大纲
- PHON – phonetics and phonology
- 1. Phonetics and Representations of Speech
- 2. Acoustics of Consonants and Vowels
- SIGNALS – signal processing, with a focus on speech signals
- 3. Digital Speech Signals
- 4. the Source-Filter Model
- TTS – text-to-speech synthesis (focusing on concatenative synthesis)
- 5. Speech synthesis - phonemes and the front end
- 6. Speech Synthesis - waveform generation and connection speec
- ASR – automatic speech recognition (Focusing on HMM based ASR)
- 7. Speech Recognition - Pattern matching
- 8. Speech Recognition - Feature engineering
- 9. Speech Recognition - the Hidden Markov Model
- 10. Speech Recognition - Connected speech & HMM training
- SKILLS – maths, computing, writing
Module 1 – Phonetics and Representations of Speech 语音学
1. Vocal anatomy
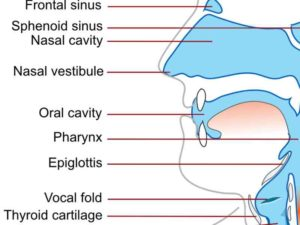
2. Consonants 辅音
Consonants(辅音) are speech sounds that are made with some degree of constriction in the vocal tract 声道.
Phoneticians define consonants according to three articulatory dimensions:
- Voice:voiced or voiceless (produced with vibrations of the vocal folds 声带);Breathy or Creak (e.g., ssss or zzzz)
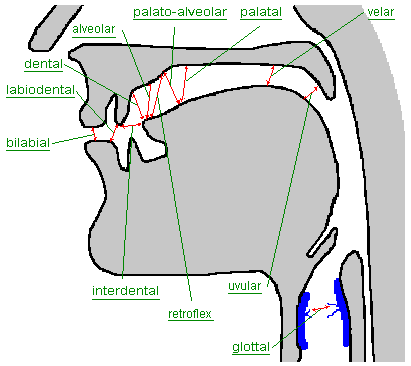
- Place 发音部位: place of articulation, where in the vocal tract the constriction is taking place (bilabial, labiodental, dental, alveolar, post-alveolar, palatal, glottal, and velar)
- Manner 发音方法: how much constriction is present in the vocal tract, ranging from complete closure to mere approximation (Fricative, Affricate, Approximant, Nasal, Plosive, Tap and flap consonants, Manner of articulation, Glides, Nasalization of vowels, Stop, Trill consonant)

3. Vowel articulation and description 元音
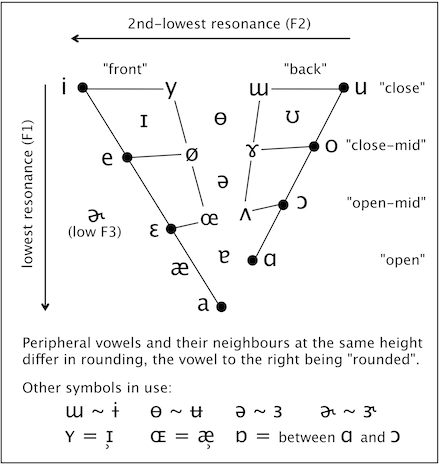
定位元音 (Cardinal vowels): 当舌头位于极端的位置,发出的元音就是定位元音,不论位置的前后或高低。
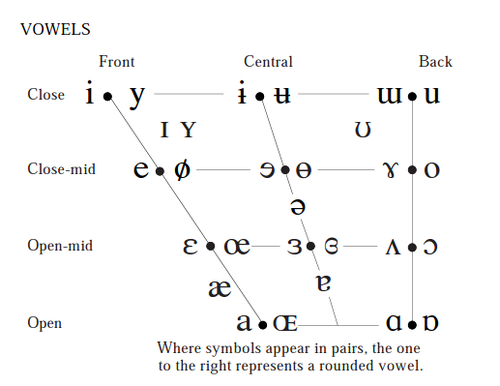


4. International Phonetic Alphabet 国际音标
Full IPA chart designed to allow for the transcription of all languages using a standard set of phonetic symbols.
The chart can be divided into 4 main sections:
i. Consonants,
ii. Vowels,
iii. Diacritics 附加符号或称变音符号
iv. Suprasegmentals 超音段音位:语音中除音段之外的的语音成分,例如声调、重音、语调、节奏等。超音段成分基本上等同于韵律成分。
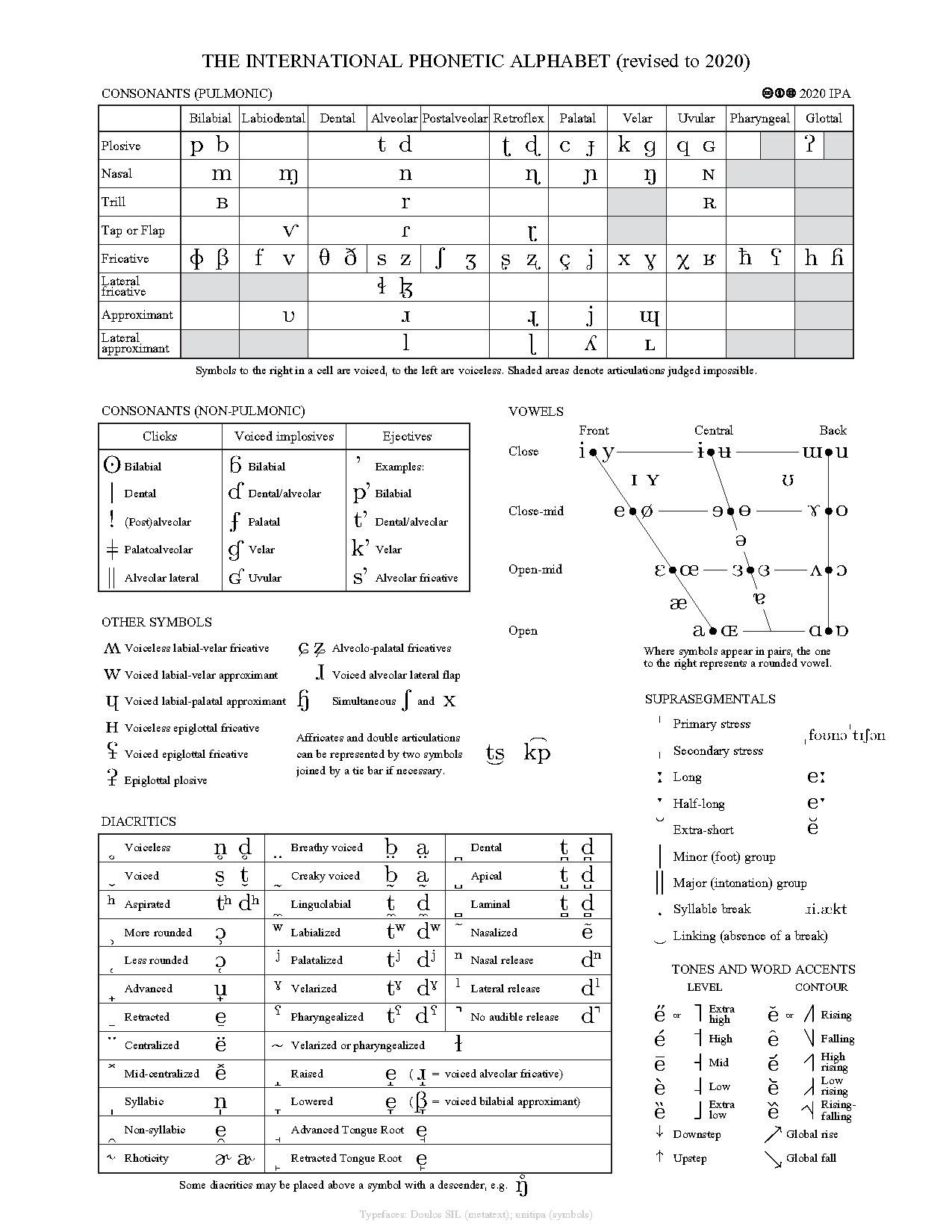
Pulmonic consonants:(columns: places of articulation; rows: manners of articulation; pairs: voiced/voiceless)
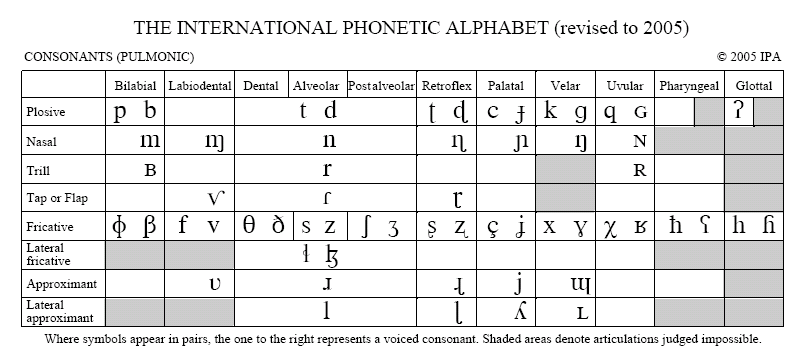
Vowels: Height, Advancement and Rounding

5. 补充: 语音学专有词英汉图解释
语音学习
Module 2 – Acoustics of Consonants and Vowels 声学特征
1. 专有名词
- waveform: Simple, complex, periodic, aperiodic, transient 瞬态波, and continuous waveforms.
- amplitude/intensity 幅度: of a sound wave is loudness 响度; measured in decibels (dB); More disturbance = more pressure = higher amplitude
- oscillation cycle 振荡周期
- frequency 频率 (=the inverse of the period) 1/T: Hertz (Hz), which represents cycles per second; related to our perception of pitch 音高
- frequency Spectrum 频谱: represents each component simple wave (傅里叶变化Fourier transform后) 会有不同个frequency components组成。
“幅度频谱”表示幅度随频率变化的情形,“相位频谱”表示相位随频率变化的情形。
对数振幅谱对原振幅A作了对数计算(20logA),所以其纵坐标的单位是dB(分贝)。 - 能量谱和功率谱:能量谱是原信号傅立叶变换的平方,单位是焦耳/Hz。功率谱=(傅立叶变换的平方)/(区间长度),单位是每赫兹的瓦特数(W/Hz)或dB/Hz

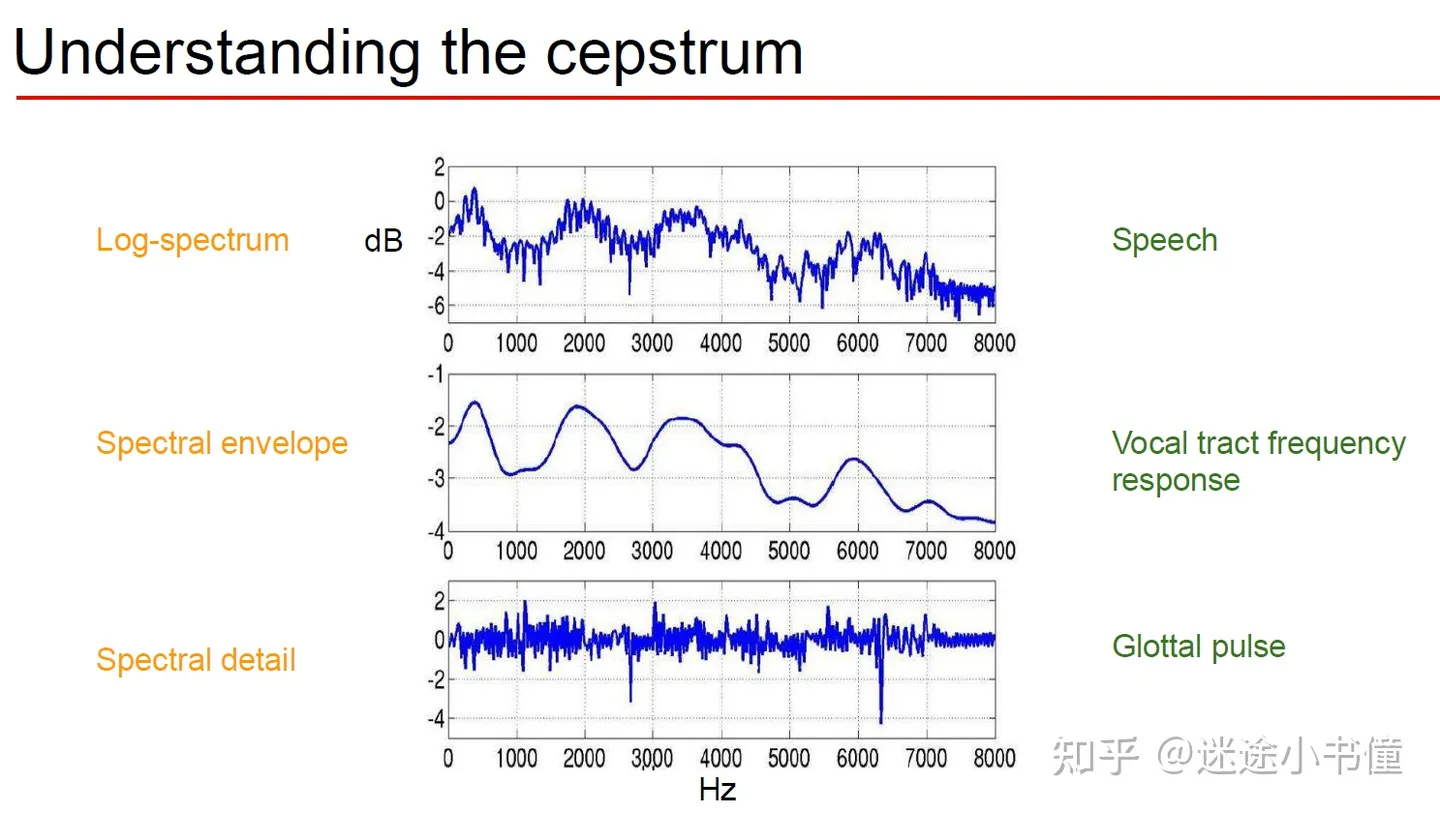
- spectral envelope 频谱包络: 将不同频率的振幅(amplitude)最高点连结起来形成的曲线
Spectrum = Spectral Envelope * Spectral Details
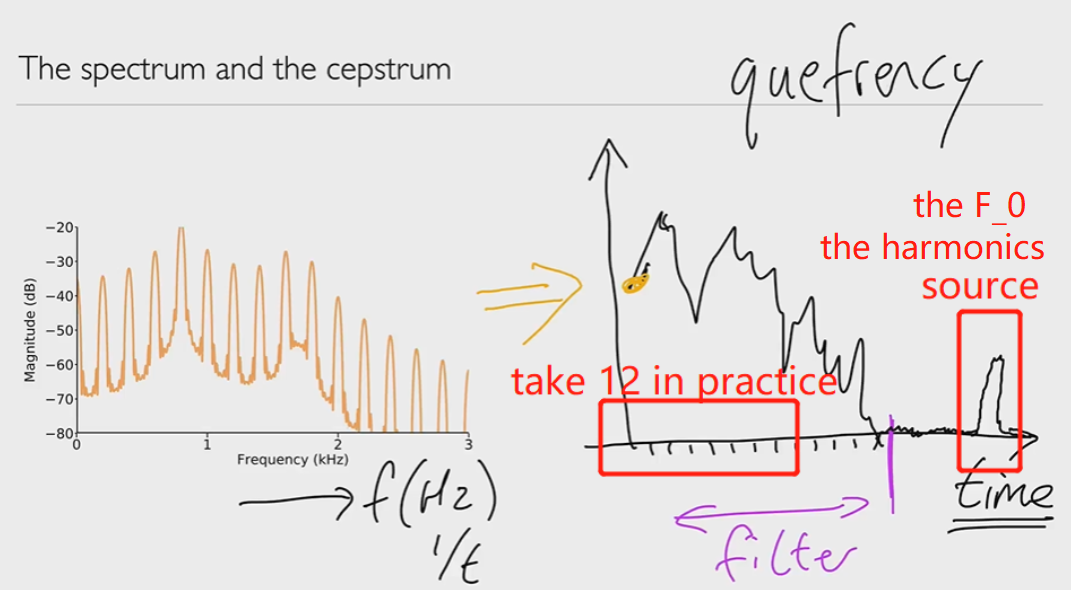
倒频谱 (Cepstrum):在频谱的对数的基础上,再进行一次逆傅里叶变换
- harmonics 谐波 (voice source):指周期函数或周期性的波形中能用常数、与原函数的最小正周期相同的正弦函数和余弦函数的线性组合表达的部分。a harmonic is a sinusoidal wave with a frequency that is a positive integer multiple of the fundamental frequency of a periodic signal【单一频率的驻波(Standing wave)可以理解为两列振幅、频率、波长都相同而方向相反的简谐波 (harmonic wave) 的叠加】
 可以看到多一个谐波,原wave就多一个峰
可以看到多一个谐波,原wave就多一个峰
最小正周期等于原函数的周期的部分称为基波fundamental tone或一次谐波1st harmonic(is also the fundamental frequency (f0) of the harmonic series)f0 = H1,最小正周期的若干倍等于原函数的周期的部分称为高次谐波。因此高次谐波的频率必然也等于基波的频率的若干倍,基波频率3倍的波称为三次谐波3rd harmonic
Lower harmonics tend to have a higher amplitude than higher harmonics, though this pattern is modulated by the presence or absence of formants, which amplify or dampen the harmonics. 低次谐波的振幅往往比高次谐波的振幅大
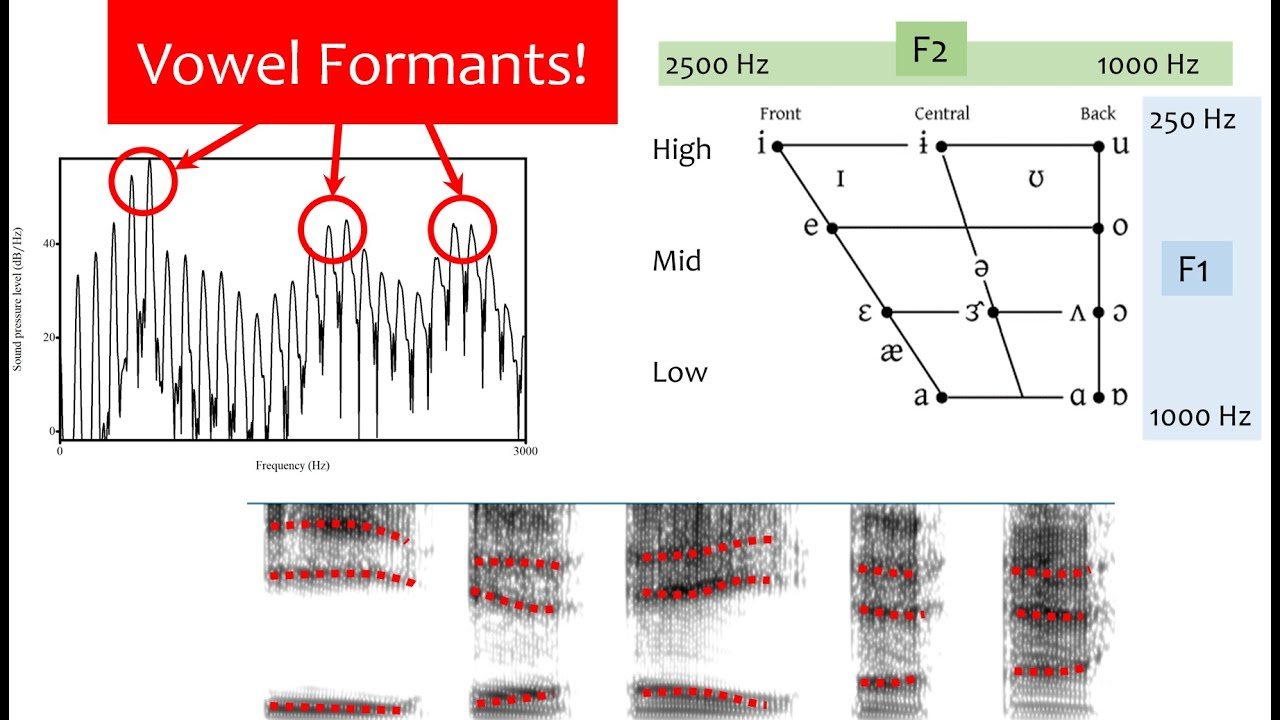
- formants 共振峰 (the shape of the vocal tract): 描述的是人类声道中的共振情形。共振峰是使听者能够区分元音的关键泛音。看频率范围frequency ranges显著增长或减少的地方(there is no predictable relationship between the formant frequencies in the spectrum. Instead they are determined by the physical properties (such as the size, shape, and position of the articulators) of the vocal tract)
- source filter model 源-滤波器模型: source - voice; filter - vocal tract
- aperiodic spectrum 非周期频谱:the spectra of aperiodic sounds are flat; no harmonics, no fundamental frequency

