细粒度分析:AI是如何一步步审视你的健康记录的?
- 提出背景
- AS-LLM 整体框架
- 关联分析
提出背景
论文:https://arxiv.org/pdf/2403.01002.pdf
代码:https://github.com/microsoft/attribute-structuring/
临床总结在医疗领域有特定的含义,它通常是指医生对患者在医院治疗过程中的全面记录,包括诊断、治疗、患者反应和治疗结果等。
是对患者住院期间发生的一系列医疗活动的总结描述,一般在患者出院时提供给患者和家属,用于传达治疗过程、结果及后续的护理指导。
医生们通常很忙,他们需要快速理解病人的医疗记录。
自动将这些记录总结成简短的摘要可以节省时间,但是要确保这些摘要既准确又有用,评估它们是个挑战。
问题:我们如何确保这些自动生成的医疗摘要既详细又准确,同时又不需要太多人工检查?
解决方案:我们提出使用大型语言模型来帮助评估摘要,通过一种称为属性结构化(AS)的方法。
-
属性结构化:就是将总结评估分解成几个小步骤,每一步只关注摘要的一部分信息。
想象一下,就像你用清单来检查东西是否齐全一样。
-
提示评分:我们不是直接让语言模型给出整体评分,而是让它看看摘要里的每个重点信息是否和参考摘要相匹配,然后分别给分。
-
使用临床本体:我们有一个医学上的参考清单,列出了一个好的摘要应该包含的所有关键点,这样评分就更有目标,更可信。
就是我们用一个分步骤的方法来评估摘要,这样就更容易确保每部分都是正确的,而不是一股脑儿地试图评估整个摘要的好坏。
这种方法让评估更准确,也便于之后检查和理解评分的依据。
传统方法:
- 假设我们有一个完整的医疗记录摘要,我们让一个医生阅读它,并给出一个整体评价,比如从1到10分评估它的准确性和完整性。
- 医生需要一次性考虑所有的信息,这可能会错过一些细节,因为有些错误可能会在大量信息中被忽视。
- 如果摘要很长,这个过程可能非常耗时,并且最后给出的分数可能不容易解释,因为它基于整体印象。
属性结构化方法:
- 我们有同样的医疗记录摘要,但这次我们不是让医生整体评估。
- 相反,我们使用一个大型语言模型,根据预先定义的医疗术语列表(我们的本体)来检查摘要。
- 每一个术语(如“入院诊断”,“治疗过程”等)都会被单独比较和评分,以确保摘要中的信息与原始记录匹配。
- 这个方法让我们可以对每一部分的准确性进行精细的评估。
- 例如,如果原始记录中提到“病人有高血压”的历史,但摘要中漏掉了这一点,这个细节就会在这个评估步骤中被发现并记录下来。
在属性结构化方法中,我们得到的是一系列详细的评分,而不是一个总分。
这些评分让我们明确知道哪些方面做得好,哪些方面需要改进。
这种方法的优势在于它为每个关键点提供了明确的评估和可追踪的证据,从而在详细程度和透明度上超越了传统的评估方法。
AS-LLM 整体框架
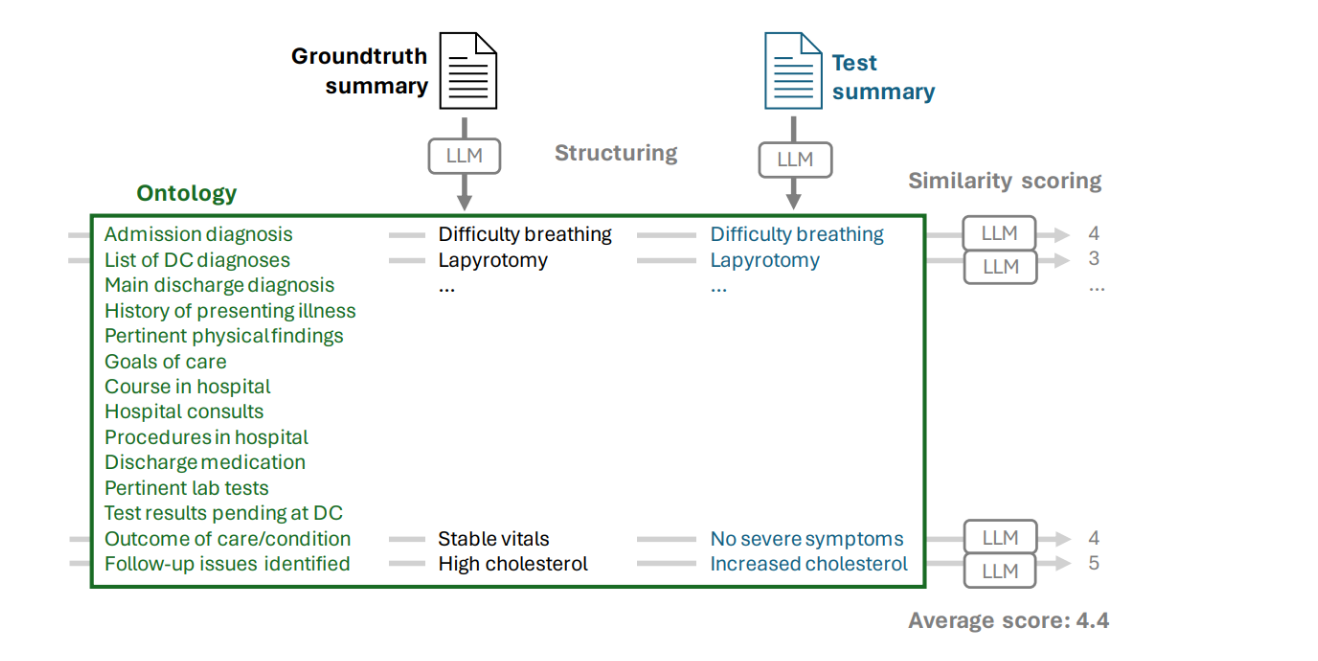
这个框架通过使用人类给出的本体来提取摘要中的属性,然后对这些属性进行单独评分。
框架分为以下步骤:
-
本体(Ontology):列出了评估时考虑的各种临床属性,例如“入院诊断”、“出院时主要诊断”、“病情史”、“重要的体格检查结果”等。
