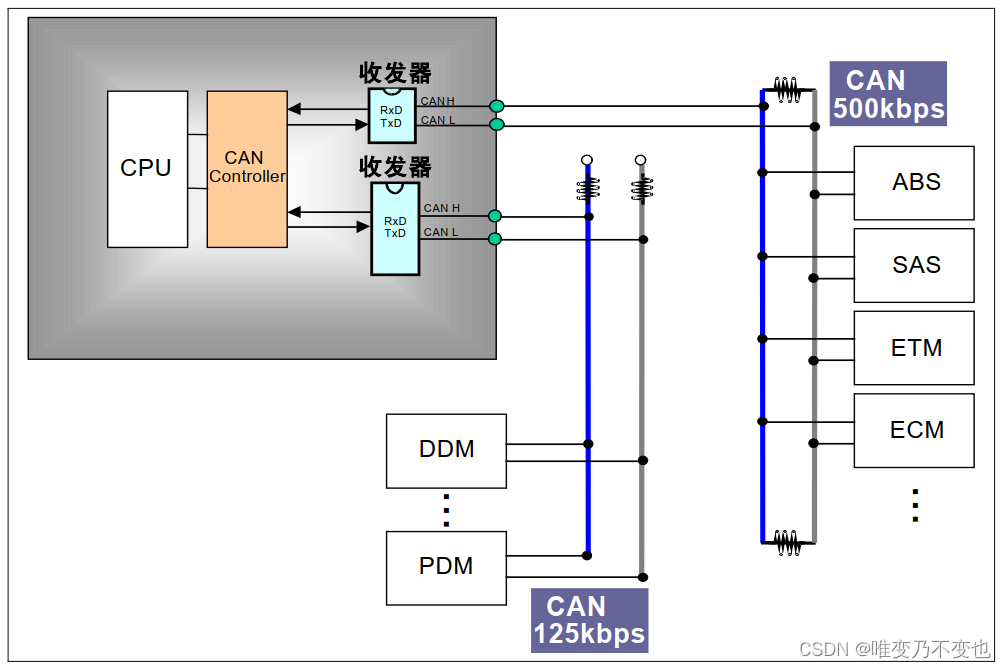
总结:
使用变分自动编码器(VAE)对抓取进行采样,并使用基于点网的抓取评估器模型对采样的抓取进行评估和细化
摘要:
我们将抓取生成问题表述为 使用变分自编码器对一组抓取进行采样,并使用抓取评 估器模型对采样的抓取进行评估和重新精细。Grasp Sampler和Grasp refine网络都将深度相机观测到的3D点 云作为输入。
1.简介
抓取选择是机器人操作中最重要的问题之一。在这 里,机器人观察一个物体,需要决定在哪里移动它的抓 手(3D位置和3D方向)来拾取物体(见图1)。抓手的选择是 复杂的,因为抓手的稳定性取决于物体和抓手的几何形 状、物体质量分布和表面摩擦。物体周围的几何形状对 抓取点的可达性提出了额外的约束,而不会导致机器人 机械手与场景中的其他物体发生碰撞(见图2)。


通常,这 个问题是通过几何启发的启发式方法来解决的,以选择 物体周围有希望的抓取点,可能随后会对采样抓取[31] 的稳定性和可达性进行更深入的几何分析。
这些方法中 的许多都依赖于物体的完整3D模型的可用性,这在现实 场景中是一个严重的限制,例如,机器人只能用嘈杂的 深度相机观察场景。为了克服这一限制,人们可以移动 相机来生成完整的物体模型或执行形状补全,然后进行 基于几何的抓取分析。然而,在受限的空间中移动相机并且对于抓取生成和评估进行形状补是不可能的。
最近,几个小组引入了深度学习技术来评估原始点 云数据的抓取质量[21,19,31,15]。
虽然这些方法提供了很 好的抓取评估,但它们仍然使用手动设计的启发式方法 对样本抓取进行评估,或者依赖于黑盒优化技术,如 CEM[19,35]。此外,它们并没有提供有效的方法来改善 采样抓取。
在本文中,我们引入了第一个基于学习的框 架,用于有效地为未知对象生成各种稳定抓取集。
我们 的方法引入了两种网络架构,用于采样、评估和改进抓 取。本文的主要贡献是:
- 可训练的变分自编码器(VAE),可将观察对象的部 分点云映射到该对象的不同抓取集。重要的是,我 们的VAE提供了所有可能的、有效的抓点的高覆盖 率,同时只产生少量的失败抓点。
- 为了提高VAE样本的精度,我们引入了一个抓取 评估器网络,该网络将观察对象和机器人抓取器 的点云映射到6D抓取器姿势的质量评估。至关重 要的是,我们证明了该网络的梯度可用于改进抓 取样本,例如移动抓取器以避免碰撞或确保抓取 器与物体良好对齐。
- 我们证明,我们的方法优于以前的方法,使机器 人能够拾取17个物体,成功率为88%。生成不同的 抓取是非常重要的,因为不是所有的抓取都是机 器人执行的运动学上可行的。我们进一步表明, 我们的方法在保持高成功率的同时生成了不同的 抓取样本集
本文组织如下。我们首先对比了使用深度学习的 抓取相关方法,然后解释了我们方法的不同组成部分: 抓取采样、评估和细化。最后,我们在一个真实的机 器人平台上评估了我们的方法,并展示了不同超参数 在各种消融研究中的影响。
2.相关工作
目前解决机器人抓取问题的主要方法是数据驱动抓取。 虽然早期的方法是基于手工制作的特征向量[27,1,7], 但最近的方法利用卷积架构来操作原始视觉测量[13,25, 21,19,14]。
这些抓取合成方法中的大多数都是通过将抓 取表示为图像[8]中的定向矩形来实现的。这种3-DOF 表示将夹持器姿态限制为与图像平面平行。这种表示 的缺点是多方面的:由于它限制了抓取的多样性,考虑 到手臂或任务施加的额外约束,拾取物体可能是不可 能的。在静态图像传感器的情况下,它还会导致严重 限制的工作空间[19]。Yan等人[35]通过包含 重建目标物体几何形状的辅助任务来规避这个问题。Zhou等人 [37]学习了一个抓握评分函数,他们也使用该函数进行 抓握细化。这两种方法[35,37]都 只在模拟中进行评估。
