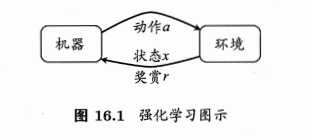
在强化学习中,智能体通过与环境的交互来学习如何做出决策。在每个时间步,智能体观察当前的环境状态,并根据其策略选择一个动作。环境会对智能体的动作做出响应,并给出一个奖励信号(reward),该信号反映了智能体当前动作的好坏。智能体的目标是通过学习找到一种策略,使得在长期的交互过程中获得的累计奖励最大化。
1.K摇臂赌博机
在K摇臂赌博机问题中,每个“摇臂”代表一个可能的动作,拉动摇臂会获得一个与这个动作相关联的奖励。奖励可能是固定的,也可能是随机的。智能体的目标是通过多次尝试来找到哪个摇臂(动作)平均而言能够产生最大的奖励,即找到最优的动作。
(1)ε-贪婪策略
ε-贪婪策略的核心思想是在强化学习中实现探索和利用之间的平衡。它确保智能体在寻找最优策略的过程中,既不会完全依赖于当前已知的最佳信息(利用),也不会完全随机地选择动作(探索),而是结合两者,以一定的概率进行探索和利用。
具体来说,该策略以一定的概率ε进行探索,即随机选择一个动作,而以1-ε的概率进行利用,即选择当前已知的最优动作。通过这种方式,智能体可以在探索新动作以获取更多信息的同时,也能利用已有知识选择当前最优的动作,从而实现探索和利用的平衡。
在实际应用中,ε的值通常会根据时间步长逐渐减小,以便在初期更多地探索新动作,而在后期则更多地利用已知的最优动作。这种策略简单而有效,被广泛应用于各种强化学习任务中。
(2)SoftMax策略
SoftMax策略的核心思想是根据每个动作可能带来的收益,为其分配一个选择概率,从而实现探索和利用之间的平衡。与ε-贪婪策略相比,Softmax策略在选择动作时考虑了所有可能动作的价值,并以一种更平滑的方式进行了探索和利用的权衡。
具体操作如下:
-
对于每一个时间步,智能体需要根据当前的状态来选择一个动作。在Softmax策略中,每个动作a都被赋予一个选择概率p(a),这个概率是由该动作的价值Q(a)(或者称为动作的优势、期望收益等)通过一个Softmax函数计算得到的。
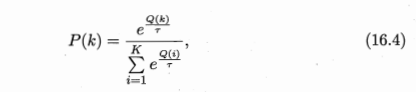
其中T是一个称为“温度”的参数,它控制着概率分布的形态。当T较大时,概率分布较为均匀,智能体更倾向于进行探索;当T较小时,概率分布则更为集中,智能体更倾向于利用当前价值较高的动作。
-
智能体根据这些概率随机地选择一个动作执行。这样,即使某个动作的价值明显高于其他动作,智能体也不会总是确定地选择它,而是有一定的概率尝试其他动作,从而实现了探索。
-
在执行动作并接收到环境的反馈(即奖励信号)后,智能体会更新其对动作价值的估计。这通常是通过一些强化学习算法(如Q-learning、SARSA等)来完成的。
- 随着时间的推移和智能体对环境了解的加深,动作的价值估计将越来越准确。同时,可以通过逐渐降低温度参数T来使智能体从初期的广泛探索逐渐过渡到后期的精确利用。
想象你站在一个有很多条路的交叉路口,每条路都可能导致不同的结果,但你不知道哪条路是最好的。这时,你就面临一个探索和利用的问题:你应该尝试新的路(探索),还是选择你已经知道比较好的那条路(利用)?
ε-贪婪策略就是一种解决这个问题的方法。它告诉你,大部分时间(比如95%的时间,如果ε设为0.05)你应该选择那条你已经知道比较好的路(利用),但是偶尔(比如剩下的5%的时间)你也应该尝试一下新的路(探索),说不定你会发现更好的路。
而Softmax策略则是另一种方法。它不像ε-贪婪策略那样直接选择已知最好的路或者完全随机选择一条路,而是根据每条路可能的好处(或者叫“价值”)来决定选择每条路的概率。如果一条路的好处远远大于其他路,那么选择这条路的概率就会非常高;如果所有路的好处都差不多,那么选择每条路的概率就会比较平均。
2.有模型学习
有模型学习与之前提到的无模型学习(如ε-贪婪策略和Softmax策略)在强化学习中的主要区别在于是否对环境进行建模。有模型学习的核心思想是构建一个表示环境行为的模型,并利用这个模型来优化智能体的决策过程。
(1) 策略评估 (Policy Evaluation)
在有模型学习中,策略评估的目的是估计给定策略下的状态值函数或状态-动作值函数。这意味着对于每个状态(或在状态-动作对中),我们想要知道遵循当前策略时能获得多少预期回报。这通常通过求解模型的贝尔曼方程来完成,可以使用动态规划方法,如高斯-赛德尔迭代。
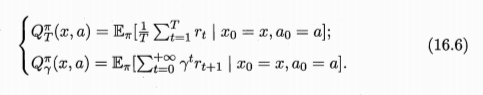
(2)策略改进 (Policy Improvement)
一旦我们有了策略的值函数评估,我们就可以尝试改进它。策略改进的目标是找到一个新的策略,它在所有状态下都不比原策略差,并且至少在一个状态上比原策略更好。这通常是通过贪心选择动作来实现的,即在每个状态下选择使状态-动作值函数最大的动作。
