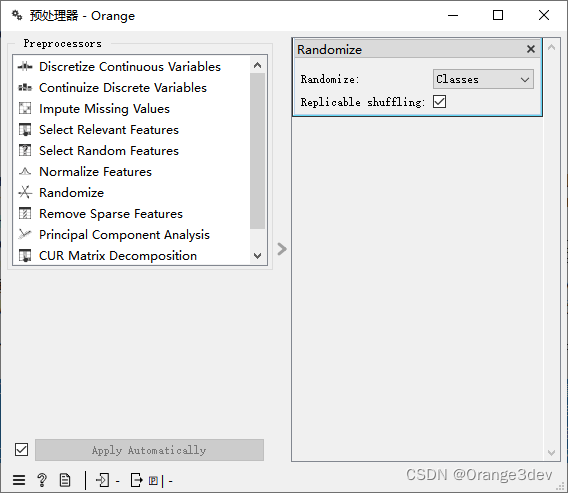
1.组件介绍
Orange3 提供了一系列的数据预处理工具,这些工具可以帮助用户在数据分析之前准备好数据。以下是您请求的预处理组件的详细解释:
- Discretize Continuous Variables(离散化连续变量): 这个组件将连续变量转换为分类变量。它提供了多种方法,如等宽区间划分、等频区间划分、基于决策树的最优划分等。离散化可以帮助简化模型,使决策规则更加直观。
- Continuize Discrete Variables(连续化离散变量): 与离散化相反,这个组件将分类变量转换为连续变量。这可以通过将类别编码为唯一的数值来实现,例如使用独热编码或标签编码。
- Impute Missing Values(填充缺失值): 这个组件用于处理数据中的缺失值。它提供了多种填充策略,如使用平均值、中位数、众数,或者通过模型预测来估算缺失值。
- Select Relevant Features(选择相关特征): 特征选择是识别数据集中最重要特征的过程。这个组件提供了多种方法,如过滤式选择(例如基于方差、相关系数)、包裹式选择(例如递归特征消除)和嵌入式选择(例如使用LASSO或随机森林的特征重要性)。
- Select Random Features(选择随机特征): 这个组件随机选择一定比例的特征。这在创建模型的随机子集或进行特征选择时非常有用,可以帮助减少过拟合并提高模型的泛化能力。
- Normalize Features(归一化特征): 标准化是将特征缩放到一个共同的尺度,通常是将特征值转换为平均值为0、标准差为1的正态分布。这个组件可以使用最小-最大标准化、Z分数标准化等方法。
- Randomize(随机化): 这个组件随机打乱数据集中的行。这通常用于在建模之前打乱数据,以确保模型的训练不会受到数据原始顺序的影响。
- Remove Sparse Features(移除稀疏特征): 稀疏特征是指在数据集中出现频率很低的特征。这个组件可以帮助移除那些可能对模型训练没有帮助的稀疏特征。