- spectrogram 时频谱 又叫声谱图(voicegram):a visual representation of the spectrum of frequencies of a signal as it varies with time 描述波动的各频率成分如何随时间变化的热图(heat map)
利用傅里叶变换得到的传统的2维频谱可展示复杂的波动是如何按比例分解为简单波的叠加(分解为频谱),但是无法同时体现它们随时间的变化。能对波动的时间变量与频率分布同时进行分析的常用数学方法是短时距傅里叶变换,但是直接绘成3维图像的话又不便于在纸面上观察和分析。时频谱在借助时频分析方法的基础上,以热图的形式将第3维的数值用颜色的深浅加以呈现。

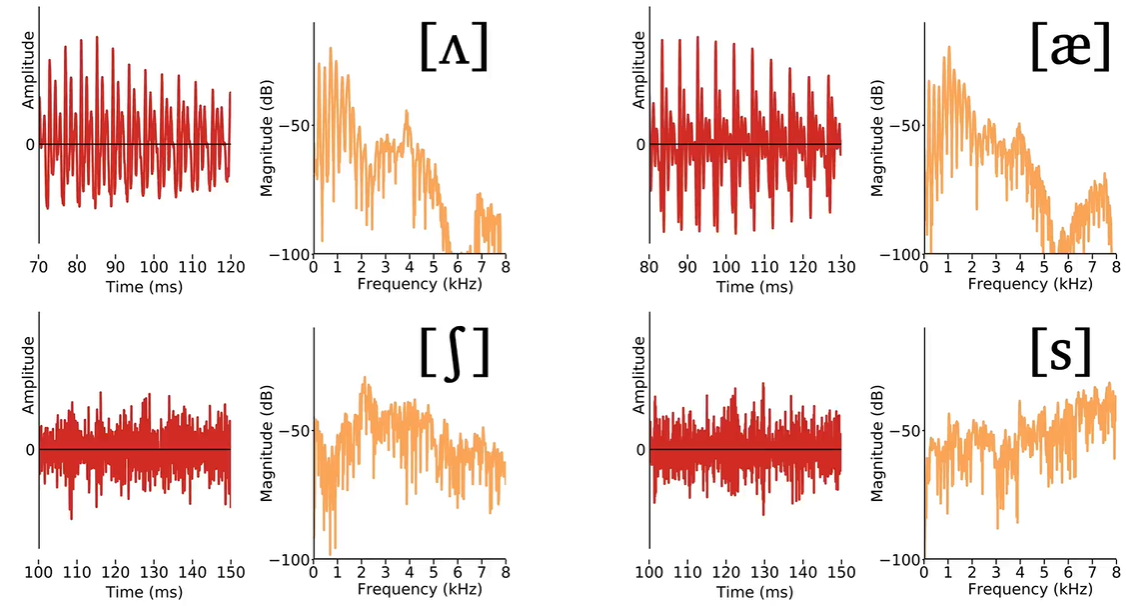
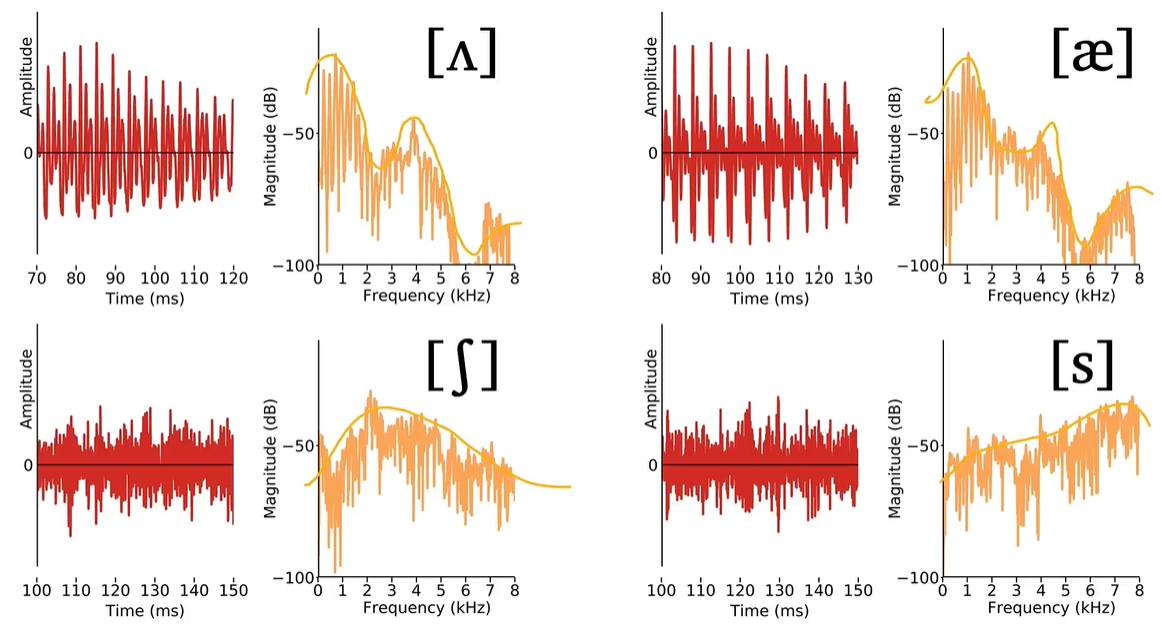
2. Acoustic characteristics of vowels

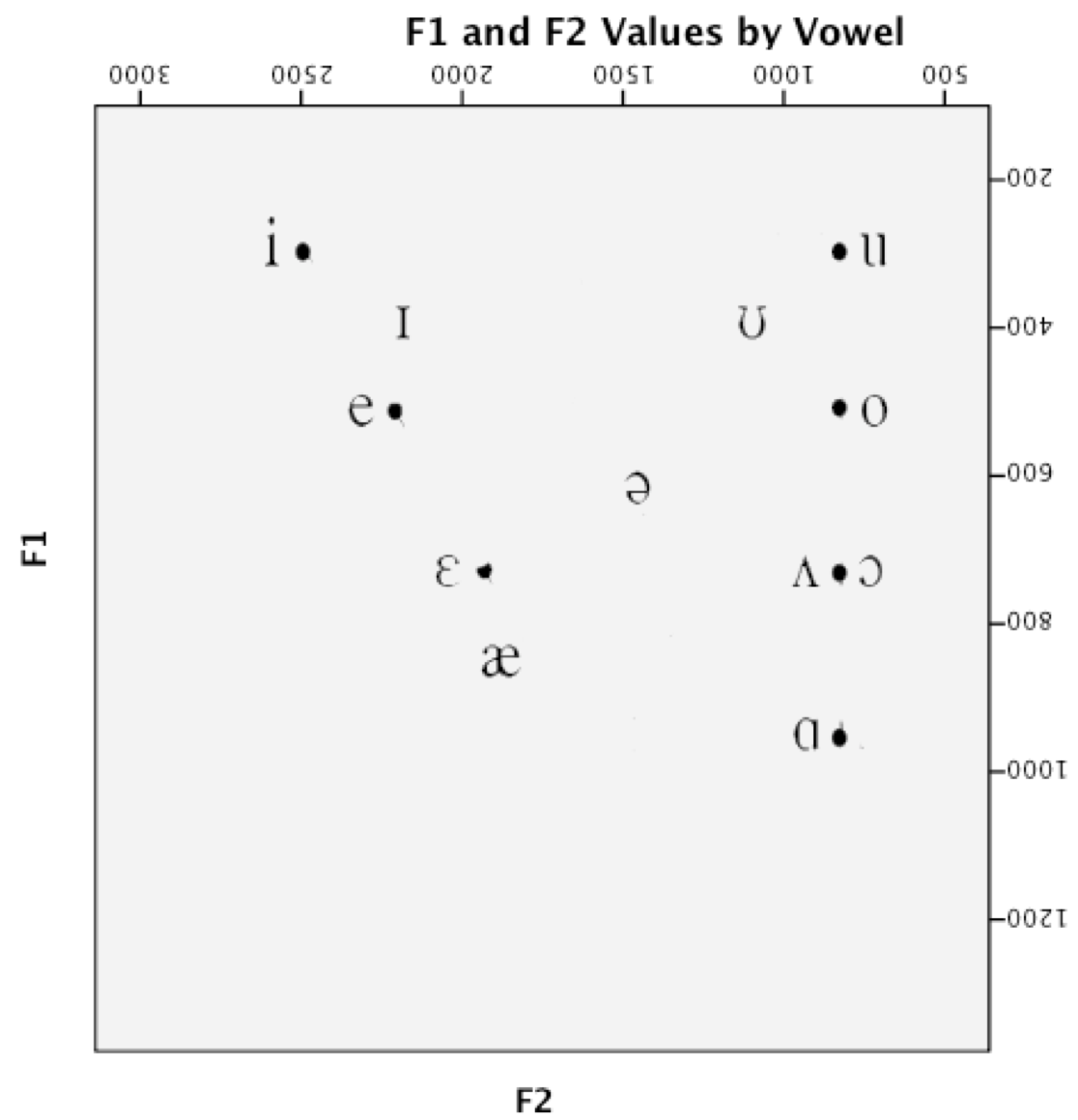
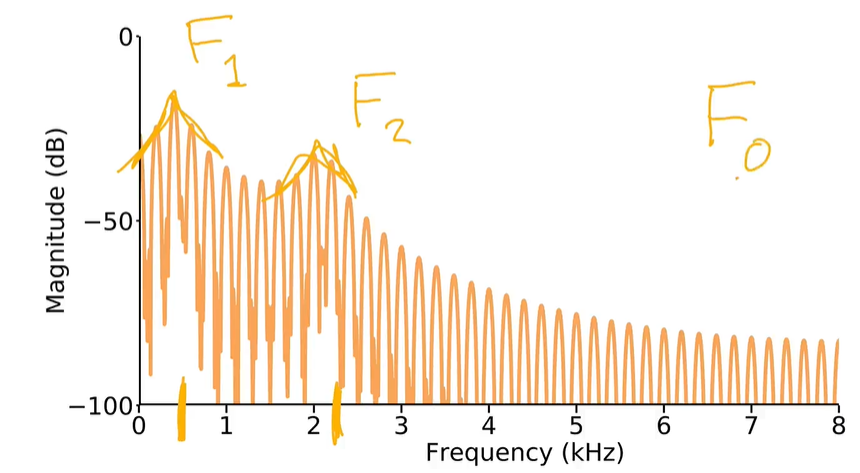
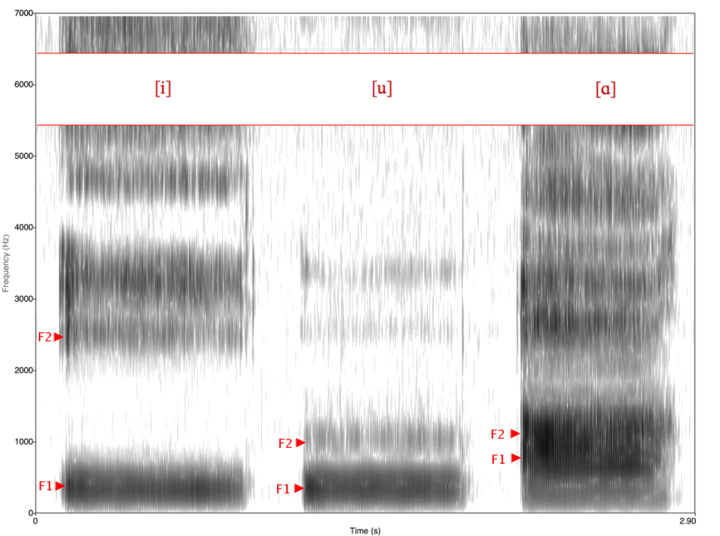
In [a] F1 and F2 are quite close together, while in [i] they are rather far apart. In [u] F1 and F2 are again close together, but lower in the frequency range than we saw for [a]
The relative position of the first and second formants result in the different vowel qualities that we hear.
spectrograms of 8 american English vowels. [i, ɪ, ɛ, æ, ɑ, ɔ, ʊ, u]


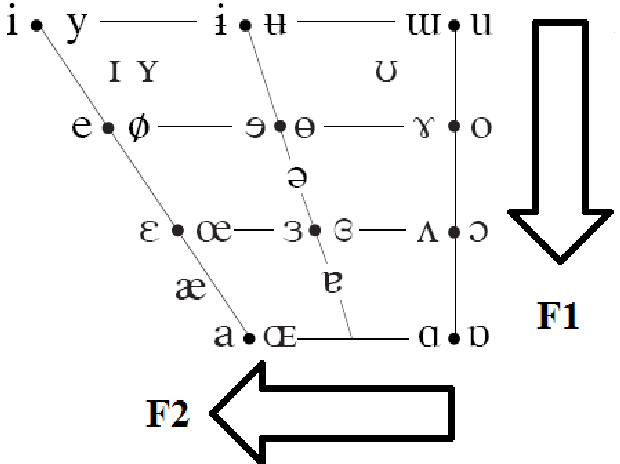
the lower the vowel, the higher the first formant will be in the spectrogram. The first formant is therefore inversely related to vowel height. Close/high vowels have lower F1, while open/low vowels have higher F1.
By comparison, the back vowels have lower F2 values than the front vowels as a whole.
Therefore, the second formant is directly related to vowel frontness. The more front a vowel is, the higher F2 will be. The more back a vowel is, the lower F2.
第一共振峰F1与元音高度成反比。闭元音/高元音具有较低的 F1,而开元音/低元音具有较高的 F1。第二共振峰F2与元音前置直接相关。元音越靠前,F2 就越高。元音越靠后,F2 越低。
前元音的 F1 和 F2之间通常有一些频率范围的振幅较低。相比之下,后元音的F1和F2非常接近。后元音都具有相似的 F2 值,这表明它们大致同样靠后,而前元音则显示出对于更开放的元音而言 F2 减小。

