原文地址:https://arxiv.org/abs/2105.11120
摘要
现代深度神经网络在测试数据和训练数据的不同分布下进行评估时,存在性能下降的问题。领域泛化旨在通过从多个源领域学习可转移的知识,从而泛化到未知的目标领域,从而解决这一问题。本文提出了一种新的基于傅里叶的域泛化视角。主要假设是傅里叶相位信息包含高级语义<1>,不容易受到域移位的影响。为了迫使模型捕获相位信息,我们开发了一种新的基于傅立叶的数据增强策略,称为振幅混合,它在两个图像的振幅谱之间线性插值。在原始图像和增强图像的预测之间进一步引入了一种称为co-teacher正则化的双形式一致性损失。在三个基准上进行的大量实验表明,所提出的方法能够达到最先进的领域泛化性能。
【注】<1>在深度学习中,语义(semantics)主要指代数据背后的概念、类别和关联关系。它是对数据结构化表征的理解,这种表征能够揭示数据中所蕴含的意义和信息。具体来说,语义可以从以下几个方面理解:
- 数据与意义的联系:数据本身没有内在的意义,它们只是符号或数值。当给定数据一个具体的上下文或含义时,它才能被理解为有用的信息。这个上下文或含义就是数据的“语义”。
- 数据的多层次表达:数据可以被视为具有多个层次的语义表达。例如,在图像处理中,图像的语义可以分为视觉层、对象层和概念层。视觉层包括颜色、纹理和形状等基础特征;对象层可能包含属性特征,描述了某一对象的特定状态;概念层则是最接近人类理解和认知的信息。
- 从数据到语义空间的映射:在深度学习中,构建模型的过程可以看作是从原始数据空间到语义空间的一个映射过程。这个映射旨在捕捉数据中的概念类别、关联关系等语义信息。
- 综上所述,深度学习中的语义关注的是数据背后所代表的现实世界中的概念及其相互关系,它是数据在特定领域的解释和逻辑表示。通过这种方式,机器学习和人工智能系统能够在不依赖于人工标签的情况下,理解并生成与人类认知相符的复杂概念和行为。
1. Introduction
在过去的几年里,深度学习在各种任务上取得了巨大的进步。在训练和测试数据共享相同分布的假设下,深度神经网络(dnn)在广泛的应用中显示出巨大的前景[19,11,13]。然而,dnn对于分布外数据的泛化能力很差。这种由分布移位(又称域移位)引起的性能退化会损害dnn的应用,因为在现实中,训练和测试数据通常来自不同的分布。
为了解决领域转移问题,领域自适应(DA)利用一些标记或未标记的目标数据在源领域和特定目标领域之间架起桥梁。然而DA方法在训练期间无法泛化到尚未见过的目标领域。从每个可能的目标领域收集数据并使用每个源-目标对训练数据处理模型是昂贵且不切实际的。因此,提出了一个更具挑战性但更实际的问题设置,即域泛化(DG)[30,21]。与数据分析不同,DG旨在训练具有多个源域的模型,这些源域可以推广到任意未知的目标域。为了解决DG问题,许多现有的方法利用对抗性训练[25,24,39]、元学习[22,1,26,4]、自监督学习[2]或域增强[45,38,52,53]技术,并显示出令人满意的结果。
在本文中,我们介绍了一种新的基于傅立叶的角度DG。我们的动机来自傅里叶变换的一个众所周知的特性:傅里叶频谱的相位分量保留了原始信号的高级语义,而幅度分量包含低级统计信息[33,34,36,12]。为了更好地理解,我们在图1中给出了仅从幅度信息和仅从相位信息重建的图像以及对应的原始图像的示例。如图1(c)所示,纯相位重建揭示了重要的视觉结构,从中可以很容易地识别出原始图像中传达的“房子”。另一方面,很难从图1(b)中的仅振幅重建中分辨出确切的对象。
