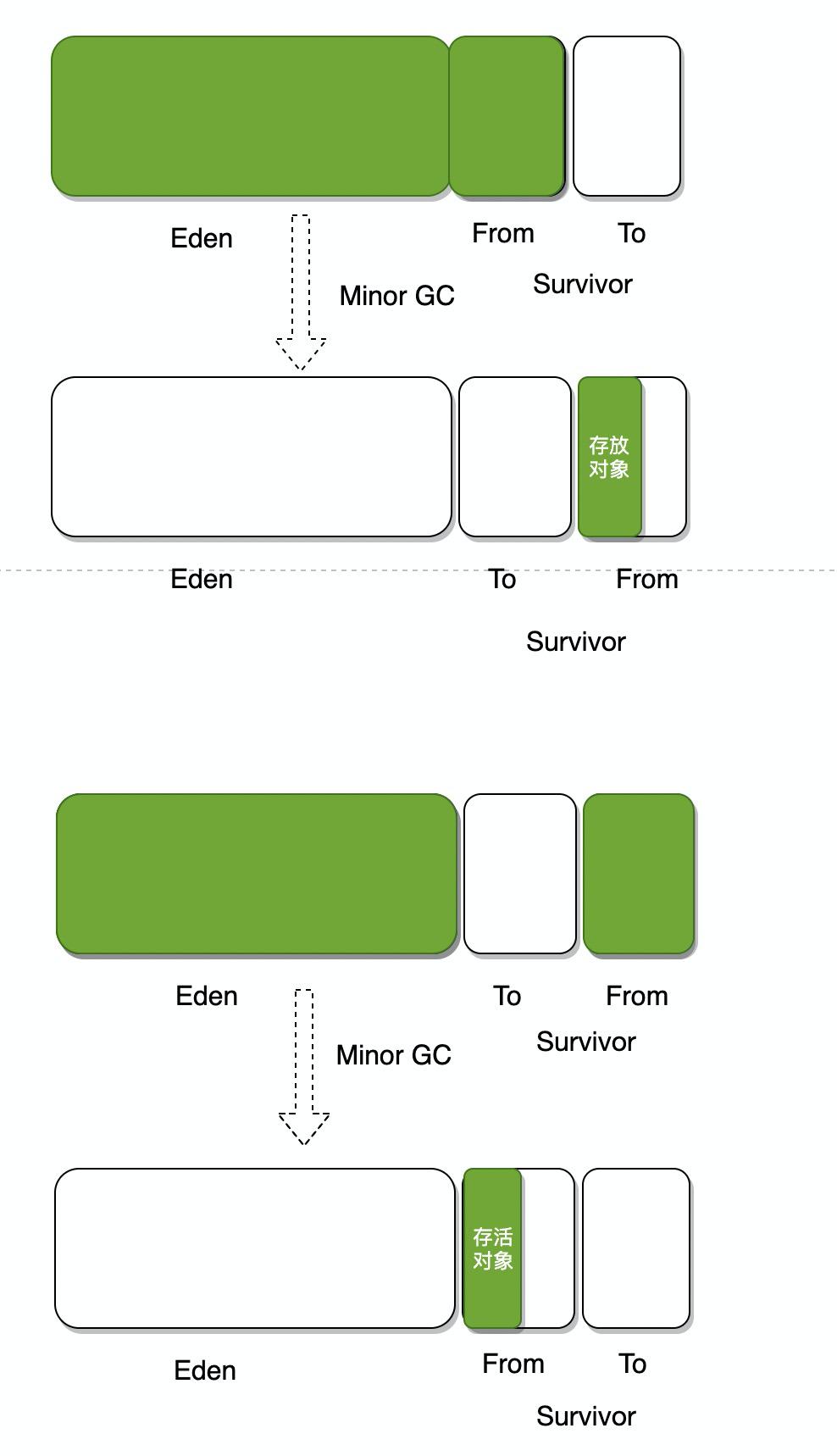
当新生代发生GC时,通常叫做minor GC,老年代发生GC叫做major GC,或者Full GC。网上很多人说两者有区别,也有说没区别的。其实我是觉得怎么说都不为过。Full GC可以包括Minor GC,所以说Full GC范围更广,但Minor GC在Full GC中不是必需的,一般情况下Full GC就是对老年代/永久代的回收。
minorGC 采用的是标记复制算法,即当触发minor GC时,会将Eden以及suvivor from中的对象进行标记,将不被回收的对象复制到suvivor to中(放不下直接放到老年代),随后清除Eden以及suvivor对象,随后再将suvivor to中的对象移步到suvivor from,此时对象年代+1,如果到了15,会被放到老年代。
那什么样的对象会被回收呢?JAVA采用了三色标记法,他会对对象进行可达性分析,从GC root对象开始,不可达的就是垃圾。
黑色 :表示root对象或者root对象的子对象都被扫描。
灰色 :对象本身被扫描,但还没扫描完该对象中的子对象
白色 :未被扫描对象,扫描完成所有对象之后,最终为白色的为不可达对象,即垃圾。

GC过程:
2)GC收集器
1) Serial 收集器
这种是最古老的一种收集器了,它是单线程版本,在最早的新生代收集中都采用这种算法。这种单线程收集意味着当要进行GC时,就会发生STW。但是,也正因为是单线程,不会存在线程切换的开销,效率很高,且STW的时间一般不长,尤其是对于单CPU的情况。如果GC频率不高,还是很优秀的,这也是为什么现在很多的虚拟机依然把它当作新生代默认的收集器。
该收集器在新生代采用复制算法,老年代采用标记-整理算法。
2) ParNew 收集器
它是Serial收集器的多线程版本,其余完全没区别。因此在多CPU的情况下,它比Serial收集器更高效。
3)Parallel Scavenge 收集器
这是一个新生代收集器,它追求的目标是达到更高的吞吐量。它可以自适应调整参数。
其余几个不说了,主要说下CMS和G1.
4)CMS收集器
它的目标就是尽可能的缩短STW的时间,从而提高GC效率。是老年代的一种收集器。
CMS全称Cocurrent Mark Sweep,它的意思已经很清晰明了了,并发标记清除,其主要经历以下几个过程:
-
标记;
-
并发标记;
-
重新标记;
-
并发清除。
1、初始标记
