RevCol:解决深度学习信息从低层(输入)传递至高层(输出)的过程中,信息会逐层丢失问题
- 学习解耦表示
- 可逆列网络(RevCol)
- 子特征1:多级可逆单元
- 子特征2:可逆列架构的宏观设计
- 子特征3:微观设计调整
- 子特征4:中间监督
- 联想
- 小目标涨点
- YOLO v5 魔改
- YOLO v7 魔改
- YOLO v8 魔改
- YOLO v9 魔改
论文:https://arxiv.org/pdf/2212.11696.pdf
代码:https://github.com/megvii-research/RevCol
传统的深度学习模型(遵循信息瓶颈原则)在层与层之间传递信息时,会逐步压缩与目标无关的信息。
在深度学习中,有一个常见的问题:当我们训练模型识别图片或者处理信息时,模型往往只关注于对当前任务有用的信息,而忽略其他可能对将来任务有用的信息。
这就像是在读书时,只记住了考试要考的知识点,但对书中其他有趣或有用的内容视而不见。
虽然短期内这样做可以帮助我们通过考试,但长期来看,我们可能会错过很多重要的知识。
类于交通系统中的立交桥设计。在繁忙的城市中,不同方向的车辆流需要高效地交织而不互相干扰。
立交桥通过不同层级的道路允许车辆在不同方向上流动,从而避免了交叉路口的拥堵和潜在冲突。
同样地,在深度学习网络中,信息需要在不同的层级(类似于不同的道路层级)之间流动。
传统的神经网络结构(比如简单的前馈网络)就像一个没有立交桥的交通系统,信息流(车辆)只能一层层单向传递,这可能导致信息的堵塞和丢失(交通拥堵)。
RevCol网络中的融合模块则像是在这些层级之间建立了立交桥,允许信息在高分辨率和低分辨率的层级之间自由流动(车辆在不同层级间行驶),从而减少了信息丢失,并增加了网络对信息的处理能力。
传统的卷积神经网络(CNNs)在信息流动方面就类似于普通道路系统,信息(车辆)从输入层(起点)一直传递到输出层(终点),中间的每一层只能接收到前一层的信息,难以直接获取到后面层的反馈。
我们得设计一个(立交桥网络)允许信息不仅向前传递,也可以从后续层返回到前面的层,就好比车辆在立交桥中可以自由地改变方向,从而提高了整个网络处理信息的灵活性和效率。
如果我们能在学习时,不仅仅记住考试内容,还能把书里的其他知识也整理归档,那么我们就能在需要时随时取用这些知识。