图1:仅振幅和仅相位重构的示例:(a)原始图像;(B)通过将相位分量设置为常数而仅具有振幅信息的重构图像;(c)通过将振幅分量设置为常数而仅具有相位信息的重构图像。

根据这些观察,Yang等人[49]最近开发了一种基于傅立叶的DA方法。他们提出了一种简单的图像平移策略,即用随机目标图像的幅度谱代替源图像的幅度谱。通过简单地对幅值转换后的源图像进行训练,他们的方法取得了显着的表现。
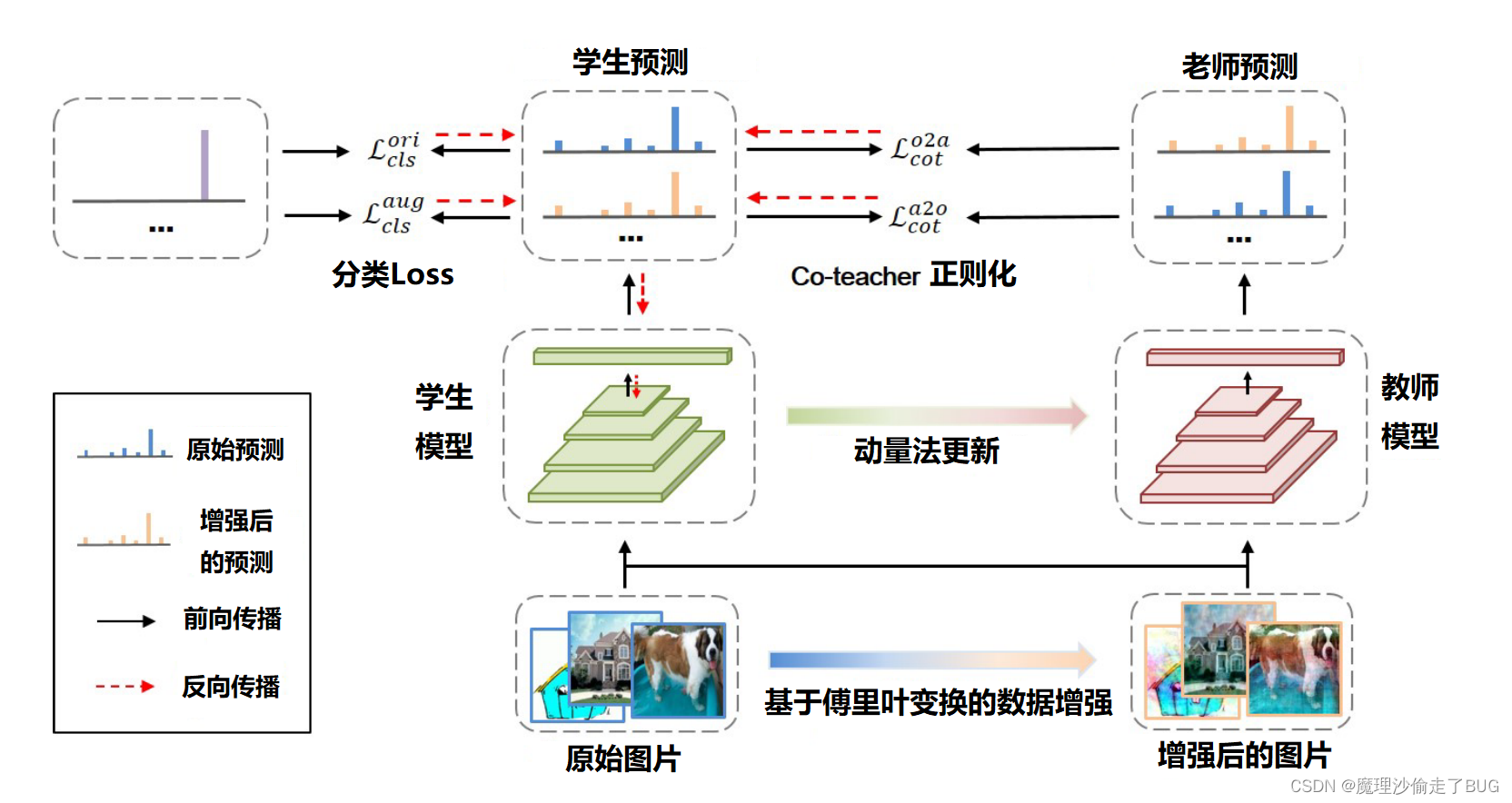
受上述工作的启发,我们进一步探索了基于傅立叶的域泛化方法,并引入了傅立叶增强的Co-Teacher(FACT)框架,该框架由基于傅立叶的数据增强引起的隐式约束和Co-Teacher正则化方面的显式约束组成,如图2所示。
图2:
文中所提出的FACT框架。我们的框架包含两个关键组件,即基于傅立叶的数据增强和co-teacher正则化,以粗体突出显示。原始数据和增强数据都被发送到学生模型和动量更新的教师模型。然后,co-teacher正则化在来自原始数据和增强数据的预测之间施加双重一致性。请注意,在反向传播过程中,教师模型的参数不会更新。
1)基于傅立叶的数据增强。由于已知相位信息携带定义对象的基本特征,因此可以合理地假设,通过从相位信息中学习更多,模型可以更好地提取对域偏移具有鲁棒性的不同对象的语义概念。然而,当处理DG时,我们无法访问目标域,因此[49]中的幅度转移策略不适用。为了克服这一点,我们建议通过扭曲幅度信息来增加训练数据,同时保持相位信息不变。具体而言,采用类似于MixUp <2>[51]的线性插值策略来生成增强图像。
【注】<2>MixUp线性插值
但不是整个图像,而是仅图像的幅度被混合。通过这种基于傅立叶的数据增强,我们的模型可以避免过拟合到振幅信息中携带的低级别统计信息,从而在决策时更加关注相位信息。2)Co-teacher正则化。除了上述基于傅立叶的数据增强引起的隐式约束外,我们还引入了一个显式约束,以迫使模型保持原始图像与其幅度扰动对应图像之间的预测类关系。这个显式约束以配备动量更新教师的双一致性正则化的形式设计[42]。通过Co-teacher正则化,该模型进一步约束为专注于不变的相位信息,以最小化原始图像和增强图像之间的预测差异。
我们在三个领域推广基准上验证了FACT的有效性,即Digits-DG [52],PACS [21]和DigitalHome [43]。大量的实验结果表明,FACT在推广到未知领域的能力方面优于几种最先进的DG方法,这表明从相位信息中学习更多确实有助于模型更好地跨领域推广。我们进一步进行详细的消融研究,以显示我们的框架设计的优越性。我们还对我们的假设和方法背后的理论基础进行了深入的分析,这表明相位信息中的视觉结构包含了丰富的语义,我们的模型可以有效地从中学习。
2. Related Work