- Principal Component Analysis(主成分分析): 主成分分析(PCA)是一种降维技术,它通过线性变换将原始特征转换为新的特征空间,其中新特征是原始特征的线性组合。PCA可以帮助识别数据中的主要变量,并减少特征的数量。
- CUR Matrix Decomposition(CUR矩阵分解): CUR分解是一种矩阵分解方法,它将矩阵分解为三个矩阵的乘积:C(保留的列)、U(保留的行)和R(对角线上的元素)。这种方法可以用于降维和特征选择,特别是在处理大型稀疏矩阵时。
这些预处理组件在Orange3中通过图形用户界面操作,用户可以通过拖放这些组件到工作流程中来构建数据处理流程。每个组件都有相应的参数可以调整,以满足特定的数据处理需求。
2.离散化连续变量
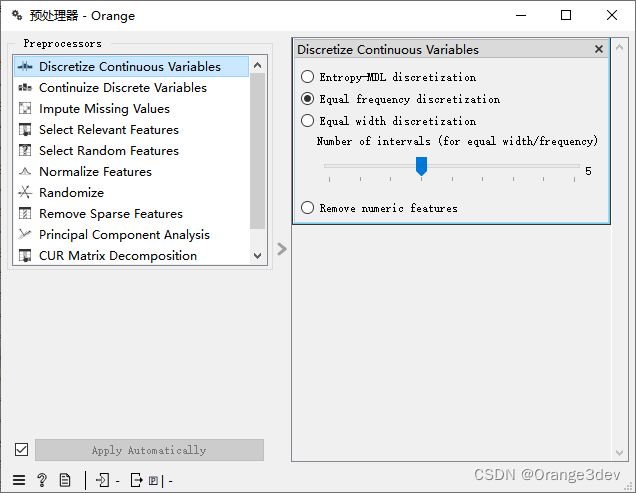
- Entropy-MDL discretization(基于熵和最小描述长度的离散化): 这种方法使用熵和最小描述长度(Minimum Description Length, MDL)原则来确定最优的离散化区间。它旨在找到最小化数据描述长度的分割点,同时考虑到数据的熵(即信息的混乱程度)。这种方法通常能够产生较少的区间,同时保留数据的分类信息。
- Equal frequency discretization(等频离散化): 等频离散化将连续变量划分为具有相同频率的区间。每个区间的数据点数量大致相等,这意味着每个区间包含相同数量的观测值。这种方法适合于处理具有不同分布的数据,因为它不依赖于数据的具体数值,而是根据数据点的相对位置进行分割。
- Equal width discretization(等宽离散化): 等宽离散化通过将连续变量的整个范围等分成宽度相等的区间来实现。每个区间的宽度是固定的,这对于具有均匀分布的数据非常有用。这种方法简单直观,但可能不考虑数据的具体分布,导致某些区间包含过多或过少的观测值。
- Remove numeric features(移除数值特征): 这个选项不是离散化方法,而是一个辅助功能,用于从离散化过程中排除特定的数值特征。如果你有一些不需要离散化的数值特征,可以使用这个选项来确保它们不被修改。
在选择离散化方法时,需要考虑数据的特点和分析的目标。例如,如果数据分布不均匀,等频离散化可能是一个更好的选择。相反,如果数据的分布相对均匀,等宽离散化可能足够使用。基于熵和MDL的离散化方法则尝试在保留数据信息的同时减少区间的数量,这通常需要更多的计算资源。