Vowel space 元音空间: use the vowel formant patterns described above to visualize the acoustic relationships between vowels by plotting the first and second formants against each other. 【reveals the relationship between the first formant and vowel height, and the second formant and vowel advancement.】和IPA的图很相似的规律
3. Acoustic characteristics of consonants
sonorants 响音: (vowels), nasals鼻音, and approximants近音. 发音时向出气流不受阻碍直接冲出口腔,并不受干扰而产生湍流
In sonorants, voicing is apparent in the periodic structure of the waveform, vertical striations in the spectrogram, or as clearly defined harmonics in the spectrum.
在声谱图中,浊音明显表现为或多或少规则间隔的垂直条纹。这些条纹可能更近或更远,具体取决于基频。紧密的条纹表示 F0 较高,较宽的条纹表示 F0 较低。当 F0 较低时,谐波间隔很近。如果 F0 高,谐波将分散得更远。
Obstruents 阻碍音: Consonants produced with a complete or near-complete obstruction of airflow through the vocal tract 调音方法为阻碍气流外出,令声腔气压升高的辅音. These include plosives/stop 爆破音, fricatives 摩擦音, and affricates塞擦音.
 voice bar is present when the vocal folds are vibrating.
voice bar is present when the vocal folds are vibrating.
摩擦音(Fricatives):清唇齿擦音(voiceless labiodental fricative) [f]、清齿间擦音(voiceless interdental fricative) [θ]、清齿龈擦音(voiceless alveolar fricative)和清齿龈擦音(voiceless postalveolar fricative) [ʃ] 前元音(preceding vowels)
鼻音(Nasals):双唇音(bilabial) [m] 齿龈音(alveolar) [n] 和软腭音(velar) [ŋ]
近似音(approximant):唇软腭近似音(labiovelar approximant) [w],齿龈音近似(alveolar approximants) [l] 和 [ɹ]
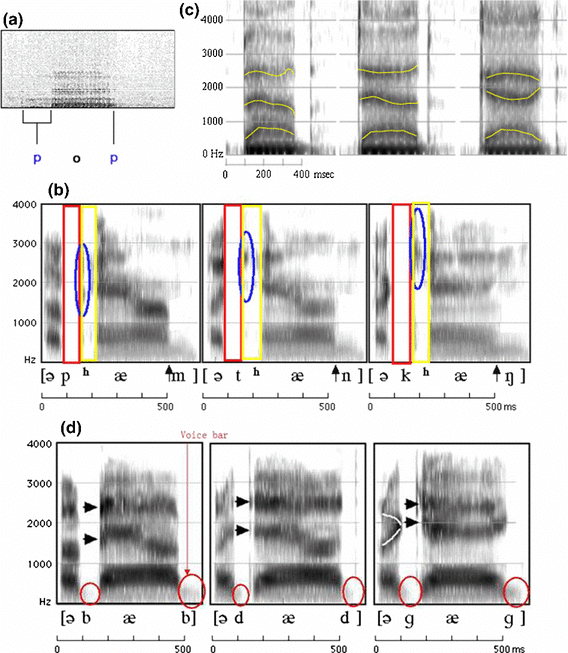
4. Voice Onset Time (VOT) 发声起始时间
The terms “voiced” and “voiceless” are used indicate whether the vocal folds are vibrating, but these terms do not tell us much about when those vibrations occur, relative to other events.
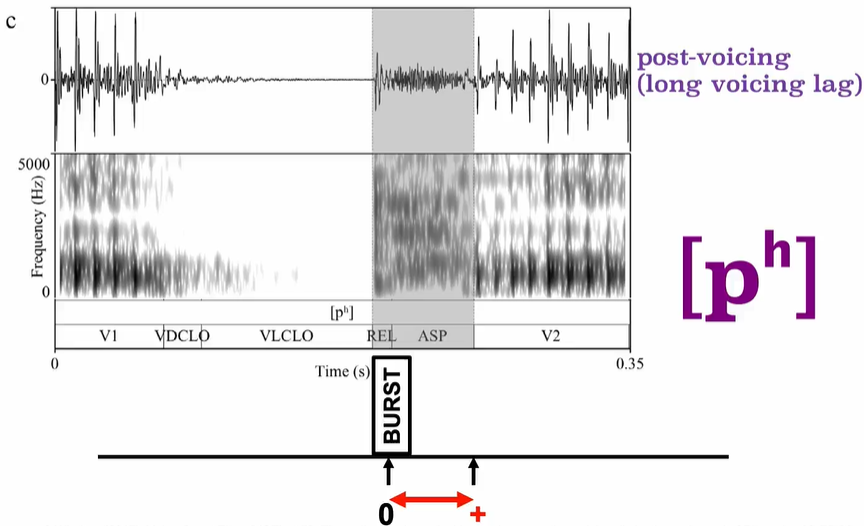
Voice onset time (VOT) is a feature of the production of stop consonants. It is defined as the length of time that passes between the release of a stop consonant and the onset of voicing, the vibration of the vocal folds, or, according to other authors, periodicity. 指某一辅音从除阻的一刻到声带开始震动,中间所经过的时间
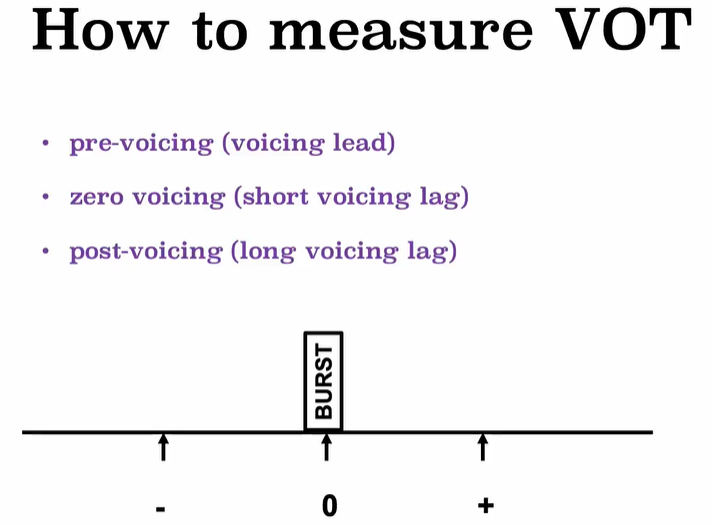


- 【-】浊塞音Voiced stops的出奇之处在于其VOT值小于0,负VOT值意味着,声带在阻碍消除之前就开始了震动。术语完全浊塞音是指声带恰好在阻塞刚刚形成的一刹那开始震动,而不完全浊塞音则是指在阻塞保持阶段中的某一时刻声带开始震动。
- 【0】单纯的不送气的无声(非响音的)塞音unaspirated voiceless stops,有时也称作无声爆破音"tenuis" stops——中文习称为全清音。其VOT等于或近似零,也就是说几乎在阻碍消除(除阻)的同时,后接的响音(比如元音)即开始发音。(好比塞音[t],如果其消退时间为15毫秒,或者如塞音[k],30毫秒,则认为它们是无声爆破音)
- 【+】后接响音的送气塞音Aspirated stops followed by a sonorant,其VOT比全清音要长,称作爆破VOT。爆破VOT的长度是衡量送气程度的实用指标:VOT越长,送气就越强。比如,在强送气的纳瓦霍语中,送气的持续时间是英语的两倍:[kʰ]的VOT值两者分别为160毫秒和80毫秒,而英语不送气[k]的VOT却只有45毫秒。另一些语言中也有比英语更弱的送气音。概括来说,以软颚塞为例,不送气[k]的典型VOT在20至30毫秒间,弱送气的的参考值为50至60毫秒,中等送气[kʰ]平均约为80至90毫秒,而拥有超过100毫秒甚至更长VOT的音则视作强送气音。呼吸音,通常也称作送气浊音,为了将VOT用作分析浊送气音的指标,须将VOT中的O——Onset:起始——理解为开始发呼吸浊音[ɦ]的一刹那。当然,送气辅音不一定都有后续的响音,但VOT是以响音的起始来定义的,就是说在这种情况下送气强度不能用VOT来衡量。
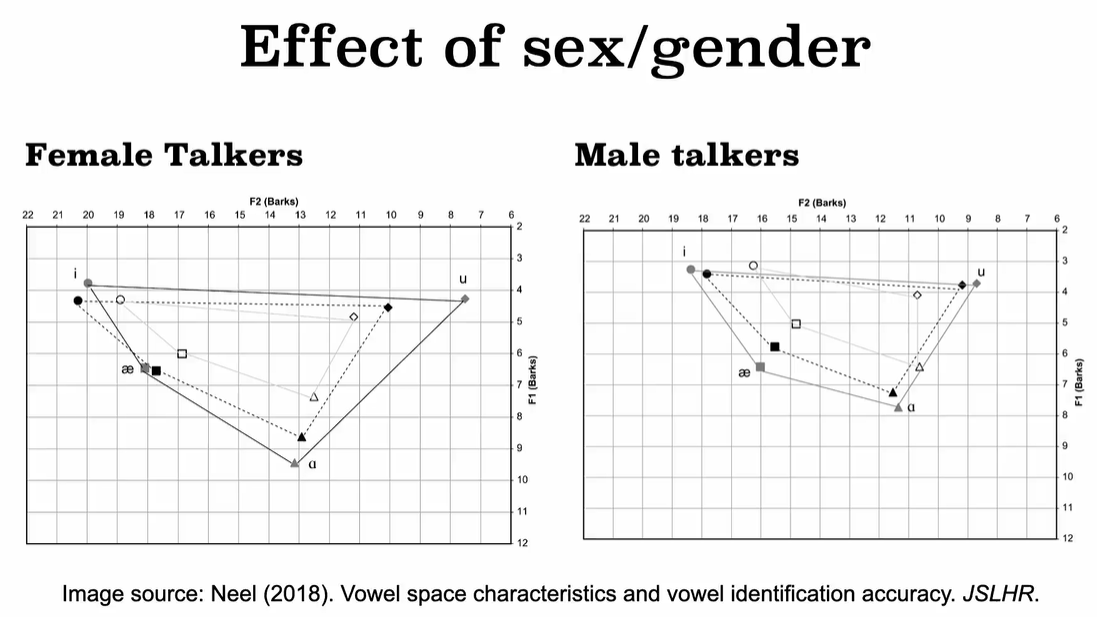
5. Vowel space 元音空间
Definition:: Variability in the acoustic vowel space as well as the relationship of it to inventories of contrastive vowel sounds in languages.

Module 3 – Digital Speech Signals
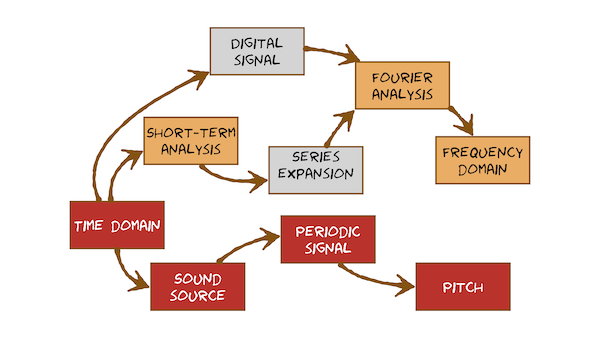
- Time domain 时域: 横轴是时间,纵轴是信号的变化(振幅amplitude (measured pressure relative to atmospheric pressure) over time)

- 频域(Frequency domain):分析信号包含的频率成分。各频率分量的频率和功率参数。在频域中,复数信号(即,由一个以上频率组成的信号)被分离成它们的频率分量,并显示每个频率的电平。示波器(oscilloscope)用来看时域内容。
- Sound source 声源:two principal sources of sound in speech, voice and frication. 【the air flow is slow, its only the power source of sound, the pressure change with our vocal folds is the key generating sounds, repeat pulse of sound.】

- 确知信号(deterministic signal):指其取值在任何时间都是确定和可预知的信号。
- Periodic signal 周期性信号:瞬时幅值随时间重复变化的信号。重复的最小信号时长的倒数可以计算出信号频率。
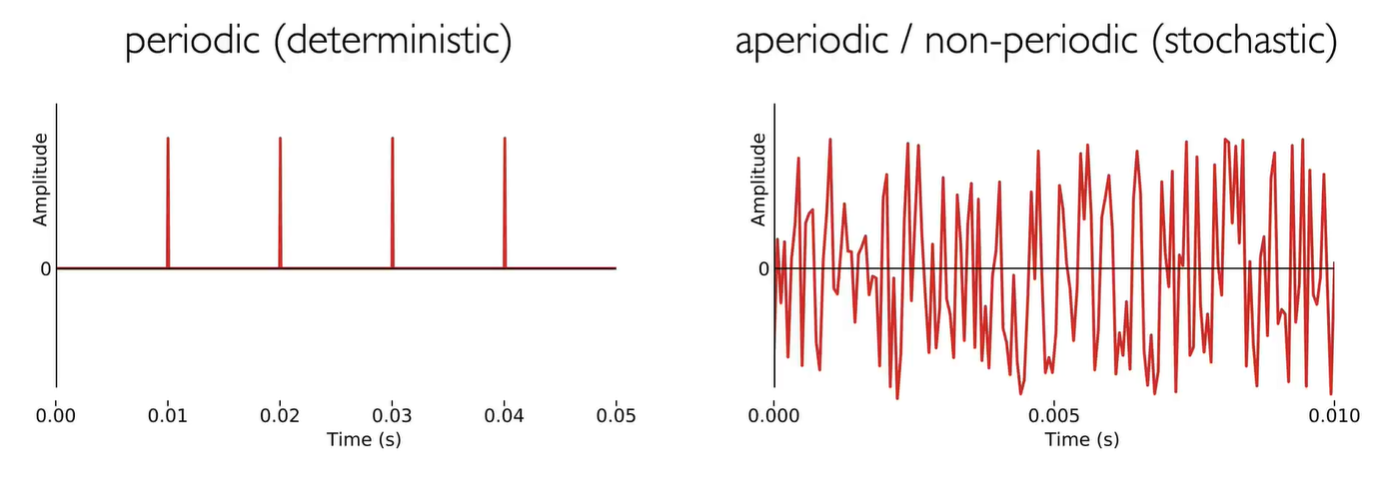
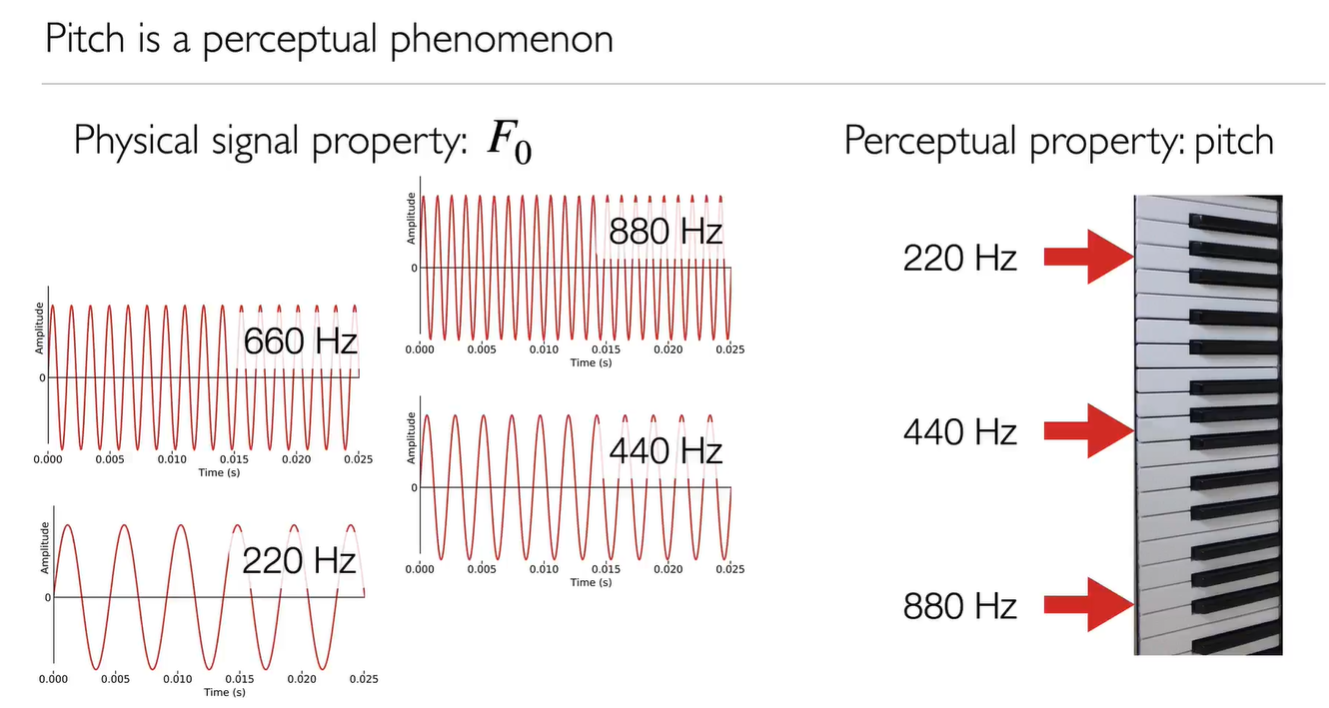
- Pitch音高: 周期性信号(Periodic signal)被认为具有音高(pitch)。基频(fundamental frequency) F0 的物理特性与音高的感知量有关。a musical note, logarithmic none linear, with a base 2
F0 是一种物理特性:它是声带的振动频率。我们可以直接从声带测量,或者从信号估计。F0 estimation algorithm是a non-trivial estimation F0不能精确计算出来。音高只是感知现象(perceptual phenomenon), 说话者还要考虑韵律prosody.
即:把国际标准音 440 Hz 的 midi number 定为 69,然后每升高(或降低)一个八度(octave),midi number 增(或减)12。由此可见 midi number 的单位为半音(semitone)。把一个八度 12 等分,每一份称为一个半音(semitone)。把一个半音再 100 等分,每一份称为一个音分(cent)。
- 基频提取(pitch estimation, pitch tracking)在声音处理中有广泛的应用。它最直接的应用,是用来识别音乐的旋律。它也可以用于语音处理,比如辅助带声调语言(如汉语)的语音识别,以及识别语音中的情感。
由于声音的基频往往随时间而变化,所以基频提取通常会先把信号分帧(帧长通常为几十毫秒),再逐帧提取基频。提取一帧声音基频的方法,大致可以分为时域法和频域法。时域法以声音的波形为输入,其基本原理是寻找波形的最小正周期。当然,实际信号的周期性只能是近似的。频域法则会先对信号做傅里叶变换,得到频谱(仅取幅度谱magnitude spectrum,舍弃相位谱phase spectrum)。频谱上在基频的整数倍处会有尖峰,频域法的基本原理就是要求出这些尖峰频率的最大公约数。

考虑到基频并不是每一帧都会有,在提取基频之前、之后或同时,往往要判断一下基频的有无,这称为清浊音判别(unvoiced / voiced decision,简称 U/V decision)。逐帧提取的基频常常含有错误,其中最常见的错误是「倍频错误」和「半频错误」,即提取出的基频是真实基频的两倍或者一半。为了纠正这些错误,通常会再对结果进行平滑(smoothing)处理,得到光滑的基音轨迹(pitch contour)。
基频提取长期以来都是用纯信号处理的方法进行的,属于基于规则(rule-based)的方法。这是由于基频的概念在信号层面上就比较清晰,不像语音识别中的「音素」等概念那样抽象。不过,用纯信号处理方法,很难同时降低「倍频错误」和「半频错误」的发生率:在算法中努力降低一者,往往会造成另一者升高,呈现「按下葫芦起来瓢」的态势。因此,最近几年出现了一些使用机器学习方法提取基频的研究,它们通过数据驱动(data-driven)的方式,超越了纯信号处理方法的性能。
音高感知理论的部位学说中,经过严谨的实验得出了一个结论:去除基频成分后,脉冲波的音高依然保持不变,由此可以证明以下两点:
(1)感知音高时基频不是必须存在的;
(2)最低的频率成分不是感知音高的基本依据, 当脉冲波的基频缺失时,二次谐波是最低频率成分,音高并不会因此提升一个倍频程,这个实验被称为“缺失基频现象”。 部位学说与人耳基底膜的频率分析特性有着直接关系,输入人耳声音信号的不同频率分量刺激基底膜的不同部位,毛细胞在基底膜的每个位置进行神经放电,刺激与输入声源的频率成分相对应的神经细胞和大脑高级中枢。基于这一理论,部位学说提出,人耳所感知的声音音高接近不同频率分量的最大公因数,利用这个方式还可以为以下声音找到合适的音频:
(1)缺失基频成分的声音;
(2)只有奇次谐波的声音;
(3)缺少基频成分且只有奇次谐波的声音。
以上三种情况下的最大公因数都是基频。 根据部位学说的这一理论,我们在生成单音时,基频和谐波与谐波和谐波之间的差值应尽量靠近目标乐器单音音高对应的频率,尽量符合原始乐器的发音特性。
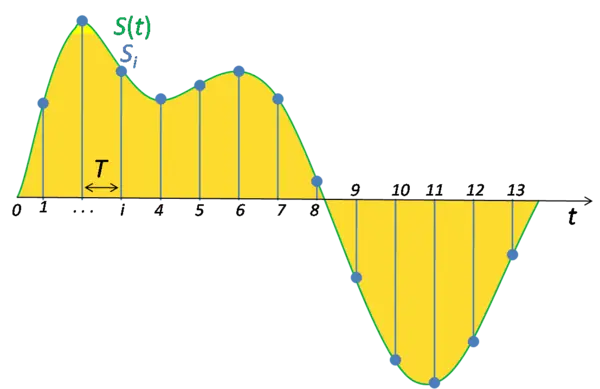
1. Analogue to digital conversion 模拟信号(连续)到数字信号(离散)
- Digital signal 数字信号

