论文地址:Depth Completion with Twin Surface Extrapolation at Occlusion Boundaries
论文代码:https://github.com/imransai/TWISE
深度补全是从稀疏的已知深度值开始,为其余图像像素估计未知深度。
大多数方法将其建模为深度插值,并错误地将深度像素插值到空白区域,导致深度在遮挡边界处模糊问题。
深度补全的两个挑战,这两个挑战可能相互矛盾。第一个挑战是在对象内插值缺失的像素深度,利用附近的稀疏深度信息。第二个挑战是准确地找到对象的遮挡边界,并确保插值的像素属于前景或背景对象。
论文提出一种多假设深度表示,明确地对难以处理的遮挡边界区域中的前景和背景深度进行建模。该方法可以被看作是在这些区域中执行双表面外推,而不是插值。
方法称为双曲面估计(TWISE),而不是使用多个通道进行分拆,它使用了一个更有效的双曲面表示,并可以通过发现双曲面深度之间的差异来显式地建模模糊性。
为了训练双曲面估计器,论文提出了一对非对称损失函数,可以自然地将估计结果偏向前景和背景深度表面。损失函数中的非对称性是实现在模糊像素处分离前景和背景深度的关键。还加入了一个融合通道,自动将前景和背景深度组合成每个像素的最终深度估计,通过在模糊区域选择前景/背景深度,在非模糊区域混合两个深度。
方法
论文将深度补全分为两个较为简单的问题,每个问题都可以更容易地由网络学习。
第一个问题是深度插值,而无需确定边界。 与估计单个表面不同,关键创新在于估计双曲面。前景表面将前景对象的深度外推到边界之前和之后,而背景表面将背景深度外推到遮挡对象的后面。
第二个问题是找到边界,并通过融合这两个表面确定单个深度。 发现彩色图像在辅助表面融合方面特别有用。

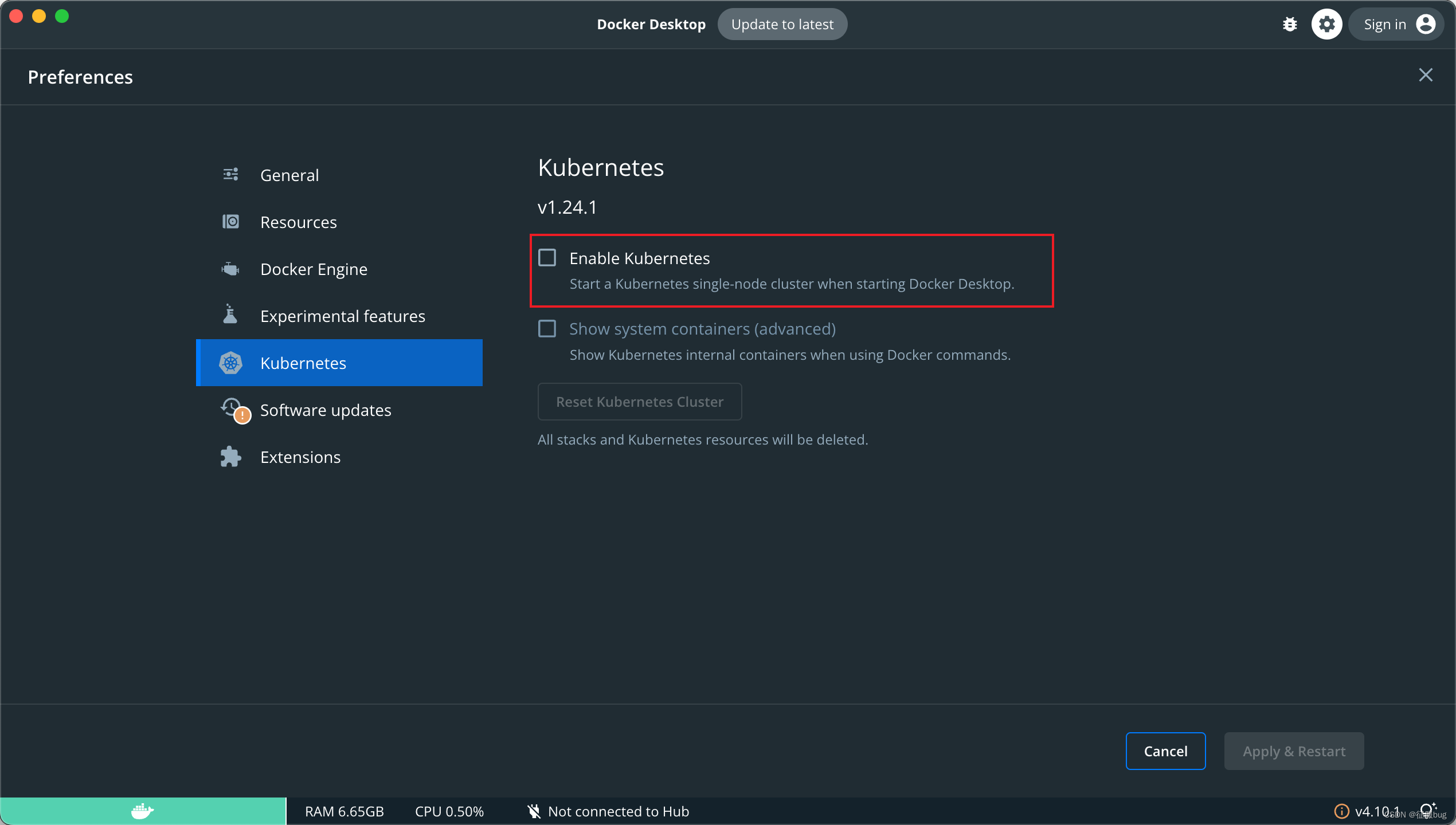
上图为深度模糊出现在边界上。我们展示了地面实况深度(用红色标出)与图像重叠(a),SoTA方法估计的深度(b),论文融合的深度(c),论文估计的权重σ(d);SoTA的深度切片(e)论文的融合深度和σ切片(f),以及前景和背景切片(g)。在(g)中的外推能力导致(f)中的清晰深度边界,而不是(e)中的模糊深度。
模糊和期望损失
模糊对深度完成有很大的影响,有一个定量的方法来评估它们的影响是很有用的。论文提出使用期望损失来预测和解释歧义对已训练网络的影响。
所谓模糊,并不是指不存在唯一真实解,而是指在给定测量数据的情况下,算法和/或人类很难在两个或更多个不同的解决方案之间做出决定。
模糊可以更正式地定义如下:给定对场景的稀疏采样的测量数据,模糊的数量等于可能生成稀疏测量的不同真实场景的数量,也就是在论文的情况下,可能生成稀疏测量的不同真实深度图的数量。这个数量取决于实际数据中出现的变化。为了简化,论文独立地处理每个像素的模糊,因此对于一个像素来说,模糊是其可能的深度值,这些深度值与测量数据一致。
预期在不同场景中模糊的程度会有所不同。平面上的像素会很好地受到附近像素的约束,具有较低的模糊性。相比之下,接近深度不连续点的像素可能有很大的深度模糊。通常没有足够的深度图像数据来决定像素是在前景还是在背景上。
对应的彩色图像可以帮助解决像素属于前景还是在背景的模糊。
对于一个像素,要估计其深度 d d d , 假设这个像素有一对模糊集 d i d_i di , 每个模糊具有概率 p i p_i pi。这个概率度量了在模拟的场景假设下,地面真值将采取相应深度的可能性有多大。