领域泛化:领域泛化(DG)的目的是从多个源领域中提取知识,以便很好地泛化到任意未知的目标领域。早期的DG研究主要遵循域自适应中的分布对齐思想,通过内核方法[30,10]或域对抗学习[25,24,39]学习域不变特征。后来,Li等人。[22]提出了一种Meta学习方法,该方法通过反向传播在每次迭代时从源域中分离的随机元测试域上计算的二阶梯度来模拟MAML [6]的训练策略。随后的基于Meta学习的DG方法利用类似的策略来元学习正则化器[1],特征评论网络[26]或如何维护语义关系[4]。解决DG问题的另一种流行方法是域增强,它通过基于梯度的对抗扰动[45,38]或对抗训练的图像生成器[52,53]从虚拟域创建样本。最近,受到形状偏置模型对分布外的鲁棒性的启发[9],Shi等人。[40]通过根据局部自信息过滤纹理特征来将他们的模型偏向于形状特征。类似地,Carlucci等人。[2]引入了一个自我监督的拼图任务来帮助模型学习全局形状特征,Wang等人。[46]通过引入动量度量学习方案进一步扩展了这项工作。其他DG方法也采用低秩分解[21,37]和梯度引导的丢弃[17]。与上述方法不同的是,我们的工作采用了一种新的基于傅立叶变换的视角来研究DG。通过强调傅立叶相位信息,相比目前的DG方法,我们的方法实现了显着的表现。
相位信息的重要性:许多早期研究[33,34,36,12]表明,在信号的傅立叶谱中,相位分量保留了原始信号中的大部分高层语义,而幅度分量主要包含低层统计信息。最近,Yang等人。[49]将傅立叶视角引入域适应。通过简单地用目标图像的集中幅度谱替换源图像的集中幅度谱中的小区域,它们可以生成用于训练的类似目标的图像。Yang等人[48]的另一项并行工作提出在源-目标图像转换中保持相位一致性,这被证明是比DA场景下分割任务常用的周期一致性[16]更好的选择。受上述工作的启发,我们开发了一个新的基于傅立叶的框架DG鼓励我们的模型专注于相位信息。
一致性正则化:一致性正则化(CR)广泛用于监督和半监督学习。Laine和Aila [18]首先在两个不同扰动模型的输出之间引入了一致性损失。Tarvainen和Valpola [42]通过使用动量更新的教师模型来提供更好的一致性对齐目标进一步扩展了这一工作。Miyato等人。[28]和Park等人。[35]通过用对抗性扰动取代随机扰动来开发不同的技术。Verma等人。[44]还证明了与MixUp [51]样本的插值一致性可能会有所帮助。最近的一些工作[7,41,47]也在UDA中使用一致性正则化来提高目标域的性能。在我们的工作中,我们设计了一个双重形式的一致性损失,以进一步偏置我们的模型的相位信息。
3. Method
给定多个源域的训练集 D s = { D 1 , … , D S } \mathcal{D}_{s}=\left\{\mathcal{D}_{1}, \ldots, \mathcal{D}_{S}\right\} Ds={D1,…,DS},其中在第 k k k个域 D k \mathcal{D}_{k} Dk中具有 N k N_{k} Nk个标记样本 { ( x i k , y i k ) } i = 1 N k \left\{\left(x_{i}^{k}, y_{i}^{k}\right)\right\}_{i=1}^{N_{k}} {(xik,yik)}i=1Nk,其中 x i k x_{i}^{k} xik和 y i k ∈ { 1 , … , C } y_{i}^{k} \in\{1, \ldots, C\} yik∈{1,…,C}分别表示输入和标签,领域泛化的目标是在源域上学习未知领域模型 f ( ⋅ ; θ ) f(\cdot ; \theta) f(⋅;θ),也就是在看不见的目标域 D t \mathcal{D}_{t} Dt上表现良好。
