写在前面
本文看下es聚合的原理,以及精准度相关的问题。
1:分布式系统近似统计算法
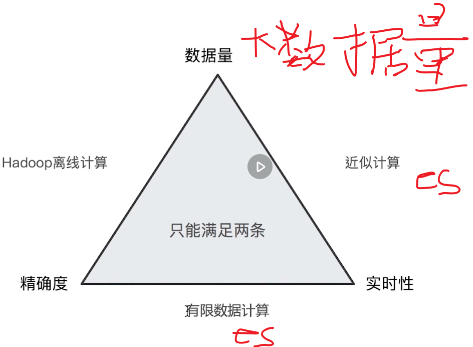
万物都有其内在的规律和限制,如CAP,我们无法设计一个系统同时满足所有的因素,在分布式的计算中也是如此,它也有3个因素:
1:大数据量
2:实时性
3:准确性
以上3个因素,只能满足其中的两个,即如果你需要大数据量下的实时性就会牺牲掉准确性(es),需要大数据量下的准确性就会牺牲掉实时性(Hadoop)
,需要实时性和准确性的话只能牺牲掉大数据量(只能小数据量)。
本文我们要分析es精准度问题,就属于牺牲掉准确性的场景。
1:metric min是准确的吗?
想要弄清楚metric min是否是存在精准度的问题,需要先来看下min的执行过程,这里我们假定number_of_shard=3 :
1:请求到达coordinate node,coordinate node随机选择三个分片获取min数据
2:每个分片根据本分片的数据计算得到min结果,并将结果发送给coordinate node
3:coordinate node执行min(分片1结果,分片2结果,分片3结果),获取最终的结果
如下图:

其实可以很容看出来,每个分片返回的min中最小的那个min,肯定是整个数据集的min,所以metric min是准确的。
2:term agg是准确的吗?
想要弄清楚term agg是否是存在精准度的问题,需要先来看下term的执行过程,这里我们假定number_of_shard=3 ,然后获取top 3:
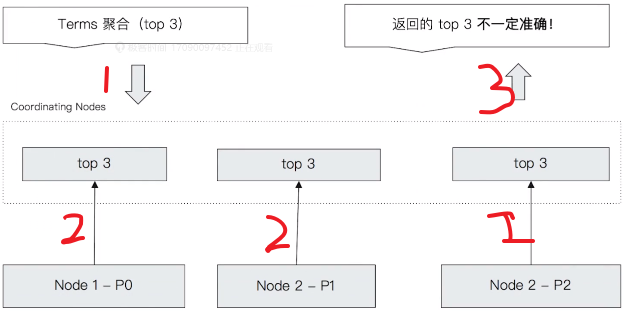
1:请求到达coordinate node,coordinate node随机选择三个分片获取term count数据
2:每个分片,分别对自己的数据,按照term进行分组,并对term count的结果,按照降序排序,并将自己的top 3返回给coordinate node
3:coordinate node收集每个分片的top 3,再对相同的term加在一起,得到总的最终的term count的top 3,作为最终的结果
以上的这个过程是可能有问题的,参考下图:
