目录
一、规则
二、方法
1、seed
2、identifier
1)选取一个身份号
2)选取一定比例的身份号作为测试集
3)身份号的选取:
3、利用scikit-learn:
1) 随机生成:
2)注:分类
3)利用对收入的分层样本的数量,按比例抽取训练集
代码解释:
目的:
一、规则
随机选取一些例子,除非数据集超大,否则一般选取20%作为测试集
随机选取的函数代码:
import numpy as npdef split_train(data,test_radio):#生成随机数shuffled_indices = np.random.permutation( len(data) )#按照比例计算测试集中数据个数setsize = int( len(data)*test_radio )#切片:随机后的前一部分作为测试集,其余作为训练集test_indices = shuffled_indices[ : setsize]train_indices = shuffled_indices[setsize : ]return data.iloc[train_indices], data.iloc[test_indices]
二、方法
每次随机所得数据都有可能不同,为了保证选取的测试集中的例子稳定,有两种办法
1、seed
为保留相同的数据集,保留随机数的种子 -- 生成随机数的种子号相同,生成的随机数就相同。
import numpy as npdef split_train(data,test_radio):#生成随机数种子,括号里的数字可为任意数np.random.seed(1)shuffled_indices = np.random.permutation( len(data) )setsize = int( len(data)*test_radio )test_indices = shuffled_indices[ : setsize]train_indices = shuffled_indices[setsize : ]return data.iloc[train_indices], data.iloc[test_indices]
调用该函数(同一文件夹下不同py文件):
import random_split_trainsettrainset, testset = random_split_trainset.split_train(housing,0.2)
#注:housing变量见下载和加载数据一文
print('~'*40)
#运行两次可验证是否生成相同随机数
print(trainset[:10])
print('~'*30)
#分别输出训练集和测试集的数据量
print(len(trainset))
print(len(testset))
2、identifier
给每个例子一个固定标识号,给每一个标识号排序,选取前20%的标识号。这样能保证每次训练的例子相同,即使更新了数据集。
代码:根据数据集中的标识符,按照一定比例将数据集划分为训练集和测试集,以保证在划分过程中不会出现同一样本在不同数据集中的情况。
from zlib import crc32def test_set_check(identifier, test_radio):return crc32(np.int64(identifier)) & 0xffffffff < test_radio *2**32def split_train_test_by_id(data, test_radio, id_column):ids = data[id_column]in_test_set = ids.apply(lambda id_: test_set_check(id_,test_radio))return data.loc[-in_test_set], data.loc[in_test_set]-
from zlib import crc32:从Python标准库中的zlib模块导入crc32函数,用于计算CRC32校验值。 -
def test_set_check(identifier, test_ratio)::定义了一个名为test_set_check的函数,它接受两个参数:identifier是数据集中的唯一标识符,test_ratio是测试集所占比例。np.int64(identifier)将标识符转换为64位整数类型。crc32(np.int64(identifier))计算标识符的CRC32校验值。crc32(np.int64(identifier)) & 0xffffffff确保CRC32校验值是一个32位无符号整数。crc32(np.int64(identifier)) & 0xffffffff < test_ratio * 2**32比较CRC32校验值是否小于测试比例的2^32倍,用于确定该标识符是否应该被分配到测试集。