初始标记会标记所有与GC Root直接关联的对象,这个过程会STW,但耗时较短;
2、并发标记
并发标记所有与GC ROOT有关联的对象,不一定是直接关联的。耗时长,但因为是并发,所以不影响用户进程。
3、重新标记;
重新标记是因为在上述过程中,可能会有新产生的对象,这个过程会STW,但因为新产生的也不会很多,因此耗时也不会很长。实际上,由于本环节会扫描整个堆(虽然是回收老年代,但也有可能,有些新生代会引用老年代对象),因此在真正进行重新标记之前,会进行可中断的预处理,目的就是为了能够进行一次Minor GC,从而回收一些新生代的对象,减少重新标记时堆的扫描时间。与此相对应的是在新生代GC时,即Minor GC时,同样也会扫描老年代的对象。为了减少老年代对象的扫描,虚拟机采用了空间换时间的策略,使用卡表用来标记。
卡表将整个堆划分为一个个大小为 512 字节的卡,并且维护一个卡表,用来存储每张卡的一个标识位。这个标识位代表对应的卡是否可能存有指向新生代对象的引用。如果可能存在,那么我们就认为这张卡是脏的。在进行 Minor GC 的时候,我们便可以不用扫描整个老年代,而是在卡表中寻找脏卡,并将脏卡中的对象加入到 Minor GC 的 GC Roots 里。当完成所有脏卡的扫描之后,Java 虚拟机便会将所有脏卡的标识位清零。想要保证每个可能有指向新生代对象引用的卡都被标记为脏卡,那么 Java 虚拟机需要截获每个引用型实例变量的写操作,并作出对应的写标识位操作。
卡表能用于减少老年代的全堆空间扫描,这能很大的提升 GC 效率 。
4、并发清除
标记后,开始并发清除,这个过程耗时也相对长一些,但同样是因为并发,并不会出现STW。

上述就是CMS的整个过程,优点很明显,提高了效率,但缺点也很明显,一是它采用标记-清除算法(之所以选择标记清除,是因为回收是并发执行的,如果采用标记整理或者复制,可能会导致用户线程在访问数据时出现内存异常),会产生很多的内存碎片;其次就是在并发清除时,用户进程仍然会产生许多对象,这些对象可能要等到下次回收,这部分被称作是浮动垃圾。
5)G1收集器
G1收集器是从JDK1.7开始使用的,它的产生很好解决了CMS所产生的碎片化的问题,它是基于标记-整理算法进行垃圾回收。
G1不再像传统的收集器那样,把整个内存区域分成固定的新生代,老年代和永久代。而是把整个区域分成固定大小的区,叫做region,这个region彼此之间是逻辑连续的。且也都较做Eden、Survivor 、Old、Humongous .