受傅立叶相位分量的语义保持特性的启发[33,34,36,12],我们假设模型突出相位信息具有更好的跨域泛化能力。为此,我们设计了一种新的基于傅立叶的数据增强策略,通过混合图像的幅度信息。我们进一步添加了一个双重形式的一致性损失,称为co-teacher正则化,以在来自增强输入和原始输入的预测之间达成共识。一致性损失是用动量更新的教师模型来实现的,以便为一致性对齐提供更好的目标,如[42]所示。整体的基于傅立叶的增强Co-Teacher(FACT)框架如图2所示。
图2:
文中所提出的FACT框架。我们的框架包含两个关键组件,即基于傅立叶的数据增强和co-teacher正则化,以粗体突出显示。原始数据和增强数据都被发送到学生模型和动量更新的教师模型。然后,co-teacher正则化在来自原始数据和增强数据的预测之间施加双重一致性。请注意,在反向传播过程中,教师模型的参数不会更新。
下面我们介绍FACT的主要组成部分,即:基于傅立叶的数据增强和Co-Teacher正则化。
3.1. Fourier-based data augmentation(基于傅里叶的数据增强)
对于单通道图像 x x x,其傅里叶变换 F ( x ) \mathcal{F}(x) F(x)的公式为:
F ( x ) ( u , v ) = ∑ h = 0 H − 1 ∑ w = 0 W − 1 x ( h , w ) e − j 2 π ( h H u + w W v ) \mathcal{F}(x)(u, v)=\sum_{h=0}^{H-1} \sum_{w=0}^{W-1} x(h, w) e^{-j 2 \pi\left(\frac{h}{H} u+\frac{w}{W} v\right)} F(x)(u,v)=h=0∑H−1w=0∑W−1x(h,w)e−j2π(Hhu+Wwv)
并且我们规定 F − 1 ( x ) \mathcal{F}^{-1}(x) F−1(x)为傅里叶逆变换。傅里叶变换及其逆变换都可以用FFT算法有效地计算<3>[32]。
【注】<3>FFT快速傅里叶变换
然后,幅度分量和相位分量分别表示为:
A ( x ) ( u , v ) = [ R 2 ( x ) ( u , v ) + I 2 ( x ) ( u , v ) ] 1 / 2 P ( x ) ( u , v ) = arctan [ I ( x ) ( u , v ) R ( x ) ( u , v ) ] \begin{array}{l} \mathcal{A}(x)(u, v)=\left[R^{2}(x)(u, v)+I^{2}(x)(u, v)\right]^{1 / 2} \\ \mathcal{P}(x)(u, v)=\arctan \left[\frac{I(x)(u, v)}{R(x)(u, v)}\right] \end{array} A(x)(u,v)=[R2(x)(u,v)+I2(x)(u,v)]1/2P(x)(u,v)=arctan[R(x)(u,v)I(x)(u,v)]
