原文链接:最新基于R语言lavaan结构方程模型(SEM)技术![]() https://mp.weixin.qq.com/s?__biz=MzUzNTczMDMxMg==&mid=2247596681&idx=4&sn=08753dd4d3e7bc492d750c0f06bba1b2&chksm=fa823b6ecdf5b278ca0b94213391b5a222d1776743609cd3d14bfbddf2623795f0a8edadf4e6&token=20152544&lang=zh_CN#rd
https://mp.weixin.qq.com/s?__biz=MzUzNTczMDMxMg==&mid=2247596681&idx=4&sn=08753dd4d3e7bc492d750c0f06bba1b2&chksm=fa823b6ecdf5b278ca0b94213391b5a222d1776743609cd3d14bfbddf2623795f0a8edadf4e6&token=20152544&lang=zh_CN#rd
前沿
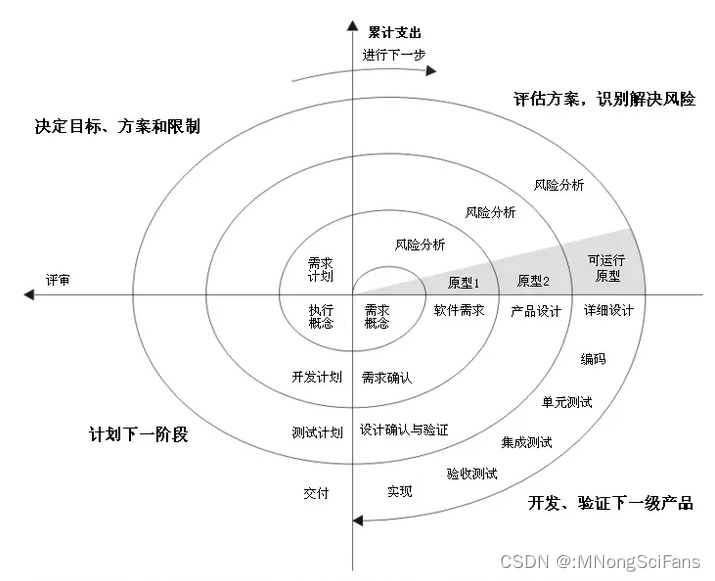
结构方程模型(Sructural Equation Modeling,SEM)是分析系统内变量间的相互关系的利器,可通过图形化方式清晰展示系统中多变量因果关系网,具有强大的数据分析功能和广泛的适用性,是近年来生态、进化、环境、地学、医学、社会、经济等众多领域应用十分广泛的统计方法。在R语言结构方程程序包中,lavaan具有简洁的语法结构、成熟模型构建和调整过程和稳定可靠的结果等特点,使其不亚于收费商业软件,是最受欢迎的结构方程模型程序包之一。
一:R/Rstudio及入门
1)R及Rstudio介绍:背景、软件及程序包安装、基本设置等
2)R语言基本操作,包括向量、矩阵、数据框及数据列表等生成和数据提取等
3)R语言数据文件读取、整理(清洗)、结果存储等(含tidverse)
4)R语言基础绘图(含ggplot):基本绘图、排版、发表质量绘图输出存储

二:结构方程模型(SEM)
1)SEM的定义、生态学领域应用及历史回顾
2)SEM的基本结构
3)SEM的估计方法
4)SEM的路径规则
5)SEM路径参数的含义
6)SEM分析样本量及模型可识别规则
7)SEM构建基本流程

三: lavaan包讲解及应用案例
1)结构方程模型在生态学研究中的应用及要点回顾
2)lavaan简介、语法及结构方程模型分析入门
1)lavaan结构方程模型构建应用案例
(1)问题提出、元模型构建
(2)模型构建及模型估计
(3)模型调整:路径删减和增加原则
(4)模型评估:最优模型筛选
(5)结果表达

四:lavaan潜变量分析
1)潜变量的定义、优势及应用背景分析
2)潜变量分析lavaan实现基本原理
3)案例1:单潜变量模型构建
4)案例2:多个潜变量模型构建

五:lavaan复合变量(composite)分析
1)复合变量的定义及在生态学领域应用情景分析
2)复合变量分析lavaan实现途径
3)案例1:单复合变量构建
4)案例2:多复合变量构建

六:lavaan处理非线性/非正态/缺失数据
1)非线性数据:外生变量及内生变量非线性关系
2)变量间交互作用关系分析
3)非正态数据vs非正态变量分析
4)缺失数据处理方法

七:lavaan分类变量分析
1)分类变量介绍
2)外生变量为分类变量分析
3)内生变量为分类变量分析

八:lavaan分组数据(multigroup)分析
1)分组数据vs分类变量vs交互作用
2)数据分组分析实现途径
3)二分组及多分组模型分析及结果表达
4)包含潜变量模型分组分析

九:lavaan嵌套/分层/多水平数据分析
1)嵌套/多水平/分层数据
2)嵌套/多水平/分层数据结构结方程模型实现途径:lavaan vs lavaan.survey
3)均衡和不均衡结构嵌套/多水平/分层数据结构方程实例
4)嵌套/多水平/分层数据潜变量模型

十:lavaan重复测量和时间数据分析
1)时间重复测量数据特点
2)时间/重复测量数据的交叉滞后模型(Autoregressive Cross-Lagged Model)
3)时间/重复测量数据的生长曲线模型(Growth Curve Model)

十一:lavaan空间自相关数据分析
1)数据空间自相关
2)lavaan处理空间自相关数据基本原理
3)lavaan处理空间自相关问题实例

十二:lavaan非递归模型分析
1)递归模型与非递归模型区别
2)lavaan非递归模型分析注意事项及实现途径
3)lavaan非递归模型案例