现在考虑一个关于每个像素的误差的损失函数 L ( d − d t ) L(d-d_t) L(d−dt),其中 d t d_t dt 是地面真实深度。期望损失作为深度的函数为: E { L ( d ) } = ∑ i p i L ( d − d i ) . (1) \tag1 E\{L(d)\}=\sum_i p_i L (d-d_i). E{L(d)}=i∑piL(d−di).(1)这个期望损失很重要,因为如果一个网络是在代表性数据上训练的,那么它将被训练到最小化期望损失。通过检查期望损失,可以预测网络在模糊情况下的行为。
非对称线性误差
论文使用了一对误差函数:非对称线性误差(ALE)和反射非对称线性误差(RALE): A L E γ ( ϵ ) = max ( − 1 γ ϵ , γ ϵ ) (2) \tag2 ALE_\gamma(\epsilon)=\max (- \frac{1}{\gamma}\epsilon,\gamma \epsilon) ALEγ(ϵ)=max(−γ1ϵ,γϵ)(2) R A L E γ ( ϵ ) = max ( 1 γ ϵ , − γ ϵ ) (3) \tag3 RALE_\gamma(\epsilon)=\max ( \frac{1}{\gamma}\epsilon,- \gamma \epsilon) RALEγ(ϵ)=max(γ1ϵ,−γϵ)(3)
这里 ϵ \epsilon ϵ 是测量值和地面真值之间的差, γ γ γ 是参数, m a x ( a , b ) max(a,b) max(a,b)返回 a a a 和 b b b 中较大的一个。 ALE 和 RALE 是绝对误差的推广,与 γ = 1 γ=1 γ=1 时的绝对误差相同。
不同之处在于ALE的负侧以 1 / γ 1/γ 1/γ 加权,正侧以 γ γ γ 加权。 RALE 只是 ALE 在 ε = 0 ε=0 ε=0 线上的反射。
 ( a ) 公式(2)中的反射式非对称线性误差(ALE)在原点处的最小值是非对称的。
( a ) 公式(2)中的反射式非对称线性误差(ALE)在原点处的最小值是非对称的。
( b ) 公式(3)中的反射式非对称线性误差(RALE)是 ALE 的镜像。我们在前景表面估计中使用 ALE,而在背景估计中使用RALE。
( c ) 一个像素深度用两个不确定性深度 d 1 d1 d1 和 d 2 d2 d2 表示,并分别对应概率 p1 和 p2。
黑线表示 ALE 的期望,它是两个 ALE 函数的概率加权和。 ALE 的期望将在 d 1 d1 d1 和 d 2 d2 d2 出现的标记角之一处具有最小值。
需要注意的是,如果 γ γ γ 被 1 / γ 1/γ 1/γ 代替, A L E ALE ALE 和 R A L E RALE RALE 都被反射。 因此,在不丧失一般性的情况下,论文文对 γ ≥ 1 γ≥1 γ≥1 加以限制。
前景和背景估计器
二元模糊性由分别具有深度 d 1 d1 d1 和 d 2 d2 d2 的概率 p 1 p1 p1 和 p 2 p2 p2 的像素来描述。 当 d 1 < d 2 d1<d2 d1<d2 时,我们称 d 1 d1 d1 为前景深度, d 2 d2 d2 为背景深度。 这样的二元模糊性很可能发生在物体边界深度不连续点附近。
为了估计前景深度,提出了最小化所有像素的平均 ALE 来得到估计的前景面 d ^ 1 \hat d_1 d^1,为了从一个训练过的模糊像素的网络中预测 d ^ 1 \hat d_1 d^1 的特征,我们检验了预期的 ALE,如上图( c )所示。这是分段线性的,有两个角,一个在 d 1 d_1 d1,另一个在 d 2 d_2 d2。其中较小的一个将决定最小期望损失,并因此决定了理想网络的预测。