错误例子如下:
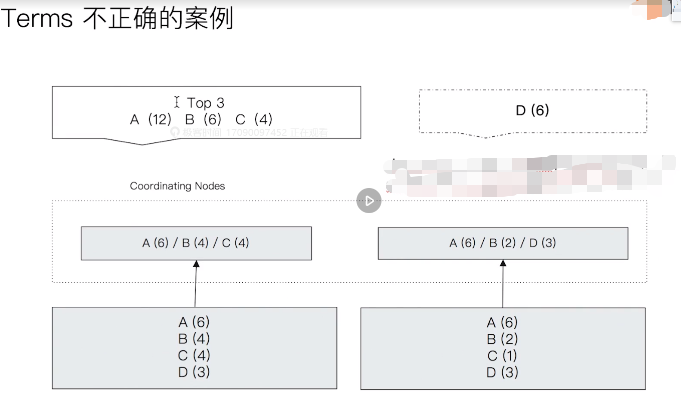
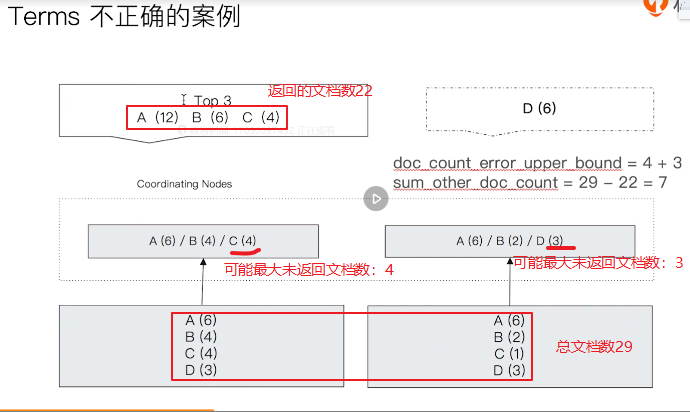
最终正确的结果应该是:A(12),B(6),D(6)。这里出错的根本原因是只返回了top 3。es为了表述这里返回的结果是否正确,在返回的结果中增加了doc_count_error_upper_bound和sum_other_doc_count,含义如下:
doc_count_error_upper_bound:被遗漏的文档中可能包含的最大的文档数
sum_other_doc_count:没有返回的term的文档的总数
以上的错误例子中,左侧的分片返回的结果是A(6)/B(4)/C(4),因为返回的最小的,所以其可能的最大的未返回文档数是4(最大等于4),同理右侧返回的是A(6)/B(2)/D(3),所以其可能未返回的最大文档数是3,所以例子中的doc_count_error_upper_bound=4+3,sum_other_doc_count就比较简单了,总文档数是(A(6)+B(4)+C(4)+D(3)+A(6)+B(2)+C(1)+D(3)=29),而返回的文档总数是(A(12)+B(6)+C(4)=22),所以
,sum_other_doc_count=29-22=7,如下图:
es为了解决这个问题,提供了参数shard_size,来设置执行term时从每个分片获取top 几,默认是size*1.5 + 10,通过调大该参数到一定的小可解决问题,另外如果是num_of_shards设置为1也可以解决问题。具体如下图:

为了加深理解,我们来看一个具体的例子。
2.1:具体实例
数据准备参考这篇文章 。
- 创建索引
DELETE my_flights
PUT my_flights
{"settings": {"number_of_shards": 