Pytest作为Python的一个单元测试框架,主要用来针对软件最小单位(函数、方法)进行正确性的检查,经过封装可以用于我们自动化测试。
一、Pytest可以做什么
单元测试框架主要用于编写、组织和执行测试用例。具体概述如下:
1、编写测试用例:提供了一种简单的语法和结构,用于编写测试用例。通过断言来判断预期结果和实际结果的差异
2、组织测试用例:按照一定的规则从多个文件中找到我们的测试用例
3、执行测试用例:按照一定的顺序和规则去执行测试用例,并输出结果
4、测试报告:统计测试进度、耗时、通过的测试用例数、失败的测试用例数,生成测试报告
二、Pytest插件:
Pytest 有许多强大的插件,可以帮助你扩展和定制测试框架,以满足不同的测试需求。以下是一些常用的 Pytest 插件:
1、pytest-xdist: 允许并行运行测试用例,支持多进程和分布式测试。
2、pytest-html: 生成漂亮的 HTML 测试报告,包含详细的测试结果和统计信息。
3、pytest-ordering: 允许你控制测试用例的执行顺序。有时候,测试用例的执行顺序是很重要的,比如测试依赖性的场景。这个插件允许你指定测试用例的顺序,以确保它们按照你期望的顺序执行。
4、pytest-rerunfailures: 当测试用例失败时,这个插件允许重新运行失败的测试用例,以便检查是否是偶然性的失败。你可以指定重试的次数和间隔时间。
5、pytest-html: 生成漂亮的 HTML 测试报告,其中包含详细的测试结果、统计信息和图表。这样的报告易于阅读和分享,有助于更好地理解测试结果。
6、allure-pytest: 将 Allure 报告集成到 Pytest 中,以生成具有丰富功能和交互性的测试报告。Allure 报告不仅提供了测试结果和统计信息,还提供了图表、趋势分析和历史记录等功能,帮助你更好地理解测试结果和趋势。
7、pytest-cov: 用于生成测试覆盖率报告,可以帮助你评估测试覆盖范围和质量。
8、pytest-mock: 提供了强大的 mocking 功能,可以方便地模拟对象和行为,用于单元测试。
9、pytest-parameterized: 提供了参数化测试的功能,可以通过参数化测试用例来测试不同的输入和场景。
10、pytest-timeout: 设置测试用例的超时时间,防止测试用例运行时间过长导致阻塞。
这些插件提供了丰富的功能和工具,可以帮助你更轻松、高效地编写和运行测试用例,提高测试覆盖率和质量。你可以根据项目需求选择合适的插件,并根据需要进行定制和配置。
二、Pytest默认使用规则:
为了使Pytest能够自动发现项目中的测试文件和测试函数必须要满足以下规则:
1、模块命必须以test_开头或者_test结尾
2、测试类必须以Test开头,并且不能有init方法
3、测试用例必须以test开头
(以上规则可以在pytest.ini配置文件中修改)
三、Pytest测试用例运行方式
1、主函数模式
(1) 运行所有:pytest.main()
(2) 指定模块 : pytest.main([‘-vs’, ‘test_selesnium.py’])
