个人学习笔记。
1 工具介绍
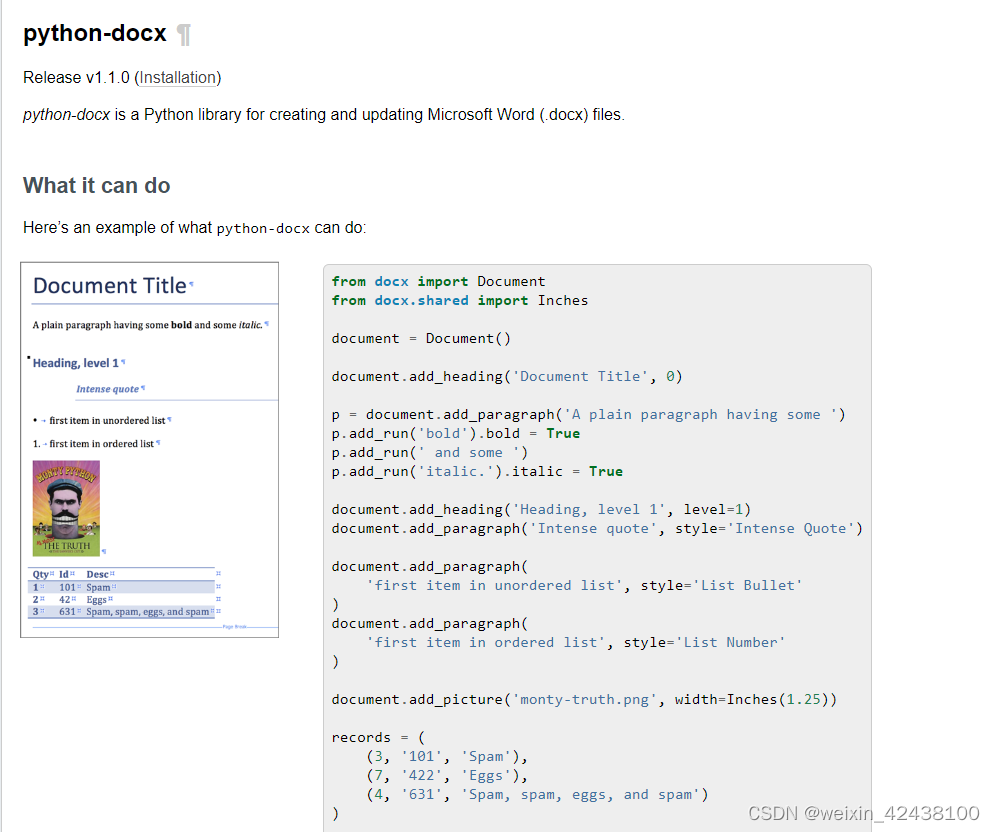
python-docx 是用于创建可修改 微软 Word 的一个 python 库,提供全套的 Word 操作,是最常用的 Word 工具。
1.1 基本概念
- Document:是一个 Word 文档 对象,不同于 VBA 中 Worksheet 的概念,Document 是独立的,打开不同的Word 文档,就会有不同的 Document 对象,相互之间没有影响。
- Paragraph:是段落,一个 Word 文档由多个段落组成,当在文档中输入一个回车键,就会成为新的段落,输入 shift + 回车,不会分段。
- Run: 表示一个节段,每个段落由多个节段组成,一个段落中具有相同样式的连续文本,组成一个节段,所以一个 段落对象有多个 Run 列表。

1.2 对象介绍
此处只列出部分,剩余的部分,见官方文档介绍。
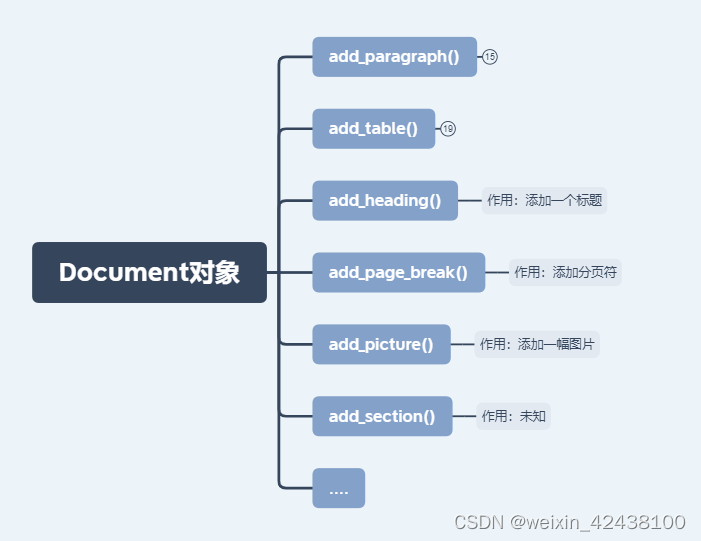
1.2.1 Document objects
整篇word文档的对象,可以对该对象添加标题、段落、表格、图片等信息。
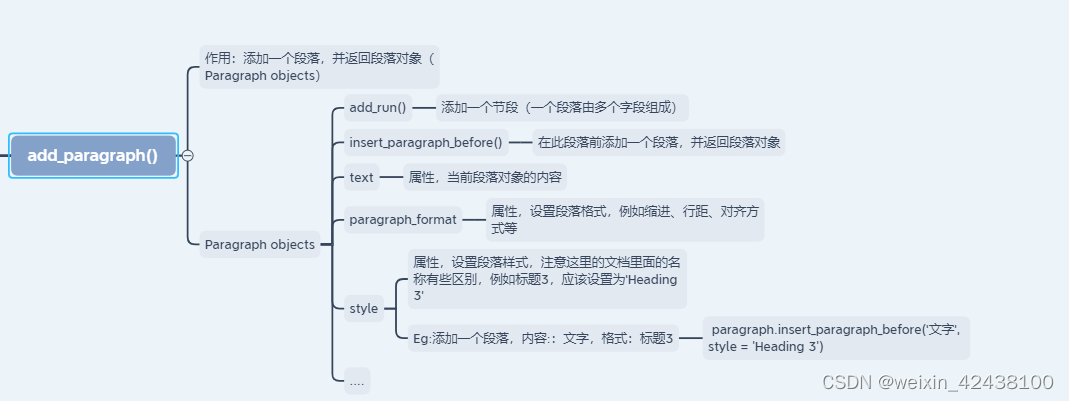
1.2.2 Paragraph objects
段落对象,可以在段落里面添加一个节段、段落前添加一个段落(不支持在后面添加)、设置格式等。
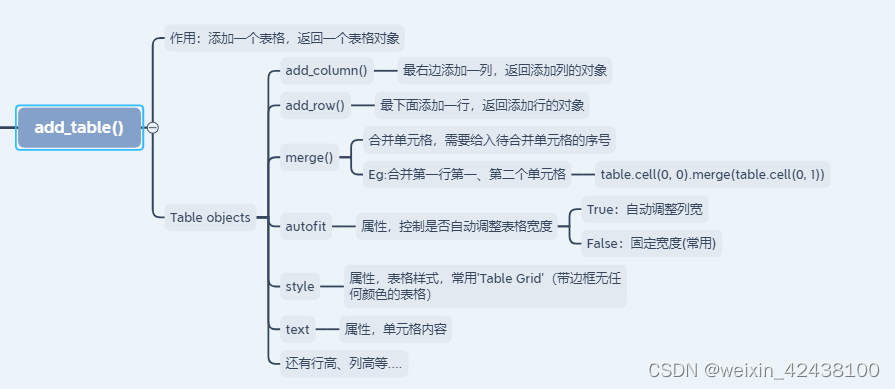
1.2.3 Table objects
表格对象,常规的添加行、列、合并单元格等。
2 实操
实现功能:在word文档的指定位置添加相应的宏定义和函数定义
2.1 准备材料
word文档模板:

备注:
1、需要现在word文档中设置好自动编号(关联到相应标题)
2、相应标题格式(字体颜色、大小等)需要提前调整,脚本只是应用,占时不修改属性
2.2 运行结果

2.3 代码
from docx import Document
from docx.enum.table import WD_ALIGN_VERTICAL # 导入单元格垂直对齐
from docx.shared import Cm, Inches, Pt
import reColumn = 4 # 设置表格列数
# 这里添加表格内容,具体内容后期提取代码或提前PDF文档
EnumInfo = [{'Name': 'Crypto_AlgorithmFamilyType', 'kind': 'Enumeration','Range': [['CRYPTO_ALGOFAM_NOT_SET', '0x00', 'Algorithm family is not set'],['CRYPTO_ALGOFAM_SHA1', '0x01', 'SHA1 hash'],['CRYPTO_ALGOFAM_SHA2_224', '0x01', 'SHA2-224 hash']],'Description': 'Enumeration of the algorithm family.', 'Availablevia': 'Crypto_GeneralTypes.h'},{'Name': 'Crypto_InputOutputRedirectionConfigType', 'kind': 