其中 R ( x ) R(x) R(x)和 I ( x ) I(x) I(x)分别表示 F ( x ) \mathcal{F}(x) F(x)的实部和虚部。对于RGB图像,每个通道的傅立叶变换被独立地计算以获得相应的幅度和相位信息。
利用傅立叶相位分量的语义保持特性,我们在这里尝试构建专门突出相位信息的模型,期望这些模型具有更好的跨域泛化能力。为了实现这一目标,自然的选择是通过某种形式的数据增强来扰动原始图像中的幅度信息。受MixUp <2>[51]的启发,
【注】<2>MixUp线性插值
我们通过在来自任意源域的两个图像的幅度谱之间进行线性插值来设计一种新的数据增强策略:
A ^ ( x i k ) = ( 1 − λ ) A ( x i k ) + λ A ( x i ′ k ′ ) , \hat{\mathcal{A}}\left(x_{i}^{k}\right)=(1-\lambda) \mathcal{A}\left(x_{i}^{k}\right)+\lambda \mathcal{A}\left(x_{i^{\prime}}^{k^{\prime}}\right), A^(xik)=(1−λ)A(xik)+λA(xi′k′),
其中, λ ∼ U ( 0 , η ) \lambda \sim U(0, \eta) λ∼U(0,η)(服从标准正态分布,是以0为平均值,以1为标准差的正态分布。)超参数 η \eta η控制增强的强度。然后将混合振幅谱与原始相位谱组合以形成新的傅立叶表示:
F ( x ^ i k ) ( u , v ) = A ^ ( x i k ) ( u , v ) ∗ e − j ∗ P ( x i k ) ( u , v ) , \mathcal{F}\left(\hat{x}_{i}^{k}\right)(u, v)=\hat{\mathcal{A}}\left(x_{i}^{k}\right)(u, v) * e^{-j * \mathcal{P}\left(x_{i}^{k}\right)(u, v)}, F(x^ik)(u,v)=A^(xik)(u,v)∗e−j∗P(xik)(u,v),
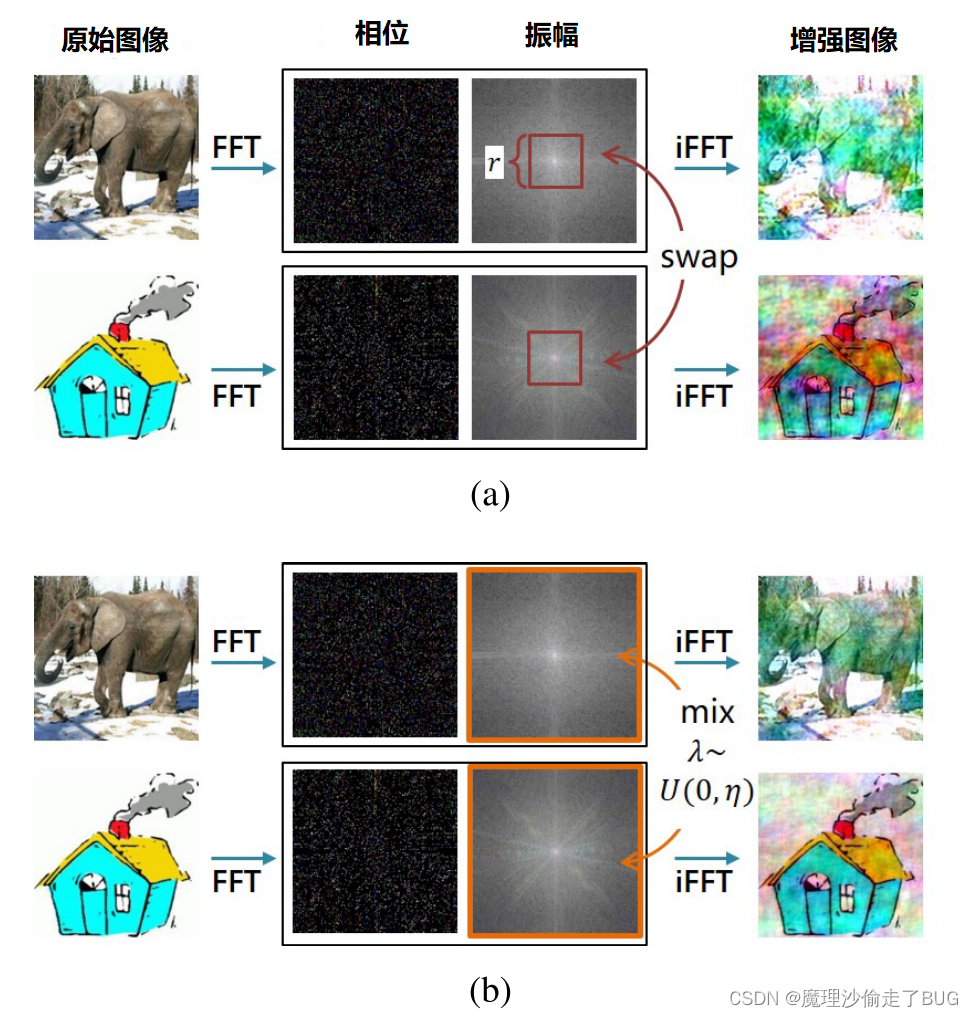
然后将其馈送到逆傅立叶变换以生成增强图像。 x ^ i k = F − 1 [ F ( x ^ i k ) ( u , v ) ] \hat{x}_{i}^{k}=\mathcal{F}^{-1}\left[\mathcal{F}\left(\hat{x}_{i}^{k}\right)(u, v)\right] x^ik=F−1[F(x^ik)(u,v)]. 这种基于傅里叶变换的增强策略,我们再后文中称其为幅度混合(AM),如图3(b)所示。
图3:(a)AS和(B)AM策略的图示。
然后,我们将增强图像和原始标签送到模型中进行分类。损失函数用公式表示为标准交叉熵:
L c l s a u g = − y i k log ( σ ( f ( x ^ i k ; θ ) ) ) \mathcal{L}_{c l s}^{a u g}=-y_{i}^{k} \log \left(\sigma\left(f\left(\hat{x}_{i}^{k} ; \theta\right)\right)\right) Lclsaug=−yiklog(σ(f(x^ik;θ)))