我们的方法解决了预测完整的6-DOF预抓姿势的 问题。
很少有方法将问题表述为对单个最佳抓取姿势的 回归[28,16]。它们本质上缺乏预测可能抓取的不同分 布的能力。Choi et al.[4]对24个预定义方向进行分类, 选择一个6-DOF预抓姿势。如此粗糙的SO(3)分辨率必 然会导致预测抓取的多样性有限。
相比之下,抓点检 测方法(GPD)[31,15]对候选抓点进行更密集的采样:对 观测到的点云中的一个点进行随机采样,并构建一个 与估计的表面法线和主曲率的局部方向对齐的达布框 架。尽管这种启发式方法创建了一组相当多样化的候 选抓点,但它无法沿着薄结构(如马克杯、盘子或碗的 边缘)生成抓点,因为从噪声测量中估计这些表面法线 是具有挑战性的。
我们学习的抓握采样器不会受到这 种偏差的影响。因此,我们提出的方法可以找到GPD 无法找到的抓手(参见第4.2节)。
除了使用监督学习之外,抓取也被表述为一个强 化学习问题[9,36]或它的近似[14]。学习到的抓取策略 比只描述最终的抓取姿势更具表现力。尽管如此,这 些方法的动作空间通常是se(2),将多样性限制在自上 而下的抓取。
Deep Neural Networks for Learning from 3D Data深度学习在3D点云数据上的成功要比它在RGB图像上 的巨大成功晚得多。在早期,三维数据被表示为三维体素 [20] 或从 2.5 深度图像中提取特征[6],并使用卷积神经网络对其进行类似于 RGB 图像的处理。Qi 等人[23, 24]引入了一种新的架构,称为PointNet 和 PointNet++,能够表示三维数据并高效地提取表示。PointNet的成功引入了代表3D数 据的不同网络架构[33,30],在3D物体姿态估计、语 义分割和零件分割方面有了显著改进[30,24,22,34]。 为了估计一个成功的喘息,抓取的6-DOF姿势需要是 准确的。在单个RGB图像上操作不能提供所需的精度, 因为输入和输出不在同一域中。因此,我们在SE(3) 中使用3D点云和point - net ++[24]来生成和评估抓地 率。
Variational Autoencoders 变分自编码器[10](VAE)是深度生成模 型的主要类别之一。vae可以以无监督的方式进行训 练,以最大化训练数据的似然性。它们已被应用于各 种任务,如未来预测[12,32],生成新颖的观点[11]和 目标分割[29]。在这项工作中,我们使用VAE对SE(3) 中的一组不同的把握进行采样。
我们模型的整体架构类似于GANs[5]。生成器模 块是一个基于潜在空间和观测点云x的不同样本的 VAE,它生成不同的抓取建议,评估网络(鉴别器)根 据它们成功的可能性接受或拒绝它们。生成器和鉴别 器都将对象的3D点云X作为输入的一部分。
3. 6DOF抓取姿势生成
我们将抓取姿势生成表述为生成机器人抓取姿势 集的过程,这样在这些姿势中的任何一个位置关闭抓 取器都会导致对物体的稳定抓取。此外,该过程应该 生成不同的姿势集,最终覆盖物体可能被抓住的所 有可能方式。在SE(3)中给出了机器人夹持器的姿态, 指定了夹持器的三维平移和三维方向。
在这里,我们 专注于生成单个对象的抓取姿势,由于机械手的到达 和由于场景中的其他对象而产生的额外约束超出了本 工作的范围,可以通过轨迹优化技术来处理。由于在 所有可能抓取的空间中成功抓取的子空间很窄,抓取 姿势生成是具有挑战性的。抓取姿势中的微小扰动可 以将成功的抓取转变为失败的抓取。为了生成不同的 稳定抓握集,我们的方法使用变分自编码器网络进行 采样抓握姿势,然后进行迭代评估和细化过程。