- Sampling 采样:
The sampling rate 采样率 (samples/second = Hz), aka sampling frequency, determines how often we record a value from wave
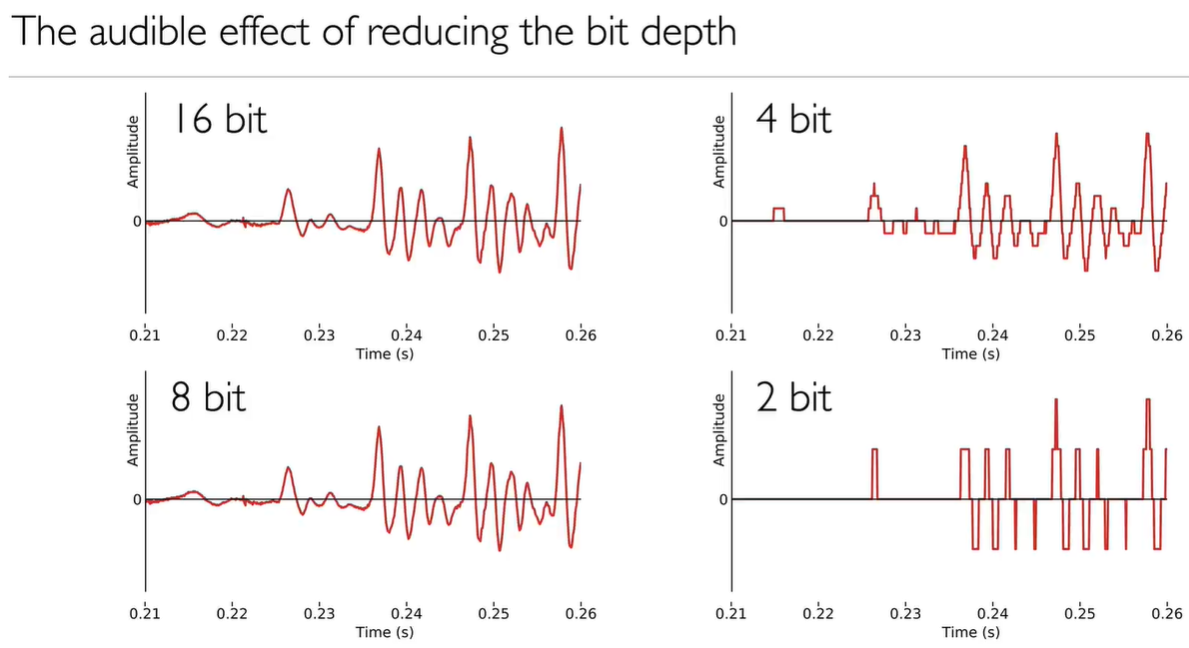
Sampling period = 1/sampling rate (seconds) - quantization (or bit depth 位深度, the digitized amplitude):Quantisation is the process of storing the amplitude of each sample with a fixed precision (generally, that means as a binary number with a fixed number of bits)
类比声音的「分辨率」:一个声音信号的质量由两个变量决定:采样率 Sample rate 和 比特深度(位深度)Bit depth。图像分辨率由横纵坐标的像素数量所决定。对应到声音,Sample rate 设定了能够捕捉音频信号的最高频率,可以看做横坐标;Bit depth 决定了每一个 sample 的精度,可以看做纵坐标。两者在两个维度上共同决定了音频的分辨率。


- 混叠 (Aliasing):混叠是指取样信号被还原成连续信号时产生彼此交叠而失真的现象。当混叠发生时,原始信号无法从取样信号还原。而混叠可能发生在时域上,称做时间混叠,或是发生在频域上,被称作空间混叠。
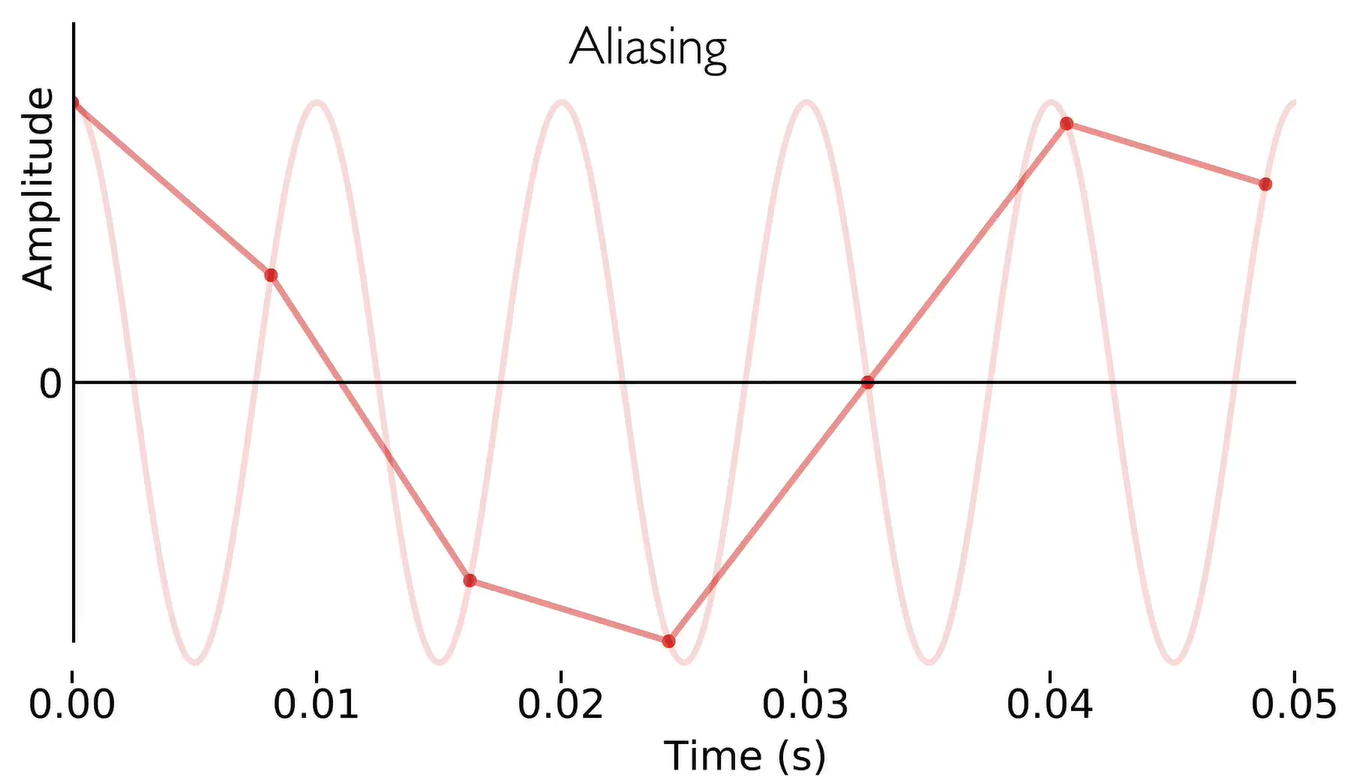
2. 音频的「分辨率」Sample rate, Bit depth, Bit rate, Dynamic range
2.1 采样率 Sample rate
采样率决定了每一秒内会从音频信号中采集多少样本。在现实世界中的音频采样,是不连续或离散的信号,每个梯级值都是一个数值,表示一个单一时间点上的幅度。
多少采样点算是足够多,能够精确编码一个声音信号呢?这就要提到 The Nyquist Theorem (尼奎斯特定理)了:
States that the signal’s sample rate must be at least two times greater than the highest desired frequency.
采样率/2是一个特殊数字,被称为奈奎斯特点 Nyquist point,它是在任何声音中能够被一个给定采样率所编码的最高频率。 也就是说,每秒的采样至少是信号中的最高频率的 2 倍,就可以完美地还原声音信号。
所以,为了覆盖人类的听觉范围(20Hz~20kHz),每秒需要 40000 个采样点。
既然 40 kHz 就够了,为什么现在音频 CD 的标准采样率是 44.1 kHz 呢?
- 一方面原因是工程的需要。现实中,麦克风所能接收、采集到的空气振动的频率范围非常大,远远超过人耳听力。如果直接采样会出现混叠 Aliasing。所以要先使用一个低通滤波器,把高于阈值的信号过滤掉。超过 40 kHz 的频段,给低通滤波器留出空间,使得那一段不怎么完美的下降曲线落在 20KHz 之外,不影响音频效果。
- 另一方面是技术历史问题。在数字存储媒介被发明之前,早期的数字音频录制在模拟录像带上。当时世界上的录像机主要有二大制式:欧洲的 PAL 和美国日本的 NTSC。当时的 CD 是 SONY(美日制式)与 PHILIPS(欧洲制式)合作的。适用于 PAL 制式录像机的编码器采样频率是 44.1kHz。适用于 NTSC 制式录像机的编码器采样频率是 44.056。
2.2 比特深度 Bit Depth
在 CD 的采样标准中,44.1 kHz 的 Sample Rate 我们有所了解了。那么 16 Bit Depth 又是什么意思呢?
在音频采样中,每个采样的 amplitude 用二进制数字编码。这个编码的分辨率就是比特深度。
把数据存储成二进制,意味着如果用 n 个二进制位来存储每个幅度值,总共可以表示的数值数量为 2 的 n 次方-1。1 bit 代表采样的值: 0 或 1。如果是 2 bit,采样值范围就是 0, 1, 2, 3。2 的 16 次方是 65536,所以 16 bit 的采样深度分辨率是 -32768~32768。

Bit depth 实际上决定的是 dynamic range 的分辨率。
2.3 动态范围 Dynamic Range
声音的 dynamic range 由信号的最大值和最小值所决定。在音频处理中,dynamic range 与最大振幅和 noise floor 的比值有关:

假设 1 bit 表示听觉的门限,16 位 bit depth 可以给出 98 dB 的 dynamic range,32 位为 192 dB,64 位为 385 dB。现在很多数字音频系统都用 64 位。
2.4 比特率 Bit Rate
在数字多媒体领域,比特率是单位时间播放连续的媒体(如压缩后的音频或视频)的比特数量,常用码流或码率表示,单位是kbps(千位每秒)。
高音质 MP3 的 Bit rate 可达 256-320 kbps ,低音质的 MP3 大概在 100 kbps 。
音频数据的比特率文件大小计算公式如下:
Bit rate = sample rate * bit depth * channels
Size in bits = sample rate * bit depth * channels * length of time
所以,Sample rate 和 Bit depth 会影响 Bit rate 和文件大小。
一般原始的多媒体文件都比较大,为了便于使用需要对其进行压缩,而码流就对应了压缩时的取样率。单位时间内取样率越大,精度就越高,处理出来的文件就越接近原始文件,但是文件也会越大。
- Sample rate:每秒采集的音频信号样本。
- Bit depth:每个信号样本的幅度范围分辨率。
- Dynamic range:信号的范围极限值区间
- Bit rate:单位时间传送的媒体信号量
3. Short-term analysis 短时分析
由于语音会随着时间的推移而变化,因此我们只需要分析信号的短时区域。我们将语音信号转换为帧序列(sequence of frames)。
为了定义一帧波形,我们需要使用窗函数(window function),对波形进行剪切。不同的窗口函数会产生不同的结果。如果我们简单地使用 0/1 窗口函数来分析这个信号,我们不仅要分析语音,还要分析那些伪音artefacts。因此,我们可以使用锥形窗口(tapered windows),用一个向边缘逐渐变细的窗口函数将其剪切出来。将其视为淡入(fade-in)和淡出(fade-out)。

4. Series expansion and Fourier analysis 级数展开,傅立叶分析
在时域(time domain)中很难直接分析语音。因此,我们需要使用傅里叶分析法(Fourier analysis)将其转换到频域(frequency domain),这是序列展开(series expansion)的一种特殊情况。
为了重建原始的模拟声音(analogue sounds),我们可以将无限多的项相加,以得到精确的原始信号original signal:

然而,信息量是有限的(因为是digital signal),我们只需要有限数量的基函数就能精确地重建信息。另一种说法是,这些基函数也是数字信号digital signal,可能的最高频率是奈奎斯特频率,也就是采样率的一半。
我们要做的就是简单地计算每个可能频率的系数,然后将它们相加来重建原始信号。
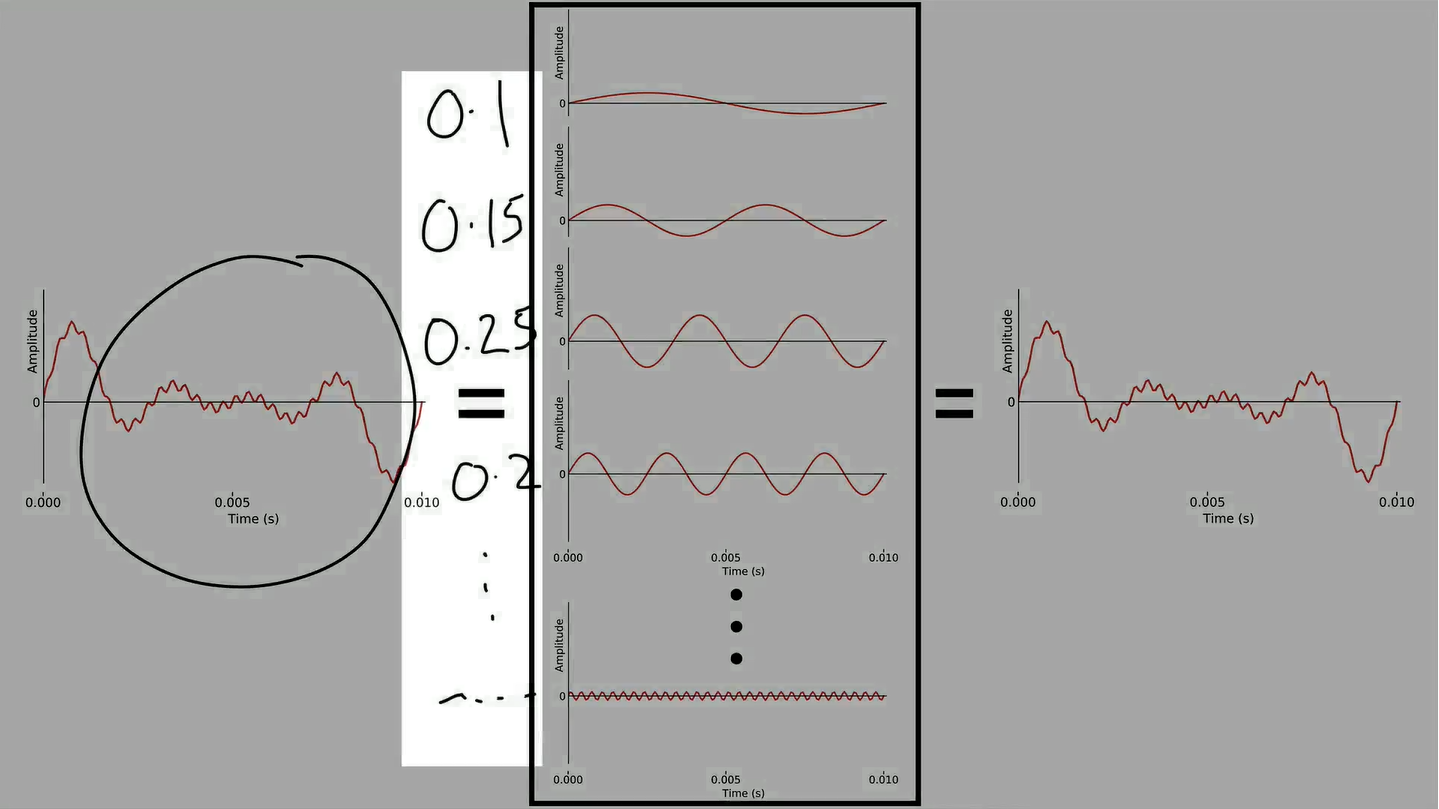
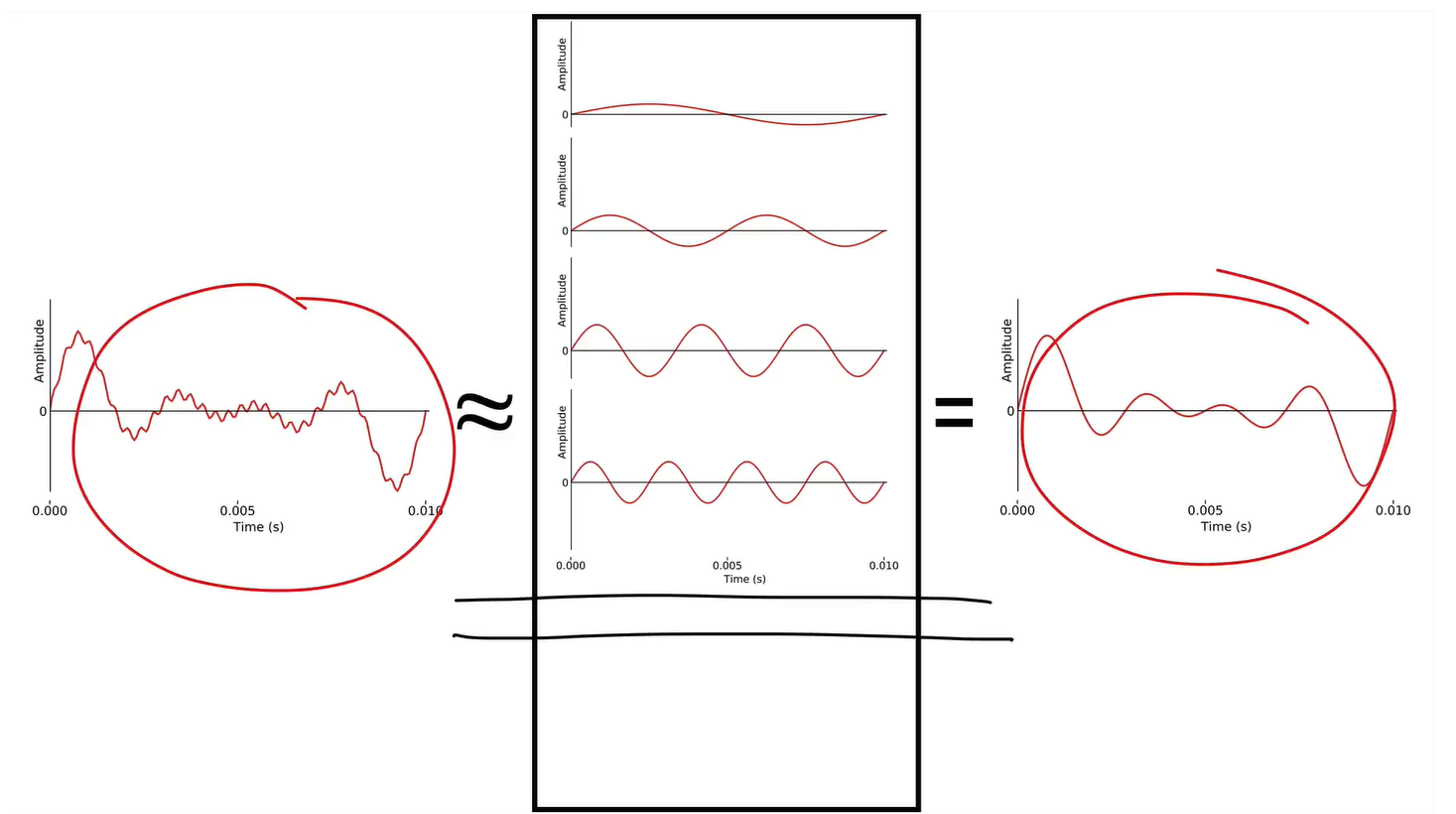
One application of this is removing noise or not useful information by stop adding terms, and we get a smoother curve. 去除一些噪声项
- Fourier analysis 傅里叶分析:从时域到频域
We can express any signal as a sum of sine waves that form a series. This takes us from the time domain to the frequency domain.
Spectrum频谱 is magnitude (dB) over frequency(kHz).
The basis functions(Periodic function 周期函数) are orthogonal, which means coefficients related are unique. 傅里叶分析可以找到这些系数。
Periodic function 周期函数 定义:
For function f which takes a time t as input, the output obeys:
f(t) = f(t + nT)
for some constant T (the period), for all times t and integers n
周期函数可以写成不同频率的简单周期函数(即正弦和余弦)的离散和 a discrete sum of simple periodic (sinusoidal) functions (i.e. sine and cosine) of different frequencies
体验傅里叶:Web Application Starter Project
5. Fourier Transform 傅立叶变换
根据原信号的不同类型,我们可以把傅立叶变换分为四种类别:
- 非周期性连续信号(傅立叶变换(Fourier Transform,FT))
- 周期性连续信号(傅立叶级数(Fourier Series,FS))
- 非周期性离散信号(离散时域傅立叶变换(Discrete Time Fourier Transform,DTFT))
- 周期性离散信号(离散傅立叶变换(Discrete Fourier Transform,DFT))
- DFS(Discrete Fourier Series):DFS变换后是周期离散信号,但是DFT只取DFS变换后的一个周期。另外,DFT也可以从DTFT抽样过来,DTFT作为连续信号,均匀采样N个点,就变成DFT了。
- 快速傅立叶变换(Fast Fourier Transform,FFT)是一种高效实现 DFT 的算法
- IFFT 逆快速傅立叶变换
- 短时傅里叶变换STFT:将语音信号分割成小的时间段,然后对每个时间段应用 FFT
- ISTFT 逆短時傅立葉轉換,將時頻表示恢復為原始語音訊號
- COLA(常數重疊相加,Constant Overlap-Add):C指的是常數,是在ISTFT之後產生的條件