-
def split_train_test_by_id(data, test_ratio, id_column)::定义了一个名为split_train_test_by_id的函数,它用于根据标识符划分训练集和测试集。函数接受三个参数:data是包含数据的DataFrame,test_ratio是测试集所占比例,id_column是数据集中用于标识唯一样本的列名。ids = data[id_column]:从数据集中选择标识符列,存储在ids中。ids.apply(lambda id_: test_set_check(id_, test_ratio)):对每个标识符应用test_set_check函数,返回一个布尔Series,表示每个样本是否应该被分配到测试集。data.loc[-in_test_set]:使用布尔索引选择不在测试集中的样本,得到训练集。data.loc[in_test_set]:使用布尔索引选择在测试集中的样本,得到测试集。
1)选取一个身份号
2)选取一定比例的身份号作为测试集
3)身份号的选取:
1、有些例子自带身份号,如学号
2、使用行号作为身份号:但需要保证:
确保新增是数据放在最后,原来的数据不会被删除
代码:
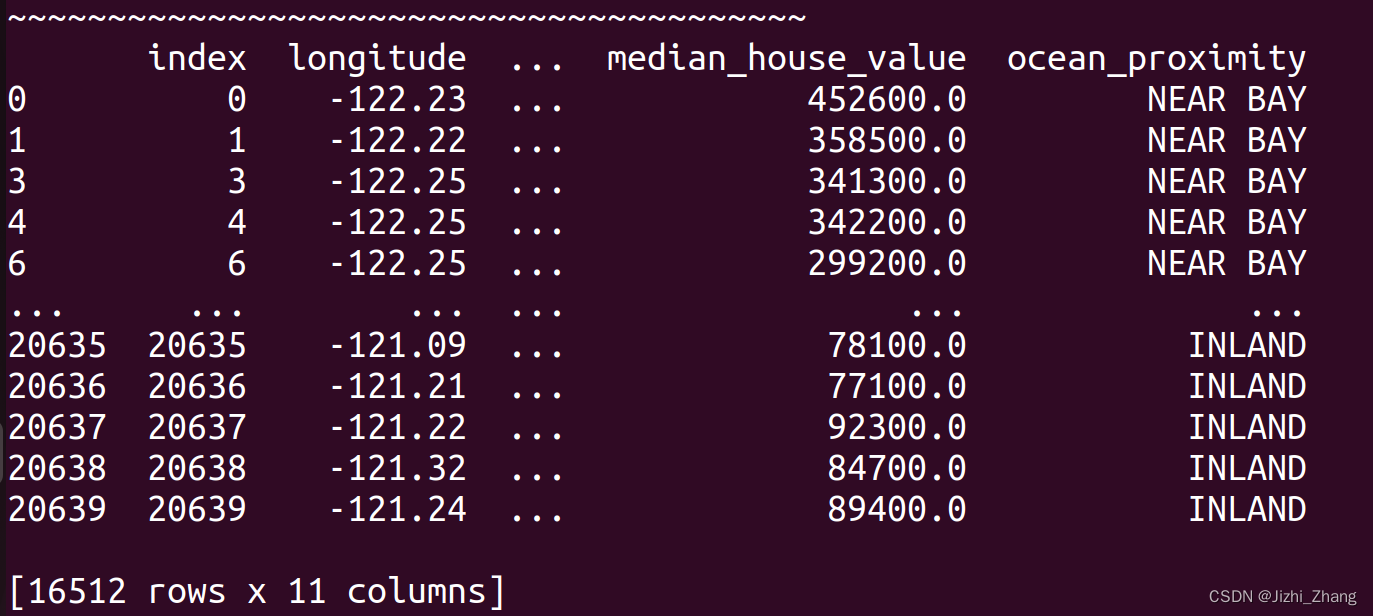
housing_with_id = housing.reset_index()
train_set, test_set = split_train_test_by_id(housing_with_id,0.2,"index")
print('~'*40)
print(train_set)
print('~'*40)
print(test_set)
输出:
3、选取最稳定的特征值,如经纬度等
housing_with_id = housing.reset_index()
housing_with_id["id"] = housing["longitude"] * 1000 + housing["latitude"]
train_set, test_set = split_train_test_by_id(housing_with_id,0.2,"index")print('~'*40)
print(train_set)
print('~'*40)
print(test_set)
3、利用scikit-learn:
1) 随机生成:
#use scikit-learnfrom sklearn.model_selection import train_test_splittrain_set, test_set = train_test_split(housing, test_size = 0.2, random_state = 1)print('~'*40)
print(train_set)
print('~'*40)
print(test_set)
注:如果数据集足够大的时候,可以取得较为理想的效果。但如果不满足,会导致巨大偏差偏心(sampling bias)。
比如在男女占比为47:53的时候,数据集的理想状态为男女占比为47:53 --> 分层样本(stratified sampling)
strata:将数据集按照同种类进行划分抽取成的小组
如果在有分类的情况下仍随机抽取,就会造成约12%的误差,这样结果会产生严重偏移。
2)注:分类
将一个变量分成五类:
import download_data # 导入下载数据模块
import random_split_trainset
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt# 假设 fetch_data() 和 load_data() 函数是正确实现的
download_data.fetch_data()
housing = download_data.load_data()# 添加一个新的列 "income_cat",将 "median_income" 划分为不同的类别
housing["income_cat"] = pd.cut(housing["median_income"], bins=[0., 1.5, 3.0, 4.5, 6.0, np.inf], labels=[1, 2, 3, 4, 5])# 绘制 "income_cat" 的直方图