6) ZGC收集器
该收集器是JDK11推出的收集器,
上面的垃圾会收集几乎都会触发STW,但并不是任何时候都会STW,而是要等待用户线程到达安全点SafePoint才可以进行STW。虚拟机的做法就是当需要STW,会设置一个标志位,用户线程检测到标志位时,会达到安全点就将线程挂起了。
安全点指的是一个稳定的状态,即当前堆栈不会发生变化,比如一些指令复用,循环,方法调用等。
新生代GC:
简单描述其思想就是当Edgen空间耗尽时,会触发 Young GC,Edgen区域可用对象移动到Survivor空间,如果Survivor空间不足,就会移动Old空间。这样Eden空间就空了。
那么对于G1,它是否需要扫描整个老年代对象来标记的。答案是否定的,G1通过记录堆和堆的引用关系来避免扫描整个老年代。每一个region都会记录old->yound的引用,称为RSet。因此扫描时,只需要扫描新生代的区域即可,这样就大大提高了效率。
老年代GC:
也叫MixGC,其实它不止时清理老年代,Young也会清理.官网描述的过程:Initial Mark(STW) -> Root Region Scan -> Cocurrent Marking -> Remark(STW) -> Copying/Cleanup(STW && Concurrent)
GC调优
GC需要关注的指标:延迟、吞吐量。
针对于当前系统的GC情况,做优化。
1、最小堆、最大堆设置相同,避免扩容引发GC;
2、Young区,Old区,进行调整,避免因为过早进入Old区,从而引发Major GC,调整包括Young区大小以及进入Old区年龄;
3、Metaspace空间,设置为固定,避免出现OOM;
4、堆外内存也要避免OOM;
三、虚拟机执行子系统
1、Class文件结构
诸如Java,Python,PHP等语言都需要借助虚拟机来执行,因此首先都需要翻译成虚拟机可识别的字节码,其中Java需要通过编译生成class字节码文件.class文件是一个二进制文件,其中存储的是程序运行时必要的文件。
ClassFile {u4 magic;u2 minor_version;u2 major_version;u2 constant_pool_count;cp_info constant_pool[constant_pool_count-1];u2 access_flags;u2 this_class;u2 super_class;u2 interfaces_count;u2 interfaces[interfaces_count];u2 fields_count;field_info fields[fields_count];u2 methods_count;method_info methods[methods_count];u2 attributes_count;attribute_info attributes[attributes_count];}数据结构组成:
- 魔数;
- 文件版本号;
- 常量池;
常量池包括字面量和符号引用。字面量主要是只文本字符串的数值以及final修饰的变量;这里所说的都是数值是存在常量池中。符号引用主要是指:
方法的名称和描述符
类和接口的全限定名
字段名称和描述符
和常量池对应的是运行时常量池,在类加载过程中,常量池会被加载到内存中,变成运行时常量池,在这个过程会生成类对象,类对象就是方法区各个方法访问的入口。
运行时常量池的作用是存储java class文件常量池中的符号信息,运行时常量池中保存着一些class文件中描述的符号引用,同时在类的解析阶段还会将这些符号引用翻译出直接引用(直接指向实例对象的指针,内存地址),翻译出来的直接引用也是存储在运行时常量池中。
运行时常量池相对于class常量池一大特征就是具有动态性,java规范并不要求常量只能在运行时才产生,也就是说运行时常量池的内容并不全部来自class常量池,在运行时可以通过代码生成常量并将其放入运行时常量池中,这种特性被用的最多的就是String.intern()。(上面内容是来自深入理解虚拟机,这个地方我还有些疑惑的,正常intern方法生成的应该在字符串常量池中吧?)