对于计算机来说只有离散的和有限长度的数据才能被处理。所以首先可以肯定的是,对于计算机中的研究,我们的时域信号需要是离散的。对于我们要处理的输入信号,考虑如果是非周期性信号的普遍情况。我们需要用无穷多不同频率的正弦曲线来表示,这对于计算机来说也是不可能实现的。所以频率域上也要是离散的。所以基于上面的分析,我们下面重点讨论和理解的是离散傅立叶变换(DFT),因为只有它才能被计算机适用。
- Discrete Fourier Transform (DFT) 离散傅里叶变换
for input x[n] with n=0,...,N-1 (N inputs), For k=0,..,N-1 (N analysis frequencies),


https://speech.zone/wp-content/uploads/2023/10/03_Speech_Processing_lecture_digital_signals.pdf
6. Frequency domain 频域
- phase 相位:周期中波形开始的点 simply the point in the cycle where the waveform starts.
如果两者的频率相同,则它们相位的关系不会改变且都会在示波器中呈现稳定的状态。
在时域中,两个信号可能看起来非常不同,但在magnitude spectrum振幅频谱中(频域),它们是相同的。
我们在重建波形时忽略了相位信息。波的起点并不重要,因为基函数会在稍后的某个时间同步。
分析帧越大,基函数就越多。【如果我们有一个更长的分析窗口,这意味着恰好一个周期适合它的最低频率正弦波将处于较低频率,因此该频率会较低。我们知道该序列在该频率下间隔相等,因此它们都会变低并且间隔更紧密。但我们也知道最高频率始终处于奈奎斯特频率Nyquist frequency。
因此,如果最低频率基函数的频率较低,并且它们的间隔更近,那么我们将有更多的基函数适合高达奈奎斯特频率Nyquist frequency的范围。】

Module 4 – the Source-Filter Model

- Harmonics 谐波:正余弦函数的周期波,是基频倍数
在频域中,周期信号具有谐波Harmonic结构:它们只包含基频倍数的能量。
voiced sound与unvoiced sound不同,在周期性上具有重复模式。因此,声音在频域中的峰值很容易观察到。
- Impulse train 脉冲序列函数:the simplest periodic signal that has energy at all multiples of its fundamental frequency (and energy are evenly distributed). 最简单的周期性信号,在其基频的所有倍数上都有能量(并且能量均匀分布)
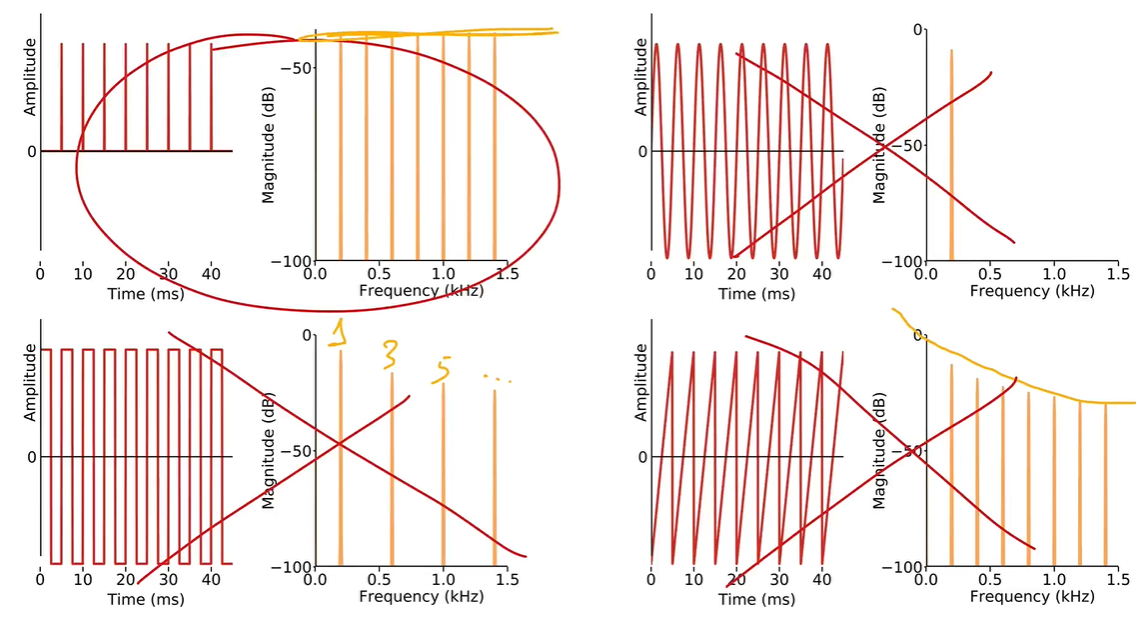
- Spectral envelope 频谱包络:频域曲线下的区域。
改变频谱包络线的形状是说话人向听话人传递语言信息的主要手段。
- Resonant tube 谐振管:波长是管长两倍,根据音速可以算出时间,计算出频率1/T赫兹
- Vocal tract resonance & formants 声道共振和共振频率
说话者可以通过改变声带形状来改变共振频率,从而改变语音的频谱包络。 - Formant frequencies 共振频率: 由于声道的过滤作用,声能集中在其周围的频率,在频谱中表现为突出的峰值。(声带共振)。峰值称为共振峰 formant,是声道的属性,F1 是第一共振峰,F2 是第二共振峰。
- Filter 滤波器:
不看声道物理模型,我们来看看滤波器模型 a filter operating on signals。滤波器是从输入域 X 到输出域 Y 的映射,就像数学中的函数
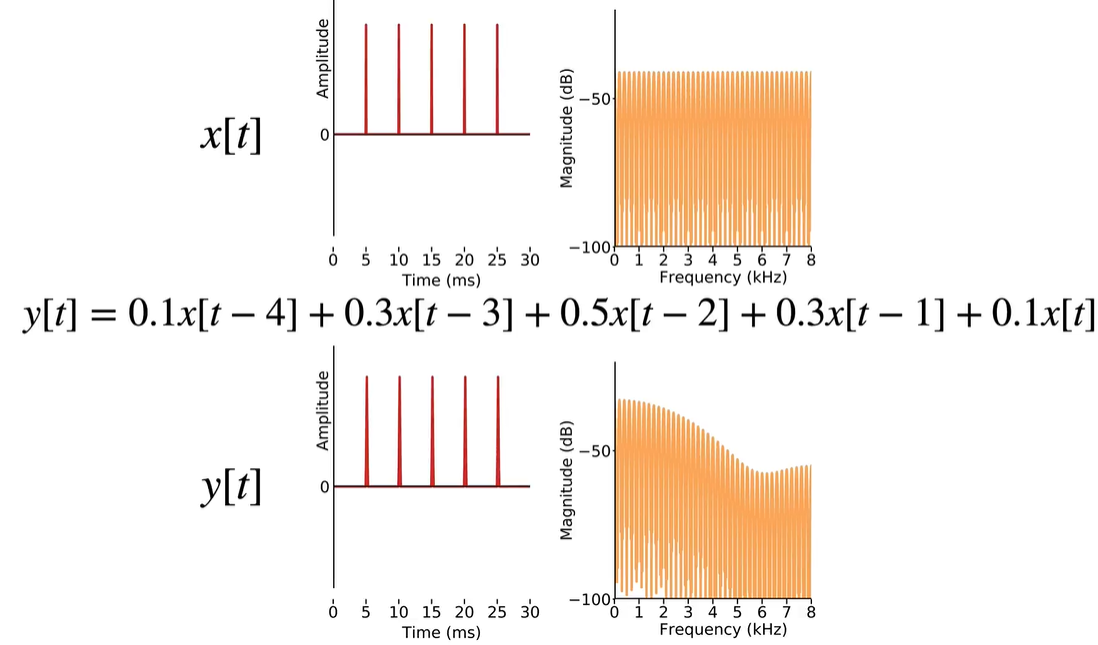
Desired action: shape the spectrum in a specific way
Some common filters:
● Low pass filter: remove all frequencies above a specific frequency
● High pass filter: remove all frequencies below a specific frequency
● Band pass filter: remove all frequencies outside two specified frequencies
two types of filters you can apply directly to the waveform:
● Finite Impulse Response (FIR) filters:takes the original signal as input and transforms it based on the previous values of the input

● Infinite Impulse Response (IIR) filters:
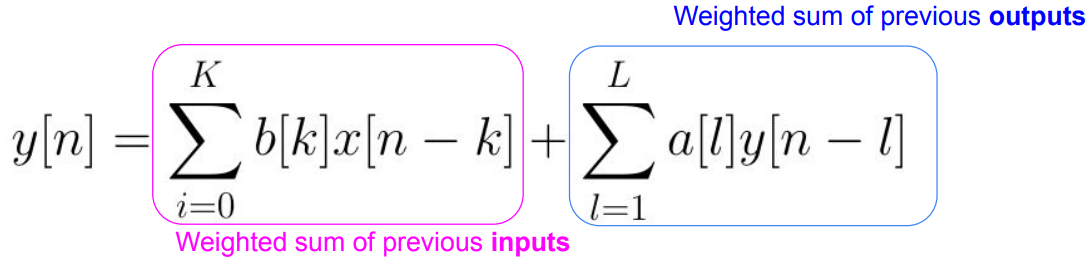
Can specify low pass filters with less coefficients than FIR filters ● Are better at modelling types of resonances we see in speech ● It’s NOT obvious what an IIR filter does from just looking at the coefficients
- Impulse response 冲激响应:一般是指系统在输入为单位脉冲函数时的输出,是暂态响应中的一种。
How the filter response to the impulse
在下图中,我们将分析框架缩小到只有一小段的波形,左边是滤波器的脉冲响应(impulse response),右边是滤波器的频率响应(frequency response)。The frequency response is the Fourier transform of the impulse response.
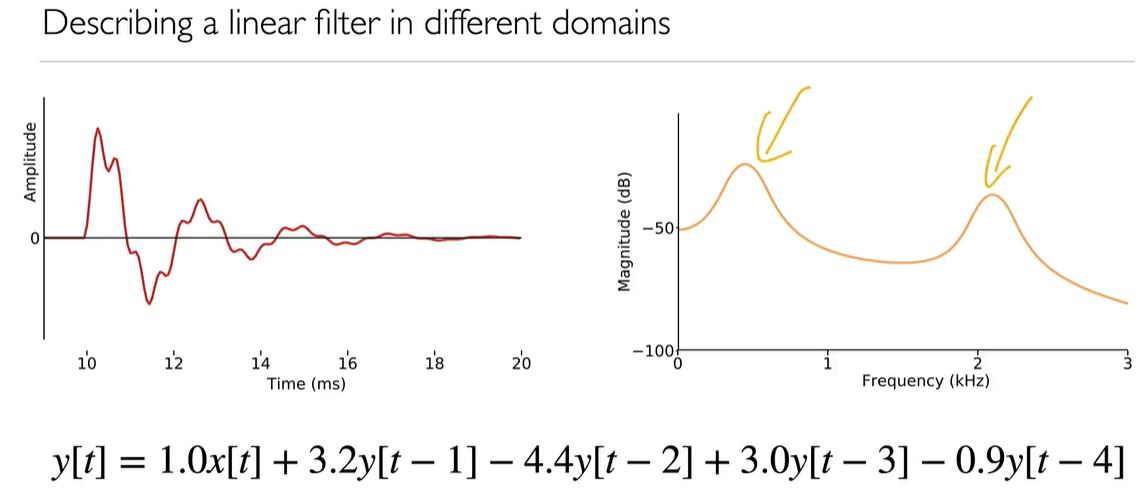
- Source-filter model 源-滤波器模型

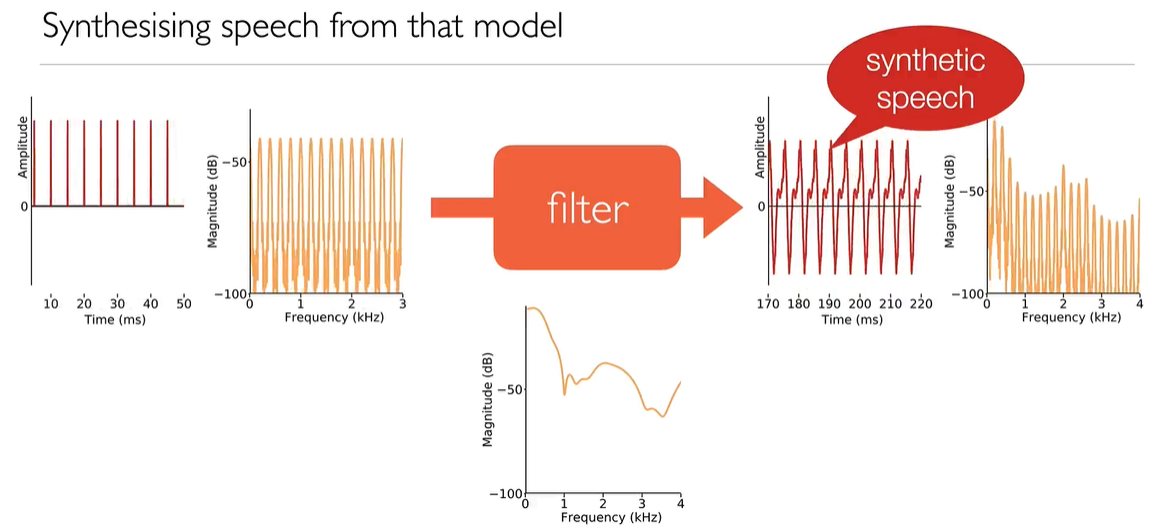
滤波器的线性性质告诉我们,输出只是一系列重叠和相加的脉冲响应Impulse response。
获取时域信号并使用它来激发脉冲响应,然后将它们重叠并添加到输出中的整个过程称为“卷积”convolution。

● Source= impulse train: frequency of impulses determines F0
● Filter=Infinite Impulse Response filter: a weighted sum of previous inputs and outputs
- Phoneme 音素:改变源-滤波器的函数去调整F1和F2来合成各种音素。
源滤波器模型有两种可能的源:周期性源和非周期性源。可以组合两个源从[s]到[z]不同的摩擦音
Module 5 – speech synthesis – phonemes and the front end
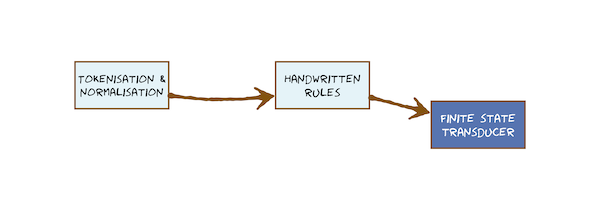
- Tokenisation & normalisation


- Handwritten rules
- Finite state transducer 有限状态传感器
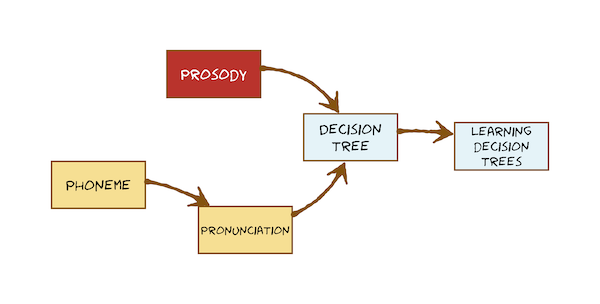
- Phonemes and allophones 音素和音位变体


- Pronunciation
- Prosody 韵律:predicting pausing, duration, and F0.