目标:让模型学会把信息分门别类地存储,既能记住对当前任务重要的知识,也能保存可能对未来任务有用的信息。
这种方法通过一个叫做可逆列网络(RevCol)的结构来实现。
RevCol就像一个高效的图书馆,它不仅能保存书中的所有内容,还能按照不同的主题将它们分类。
在这个图书馆里,信息是通过一系列的“列”进行管理的,每一列都负责存储一种类型的信息。
通过特殊的技术,这些列之间能够互相传递信息,而不会丢失任何细节。
这种方法使得模型在学习时,能够更全面地理解和保存信息,不仅仅局限于当前任务,也为处理将来可能遇到的问题做好了准备。
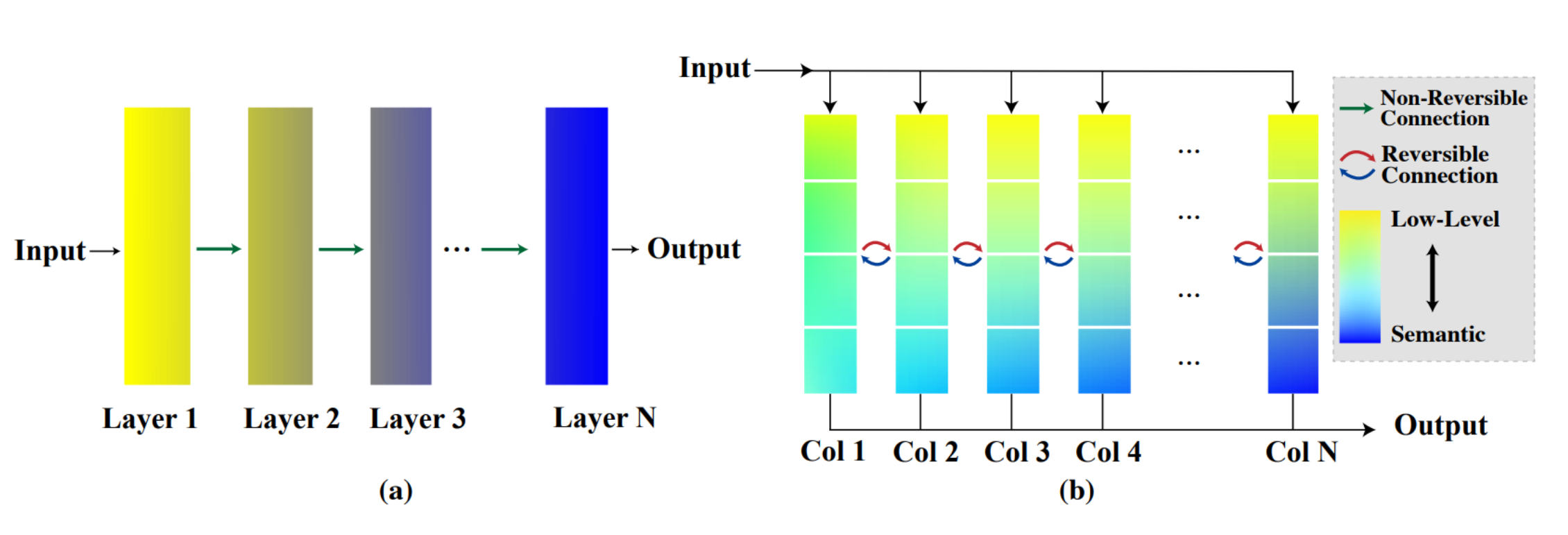
图1(a)展示的是传统的单列网络(比如一个普通的深度神经网络),其中输入数据经过多个层(Layer 1, 2, 3, …, N)处理后得到输出结果。
每层都对输入数据进行某种形式的转换,并且随着层级的深入,通常会丢失一些信息。
图1(b)展示的是RevCol网络,它包括多个列(Col 1, 2, 3, …, N),每个列都处理输入数据,并且通过可逆连接(由红色曲线标识)在列之间传递信息。
这种设计试图在不同列之间保持信息,确保即使在深层次也能保留低级(接近输入)和高级(语义)特征。
黄色表示低级信息,蓝色表示高级语义信息。
学习解耦表示
采用可逆列网络(RevCol):
-
RevCol的设计:通过N个具有相同结构但权重不同的子网络(列)组成,每个列接收输入的一个副本并生成预测,从而在每个列中存储从低级到高级语义表示的多级嵌入。
通过引入可逆变换,无损地将多级特征从第i列传递到第i+1列,从而预测输入的最终解耦表示。
-
为什么使用RevCol:由于问题的特征在于传统深度学习模型在特征传递过程中损失了大量信息,RevCol通过可逆变换保证信息无损传递,同时提供从低级到高级的多级语义表示。
引入新型的可逆多级融合模块:
- 新型可逆多级融合模块:解决了传统RevNets的两个主要缺陷:特征图形状的限制和最后两个特征图必须同时包含低级和高级信息的问题。
- 为什么使用这个子解法:这个新型模块能够更灵活地处理不同形状的特征图,并允许更有效地优化网络,避免了与信息瓶颈原则相冲突的问题。
与信息瓶颈原则下的传统深度学习模型不同,这种方法不是简单地抛弃与目标无关的信息,而是力图在保留尽可能多的输入信息的同时,将任务相关的概念或语义词嵌入到几个分离的维度中。