3.连续化离散变量

- 使用最频繁的值作为基底(Base):将最频繁的离散值视为0,其他值视为1。对于超过两个值的离散属性,最频繁的值将被视为基底,并在相应列中与剩余值进行对比。
- 每个值一个特征(One feature per value):为每个值创建列,实例具有该值的位置放置1,不具有该值的位置放置0。本质上是一种独热编码(One Hot Encoding)。
- 移除非二进制特征(Remove non-binary features):只保留值为0或1的分类特征,并将它们转换为连续特征。
- 移除分类特征(Remove categorical features):彻底移除分类特征。
- 按序处理(Treat as ordinal):将离散值视为数字。如果离散值是类别,每个类别将被分配一个它们在数据中出现的数字。
- 除以值的数量(Divide by number of values):与按序处理类似,但最终值将除以值的总数,因此新连续变量的范围将是[0, 1]。
4.缺失值填充
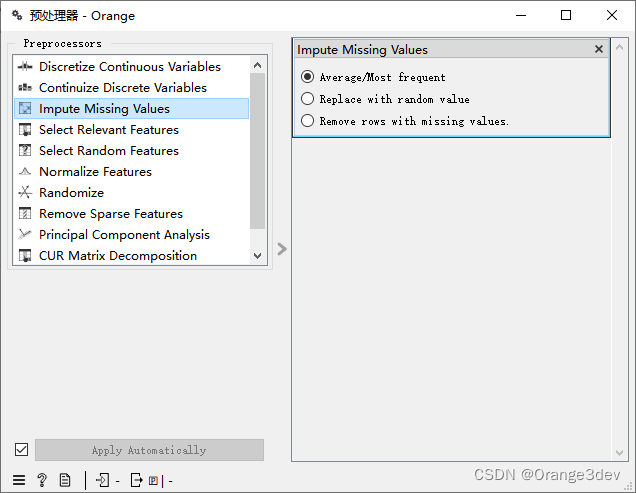
- 平均值/最频繁值(Average/Most frequent):用平均值(对于连续变量)或最频繁出现的值(对于离散变量)替换缺失值(NaN)。
- 用随机值替换(Replace with random value):用每个变量范围内随机生成的值替换缺失值。
- 移除含有缺失值的行(Remove rows with missing values)。
5.选择相关特征
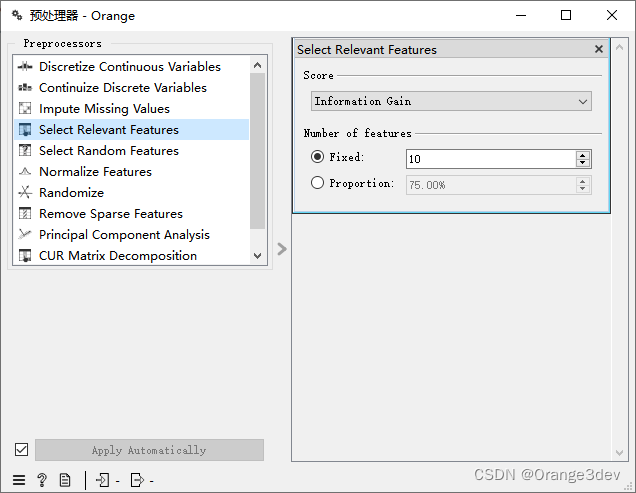
- 类似于排名(Rank),这个预处理器只输出最有信息量的特征。得分可以通过信息增益、增益比、基尼指数、ReliefF、基于快速相关性的过滤、ANOVA、Chi2、RReliefF和单变量线性回归来确定。
- 策略指的是输出中应该有多少变量。固定(Fixed)返回固定数量的最高得分变量,而百分位(Percentile)返回选择的前百分比特征。
6.选择随机特征