- Decision tree
Module 6 – Speech Synthesis – waveform generation and connected speech
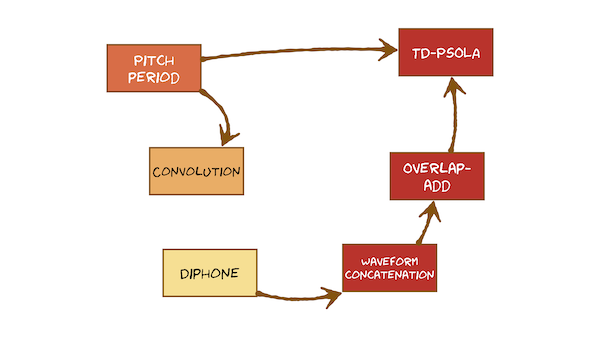
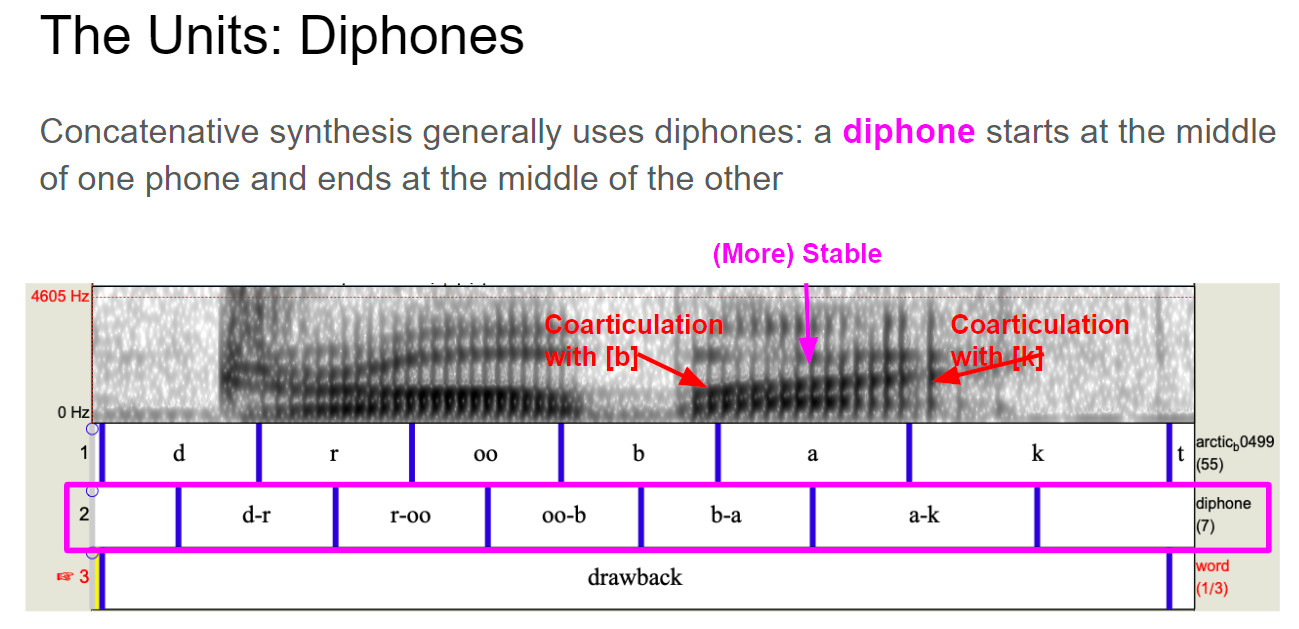
Diphone
- Diphone 双音子:starts at the middle of one phone and ends at the middle of the other. 持续时间与phone大致相同,但其边界位于phone的中心。双音子是共同发音的单位。
音素(Phones) 并不是波形串联(waveform concatenation)的合适单位,因此我们使用了捕捉共同发音(co-articulation)的双音(diphones)。
共发音Co-articulation: 是指相邻发音的重叠或目标音素对周围音素的影响。由于共发音的存在,中间音素Middles of phones的频谱特性spectral properties比边缘音素更稳定。因此,将双元音连接起来应该会使连接更加平滑 concatenating diphones should lead to smoother joins
- 自然度,共振特性formant:不同的音素在发音时涉及到声道的共振特性变化。这包括嘴唇、舌头和声门等器官的位置和形状的变化。这些共振特性的变化在音素过渡时(比如F1和F2的变化)会导致声音的平滑转变,而不是突然的跳跃。通过使用diphone,可以更好地建模这些共振特性的变化
- 上下文依赖性: Diphone考虑了音素在特定上下文中的发音方式。在实际语音中,同一个音素在不同的上下文中可能会有不同的发音。

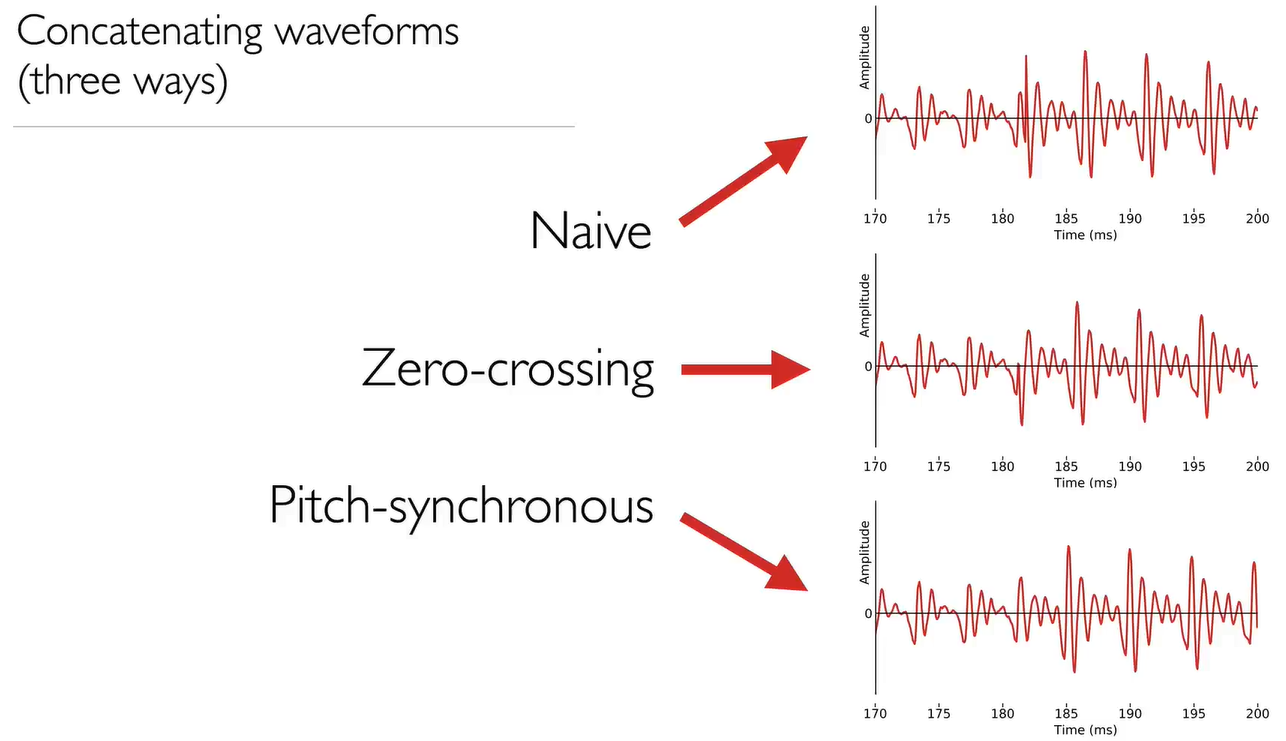
- Waveform concatenation 波形串联
波形串联是制作合成语音的一种简单方法,但我们需要注意操作方法:
直接串联的话,discontinuity cause pops 不连续性会导致爆音:at a zero crossing 有相同幅度
periodicity alignment cause glitches 周期性对齐导致突波:pitch-synchronous joins

find the fundamental periods

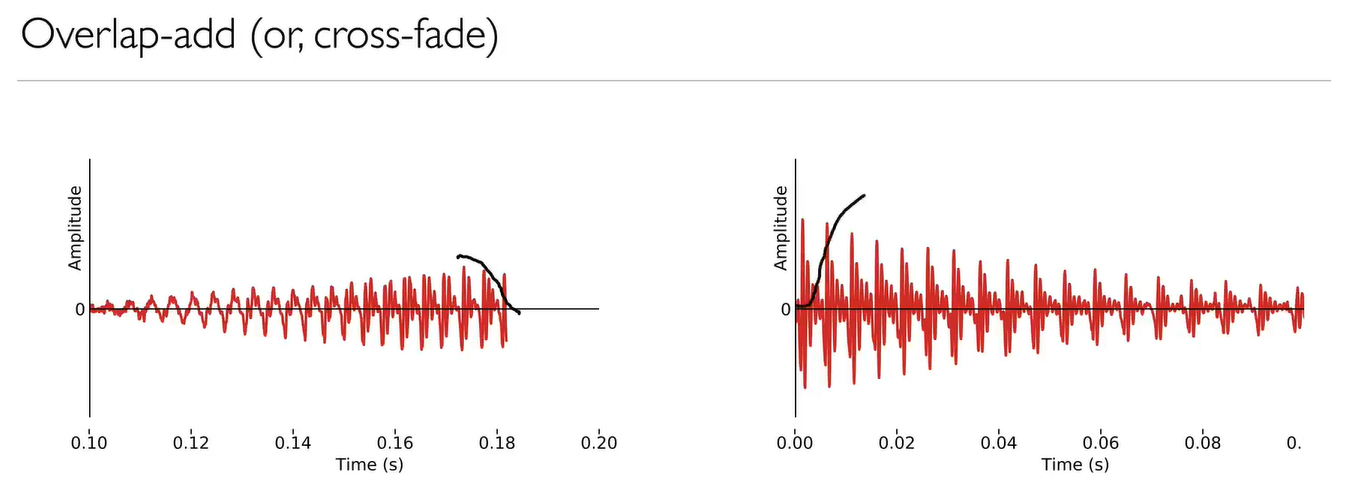
- Overlap-add 重叠加法
两个波形之间的交叉渐变(Cross-fading) 是避免串联波形的一些痕迹the artefacts of concatenation的有效方法。(没用 fundamental periods基本周期)
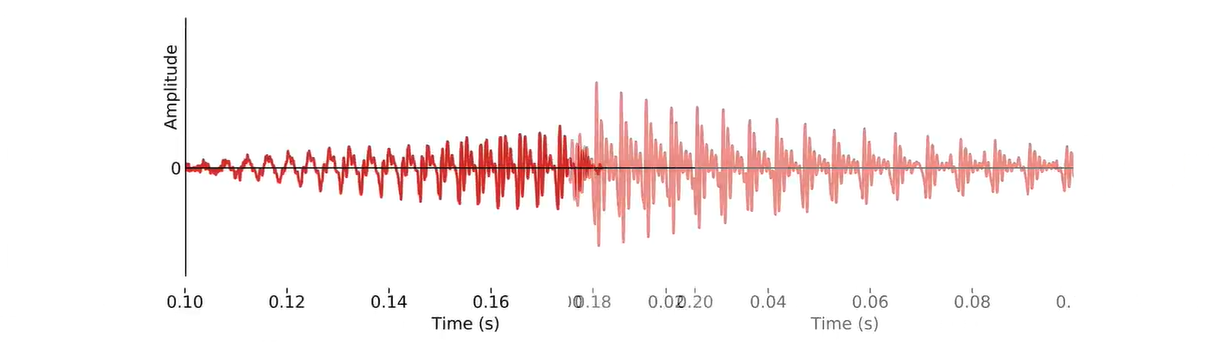
- Pitch period 音高周期
语音波形的这一基本构件为时域中的源滤波器分离提供了一条途径。

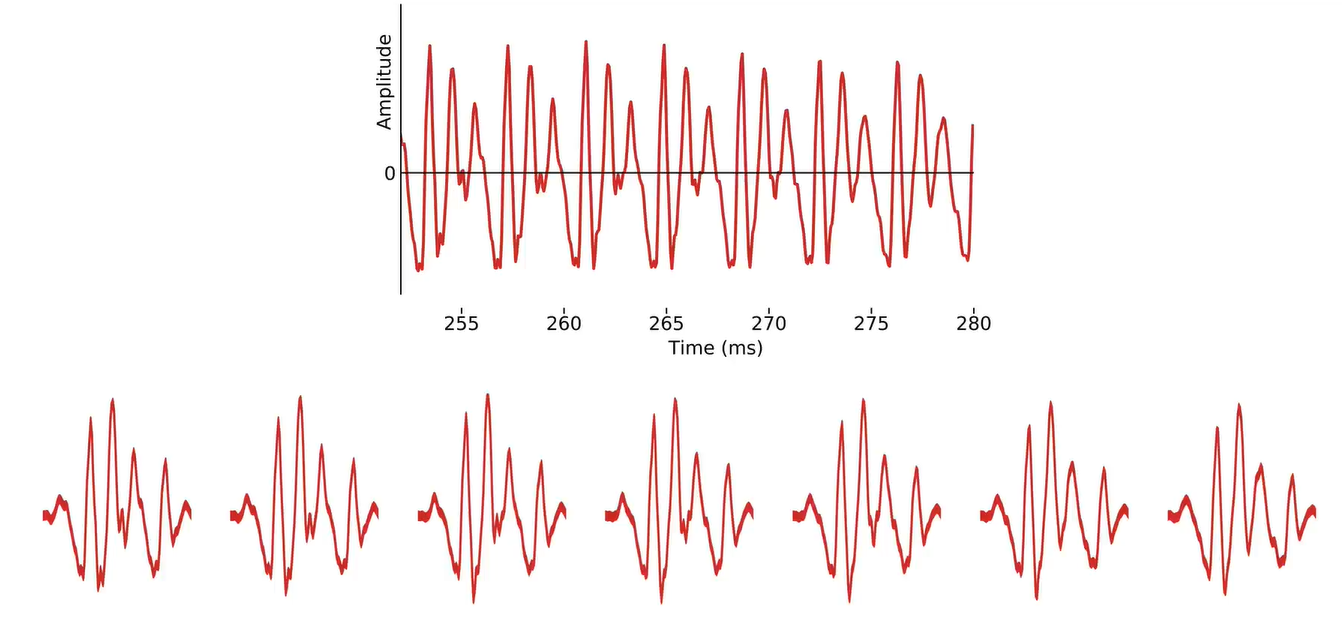
并将每个音高周期block的时间设为 T0 的两倍
twice the fundamental period /
two pitch periods

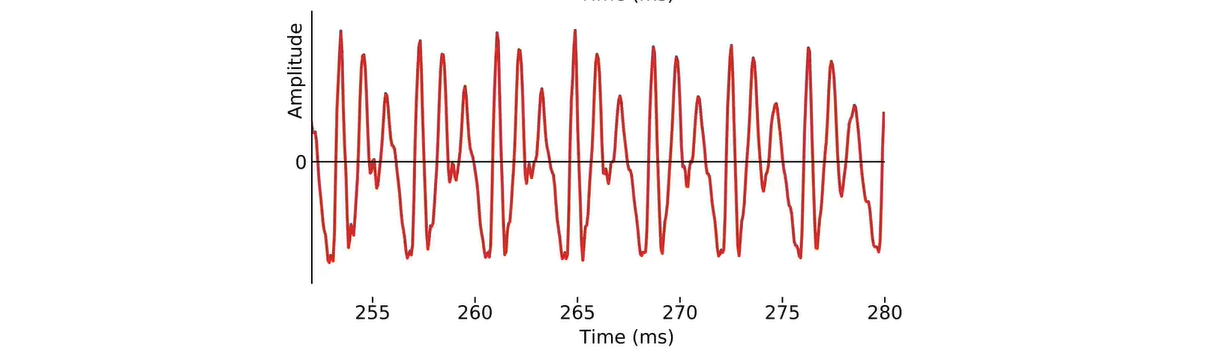
我们刚刚看到了一种新的信号处理方式,即音高同步 pitch-synchronous。
它与我们之前看到的短期分析short-term analysis本质上是一样的,只不过我们将分析帧与信号的基本周期fundamental periods对齐,并根据基本周期改变分析帧的持续时间。
因为在自然语音信号中,声道的脉冲响应impulse responses通常是重叠的。这使得我们无法提取单一的脉冲响应。而通过Pitch period提取重叠的帧,并应用锥形窗口,这样只需使用重叠添加法就能重建信号。这种将语音信号表示为音高周期序列的方法是 TD-PSOLA 方法的核心,它可以在时域中直接使用波形修改语音信号的 F0 和持续时间。
我们还将能够理解音源和滤波器在时域中的相互作用,这是一个被称为卷积convolution的过程。
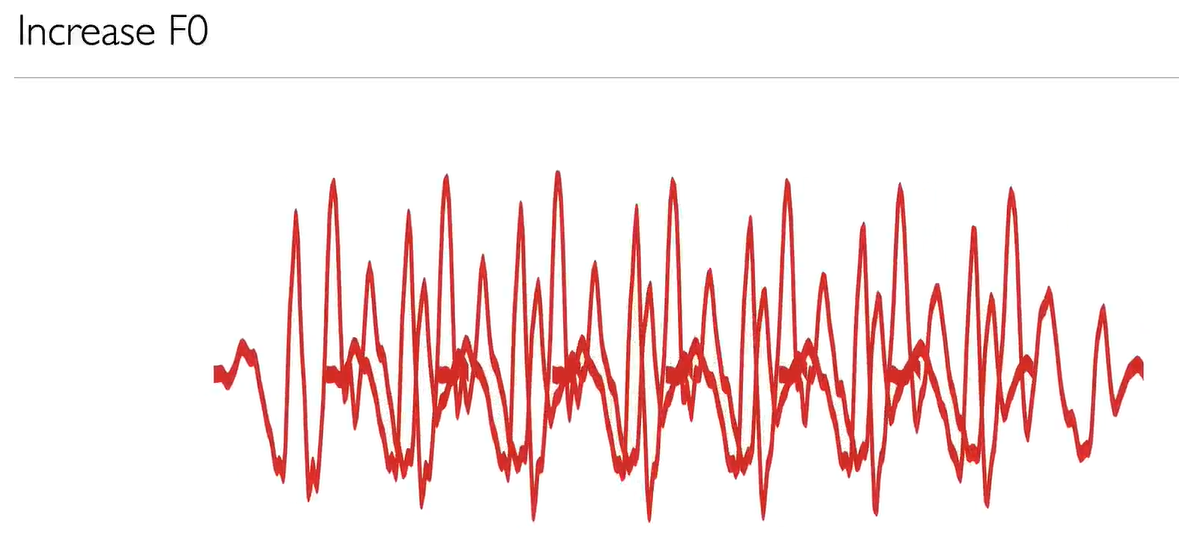
TD-PSOLA
- TD-PSOLA:Time-domain pitch-synchronous overlap-and-add
对音高周期波形pitch period waveforms应用重叠加法overlap-add技术,可以在不改变音素特性(phone identity)的情况下修改 F0 和持续时间。
时域音高同步重叠加法TD-PSOLA
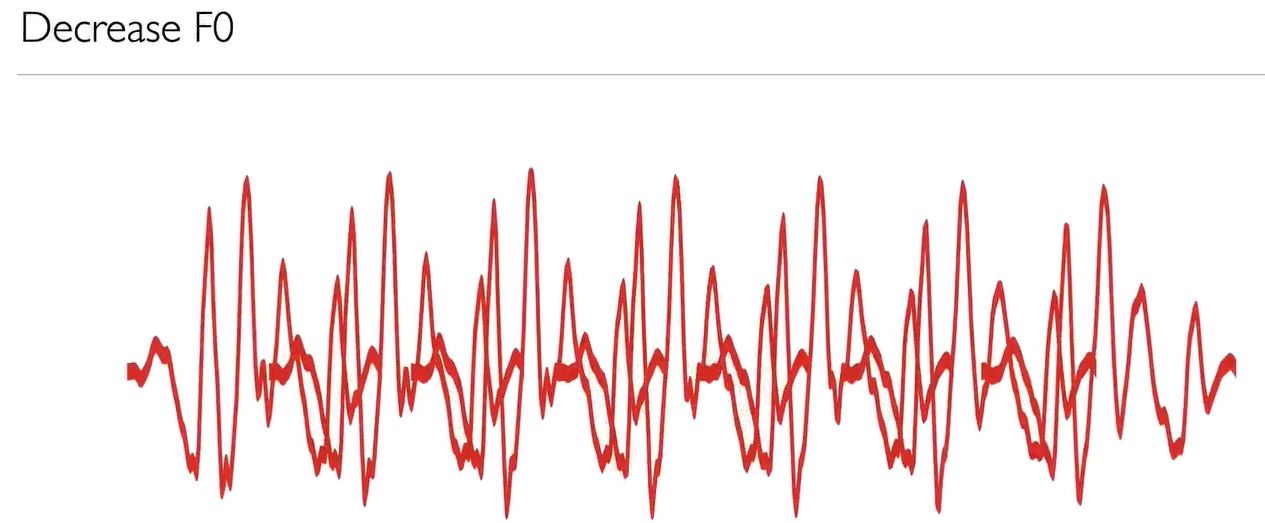