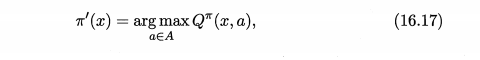
(3)策略迭代 (Policy Iteration)
策略迭代是结合了策略评估和策略改进的一种方法。它交替进行策略评估和策略改进,直到找到最优策略为止。具体来说,我们从一个初始策略开始,评估它,然后找到一个改进的策略,再评估新策略,如此往复。每次迭代后,策略都会变得更好,直到收敛到最优策略。
(4)值迭代 (Value Iteration)
值迭代是另一种找到最优策略的方法。与策略迭代不同,值迭代并不显式地维护一个策略。相反,它直接对最优值函数进行迭代更新。在每次迭代中,它使用贝尔曼最优方程来更新每个状态的最优值,直到值函数收敛。一旦最优值函数被找到,就可以通过贪心选择动作来得到最优策略。
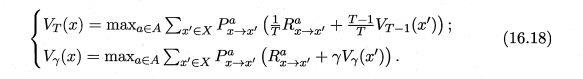
3.免模型学习
免模型学习(Model-Free Learning)是强化学习中的一种方法,与有模型学习相对。在免模型学习中,智能体不尝试对环境进行建模,而是直接通过与环境的交互来学习如何最大化累积奖励。这意味着智能体不依赖于对环境行为的预测,而是根据实际观察到的奖励和状态转移来优化其策略。
免模型学习的核心思想是通过试错(trial-and-error)的方式来学习最优策略。智能体在环境中执行动作,观察结果,并根据观察到的奖励来调整其策略。这种方法不依赖于对环境的内部工作机制的理解,而是直接关注于智能体的行为和结果。
(1)蒙特卡罗强化学习
蒙特卡罗强化学习的核心思想是通过采样来估计状态的真实价值。它直接从经历过的完整状态序列中学习,而不依赖于环境模型。每个状态的价值被估计为在多个状态序列中以该状态算得到的所有收获的平均值。这种方法不依赖于状态转移概率,因此被称为免模型方法。蒙特卡罗强化学习使用广义策略迭代框架,通过策略评估和策略改进两个步骤交互进行,直至获得最优策略。
(2)时序差分强化学习:
时序差分强化学习的核心思想是结合动态规划和蒙特卡罗方法的思想,利用经验来解决强化学习问题。与蒙特卡罗方法相似,时序差分方法也是从采样中学习,不需要知道完整的环境模型。但是,时序差分方法不需要等到完整的状态序列结束后再进行更新,而是可以在每个步骤之后立即更新估计值。这是通过结合当前步骤的奖励和下一个状态的估计值来实现的。时序差分方法可以在不完整的样本序列上进行学习,因此具有更高的学习效率。此外,它还可以在连续的任务中进行在线学习,而不需要等待任务结束。
4.值函数近似
在实际应用中,许多问题的状态空间或动作空间可能非常大,甚至无限,这使得传统的表格型强化学习方法(如Q-Learning、SARSA等)无法有效地处理。为了解决这个问题,值函数近似方法被引入到强化学习中。
值函数近似的核心思想是使用一个参数化的函数来近似表示状态值函数或状态-动作值函数。这个参数化的函数可以是一个线性函数、神经网络、决策树、最近邻方法等。通过调整函数的参数,我们可以拟合真实的状态值函数或状态-动作值函数,从而实现对大规模状态空间或动作空间的有效处理。
在实际应用中,值函数近似方法通常需要与一些强化学习算法结合使用,如梯度下降法、策略梯度法等。这些算法可以根据值函数近似的结果来更新策略或调整函数的参数,以实现更好的学习效果。
5.模仿学习
模仿学习(Imitation Learning)是一种通过观察专家行为来学习策略的方法,它属于强化学习的一个子领域。在模仿学习中,智能体通过观察专家的行为示例来学习,旨在将专家的经验知识转化为自身的行为策略,以实现快速且高效的学习。
模仿学习主要有两种方法:直接模仿学习和逆强化学习。
(1)直接模仿学习(Behavior Cloning):
直接模仿学习,也被称为行为克隆,是一种简单直接的模仿学习方法。它的基本思想是使用一个模型来直接从给定的一组专家数据中学习。这实际上是传统的监督学习方法。具体地说,通过收集专家在不同状态下的行为数据(即状态-动作对),可以利用监督学习算法(如神经网络)来训练一个模型,使其能够根据输入的状态预测出相应的动作。然而,直接模仿学习通常面临数据缺失的问题,即在某些状态下缺乏专家的行为数据,导致模型无法充分学习。
(2)逆强化学习(Inverse Reinforcement Learning):
逆强化学习是一种更为复杂和灵活的模仿学习方法。与直接模仿学习不同,逆强化学习的目标不仅仅是学习专家的行为,还要推断出专家行为背后的潜在奖励函数。通过找到这个奖励函数,智能体可以使用强化学习的方法来学习策略,即使在没有直接观察到奖励的情况下也能学习。这种方法不仅模仿专家的行为,还理解专家行为背后的动机和目标,因此具有更高的灵活性和泛化能力。然而,逆强化学习的计算复杂度通常较高,需要更多的计算资源和时间。