这种方式更贴近于生物细胞的机制,每个细胞虽然含有整个基因组的完整副本,但不同细胞的基因表达强度不同,类似地,在计算视觉任务中,也理应保留高级语义表示的同时,保持其他维度中的低级信息。
可逆列网络(RevCol)
如何在不丢失信息的前提下,实现特征的解耦和高效传递。
-
多级可逆单元:想象把信息分成好几层,每一层都处理不同类型的信息(比如一层专注于颜色,另一层专注于形状)。我们用一种特殊的方法让这些信息层之间相互传递信息,但不会丢失任何东西,就像魔术一样。
-
可逆列架构:我们把网络分成多个部分(列),每个部分都用上面提到的魔术方法处理信息。这样,我们可以在不同的部分专注于不同的任务,比如一部分识别猫,另一部分保留背景信息。
-
微观设计调整:为了让这一切工作得更好,我们对网络的一些基础部件做了细微调整,比如改变一些参数,以确保信息在传递过程中不会被扭曲。
-
中间监督:我们在网络的不同部分加入了额外的监督,这就像是给学生额外的测验,以确保他们在学习过程中没有走偏。这有助于网络更好地保留和利用信息。
可逆列网络(RevCol)就像是一个高效的学习机器,不仅能学会识别猫和狗,还能在这个过程中保留大量的其他有用信息。
这种方法让网络更加强大和灵活,适用于多种不同的任务。
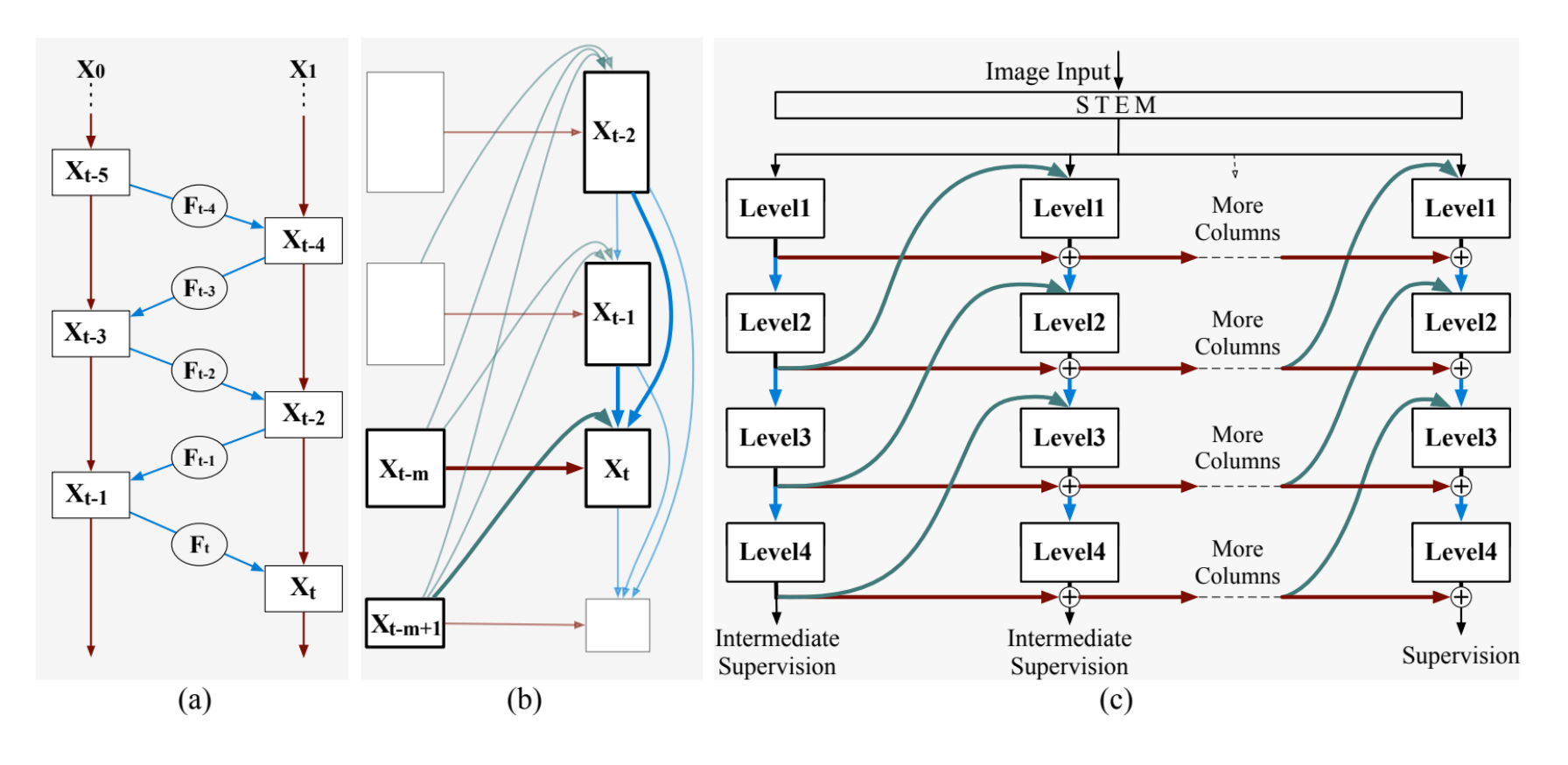
图2(a)展示的是RevNet中的一个可逆单元的例子,这是构建RevCol网络的基础。
这里显示了如何在不丢失任何信息的情况下,将输入xt通过一系列函数(Ft-1, Ft-2, …, Ft-4)转换为输出xt-5。
图2(b)是一个简化的多级可逆单元,展示了如何在网络的不同层级(Level 1, 2, 3, 4)之间传递和转换信息。
图2©展示了整个可逆列网络架构的概览,包括多个列和每个列的多个层级。
在不同层级上的中间监督(Intermediate Supervision)有助于训练过程中信息的保存和优化。
在RevCol网络中,传统的可逆结构(如RevNet)和非可逆的多列结构(如HRNet)都存在限制,包括严格的特征维度约束和信息损失问题。
特别是在进行多任务学习时,信息的保留对于模型的泛用性非常关键。
RevCol = 可逆操作的引入 + 融合模块的设计 + 中间监督的加入
子特征1:多级可逆单元