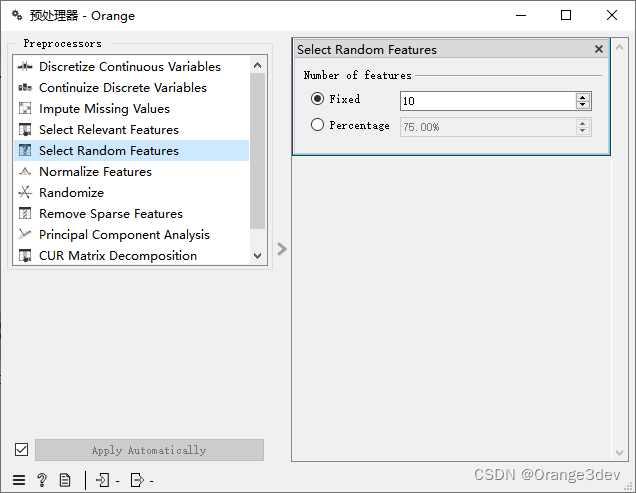
即固定数量或百分比的特征。这主要用于高级测试和教育目的。
7.特征归一化
归一化调整数值到一个共同的尺度。可以通过均值或中位数来居中数据,也可以选择不居中。在缩放方面,可以通过标准差(SD)、跨度(span)或不进行缩放来进行调整。
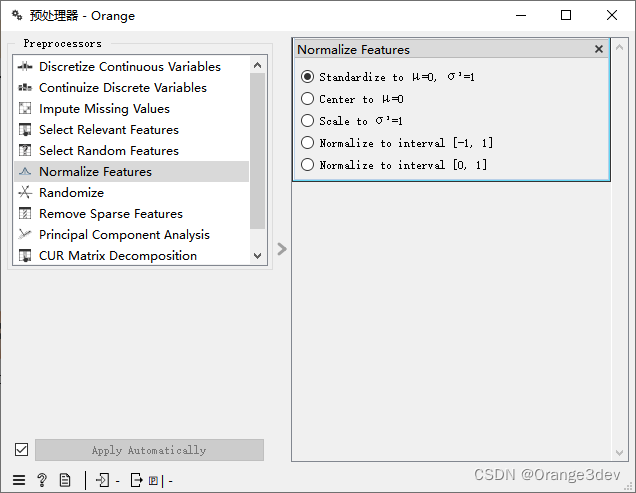
- Standardize to μ=0, σ3 =1代表将特征值标准化为均值为0,标准差为1的尺度。具体而言,对于选择了标准化为均值为0,标准差为1的归一化方式的特征,会对每个特征的数值进行以下操作:
1. 减去该特征的均值(μ=0,使得均值为0);
2. 除以该特征的标准差(σ=1,使得标准差为1)。
- 值为中心的归一化,特征的均值为0,这种方式可以消除特征之间的偏差,并达到将数据集集中在原点附近的效果。
- 将特征值缩放到标准差为1的尺度,将会对每个特征的数值除以该特征的标准差,使得归一化后特征的标准差为1。
- 归一化到区间[-1,1]
- 归一化到区间[0,1]
这种方式将数据转化为服从标准正态分布(均值为0,标准差为1)的形式,可以更好地应用于一些统计模型和机器学习算法,同时消除了特征之间的尺度差异。标准化后的数据有利于提高模型的稳定性和收敛速度,并有助于特征之间的比较和解释。
8.随机化实例
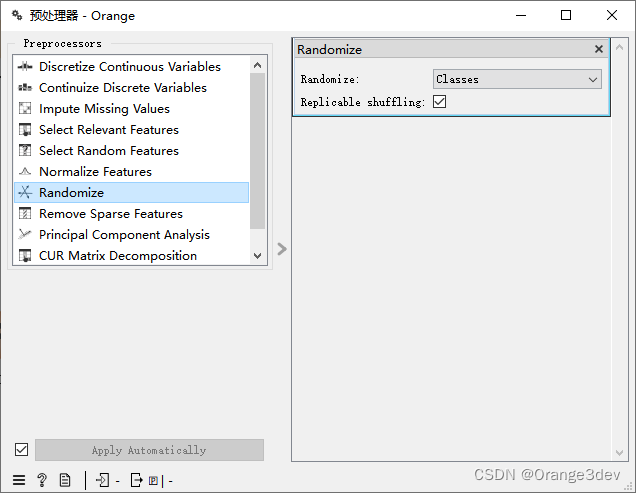
随机化类别(Randomize classes)会打乱类别值,破坏实例与类别之间的联系。同样地,也可以随机化特征或元数据。如果启用了可复制的随机化,随机化结果可以被分享和重复,前提是保存了工作流。这主要用于高级测试和教育目的。
9.移除稀疏特征
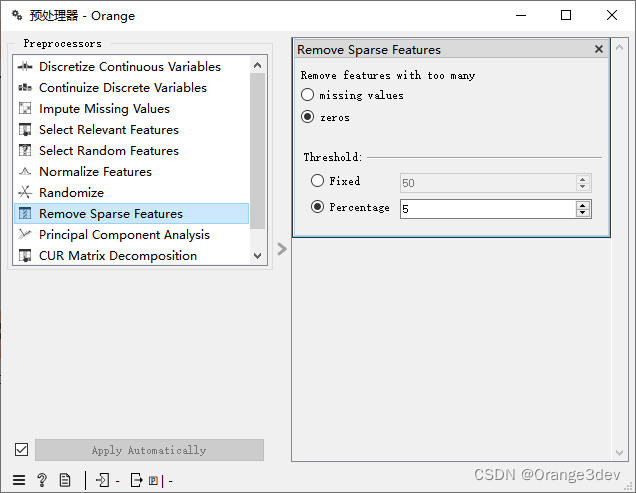
(Remove sparse features)保留那些具有超过某个数量/百分比的非零/缺失值的特征。其余的特征被丢弃。
10.主成分分析
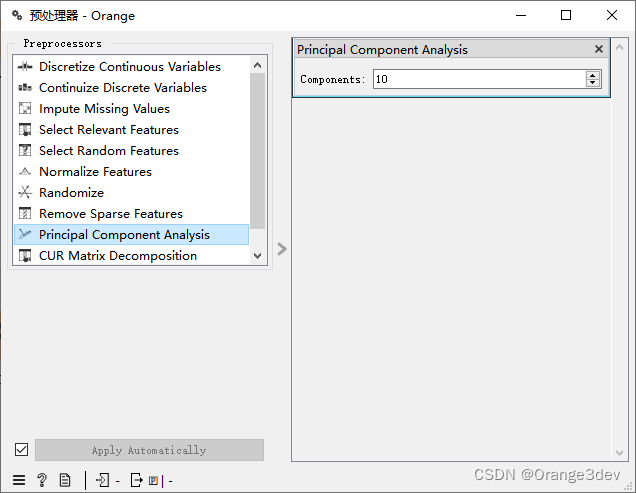
(Principal component analysis)输出主成分分析转换的结果。类似于PCA小部件。