使用公式(2)和(1),可以获得期望损失: L ( d 1 ) = p 2 ( d 2 − d 1 ) / γ , L ( d 2 ) = p 1 ( d 2 − d 1 ) γ L(d_1)=p_2(d_2-d_1)/ \gamma,L(d_2)=p_1(d_2-d_1)\gamma L(d1)=p2(d2−d1)/γ,L(d2)=p1(d2−d1)γ。从这里可以很简单地看到, γ > p 2 p 1 (4) \tag 4 \gamma>\sqrt {\frac {p_2}{p_1}} γ>p1p2(4) 在上述条件下, L ( d 1 ) < L ( d 2 ) L(d_1)<L(d_2) L(d1)<L(d2) 成立。这个方程表明了前景估计器对 γ γ γ 的灵敏度; γ γ γ 越高,在前景深度 d 1 d_1 d1 处最小所需的前景 p 1 p_1 p1 上的概率越低。
为了估计边界处的背景深度 d ^ 2 \hat d_2 d^2,论文提出了最小化期望 RALE。这里与 ALE 分析类似,得到与公式(4)中相同的 γ γ γ 约束,只是概率比率被颠倒了。
图1(b)是一个前景深度估计示例,(c)是背景深度,(f)是深度差异。我们观察到,在远离深度不连续性的像素以及稀疏的输入深度像素中,前景深度非常接近背景深度,表明没有歧义。
融合深度估计器
前景和背景深度估计为每个像素提供深度的下界和上界。 将最终的融合深度估计器 d ^ t \hat d_t d^t 表示为真实深度 d t d_t dt 的加权组合: d ^ t = σ d ^ 1 + ( 1 − σ ) d ^ 2 (5) \tag 5 \hat d_t = \sigma \hat d_1 + (1-\sigma)\hat d_2 d^t=σd^1+(1−σ)d^2(5)其中 σ σ σ 是介于 0 和 1 之间的估计值。 使用平均绝对误差作为融合损失的一部分: F ( σ ) = ∣ d ^ t − d t ∣ = ∣ σ d ^ 1 + ( 1 − σ ) d ^ 2 − d t ∣ . (6) \tag 6 F(\sigma) = |\hat d_t - d_t|=|\sigma\hat d_1+(1-\sigma)\hat d_2 - d_t|. F(σ)=∣d^t−dt∣=∣σd^1+(1−σ)d^2−dt∣.(6)预期损失为: L e ( σ ) = E { F ( σ ) } = p ∣ σ d ^ 1 + ( 1 − σ ) d ^ 2 − d 1 ∣ + ( 1 − p ) ∣ σ d ^ 1 + ( 1 − σ ) d ^ 2 − d 2 ∣ . (7) \tag 7 L_e(\sigma) = E\{F(\sigma)\} = p|\sigma \hat d_1 + (1- \sigma)\hat d_2 - d_1|+(1-p)|\sigma \hat d_1 +(1-\sigma)\hat d_2 - d_2|. Le(σ)=E{F(σ)}=p∣σd^1+(1−σ)d^2−d1∣+(1−p)∣σd^1+(1−σ)d^2−d2∣.(7) 这里, p = p 1 p =p_1 p=p1, p 2 = 1 − p p_2=1-p p2=1−p。 当 p > 0.5 p>0.5 p>0.5 时,在 σ = 1 σ=1 σ=1 处有一个最小值;当 p < 0.5 p<0.5 p<0.5 时,在 σ = 0 σ=0 σ=0 处有一个最小值,这假定深度为 d 1 d_1 d1 或 d 2 d_2 d2。