- 实现方式:通过扩展可逆变换方程,实现了特征的无损解耦传递。
- 每m个特征图分为一组,通过可逆变换在组内进行信息传递,确保了信息的无损。
- 选择原因:该方法可以在不同的语义层次或分辨率中使用不同形状的张量来表示特征,解决了特征维度强约束的问题,并易于与现有网络架构协作。
子特征2:可逆列架构的宏观设计
- 实现方式:RevCol通过多个子网络和可逆连接进行特征解耦,使用多级可逆单元简化输入,每个子网络处理图像分割成的非重叠块,提取多级特征图进行信息传递。
- 选择原因:这种宏观设计允许在不同任务中灵活使用高级和低级特征,通过可逆连接减少信息损失,提升模型的泛化能力。
子特征3:微观设计调整
- 实现方式:调整了卷积块和引入融合模块,以兼容宏观架构。
- 包括修改卷积核大小,采用可学习的可逆操作γ,优化网络稳定性和训练速度。
- 选择原因:微观设计调整使得原始的ConvNeXt块与RevCol的宏观设计兼容,提高了模型的精度和训练效率,同时保持网络的稳定性。
融合模块的设计:
- 实现方式:设计了一个新型的融合模块,以支持不同分辨率的特征融合,同时避免了传统可逆网络的严格特征维度约束。
- 选择原因:这解决了传统结构中特征维度强制匹配的问题,使得网络设计更灵活,可以在不同分辨率间更好地融合特征。
引入融合模块优化信息流动:
-
解决方案:设计了一种融合模块,结合了向上采样和向下采样的特点,以便在不同层级间更有效地传递信息。
-
选择原因:传统的网络在传递过程中可能会导致信息的损失,尤其是在高分辨率和低分辨率特征间的转换。
融合模块通过将低分辨率的特征向上采样,同时将高分辨率的特征向下采样,并将它们融合,以保持信息流动的连续性和完整性,从而提高网络的整体性能。
这样的设计使得在深层网络中的每一级都能获得丰富的上下文信息,增强了模型的表示能力。
子特征4:中间监督
- 实现方式:在网络的前几列添加额外的监督,通过优化二元交叉熵重建损失和分类损失,以减少信息丢失,提高特征的质量和网络的性能。
- 选择原因:中间监督可以在列间迭代时维持信息,减少信息在列内的丢失,提升网络对输入图像和预测之间互信息的下界,从而提高性能。
RevCol通过引入多级可逆单元和宏观设计调整,实现了特征的无损解耦传递。
微观设计的调整和中间监督的加入进一步优化了模型的训练效率和性能。