(3) 制定目录:pytest.main([‘-vs’, ‘./testcase’])
(4) 通过nodeid指定用例运行: nodeid由模块命,分隔符,类名,方法名,函数名组成
pytest.main([‘-vs’, ‘./testcase/test_loginFail.py’])
pytest.main([‘-vs’, ‘./testcase/test_loginFail.py::TestLoginFail::test_02’])
2、命令模式
(1) 运行所有:pytest
(2) 指定模块:pytes -vs test_selesnium.py
(3) 制定目录 pytest -vs ./testcase
(4) 通过nodeid指定用例运行: nodeid由模块命,分隔符,类名,方法名,函数名组成 pytest -vs ./testcase ./testcase/test_loginFail.py::TestLoginFail::test_02
参数说明:
-s:表示输出详细打印信息,包括print打印信息
-v:显示更详细信息
-vs:这两个参数一起用
-n:支持多线程和分布式运行 pytest.main([‘-vs’, ‘./testcase’, ‘-n=2’])(需要先安装:pip install pytest-xdist)
–reruns nums 失败用例重跑 pytest.main([‘-vs’, ‘./testcase’, ‘–reruns=3’])(需先安装pytest_rerunfailures库)
-x:表示只要有一个用例失败测试停止 pytest.main([‘-vs’, ‘./testcase’, ‘-x’])
–maxfail=2 出现两个用例失败停止 pytest -vs ./testcase --maxfail 2
-k:根据测试用例的部分字符串制定测试用例 入
pytest -vs ./testcase --k “01” (运行包含01字符串的测试用例)
3.通过读取pytest.ini配置文件(框架用方式)
pytest.ini 这个文件是pytest单元测试框架的核心配置文件。
(1)位置:一般放在项目的根目录
(2)编码:必须是ANSI,可以使用notpad++修改编码格式
(3)作用:改变pytest默认的行为
(4)运行的规则:不管是主函数的模式运行,命令行模式运行,都会读取这个配置文件
说明:
- addopts: 指定默认的 pytest 选项
- testpaths: 指定测试文件路径。例如,可以指定 tests 目录为测试文件路径
- norecursedirs: 指定 pytest 忽略的目录
- python_files: 指定 pytest 只查找包含指定文件名模式的文件
- python_functions: 指定 pytest 只查找包含指定函数名模式的函数
- python_classes: 指定 pytest 只查找包含指定类名模式的类
[pytest]
#命令行参数,用空格分割
addopts = -vs --html ./report/report.html