20},"mappings" : {"properties" : {"AvgTicketPrice" : {"type" : "float"},"Cancelled" : {"type" : "boolean"},"Carrier" : {"type" : "keyword"},"Dest" : {"type" : "keyword"},"DestAirportID" : {"type" : "keyword"},"DestCityName" : {"type" : "keyword"},"DestCountry" : {"type" : "keyword"},"DestLocation" : {"type" : "geo_point"},"DestRegion" : {"type" : "keyword"},"DestWeather" : {"type" : "keyword"},"DistanceKilometers" : {"type" : "float"},"DistanceMiles" : {"type" : "float"},"FlightDelay" : {"type" : "boolean"},"FlightDelayMin" : {"type" : "integer"},"FlightDelayType" : {"type" : "keyword"},"FlightNum" : {"type" : "keyword"},"FlightTimeHour" : {"type" : "keyword"},"FlightTimeMin" : {"type" : "float"},"Origin" : {"type" : "keyword"},"OriginAirportID" : {"type" : "keyword"},"OriginCityName" : {"type" : "keyword"},"OriginCountry" : {"type" : "keyword"},"OriginLocation" : {"type" : "geo_point"},"OriginRegion" : {"type" : "keyword"},"OriginWeather" : {"type" : "keyword"},"dayOfWeek" : {"type" : "integer"},"timestamp" : {"type" : "date"}}}
}
- reindex kibana_sample_data_flights数据到创建的索引
POST _reindex