这些设计选择都是为了解决深度学习中特征传递与学习过程中的信息损失问题,确保了模型在处理不同任务时的灵活性和高效性。
联想
何时使用 - 可逆列网络(RevCol):当你需要一个能够在保留重要特征的同时减少信息损失的网络时,RevCol是一个合适的选择。特别是在下游任务可能需要原始输入数据中不同层次信息的场景,如迁移学习、多任务学习,或是领域适应。
RevCol到每个子解法:
- 可逆连接:类似于解压缩算法,保留所有信息,即使在数据经过多个处理层后。
- 融合模块:像城市交通枢纽,允许信息在不同层级间有效转换,防止信息丢失。
- 中间监督:相当于考试过程中的阶段测试,确保网络在学习过程中不偏离目标。
以融合模块为例,如果我们考虑将其替换为注意力机制,注意力机制允许模型专注于输入数据的最重要部分,类似于人类在观看场景时会自然地注意到最有意义的部分。
- 对比分析:融合模块通过物理地在网络中融合不同层级的特征来保留信息,而注意力机制则是通过赋予不同特征不同的权重来实现。
融合模块可能会在保持空间信息方面更有效,因为它们允许不同分辨率的特征直接合并。
另一方面,注意力机制在确定哪些信息最相关时可能更加灵活和有效,因为它可以根据上下文动态调整不同特征的重要性。
- 信息保持:融合模块通过直接合并来自不同层次的特征,能够保持丰富的空间信息。这是特别有用的,比如在处理图像的局部细节时,这些局部细节可能在高层次的抽象中丢失。
- 信息选择:注意力机制能够选择性地强调网络应该关注的信息部分。在RevCol中,这可以用来动态调整网络在不同列和层级中传递的特征的权重。
结合这两个概念,我们可以创建一个新的融合模块,其中包含注意力机制,使模型能够通过融合模块保持来自不同层的详细信息。
具体的改进点包括:
- 加权融合:在融合模块中,不同层级的特征图在合并前首先通过注意力机制进行加权。
这意味着,每个特征图不是简单地被物理合并,而是根据其对最终任务的相关性赋予了一个权重。
这允许模型更加关注对当前任务最有用的信息,类似于人类视觉系统会集中注意力于最重要的细节。
- 多尺度注意力:设计一个可以处理来自不同尺度(即分辨率)的特征图的注意力机制。
这样的机制可以在更广泛的上下文中评估信息的相关性,不仅仅是在单个层级内。
例如,一个来自较低层的特征图(较低级的特征,如边缘或纹理)可能对某个具体任务是至关重要的,而这一点可能在高层次的抽象特征中不是那么明显。
小目标涨点
更新中…