-
父类索引、方法索引;
-
字段表集合;
-
方法集合;
-
描述符;
2、类加载机制
JVM会将我们编译生成的class文件,通过类加载系统(类加载器)加载到虚拟机内存中,如下图所示。
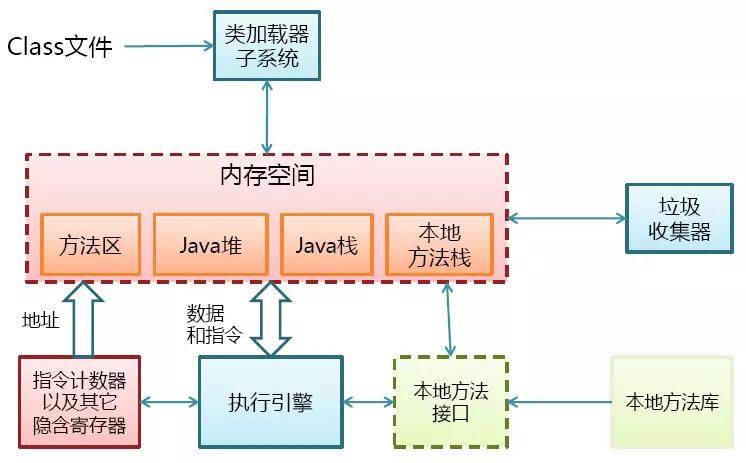
具体的加载过程要经过如下几步,如图所示:

1、加载
也称装载,这个过程就是查找所有的class文件。可以是本地系统的class文件,也可以是通过网络下载的class文件,也可以是所有jar包,war包的class文件,从专有数据库加载,Class.forName()加载,ClassLoader.loadClass()方法动态加载等等。该过程主要完成的事情就是将类的class加载到内存,在JAVA堆中生成一个表示该类的java.lang.Class对象,作为这个类的各个数据的入口。
2、连接
1)验证
验证就是确保被加载的类的准确性,符合JAVA虚拟机的规范。这个就是一个标准的验证过程,主要包括文件名,元数据,字节码和符号引用等验证。
2)准备
该阶段主要是为类的静态变量分配内存,并初始化默认值。即类中static声明的变量。不过这里还是要分成两种情况,即是否被final修饰。
private static final int s=100; //在该阶段初始化值为100private static int s=100; //在该阶段初始化值为0.赋值100的指令是在后续初始化阶段做的。3)解析
解析阶段是将常量池中的符号引用解析为直接引用。
符号引用:一种可以唯一表示类的字符串,此时它并没有在内存中。在Class文件中它以CONSTANT_Class_info、CONSTANT_Fieldref_info、CONSTANT_Methodref_info等类型的常量出现。它和内存布局完全无关,它能够准确定位到目标。
直接引用:能够直接指向目标的指针或者间接指向目标的引用(句柄),即定位到真正在虚拟机内存中的地址。
该过程会处理类、接口、接口方法、类方法、字段、方法类型、方法句柄、调用点等。
通过该过程,目标已经被叫加载到JVM中。
3、初始化
该过程由JVM完成,该步骤是对类静态变量、静态代码块进行初始化,以及类的初始化。但类执行初始化是有条件的。
-
用new创建对象时;
-
get或者set类的静态字段或者静态方法时;
-
使用JAVA反射进行调用的时侯,即java.lang.reflect调用;
-
虚拟机启动时,需要初始化main函数的类;
下面的情况不会初始化:
-
通过子类调用父类的静态字段,只会初始化父类,不会初始化子类;
-
通过数组引用来引用类,不会初始化;
-
常量在编译时被存储到常量池中,也不会初始化;
-
通过类名获取 Class 对象,不会触发类的初始化;
-
通过 Class.forName 加载指定类时,如果指定参数 initialize 为 false 时,也不会触发类初
始化,其实这个参数是告诉虚拟机,是否要对类进行初始化;
-
通过 ClassLoader 默认的 loadClass 方法,也不会触发初始化动作。
类初始化的步骤:
如果父类还没有被初始化,优先初始化父类;
如果该类中有初始化语句,依次执行初始化语句
4、卸载
卸载时机:
- 执行了System.exit()方法
- 程序正常执行结束
- 程序在执行过程中遇到了异常或错误而异常终止
- 由于操作系统出现错误而导致Java虚拟机进程终止
类加载器:
上述加载过程是由加载器完成的,加载的层次关系如下:

加载是自下而上进行的,当加载器收到类加载的请求时,自己不会加载该类,而是将请求转发给父类加载器去加载,一层一层,最终都会到达启动类加载器。当父类无法加载的时侯,子类才会去尝试加载。这种加载过程,在Java中叫做双亲委派模型。该模型的优点是对于基础类,可以保证各个加载器加载的都是同一个,而不会出现混乱的现象。也就是说,它主要是保证Java核心类的安全。而其中除了BootStrapLoader加载器,其他加载器都有自己的父类。
源码:
protected Class<?> loadClass(String name, boolean resolve)throws ClassNotFoundException{synchronized (getClassLoadingLock(name)) {// First, check if the class has already been loadedClass<?> c = findLoadedClass(name);if (c == null) {long t0 = System.nanoTime();try {if (parent != null) {c = parent.loadClass(name, false);} else {c = findBootstrapClassOrNull(name);}} catch (ClassNotFoundException e) {// ClassNotFoundException thrown if class not found// from the non-null parent class loader}if (c == null) {// If still not found, then invoke findClass in order// to find the class.long t1 = System.nanoTime();c = findClass(name);// this is the defining class loader; record the statssun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);sun.misc.PerfCounter.getFindClasses().increment();}}if (resolve) {resolveClass(c);}return c;}}每一层负责的类:
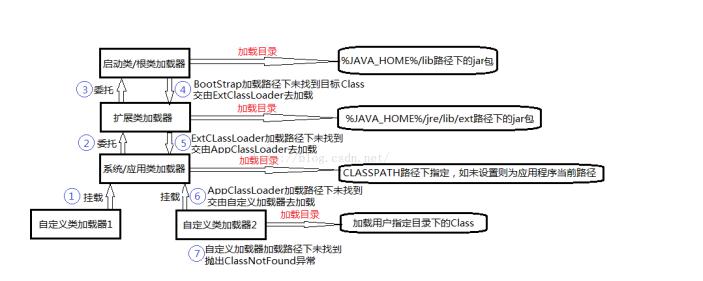
总结类加载的机制:
- 缓存机制 。加载过程首先会检查缓存中是否存在;
- 双亲委派模型机制;
- 全盘负责
双亲委派模型破坏:
双亲委派模型是可以破坏的,可以通过以下几种方式:
1、继承ClassLoader,重写loadClass方法,这样就可以按照自己的思路去加载类了,但这不是提倡的做法;
2、使用线程上下文类加载器;
JAVA中有一些标准的服务需要通过应用自定义实现类(就是通常我们所说的SPI机制)的,比如JNDI,JDBC等,因此需要通过启动类加载器加载,但是由于双亲委派模型只能自下而上委托,不能逆向,因此这时候就需要破坏该模型。而破坏该机制使用的就是线程上下文加载器(Thread Context Class Loader,TCCL)。如果当前线程没有设置,就默认从父线程继承,如果整个应用全局没有设置,就是应用程序加载器ApplicationLoader。显示地设置可通过Thread的setContextClassLoader方法实现。
拿JDBC举例,接口时java.sql.driver。在类加载过程,会执行DriverManager的静态代码块:
static {loadInitialDrivers ();println ("JDBC DriverManager initialized");}
接着会调用SPI机制重要的一个类ServiceLoader:
ServiceLoader<Driver> loadedDrivers = ServiceLoader. load (Driver.class);
ServiceLoader主要负责加载开发者实现的类。接着往下看:
public static <S> ServiceLoader<S> load(Class<S> service) {ClassLoader cl = Thread. currentThread ().getContextClassLoader();return ServiceLoader. load (service, cl);它出来了,TCCL出来了, TCCL本质上是属于APPClassLoader,。