我们已经看到音高周期是如何构成语音的,因为它是声道滤波器的脉冲响应impulse response。这是时域time domain滤波器的视角。
当我们看到声源-滤波器模型source-filter model时,我们看到可以将输入信号的幅值频谱magnitude spectrum与滤波器的幅值频率响应magnitude frequency response相结合,从而得到输出信号的幅值频谱magnitude spectrum。我们只需在幅频谱域magnitude spectrum domain中将它们相乘即可。
在时域time domain中,将输入信号input signal与滤波器的脉冲响应filter's impulse response相结合以产生输出信号的操作称为 "卷积"。
我们需要了解幅频域乘法和时域卷积之间的关系。
- Diphone synthesis 双元音合成:对每个双元音进行一次录音(小型数据库)
使用信号处理方法改变 F0、持续时间和平滑连接,以符合语言规范
例如 TD-PSOLA - Unit selection
记录大型自然语音数据库,根据与语言规范的接近程度选择双音单位 diphone units
如果数据库有足够的变化variation,就不用担心(太多)信号处理问题!
选择何种单位Unit进行连接取决于:
目标成本Target cost:单元与语言规范的匹配程度 how well the unit matches the linguistic specification
连接成本Join cost:单元边缘的匹配程度 how well edges of the units match
- Convolution 卷积 = multiplication of magnitude spectra 幅值频谱相乘 (时域) = addition of log magnitude spectra 对数幅值频谱相加 (频域)
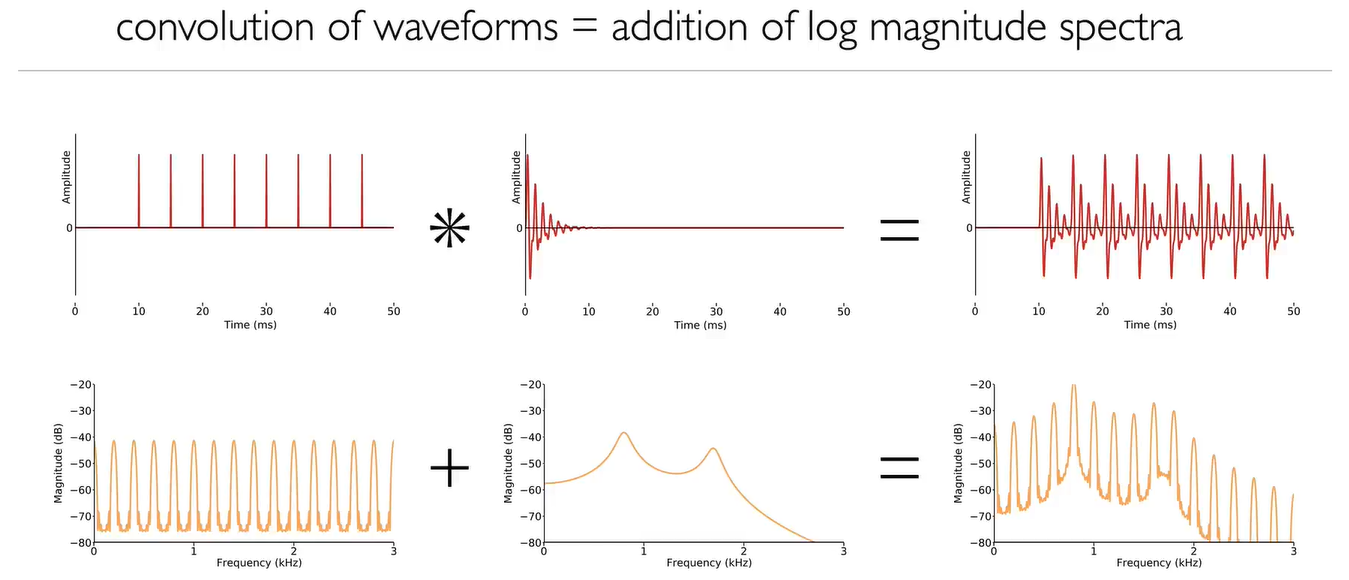
Convolution of any two waveforms in the time domain is equivalent to summation of their log magnitude spectra.
给定这样一个语音信号及其对数幅度频谱,我们通常希望从该信号中恢复声源或滤波器。
例如,我们想恢复声道频率响应frequency response(有时我们使用更广泛的 "频谱包络 "spectral envelope)。这就意味着要反过来做这个等式。这在对数幅度频谱域log magnitude spectrum要比在时域容易得多,因为反向求和要比撤销卷积容易得多。
我们将开发一种简单的方法来分离滤波器的频率响应filter's frequency response,而无需拟合声源-滤波器模型 source-filter model或找到基频周期fundamental periods。该方法从对数幅值频谱开始,进一步转换为一种称为 "倒频谱cepstrum "的新表示法,在这种表示法中,声源和滤波器非常容易分离。
Connected and Citation Speech 连读发音和基本发音


首先,当某些音在单词边界接触时,其中一个或两个音可能会发生变化。在引用形式中,单词 ten 的发音是 /ten/,但在 It's ten past 中,受后面 /p/ 音的影响,它的发音会更接近 /tem/。
第二,可能会漏音。looked 的引用形式(citation form)发音为 /lʊkt/,但在 It looked bad 中,/t/音可能被完全省略,从而简化了辅音群 /-ktb-/,发音更接近 /ɪt lʊkbæd/。
第三,在其他情况下,会插入额外的音。例如,在单词末尾通常不发 /r/ 的地方(如英格兰东南部),for 的引用形式是 /fɔ:/。然而,在 for example 中,/r/ 音被插入单词之间。
Connected Speech Processes
由于辅音和元音都要经过一系列的处理过程,连读的形式千变万化。


Prosodic Structure
Prosody 是语音属性的组合,它将语音分解为时间单位,指示这些单位的边界,并突出某些成分。

Glottalisation 喉音化/声门化
Glottalisation is known by many names including laryngealisation 喉化, creaky voice, creaky phonation and vocal fry 声带颤音.
Module 7 – Speech Recognition – Pattern matching

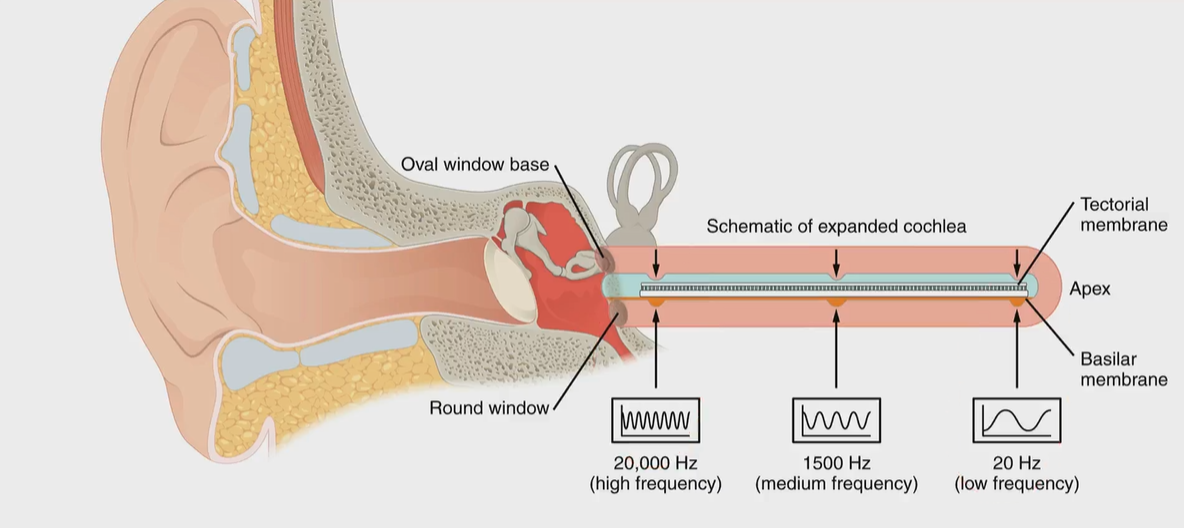
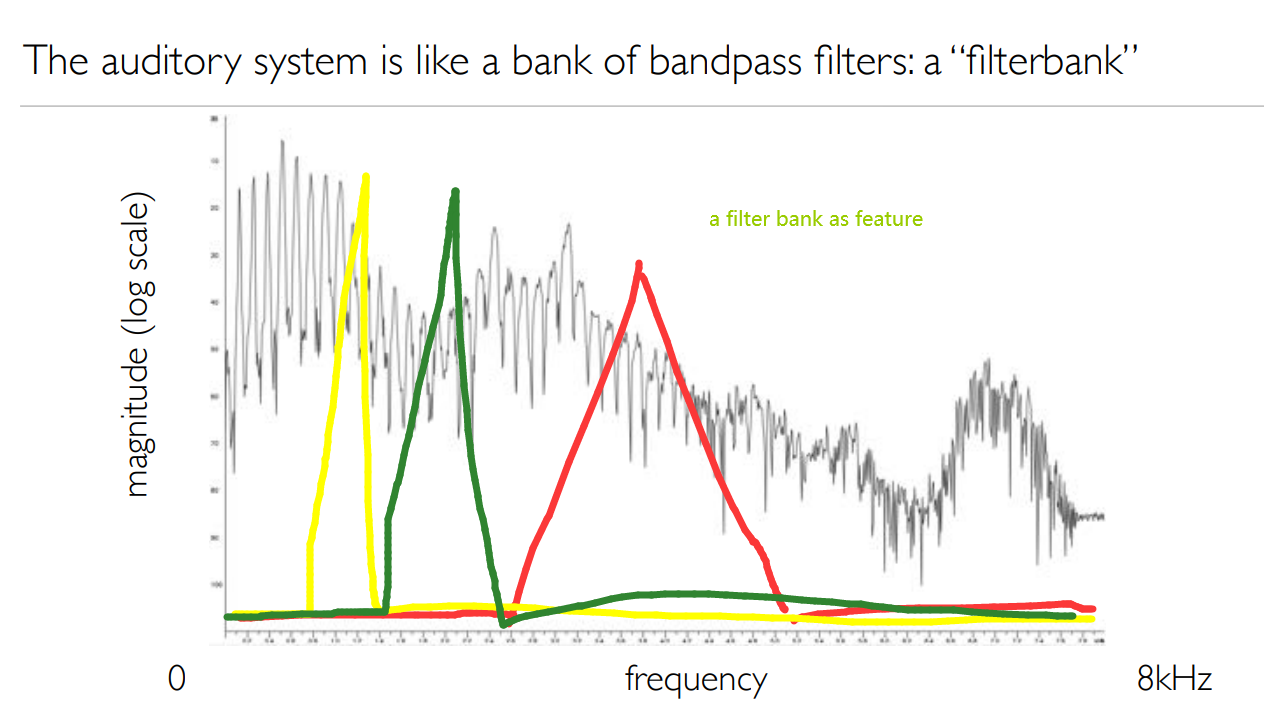
Cochlea, Mel-Scale, Filterbanks
- Cochlea 耳蜗:耳蜗的不同位置会对传入的频率做出反应(耳蜗对声音做了傅里叶变化~)
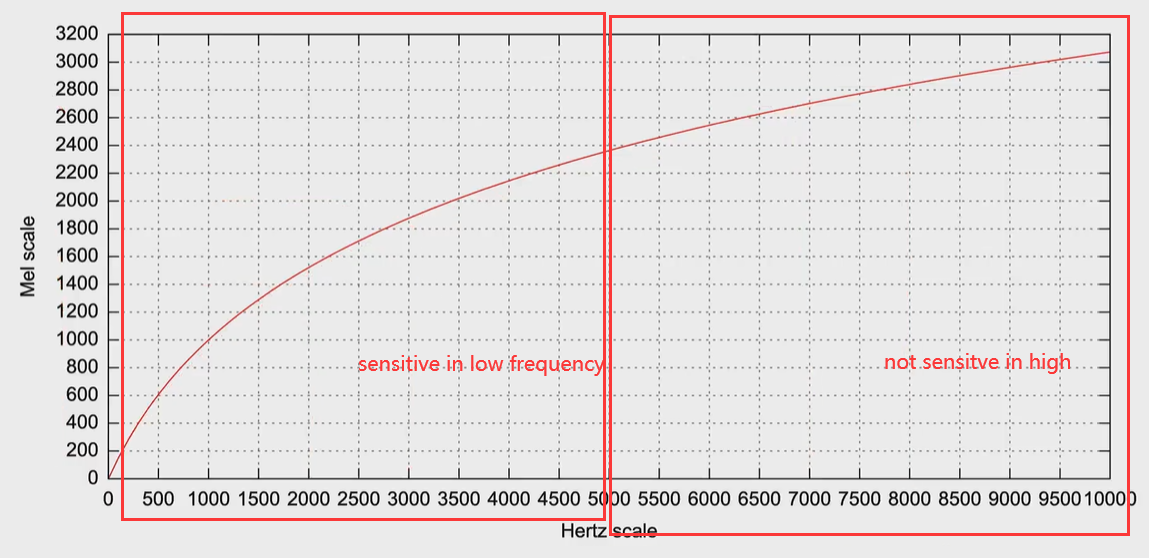
- Mel-Scale 梅尔刻度:梅尔刻度是基于频率定义的非线性刻度单位,表示人耳对音高(pitch)等距变化的感官, 梅尔刻度与线性的频率刻度赫兹之间可以进行近似的数学换算 log
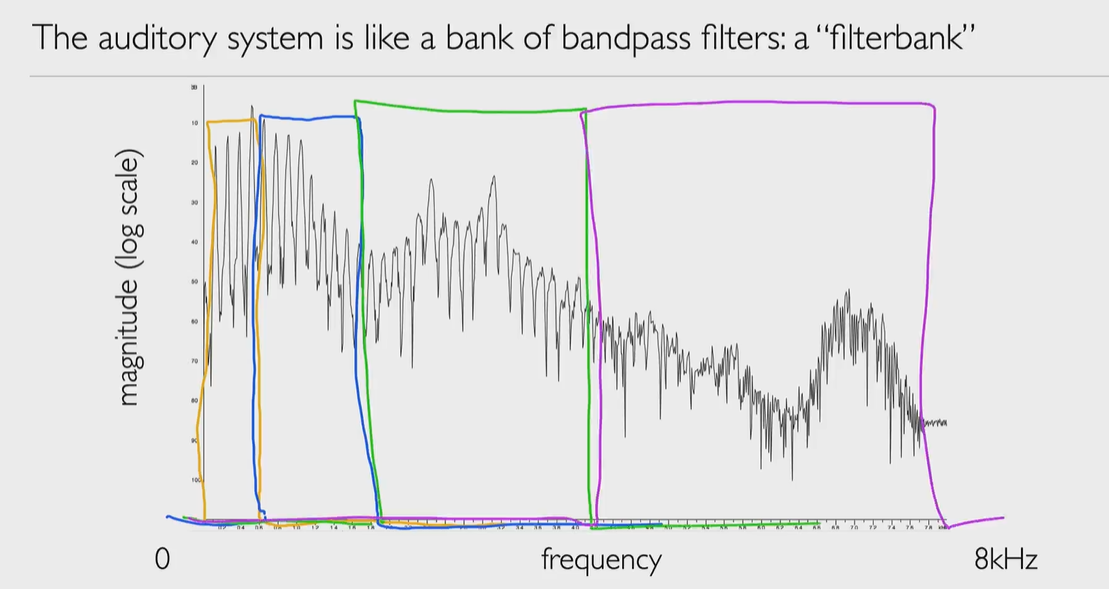
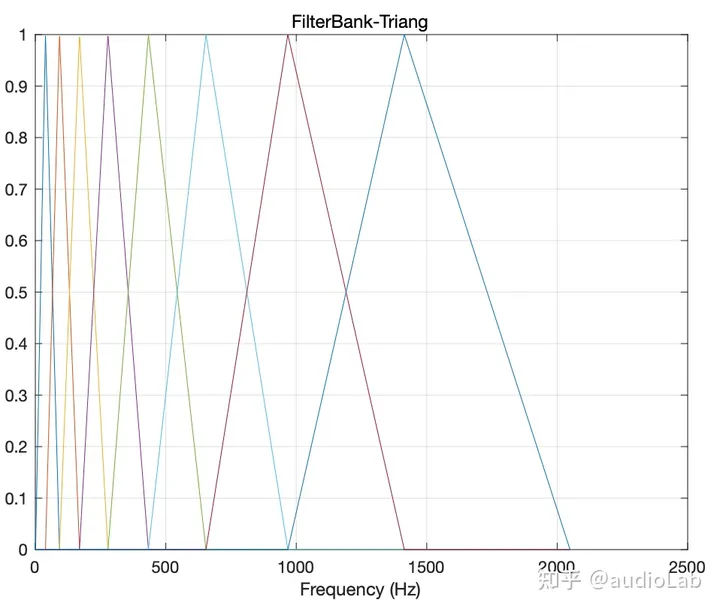
- Filterbanks 滤波器组:是一组带通滤波器bandpass filters,可将输入信号分为多个分量,每个分量承载原始信号的单个子频带(用mel-scale分)
Feature vectors, sequences, and sequences of feature vectors
将语音表示为特征向量序列。波点(Wavepoint)用处不大,magnitude spectrum (DFT)更好。频谱包络(Spectrum envelop)作为特征更好。为了使用频谱包络,我们决定使用滤波器组(filter bank)对特征包络进行编码。特征向量存储编码后的特征包络(feature envelop)或特征库(feature banks)。