#执行指定路径下的测试用例
testpaths = ./testcase
#配置测试搜索的模块文件名称
python_files = test*.py
#配置测试搜索的测试类名
python_classes = Test*
#配置测试搜搜的测试函数命
python_functions =test
四、 pytest执行测试用例的顺序
pytest:默认从上到下
改变默认的执行顺序:使用mark标记(需要安装pytest_ordering)
@pytest.mark.run(order=3)
五、分组执行用例
可以按照分组来执行,比如冒烟、分模块执行、分接口或者UI执行
smoke:冒烟用例,分布在各个模块,可以在pytest.ini中定义标签,如下:在pytest.ini中定义标记
markers =smoke: 冒烟用例login: 登录模块management: 管理模块
在测试用例上标记
@pytest.mark.managementdef test_003(self):sleep(2) print("第二个测试用例")
执行用例:
pytest -vs -m "smoke " (执行smoke标记的用例)
pytest -vs -m “smoke or management”(执行smoke和management标记的用例)
六、Pytest跳过用例
1、无条件跳过
@pytest.mark.skip(reason="想跳过")
2、有条件跳过
@pytest.mark.skipif(age > 65, reason='免门票')
七、生成报告
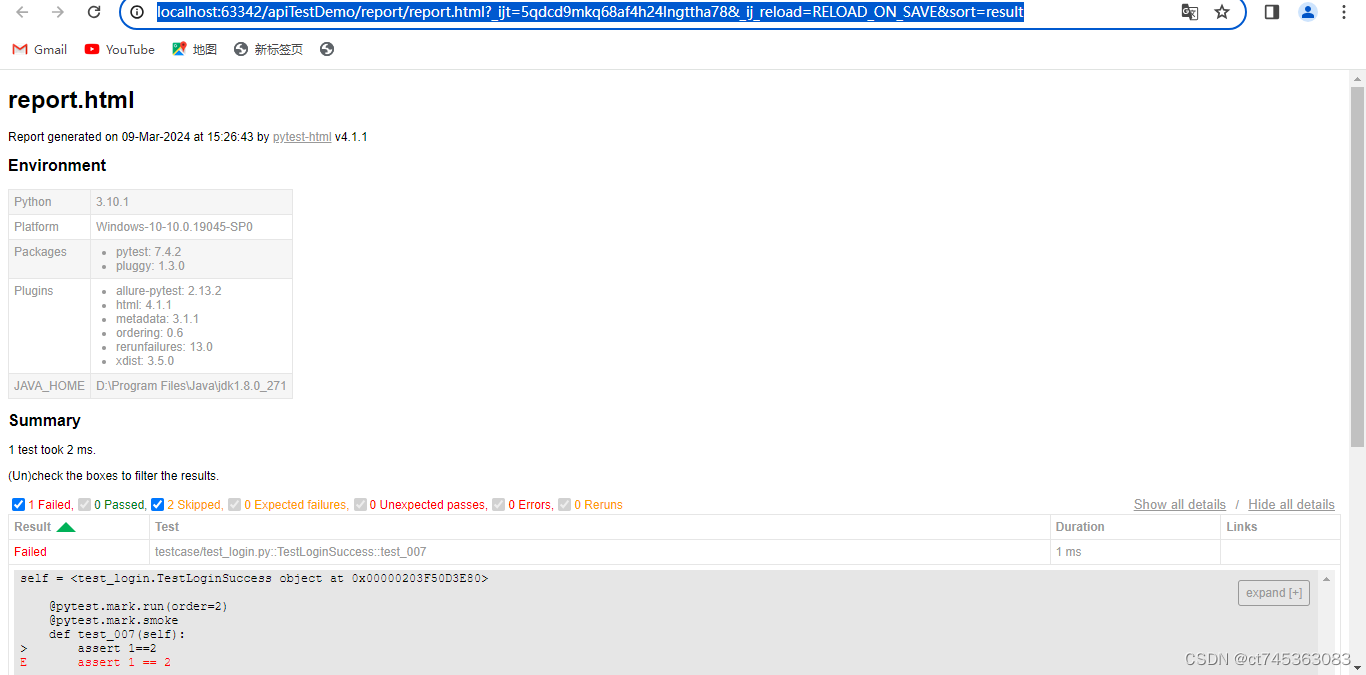
1、pytest-html
需要安装pytest-html( pip install pytest-html
)
在pytest.ini中配置html参数及报告路径
#命令行参数,用空格分割
addopts = -vs --html ./report/report.html
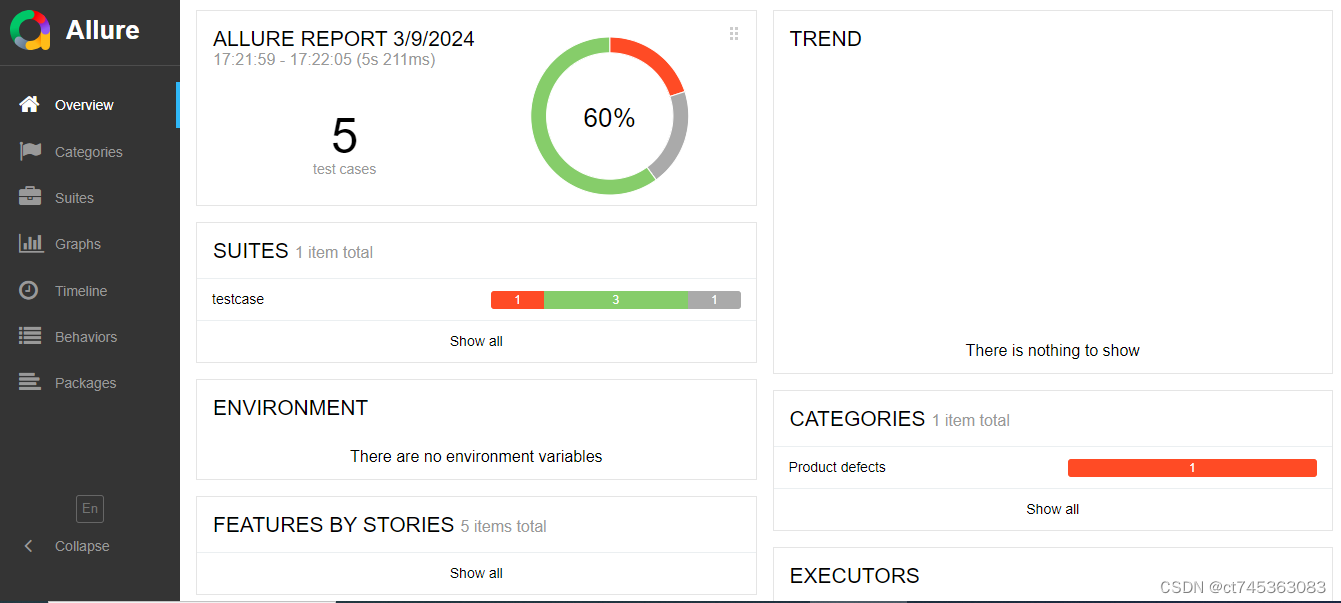
2、allure-pytest插件生成allure测试报告
(1)下载后配置path路径
(2)在pytest.ini中加入命令生成*.json格式的临时报告
addopts = -vs --alluredir ./temp
(3)生成allure报告:
if __name__ == '__main__':pytest.main()os.system('allure generate ./temp -o ./report --clean')
参数意义:
- allure generate:命令,固定的
- ./temp;临时的json格式报告路径
- -o:输出output
- ./report :生成allure报告的路径
- –clean:清空原来的报告
八、Pytest前后置处理(固件,夹具)
setup/teardown,
在自动化执行之前启动程序,在自动化执行结束后关闭程序