'Enumeration','Range': [['CRYPTO_REDIRECT_CONFIG_PRIMARY_INPUT', '0x01', '--'],['CRYPTO_REDIRECT_CONFIG_SECONDARY_INPUT', '0x02', '--']],'Description': 'Defines which of the input/output parameters are re-directed to a key element. Thevalues can be combined to define a bit field.','Availablevia': 'Crypto_GeneralTypes.h'}]def addEnum(document, paragraph):for type in EnumInfo:paragraph1 = paragraph.insert_paragraph_before(type['Name'], style='Heading 3')lineNumber = 0table1 = document.add_table(4, Column, style='Table Grid') # 添加一个4行4列的表格,表格样式为Table Gridtable1.autofit = Falsetable1.allow_autofit = False# 设置表格宽度table1.columns[0].width = Cm(2)table1.columns[1].width = Cm(4)table1.columns[2].width = Cm(1.5)table1.columns[3].width = Cm(8)# 设置第一行高度为1cmtable1.rows[0].height = Cm(1)# 填充Name信息table1.cell(lineNumber, 0).text = 'Name'table1.cell(lineNumber, 1).merge(table1.cell(lineNumber, 2)).merge(table1.cell(lineNumber, 3))table1.cell(lineNumber, 1).text = type['Name']lineNumber = lineNumber + 1# 填充Kind信息table1.cell(lineNumber, 0).text = 'kind'table1.cell(lineNumber, 1).merge(table1.cell(lineNumber, 2)).merge(table1.cell(lineNumber, 3))table1.cell(lineNumber, 1).text = type['kind']lineNumber = lineNumber + 1# 填充具体的枚举数据for i in range(0, len(type['Range'])):table1.cell(lineNumber + i, 1).text = type['Range'][i][0]table1.cell(lineNumber + i, 2).text = type['Range'][i][1]table1.cell(lineNumber + i, 3).text = type['Range'][i][2]table1.add_row()lineNumber = lineNumber + len(type['Range']) # 计算下一行的索引# 合并第一列表格(枚举相关的行)for i in range(2, lineNumber - 1): # 总共需要合并lineNumber - 1次table1.cell(i, 0).merge(table1.cell(i + 1, 0))table1.cell(2, 0).text = 'Range'table1.cell(2, 0).vertical_alignment = WD_ALIGN_VERTICAL.CENTER # 设置为水平居中# 填充Description、Availablevia信息table1.cell(lineNumber, 0).text = 'Description'table1.cell(lineNumber, 1).merge(table1.cell(lineNumber, 2)).merge(table1.cell(lineNumber, 3))table1.cell(lineNumber, 1).text = type['Description']lineNumber = lineNumber + 1table1.cell(lineNumber, 0).text = 'Availablevia'table1.cell(lineNumber, 1).merge(table1.cell(lineNumber, 2)).merge(table1.cell(lineNumber, 3))table1.cell(lineNumber, 1).text = type['Availablevia']move_table_after(table1, paragraph1) # 移动到段落后面(表格只能创建到文档末尾)
# 函数功能:移动指定表格到段落后面
def move_table_after(table, paragraph): tbl, p = table._tbl, paragraph._pp.addnext(tbl)def main():# 实例化一个Document对象,相当于打开word软件,新建一个空白文件document = Document('test.docx')for paragraph in document.paragraphs:if (paragraph.style.name.startswith('Heading')): # 识别标题,注意:这里是在标题前添加相关信息,若要在枚举章节添加枚举定义,则需要识别下一个章节标题if re.search('函数接口定义', paragraph.text): # 实际是编辑上一个章节“枚举类型定义”的内容passelif re.search('其他', paragraph.text): # 编辑“函数接口定义内容”addEnum(document, paragraph) # 添加枚举类型document.save(f"test.docx")if __name__ == "__main__":main()
3 参考资料
3.1 官方链接
https://python-docx.readthedocs.io/en/latest/index.html#
刚入门可以看该章节快速上手,具体API和对象的熟悉可以看下面的“API Documentation”。
3.2 其他博主
强烈推荐学习此博主的博文,本文部分内容从中摘选。
https://blog.csdn.net/yuetaope/article/details/119444970
4. 其他
Python提取PDF表格(基于AUTOSAR_SWS_CANDriver.pdf