-
结构化(Structuring):使用LLM和上述本体结构化地从“真实摘要”和“测试摘要”中提取对应的属性。
-
相似性评分(Similarity scoring):对从两个摘要中提取的每对属性进行评分,以确定它们之间的相似性。
例如,“Difficulty breathing” (呼吸困难)这一属性在两个摘要中都被提及,因此LLM对它们的相似性进行评分。
-
平均分(Average score):通过对每对属性评分的相加并计算平均值,得出一个总体的评估分数。
在这个例子中,平均得分是4.4分。
图中还显示了一些具体属性的对比,如真实摘要中的“Follow-up issues identified”属性中提到了“High cholesterol”(高胆固醇),而测试摘要中提到了“Increased cholesterol”(胆固醇增高)。
这些细节有助于LLM为这对属性打分,并计入总体评估中。
通过组合这些子解法,属性结构化(AS)方法提供了一种精细、可解释、并与人类评价者高度一致的方式来评估自动生成的临床出院总结的质量。

实验结果:
- AS改进了与人工注释相符的程度,特别是GPT-4在皮尔逊和斯皮尔曼相关系数上与人类评分的一致性接近了人类注释者之间的平均一致性。
- 不同的LLM(如GPT-4和GPT-3.5)在AS评估框架下的性能不同,其中GPT-4表现最佳。
关联分析
属性结构化(Attribute Structuring, AS)这种设计思路在很多方面与计算机科学和信息检索领域的索引和查询处理相似。
- 逐个分析和打分临床摘要中的关键医疗信息
在这些领域中,大量的信息需要被组织、索引并有效地查询。
属性结构化通过将信息细分为更小的、可管理的单元(即属性),与索引结构在数据库中对数据进行分解和优化检索的方法有共通之处。
多题一解的特征:
- 需要从大量数据中提取关键信息。
- 信息需要按照一定的结构或标准来组织。
- 要求对信息进行定量评估和比较。
- 对于信息的理解和分析需要透明和可解释。
共用解法名字:
- 该解法可以称为“模块化评估”或“细粒度评估”。
使用这种解法的题目:
- 任何需要从复杂或非结构化数据中提取关键信息进行比较和评估的情况。
- 当需要在多个不同的系统或模型间进行性能比较时。
- 如果要确保评估的过程是可解释的,并且可以明确每一部分对最终结果的贡献。
在临床总结的评估中,这种方法特别有用,因为它可以详细地分析和评价每一个临床属性,确保生成的摘要是全面和准确的。
这种细粒度的方法也便于后续的审查和改进,因为每个属性的评分都是透明的,可以追溯。
为什么研究者使用不同LLM评分,也不使用机器学习算法(如决策树、SVM等)?
- 准确性:SVM可能在某些结构化的属性评估上比GPT-4更准确,特别是当属性与特定的诊断代码或治疗结果有直接关联时。
- 一致性:SVM可能不如LLMs能够捕捉到语言的微妙差异,可能导致与人类注释者的一致性降低。
- 解释性:LLMs可以提供基于自然语言的解释,而SVM的决策边界和支持向量不那么直观,可能需要额外的步骤来解释评分原因。
- 可复制性:使用SVM可能降低模型的可复制性,因为它通常需要手动选择和调整特征,而LLMs可以自动处理大量的自然语言数据。