4、为了实现热部署等功能自定义的,比如OSGI。
这个地方没有深入研究过。
在Tomcat中也实现了模型的破坏,因为其可部署多个应用,不同的web应用可能引用同一个依赖的不同版本,如果使用双亲委派模型,无法做到隔离。所以其通过自实现ClassLoader来实现不同web程序的class隔离。
四、程序编译
JAVA的程序编译主要包括以下几种:
- javac的早期编译,即将JAVA代码转换成字节码;
- JIT编译,运行期间的编译,将字节码转变为机器码,二进制码;
- 静态提前编译AOT,直接将JAVA代码变成机器码(不怎么常见呢)
1、早期编译
早期编译即javac所做的工作,主要经历如下几步:
- 词法、语法解析,获得一个抽象语法树;
- 填充符号表;
- 注解处理器;
- 语义分析:
- 标注检查:变量是否声明、变量与赋值之间的类型是否匹配;
- 数据及控制流分析:程序变量是否在使用前赋值、函数是否有返回值;
- 解语法糖(JAVA语法糖有泛型、自动装箱拆箱、可变长参数等);
- 字节码生成;
自动装箱拆箱例子:
Integer a = 3;Integer b = 3;Integer c = 200;Integer d = 200;Integer e = 203;System.out.println(a == b); //trueSystem.out.println(c == d); //falseSystem.out.println(e == d+a); //trueJAVA中的语法糖有很多,其目的就是为了能够方便开发者使用,虽然不属于JAVA语法本身的功能,但却可以极大得方便开发者。比较常见的语法糖:
1、泛型;
2、自动拆箱、装箱;
3、可变长参数;
4、foreach循环;
5、switch string类型,实际上使用了string的hashcode以及equal;
6、枚举;
7、内部类;在编译时会转为单独的class;
8、条件编译;
9、字面量 int a=10_1000,会将"_"去掉。
2、晚期编译优化
对于热点代码,进行即时编译(Just In Time Compile,JIT),将其转化为本地机器代码,从而加快执行效率。热点代码如被多次执行的方法、被多次执行的循环体等等。
HotSpots使用的是C1、C2两种及时编译器。
在即时编译的过程中有很多的优化技术,它可以对我们运行的程序进行优化,如:
- 公共表达式消除;
- 方法内联;
- 逃逸分析:方法逃逸、线程逃逸
- 栈上分配;
- 同步消除(锁消除、锁粗化、锁膨胀);
- 标量替换,标量是指不能再拆解的对象,比如几种基础数据类型。拆解之后可使得数据在栈上分配,以及可能被虚拟机分配至机器的高速存储器;
问题
1、系统出现问题,如何排查? 内存过大? CPU使用率过高,如何排查?排查思路?
CPU过高:
1)使用arthas分析,thread命令即可查看当前哪个线程消耗CPU比较多。 thread 某个线程id,查看线程堆栈。
2)
先用 ps 命令找到 Java 进程ID:
ps -aux|grep...复制代码
使用 top 命令查看 某进程 中的 所有线程 的资源使用情况:
top -Hp`进程id`print "%x" 线程id,转换成十六进制;
jstack 进程id打印处所有线程栈;生成线程快照的主要目的是 定位线程出现长时间停顿的原因 ,如 线程间死锁、死循环、请求外部资源导致的长时间等待 等。
grep 十六进制的线程,查看当前线程做什么工作呢。
内存过高
1、打印堆, jmap
2、查看 jvisualvm
JVM的经典问题总结:面试必备:JVM经典五十问
参考资料:
内存与垃圾回收——(八)字符串常量池 StringTable_string常量池内存回收-CSDN博客
Java Class类文件结构格式 - 知乎
深入理解Java虚拟机之破坏双亲委派加载机制 | AnFrank's Blog
基本功 | Java即时编译器原理解析及实践 - 美团技术团队
别总说CMS、G1,该聊聊ZGC了_CMS_猿人谷_InfoQ写作社区