11.CUR矩阵分解
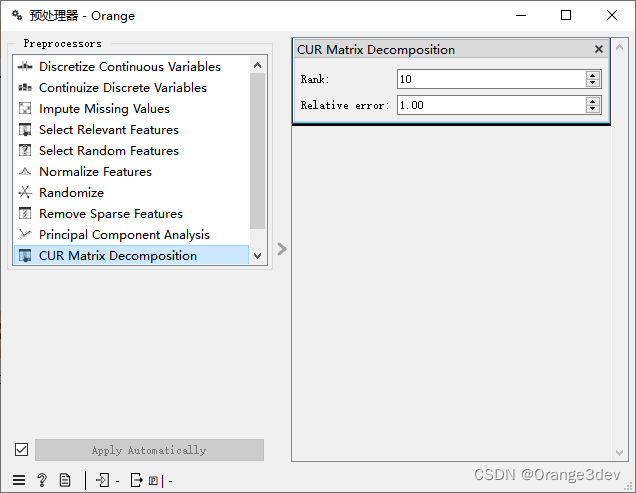
是一种降维方法,类似于奇异值分解(SVD)。
12.视频教程
关注我不迷路, 抖音:Orange3dev
https://www.douyin.com/user/MS4wLjABAAAAicBGZTE2kX2EVHJPe8Ugk3_nlJk9Nha8OZh4Bo_nTu8
1-Orange3安装
2-Orange3汉化DIY
3-Orange3创建快方式
4-数据导入(文件&数据表格组件)
5-数据导入(Python组件)
6-Python库安装(SQL表组件)
7-数据导入(Mysql)
8-数据导入(数据绘画和公式组件)
9-数据修改(域编辑和保存组件)
10-数据可视化(调色板&数据信息组件)
11-数据可视化(特征统计组件)
12-数据预处理(行选择组件)
13-特征选择(Rank组件)
14-数据转换(数据采样组件)
15-数据预处理(列选择组件)
16-数据预处理(转置组件)
17-数据预处理(合并数据组件)
18-数据预处理(连接组件)无主表且列数不同
19-数据预处理(连接组件)主附表
20-数据预处理(索引选择器组件)
21-数据预处理(唯一组件)
22-数据预处理(列聚合组件)
23-数据预处理(分组组件)
24-数据预处理(透视图表组件)
25-数据预处理(转换器组件)-表格互为模板
26-数据预处理(转换器组件)-转换示例
27-数据预处理(预处理器组件)-基本信息
28-数据预处理(预处理器组件)-特征选择
29-数据预处理(预处理器组件)-填充缺失值并标准化特征
30-数据预处理(预处理器组件)-离散化连续变量
31-数据预处理(预处理器组件)-连续化离散变量
32-数据预处理(预处理器组件)-主成分分析PCA与CUR分解
33-数据预处理(缺失值处理组件)
34-数据预处理(连续化组件)
35-数据预处理(离散化组件)
36-数据预处理(随机化组件)
37-数据预处理(清理特征组件)-清理未使用特征值及常量特征
38-数据预处理(宽转窄组件)
39-数据预处理(公式组件)
40-数据预处理(分类器组件)
41-数据预处理(创建实例)
42-数据预处理(Python代码组件)