{"source": {"index": "kibana_sample_data_flights"},"dest": {"index": "my_flights"}
}
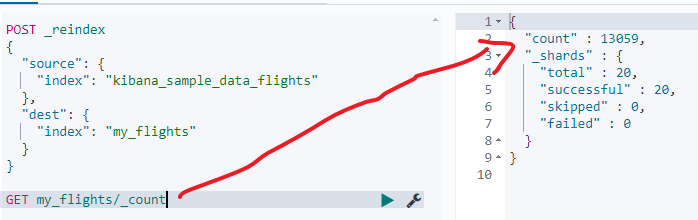
- 查询kibana_sample_data_flights
GET kibana_sample_data_flights/_search
{"size": 0,"aggs": {"weather": {"terms": {"field":"OriginWeather","size":5}}}
}
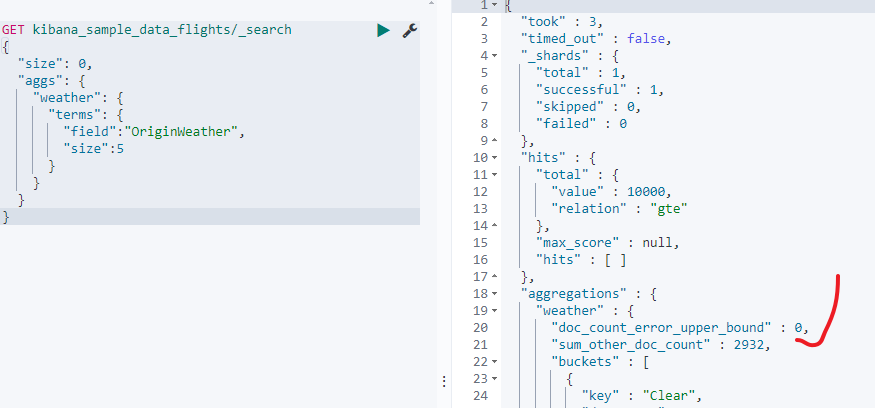
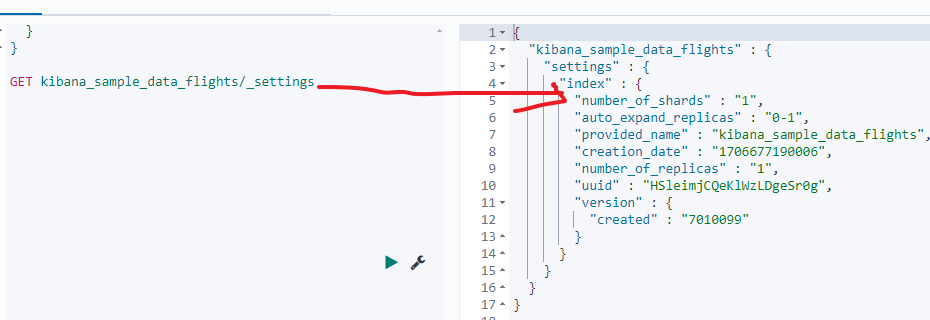
可以看到"doc_count_error_upper_bound" : 0说明结果是准确的,这是因为es7默认的主分片数就是1,如下图:
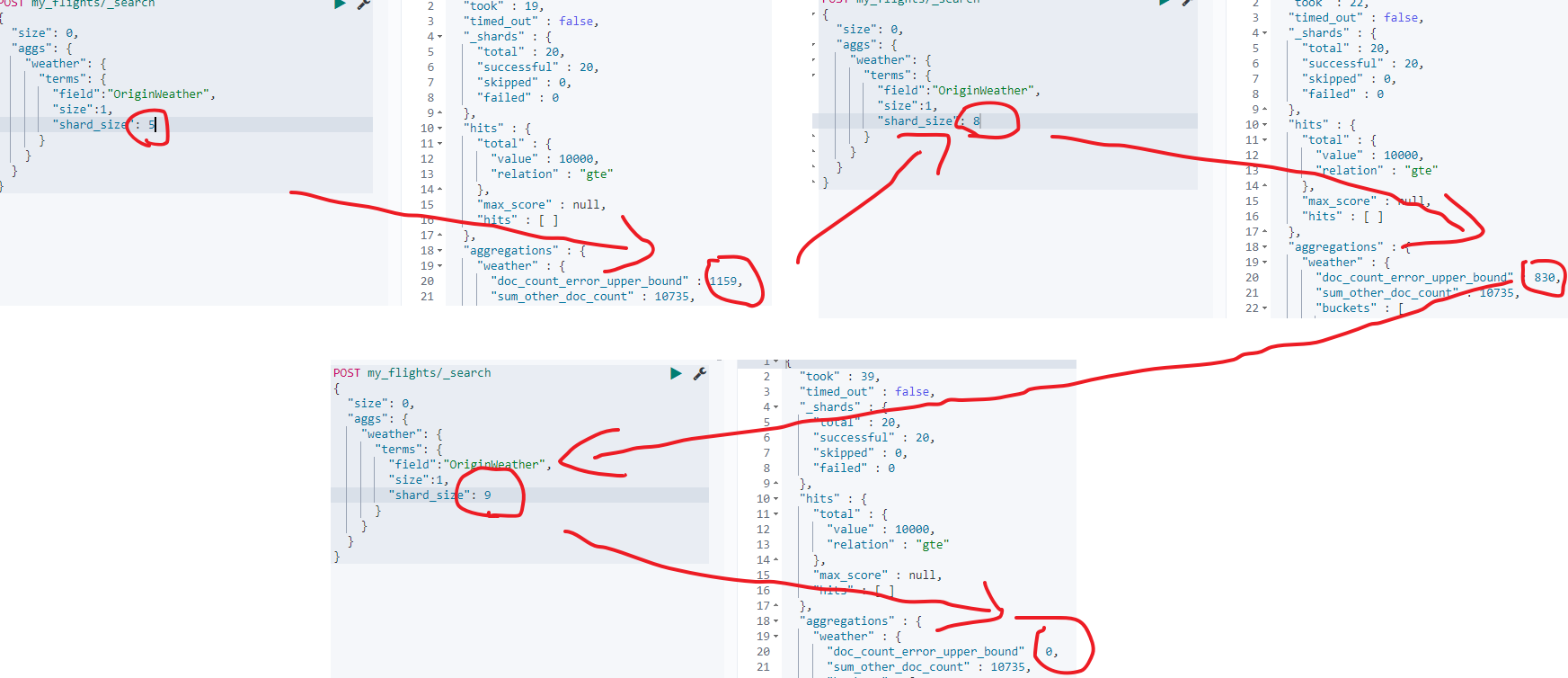
但是我们创建的索引my_flights设置的主分片数是20,所以如果是基于我们创建的索引来查询doc_count_error_upper_bound的值就大于0了,此时解决就可能是不准确的了(注意是可能准确,也可能是对的,当然如果是该值等于0,则肯定是正确的):
POST my_flights/_search
{"size": 0,"aggs": {"weather": {"terms": {"field":"OriginWeather","size":1,"shard_size": 1}}}
}
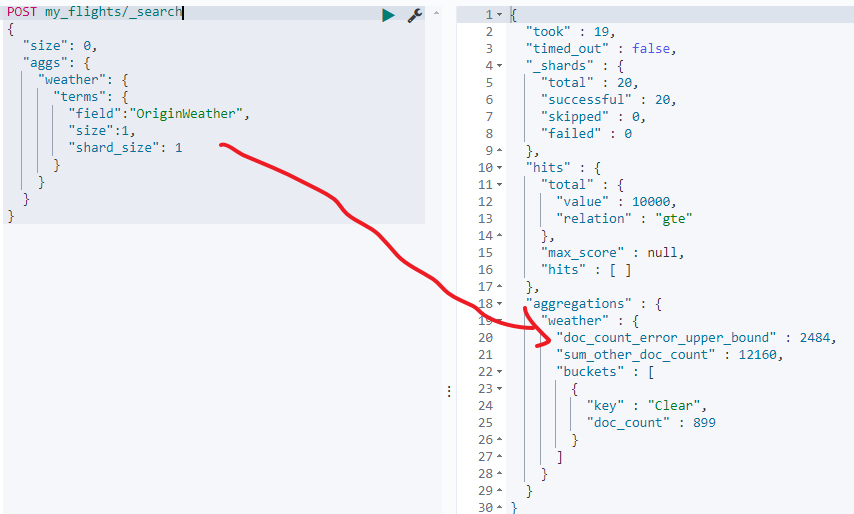
我们来尝试调大shard_size的值,此时doc_count_error_upper_bound的值会越来越小,直到为0:
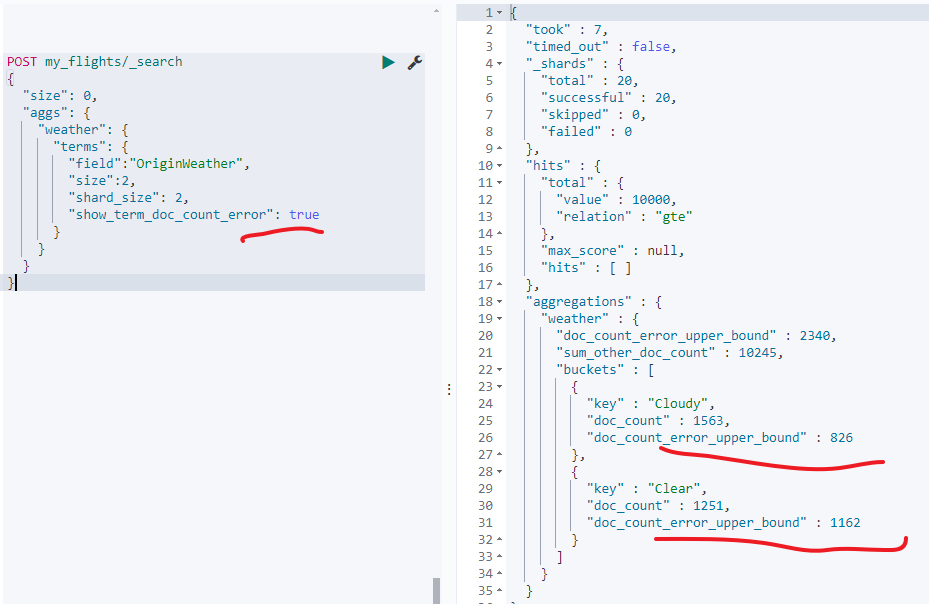
另外还可以通过增加参数show_term_doc_count_error:true来查看每个桶的最大可能误差数,但是不提清楚这个数是怎么计算的,如下:
写在后面
参考文章列表
用Elasticsearch做Terms聚合计算数据不准的问题 。