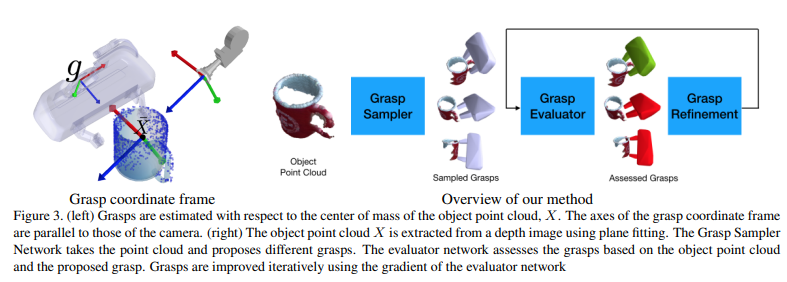
具体而言,我们旨在学习后分布p(g ∗ | x),其中g ∗表示所有成功的grasps和x的空间是相机观察到的对象的部分点云。每个Graspg∈G∗由(r,t)∈Se(3)表示,其中r∈SO(3)和T∈R3是grasp g的旋转和翻译。 grasps在对象参考框架中定义,其原点是x,是观察到的点云的质量中心。它的轴与相机框架的轴平行(见图3-A)。成功的grasps g ∗的分布可能是复杂的,脱节的。例如,杯子的G ∗分布沿边缘,手柄和底部具有多个模式。在每种模式中,成功的掌握空间是连续的,但可以将不同模式的掌握彼此分开。每个对象类别的单独模式的总数根据对象的形状和比例而变化。
由于G ∗的模式的数量未知,因此我们建议学习一个最大化成功graspsg∈G∗可能性的发生器模块。由于发电机仅在训练过程中观察到成功的抓取,因此它也可能会产生失败的graspsg∈G-。为了检测和完善这些负grasps,对评估模块进行了训练,以预测p(s | g,x),即,grasp g和观察到的点云X的成功概率。应用于采样的掌握,评估模式可以预测成功的掌握,并通过网络逐步传播成功,以产生改善的抓地力。可以重复此过程。丢弃所有保持阈值以下的抓地力,提供了最终的高质量掌握。我们方法的概述如图3-B所示。
3.1 Variational Grasp Sampler 变分抓取采样器
3.2 抓取姿势评价
抓取采样器只使用正抓取训练连续后验分布P(G | X, z)。因此,它可能包含分布模式之间的失败抓取。 这些过渡性的把握和其他误报需要被识别和修剪掉。 为此,我们需要一个把握评估网络,为每个把握分配 一个成功概率P(S|g, X)。这个网络需要相对于观察到的 点云X来推理抓取,但它也必须能够外推到物体未观 察到的部分。其他方法学习仅根据物体的局部观察部 分对抓取物进行分类[31,19]。在实践中,物体的观测 点云存在缺陷,如缺失或有噪声的深度值。为了缓解 这个问题,以前的方法求助于使用高质量的深度传感 器[19]或使用多视图[31],这限制了系统在受控环境之 外的部署。在这项工作中,我们仅使用对象的不完美 观测点云X对每次抓取进行分类。
抓取姿势的成功取决于抓取相对于对象的相对姿 势。评估器网络的输入是点云X和抓手g。与抓手采样 器类似,我们为抓手评估器使用点网[23]架构。对抓取 物进行分类有多种方法。第一种简单的方法是将抓手g 的6D姿态与第一层中每个点x∈x的特征相关联。我们 的实验表明,这样的表征导致抓握分类的准确性很差。 相反,我们建议用一种与物体点云更紧密联系的方式 来表示抓握g:我们通过一个根据6D抓取姿势g渲染的点 云Xg来近似机器人抓取器。物体点云X和抓取器点云 Xg通过使用一个额外的二进制特征组合成一个点云, 该特征表明一个点是属于物体还是属于抓取器。在点 网架构中,每个点的特征是点本身及其相邻点的特征 加上点之间的相对空间关系的函数。使用统一的点云 X∪X g,可以很自然地使用抓取姿势g和物体点云X之 间的所有相对信息来对抓取物进行分类。通过优化利 用交叉熵损失对抓握评估器进行优化。
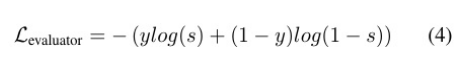
其中y是抓取的基础真值二元标签,表示抓取是否成功, s是评估器预测的成功概率。 为了训练一个鲁棒的评估器,模型需要同时训练 正抓取和负抓取。由于所有可能的6D抓取姿势的空间 组合很大,因此不可能对所有的负抓取进行采样。相 反,我们进行硬负挖掘来对负抓取进行抽样。硬负抓 取的集合G − is定义为与积极抓取姿势相似,但要么与物体发生碰撞,要么 距离物体太远而无法抓取物体的抓取姿势。更正式地, G−被定义为:

3.3 迭代抓取姿势细化
xx
4.实验
xx