setup_class/teardown_class
在每个类执行前的初始化工作,比如:创建日志对象,创建数据库的连接,创建接口的请求对象
在每个类结束后骚味工作,比如:销毁日志对象,销毁数据库的连接,销毁接口的请求对象
使用@pytest.fixture装饰器来实现部分用例的前后置
@pytest.fixture(scope=“”,params=“”,autouse=“”,ids=“”,name=“”)
(1)scope 默认是function,也可以设定为class、module、package、session
定义了夹具的作用范围,即在哪些范围内共享夹具。常用的作用范围有:
- “function”(默认值):每个测试函数都会调用夹具一次。
- “class”:每个测试类都会调用夹具一次。
- “module”:每个测试模块(Python 文件)都会调用夹具一次。
- “package”:每个测试包(含有 init.py 文件的目录)都会调用夹具一次。
- “session”:整个测试会话(Pytest 运行过程)只调用夹具一次。
(2)params:用于指定夹具的参数化值,可以是一个可迭代对象(如列表、元组、生成器等)。测试用例将根据这些参数化值多次运行,每次运行都使用不同的参数。
(3)autouse:默认是false,如果设置为 True,则所有测试函数都会自动应用该夹具,无需在测试函数中显式引用夹具。
(4)ids:一个可选的可迭代对象,用于为夹具的参数化值提供自定义标识符。这些标识符将用于生成测试报告中的标识符,以便更好地识别每个参数化测试的结果。(可以不用)
(5)name:夹具的名称,用于在测试报告中标识夹具。默认情况下,Pytest 将使用夹具函数的名称作为夹具的名称,但你可以通过指定 name 参数来自定义夹具的名称。
import pytest
# 定义被测试的函数
def add(a, b):return a + b# 使用@pytest.fixture装饰器定义测试夹具
@pytest.fixture(params=[(1, 2), (2, 3), (4, 5)], ids=["1+2", "2+3", "4+5"], name="test_data")
def test_data(request):return request.param# 使用参数化进行测试
def test_addition(test_data):a, b = test_dataresult = add(a, b)assert result == a + b
在这个示例中:
我们使用 @pytest.fixture 装饰器定义了一个测试夹具 test_data,并使用 params 参数传递了三组参数化的输入值。
我们使用 ids 参数为每组参数化值提供了自定义的标识符,以便在测试报告中更清晰地显示测试结果。
我们使用 name 参数为夹具定义了一个自定义的名称,用于在测试报告中标识夹具。
这样,测试用例 test_addition 将会被执行三次,每次使用不同的参数化值进行测试。在测试报告中,我们将能够清晰地看到每个测试用例的参数化值以及测试结果。