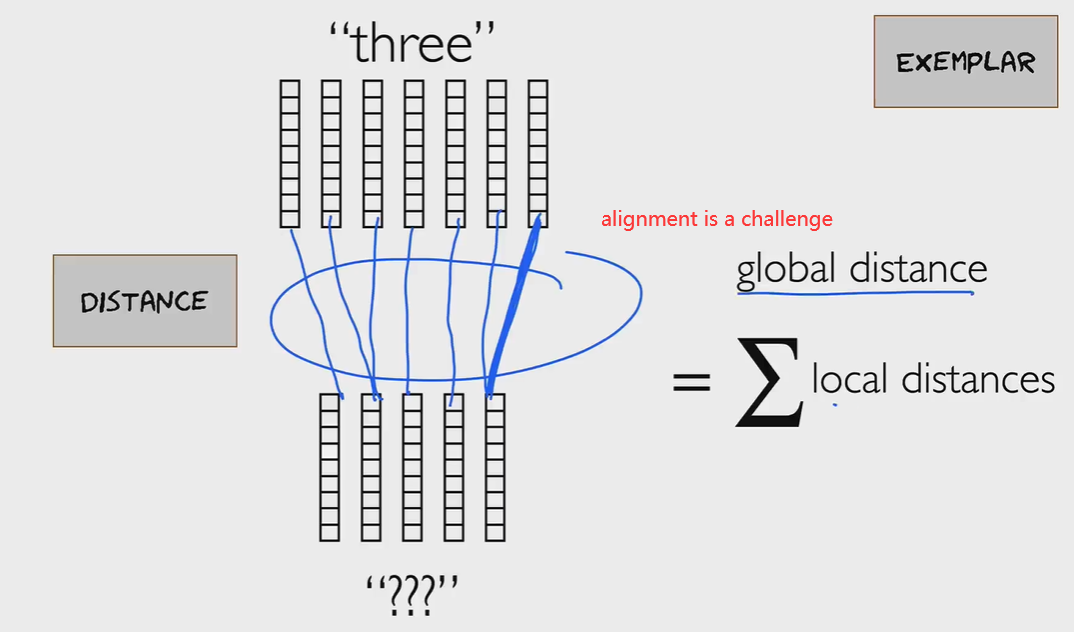
Exemplars and Distances
研究语音数据序列之间的距离和排列distance and alignment概念。Exemplar 范例:一个词的存储特征向量。距离是两个特征向量序列之间的距离(不相似度)。建立范例与未知词的对齐是计算全局距离的第一步。Create alignment of exemplars and the unknown is the first step to calculate the global distance.
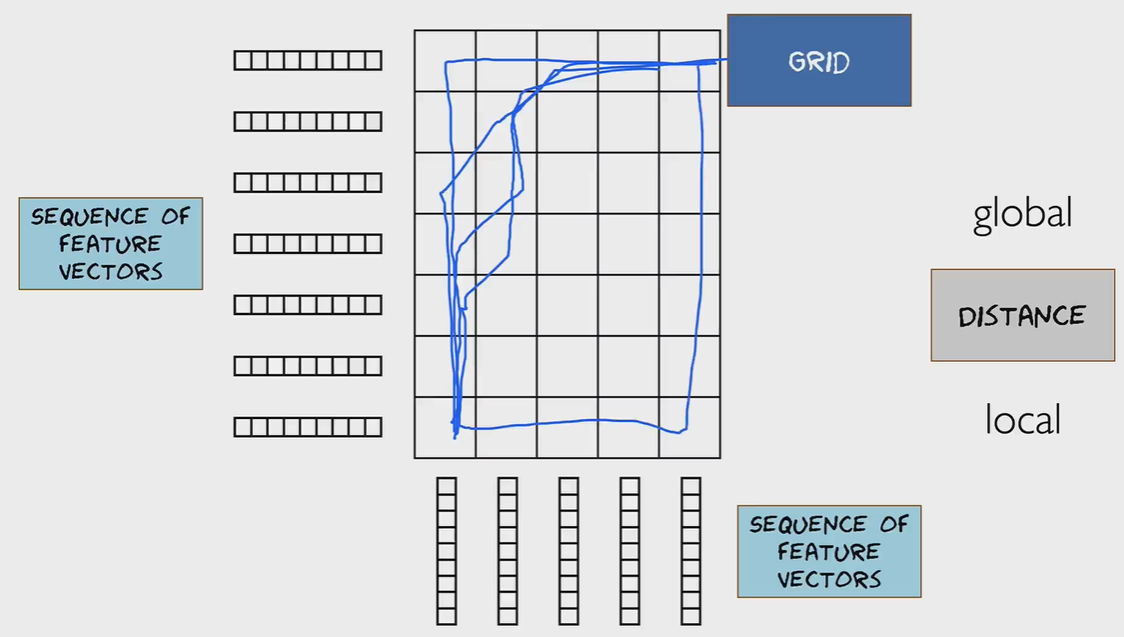
Pattern Matching, Alignment, Dynamic Time Warping(DTW)动态时间规整
DTW可以计算两个时间序列的相似度,尤其适用于不同长度、不同节奏的时间序列(比如不同的人读同一个词的音频序列)。DTW将自动warping扭曲 时间序列(即在时间轴上进行局部的缩放),使得两个序列的形态尽可能的一致,得到最大可能的相似度。
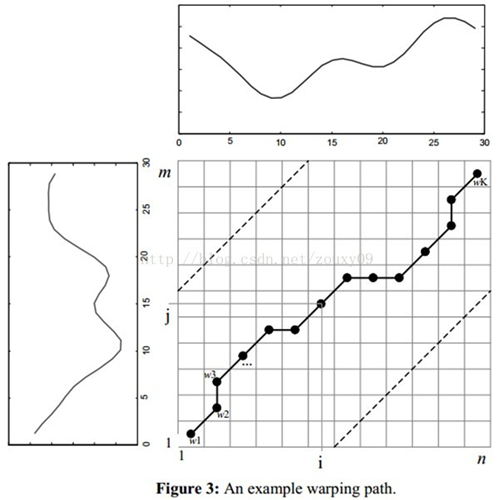
DTW(Dynamic Time Warping) 动态时间规整
DTW可以计算两个时间序列的相似度,尤其适用于不同长度、不同节奏的时间序列(比如不同的人读同一个词的音频序列)。DTW将自动warping扭曲 时间序列(即在时间轴上进行局部的缩放),使得两个序列的形态尽可能的一致,得到最大可能的相似度。应用也比较广,主要是在模板匹配中,比如说用在孤立词语音识别(识别两段语音是否表示同一个单词),手势识别,数据挖掘和信息检索等中。
在时间序列中,需要比较相似性的两段时间序列的长度可能并不相等,在语音识别领域表现为不同人的语速不同。因为语音信号具有相当大的随机性,即使同一个人在不同时刻发同一个音,也不可能具有完全的时间长度。而且同一个单词内的不同音素的发音速度也不同,比如有的人会把“A”这个音拖得很长,或者把“i”发的很短。在这些复杂情况下,使用传统的欧几里得距离无法有效地求的两个时间序列之间的距离(或者相似性)。

例如图A所示,实线和虚线分别是同一个词“pen”的两个语音波形(在y轴上拉开了,以便观察)。可以看到他们整体上的波形形状很相似,但在时间轴上却是不对齐的。例如在第20个时间点的时候,实线波形的a点会对应于虚线波形的b’点,这样传统的通过比较距离来计算相似性很明显不靠谱。因为很明显,实线的a点对应虚线的b点才是正确的。而在图B中,DTW就可以通过找到这两个波形对齐的点,这样计算它们的距离才是正确的。

也就是说,大部分情况下,两个序列整体上具有非常相似的形状,但是这些形状在x轴上并不是对齐的。所以我们在比较他们的相似度之前,需要将其中一个(或者两个)序列在时间轴下warping扭曲,以达到更好的对齐。而DTW就是实现这种warping扭曲的一种有效方法。DTW通过把时间序列进行延伸和缩短,来计算两个时间序列性之间的相似性。
那如果才知道两个波形是对齐了呢?也就是说怎么样的warping才是正确的?直观上理解,当然是warping一个序列后可以与另一个序列重合recover。这个时候两个序列中所有对应点的距离之和是最小的。所以从直观上理解,warping的正确性一般指“feature to feature”的对齐。
假设我们有两个时间序列Q和C,他们的长度分别是n和m:(实际语音匹配运用中,一个序列为参考模板,一个序列为测试模板,序列中的每个点的值为语音序列中每一帧的特征值。例如语音序列Q共有n帧,第i帧的特征值(一个数或者一个向量)是qi。至于取什么特征,在这里不影响DTW的讨论。我们需要的是匹配这两个语音序列的相似性,以达到识别我们的测试语音是哪个词)
- Q = q1,q2,…,qi,…, qn ;
- C = c1,c2,…, cj,…, cm ;
我们需要将连个序列对齐。最简单的对齐方式就是线性缩放了。把短的序列线性放大到和长序列一样的长度再比较,或者把长的线性缩短到和短序列一样的长度再比较。但是这样的计算没有考虑到语音中各个段在不同情况下的持续时间会产生或长或短的变化,因此识别效果不可能最佳。因此更多的是采用动态规划(dynamic programming)的方法。
为了对齐这两个序列,我们需要构造一个n x m的矩阵网格,矩阵元素(i, j)表示qi和cj两个点的距离d(qi, cj)(也就是序列Q的每一个点和C的每一个点之间的相似度,距离越小则相似度越高。这里先不管顺序),一般采用欧式距离,d(qi,cj)= (qi-cj)^2(也可以理解为失真度)。每一个矩阵元素(i, j)表示点qi和cj的对齐。DP算法可以归结为寻找一条通过此网格中若干格点的路径,路径通过的格点即为两个序列进行计算的对齐的点。
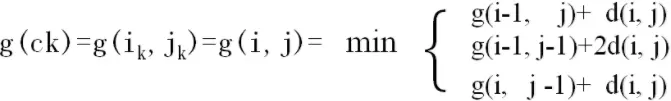
Module 8 – Speech Recognition – Feature engineering
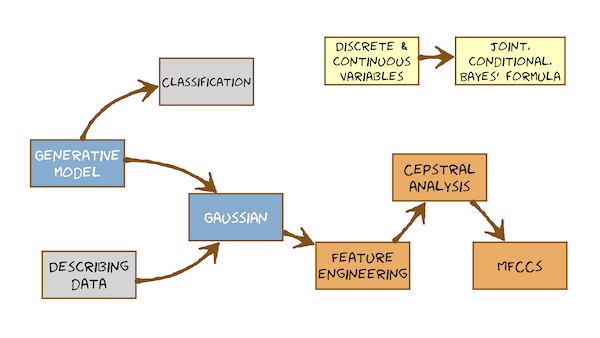
Gaussian distributions in models
高斯生成模型
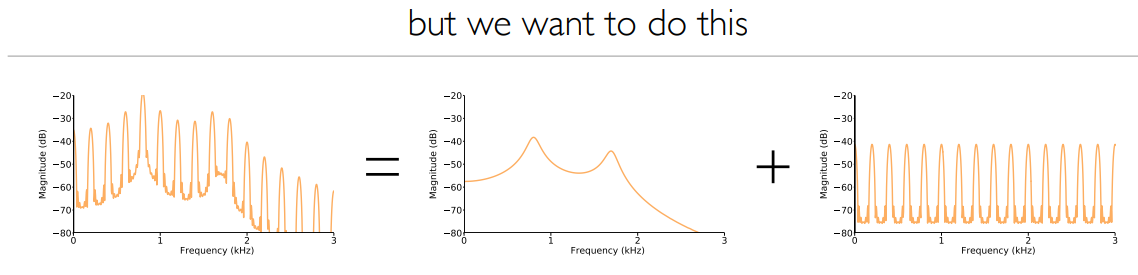
Cepstral Analysis 倒谱分析, Mel-Filterbanks 梅尔滤波器组
现在,我们开始思考如何才能很好地表示声音信号,这就是使用梅尔-频率倒频谱系数(Mel-Frequency Cepstral Coefficients (MFCCs))的原因。用filterbanks取得特征(mel-scale):

如果我们想使用高斯,就必须解决这个相关性问题。
所以我们需要倒谱分析(逆向的卷积操作):
级数展开(因为三角函数正交性):
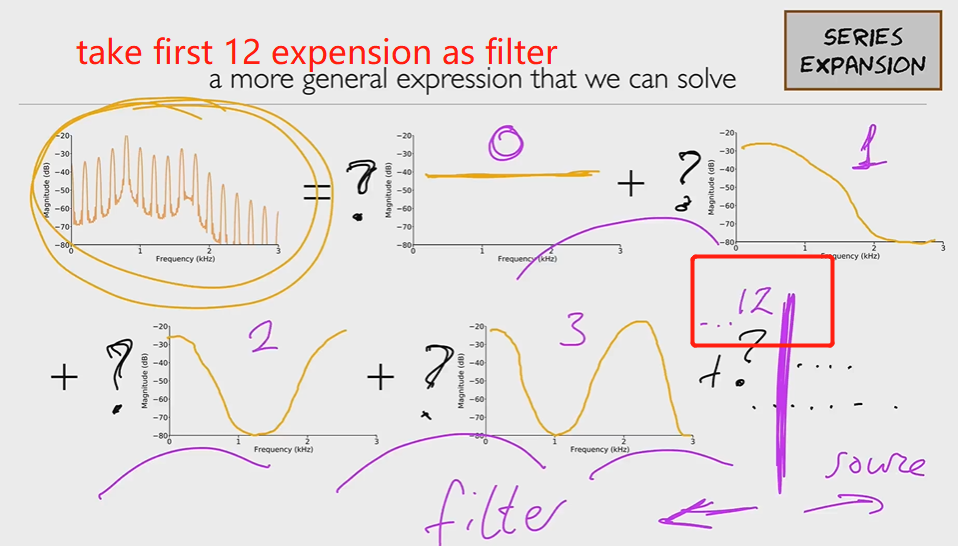
倒频谱图中的自变量称为 "倒频率(quefrency)"。倒频率(quefrency)是时间的量度,但不是信号在时域的量度。那么,倒频谱图中的前 12 个值就是我们经过特征工程后得到的特征向量。
下面是一张mel频谱和mfcc的大概算法流程图。

预加重(Pre-emphasis):属于信号的预处理,补偿高频分量损失,提升高频分量,一般情况下可以忽略此步骤,属于信号的简单增强,对特征有一定的提升效果
STFT:分帧(Frame)现实中大多数信号都是非平稳的,但大多数短时间内可以近似看做是平稳的,可以用短时傅里叶变换表现非平稳信号频域特征。;加窗(Window)目的是减少频谱泄露,降低泄漏频率干扰,提升频谱效果,默认不处理即加矩形窗(Rect),干扰泄漏较严重,一般情况下加Hann窗,针对大多数信号都有不错的效果。快速傅里叶变换FFT
滤波器组过程(Filter bank)是计算mel频谱关键部分和mfcc的重要一步。流程图如下
非线性校正(Rectification):对上一步mel功率频谱取log运算,即mel dB频谱就是通常所使用的“mel频谱”
离散余弦变换(DCT):即数据为偶函数的实数傅里叶的变换,有去相关和能量集中特点。
能量和delta:能量和delta的计算属于mfcc特征体系下的可选操作。能量特征相当于给mfcc加上bias偏置,具有一定抗噪作用。delta是计算数据的变化,基于当前点区域的局部斜率最小二乘近似值。针对mfcc计算其delta,然后再计算delta的delta,可以侦测mfcc状态的变化,变化的变化,可以作为mfcc的两组辅助特征参与网络模型的训练,某些情况下起到更好的准确性和泛化能力。
MFCCs 梅尔倒谱系数
概述推导 MFCC 所需的步骤,进而使用高斯和隐马尔可夫模型对 MFCC 进行建模

truncate series的俩目的:get a very smooth spectral envelope by truncating the series to remove any remaining evidence of the source; removed covariance through the series expansion
所以特征有:energy + 12 MFCCs (一般取前12个filters就够了)
Module 9 – Speech Recognition – the Hidden Markov Model
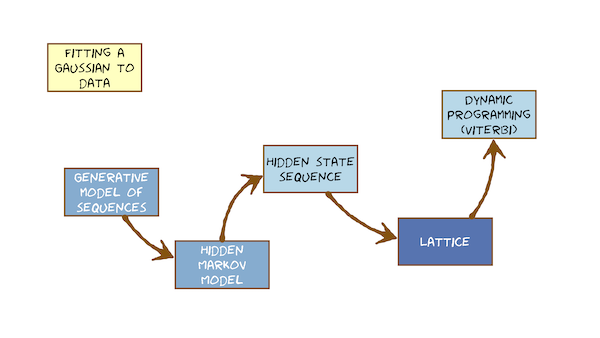
Hidden Markov Models for ASR
Hidden state sequences and alignment
The Viterbi algorithm and token passing
Module 10 – Speech Recognition – Connected speech & HMM training

From subword units to n-grams: hierarchy of models
Conditional independence and the forward algorithm
HMM training with the Baum-Welch algorithm
拓展研究
- 基频提取算法: 如何从音频中准确提取基频(去估计音高)
11872 基频提取算法综述 - 知乎 - Source-filter model 改包络F1和F2合成音色
References
课程主页:Speech Processing
SP Modules Review Contents-腾讯云开发者社区-腾讯云
《语音信号处理》整理[通俗易懂]-腾讯云开发者社区-腾讯云
信号频域分析方法的理解(频谱、能量谱、功率谱、倒频谱、小波分析) - 知乎
MakeNoise07 - 音频的「分辨率」Sample rate, Bit depth, Bit rate, Dynamic range - 简书
DTW(Dynamic Time Warping)动态时间规整 - 知乎