Python使用lxml解析XML格式化数据
- 1. 效果图
- 2. 源代码
- 参考
方法一:无脑读取文件,遇到有关键词的行再去解析获取值
方法二:利用lxml等库,解析格式化数据,批量获取标签及其值
这篇博客介绍第2种办法,以菜鸟教程中的俩个xml文档为例进行解析;
https://www.runoob.com/try/xml/cd_catalog.xml
https://www.runoob.com/try/xml/books.xml
1. 效果图
cd_catalog.xml原始文件如下:
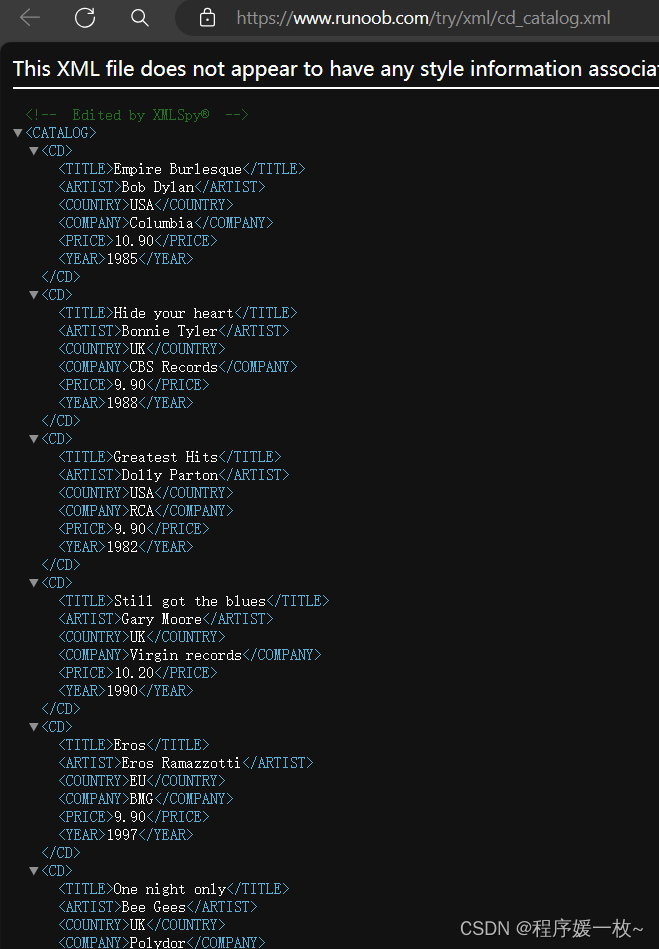
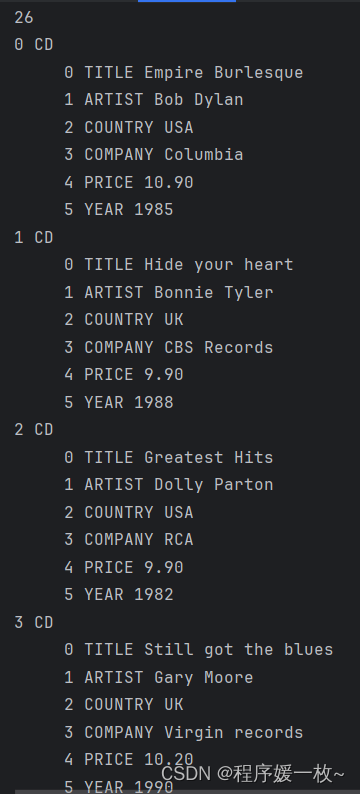
解析cd_catalog.xml后按顺序打印如下:
book.xml原始文件如下:
解析books.xml效果图如下:

2. 源代码
# parseXml.py
# 解析cd_catalog.xml,book.xmlfrom xml.etree import ElementTree as ETdef readBookXml(file):# 直接读取xml文件,形成ElementTree结构tree = ET.parse(file)root = tree.getroot() # 获取根元素for i, child in enumerate(root): # 遍历子元素print(i, child.tag, child.text, child.attrib) # 输出子元素的标签和属性值for j in range(len(child)):print('\t', j, child[j].tag, child[j].text, child[j].attrib) # 输出子元素中的标签及属性值# 获取XML文档的根元素root = tree.getroot()# 查找具有指定标签的第一个子元素element = root.find('book')# 查找具有指定标签的所有子元素books = root.findall('book')print(len(books))for i, book in enumerate(books):print(i, book.tag, book.text, book.attrib) # 输出子元素的标签和属性值for j in range(len(book)):print('\t', j, book[j].tag, book[j].text, book[j].attrib) # 输出子元素中的标签及属性值def readCatalogXml(file):# 直接读取xml文件,形成ElementTree结构tree = ET.parse(file)root = tree.getroot() # 获取根元素for i, child in enumerate(root): # 遍历子元素print(i, child.tag, child.text, child.attrib) # 输出子元素的标签和属性值for j in range(len(child)):print('\t', j, child[j].tag, child[j].text, child[j].attrib) # 输出子元素中的标签及属性值# 获取XML文档的根元素root = tree.getroot()# 查找具有指定标签的第一个子元素element = root.find('CD')# 查找具有指定标签的所有子元素books = root.findall('CD')print(len(books))for i, book in enumerate(books):print(i, book.tag) # 输出子元素的标签for j in range(len(book)):print('\t', j, book[j].tag, book[j].text) # 输出子元素中的标签及属性值file = 'test/books.xml'
readBookXml(file)file = 'test/cd_catalog.xml'
readCatalogXml(file)
参考
- https://blog.csdn.net/qq233325332/article/details/130799948
- https://blog.csdn.net/weixin_43856625/article/details/134775566