housing["income_cat"].hist()
plt.show()
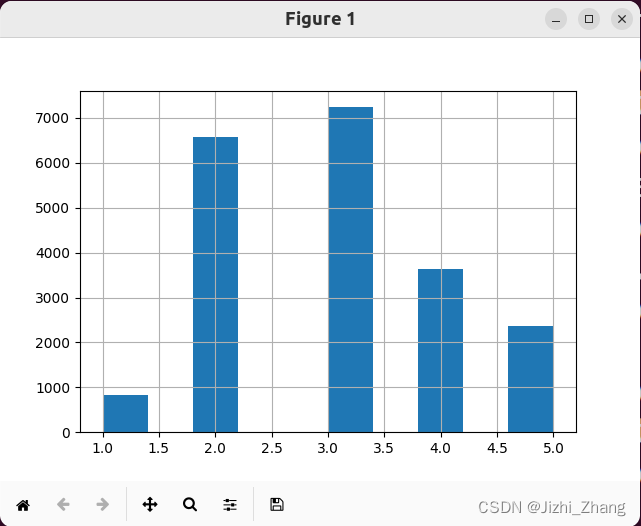
3)利用对收入的分层样本的数量,按比例抽取训练集
import download_data # 导入下载数据模块
import random_split_trainset
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt# 假设 fetch_data() 和 load_data() 函数是正确实现的
download_data.fetch_data()
housing = download_data.load_data()# 添加一个新的列 "income_cat",将 "median_income" 划分为不同的类别
housing["income_cat"] = pd.cut(housing["median_income"], bins=[0., 1.5, 3.0, 4.5, 6.0, np.inf], labels=[1, 2, 3, 4, 5])from sklearn.model_selection import StratifiedShuffleSplitsplit = StratifiedShuffleSplit( n_splits=1, test_size=0.2, random_state=1 )
for train_index, test_index in split.split(housing, housing["income_cat"]):start_train_set = housing.loc[train_index]start_test_set = housing.loc[test_index]print( start_test_set["income_cat"].value_counts() / len(start_test_set) )for set_in(strat_train_set,strat_test_set):set_drop("income_cat",axis=1,inplace=True)
代码解释:
1.导入所需的 Python 模块:download_data、random_split_trainset、numpy、pandas 和 matplotlib.pyplot。这些模块通常用于数据处理、可视化和机器学习。
2.使用 download_data 模块中的 fetch_data() 函数下载数据,并使用 load_data() 函数加载数据。假设这两个函数能够正确地从某个数据源中获取数据并将其转换为 Pandas DataFrame 格式。
3.在加载的数据中,通过将 median_income 列的值分割为不同的收入类别,创建了一个新的列 income_cat。这里使用了 pd.cut() 函数来实现,该函数将一列连续数值分成几个离散的区间,并使用 labels 参数为这些区间赋予标签。
4.接下来,代码导入了 StratifiedShuffleSplit 类从 sklearn.model_selection 模块。这个类用于按照指定的分层策略将数据集分割成训练集和测试集。
5.使用 StratifiedShuffleSplit 对象创建了一个分层的随机分割器 split,指定了分割的参数:分割份数为 1,测试集的比例为 0.2(即 20%),随机数种子为 1。
6.使用 split.split() 方法对数据集进行分层随机分割,其中 housing 是数据集,housing["income_cat"] 是分层依据。然后,通过迭代将训练集和测试集索引保存到 train_index 和 test_index 中。
7.在迭代过程中,通过 housing.loc[] 方法根据索引从原始数据集中获取训练集和测试集,并将其保存到 start_train_set 和 start_test_set 中。
8.最后,通过打印测试集中每个收入类别的比例,了解测试集的分布情况。这里使用了 value_counts() 方法统计每个类别的数量,并除以测试集的总样本数,以获得比例。
9.将income_cat移走,让数据变回原始数据。
输出结果:
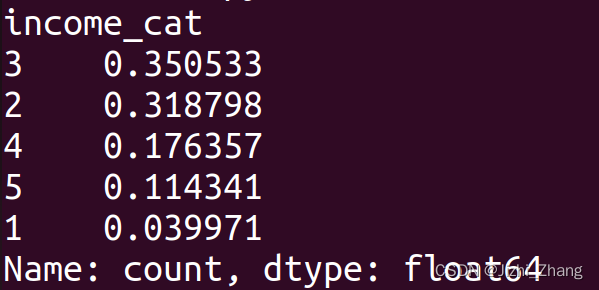
目的:
按照收入类别分层随机地将数据集分割为训练集和测试集,并检查测试集中每个收入类别的比例是否合理。这是一种常见的数据预处理步骤,以确保在模型训练和评估过程中,各个类别的样本分布保持一致。