深度面表示
将所有的损失函数组合成一个单一的损失: L ( c 1 , c 2 , c 3 ) = 1 N ∑ j N ( A L E γ ( c 1 j ) + R A L E γ ( c 2 j ) + F ( s ( c 3 j ) ) ) . (8) \tag 8 L(c_1,c_2,c_3) = \frac 1 N \sum_j^N(ALE_\gamma(c_{1j})+RALE_\gamma(c_{2j})+F(s(c_{3j}))). L(c1,c2,c3)=N1j∑N(ALEγ(c1j)+RALEγ(c2j)+F(s(c3j))).(8)这里 c i j {c_ij} cij 是指通道 i i i 的像素 j j j, s ( ) s() s() 是 sigmoid 函数,并且取所有 n n n 个像素的平均值。论文将训练网络的这三个通道的输出解释为 c 1 → d ^ 1 c_1 \to \hat d_1 c1→d^1, c 2 → d 2 ^ c_2 \to \hat{ d_2} c2→d2^, s ( c 3 ) → σ s(c_3) \to \sigma s(c3)→σ,并把它们结合起来,就像在公式(5)中获得每个像素的深度估计器 d ^ t \hat d_t d^t 一样。
使用3个通道进行多尺度监督。总损失是多分辨率损失Li的加权和,其中 L 1 L_1 L1 是公式(8)中的全分辨率 3 通道损失, L 2 L_2 L2 是半分辨率损失, L 3 L_3 L3 是四分之一分辨率损失: L = ω 1 L 1 + ω 2 L 2 + ω 3 L 3 L = ω_1L_1 + ω_2L_2 + ω_3L_3 L=ω1L1+ω2L2+ω3L3
总结
在物体之间或者物体的前景与背景之间存在遮挡关系。这会导致深度图在遮挡边界处出现不连续的情况,从而影响深度估计的准确性。论文提出了TWISE,一种新的用于深度图像的双曲面表示和估计方法,旨在解决遮挡边界处的深度估计问题。
通过建模前景和背景的双曲面来估计深度。在遮挡边界处,前景双曲面外推前景物体的深度,背景双曲面外推背景的深度,从而在遮挡区域更准确地估计深度。提出了非对称损失函数,即 ALE 和 RALE,将这些双曲面估计偏向于具有深度模糊的前景和背景像素。论文输出的第三个通道融合了这些估计,以实现单一的表面估计。这个解决方案简化了学习深度不连续性的任务,因此更好地维持了边界上的逐步深度不连续性,并生成了SOTA深度估计。
与传统深度补全相比:
1.双曲面外推方法: 本方法使用双曲面外推来处理深度补全问题。具体而言,它通过建模前景和背景的双曲面,分别在遮挡区域外推前景物体和背景的深度。这种方法能够更好地处理遮挡边界处的深度估计,提高深度图的连续性和准确性。
2.非对称损失函数: 该方法引入了一种非对称损失函数,用于训练网络进行深度估计和融合。这种损失函数有助于在深度估计中区分前景和背景深度,从而更好地处理遮挡问题。
3.连续性和准确性: 传统的深度补全方法可能在遮挡边界处出现深度不连续或估计不准确的问题。而这种双曲面外推方法能够更好地保持深度图的连续性,并提高深度估计的准确性,特别是在遮挡边界处。
4.任务目标: 传统的深度补全方法可能更注重插值技术或使用传统的回归方法来估计深度。而这种方法则专注于处理遮挡问题,通过外推来估计遮挡边界处的深度,从而更适用于处理需要考虑物体遮挡情况的场景。
可能存在的问题: 由于地面真实像素的稀疏性,远处深度像素估计的学习会受到限制。