其中 σ \sigma σ是softmax激活函数,我们还使用原始图像进行训练,分类损失函数 L c l s o r i \mathcal{L}_{c l s}^{ori} Lclsori也可以定义为上式。
我们注意到,AM策略与[49]中提出的频谱传输操作本质上不同。具体而言,谱转移操作的目的是通过用目标图像的低频幅度信息替换源图像的低频幅度信息来使低级统计从源域适应于目标域。(我个人理解是这样的:就是将目标图像的频率换到源图像中)然而,在领域泛化中,由于我们无法访问目标数据,因此这种自适应操作是不可能的。尽管如此,我们仍然可以直接交换两个源图像之间的幅度谱以创建增强图像。这种振幅交换(AS)策略如图3(a)所示。
图3:(a)AS和(B)AM策略的图示。
与[49]一样,交换区域的比例由超参数 r r r控制。然而,仅交换集中式幅度谱的小区域(即低频幅度信息)仍然可能导致模型在剩余的中频和高频幅度信息上过拟合,而交换整个幅度谱(即设置 r = 1 r = 1 r=1)对于模型学习来说可能过于激进。另一方面,AM策略相等地扰动幅度谱中的每个频率分量,并通过线性插值将模型桥接到最积极增强的图像。因此,通过AM增强去对比原始图像和增强图像,该模型可以有效地从相位信息中学习。
3.2 Co-teacher 正则化
上述基于傅立叶的数据增强施加了隐式约束,其要求模型在增强之前和之后预测相同的对象。然而,从具有相同相位信息的原始图像和增强图像预测的类别关系可能不同。例如,模型可以从原始图像中学习到马比房子更类似于长颈鹿。然而,由于不同的增强,这种学习的知识可能与从增强图像学习的知识冲突。为了缓解这种分歧,我们增加了一个明确的约束的形式的双重一致性损失。正如[42]中所建议的,我们使用动量更新的教师模型来提供更好的一致性对齐目标。在训练期间,教师模型通过指数移动平均从学生模型接收参数:
θ tea = m θ tea + ( 1 − m ) θ stu \theta_{\text {tea }}=m \theta_{\text {tea }}+(1-m) \theta_{\text {stu }} θtea =mθtea +(1−m)θstu
其中 m m m是动量参数。请注意,在反向传播过程中,没有梯度经过教师模型。为了充分利用从数据中学习到的知识,我们在温度 T T T[15]下使用软化的softmax计算教师和学生模型的输出。然后,我们强制模型在原始图像和增强图像的输出之间保持一致:
L cot a 2 o = KL ( σ ( f stu ( x ^ i k ) / T ) ∥ σ ( f tea ( x i k ) / T ) ) , L cot o 2 a = KL ( σ ( f stu ( x i k ) / T ) ∥ σ ( f tea ( x ^ i k ) / T ) ) \begin{array}{l} \mathcal{L}_{\text {cot }}^{a 2 o}=\operatorname{KL}\left(\sigma\left(f_{\text {stu }}\left(\hat{x}_{i}^{k}\right) / T\right) \| \sigma\left(f_{\text {tea }}\left(x_{i}^{k}\right) / T\right)\right), \\ \mathcal{L}_{\text {cot }}^{o 2 a}=\operatorname{KL}\left(\sigma\left(f_{\text {stu }}\left(x_{i}^{k}\right) / T\right) \| \sigma\left(f_{\text {tea }}\left(\hat{x}_{i}^{k}\right) / T\right)\right) \end{array} Lcot a2o=KL(σ(fstu (x^ik)/T)∥σ(ftea (xik)/T)),Lcot o2a=KL(σ(fstu (xik)/T)∥σ(ftea (x^ik)/T))
在这里,我们将增强图像的学生输出与原始图像的教师输出对齐,以及将原始图像的学生输出与增强图像的教师输出对齐。由于一致性损失采用对偶形式并包含动量教师模型,因此为了简洁起见,我们将损失重命名为co-teacher正则化。通过co-teacher正则化,我们希望我们的模型能够从原始图像和增强图像中平等地学习。更具体地说,原始图像和其增强的对应物可以被视为同一对象的两个视图。当从“原始视图”学习时,学生模型不仅由真实数据(ground truth)指导学习,并且也从“增强视图”学习的教师模型获得指导。当学生模型从“增强视图”学习时,情况也是如此。这种同步协同教学(co-teaching)过程使得原始视图和增强视图之间能够实现全面的知识共享,并进一步引导模型关注不变相位信息,以达到两个视图之间的一致性。
将所有损失函数组合在一起,我们可以得到完整的目标函数:
L F A C T = L c l s o r i + L c l s a u g + β ( L c o t a 2 o + L c o t o 2 a ) \mathcal{L}_{F A C T}=\mathcal{L}_{c l s}^{o r i}+\mathcal{L}_{c l s}^{a u g}+\beta\left(\mathcal{L}_{c o t}^{a 2 o}+\mathcal{L}_{c o t}^{o 2 a}\right) LFACT=Lclsori+Lclsaug+β(Lcota2o+Lcoto2a)
其中 β \beta β控制分类损失和co-teacher正则化损失之间的平衡关系。
4. Experiment
在本节中,我们将在几个DG基准测试中展示我们的方法的优越性。我们还对不同成分和增强类型的影响进行了详细的消融研究。
4.1. Datasets and settings(数据集和设置)
我们在三个传统的DG基准上评估了我们的方法,这些基准涵盖了各种识别场景。这些基准测试的详细情况如下:(1)DigitsDG[52]:数字识别基准测试由四个经典数据集MNIST[20]、MNIST- m[8]、SVHN[31]、SYN[8]组成。这四个数据集主要在字体样式、背景和图像质量上有所不同。我们在[52]中使用原始的训练验证分割,每个数据集每个类600张图像。(2) PACS[21]:包含图片风格差异较大的四个领域(照片、美术、卡通、素描)的目标识别基准。共包含7个类,9991张图片。我们使用Li等人提供的原始训练验证分割。(3) OfficeHome[43]:一个对象识别基准,包括来自四个领域(艺术,剪贴画,产品,现实世界)的65个类别的15,500张图像。域偏移主要来自图像样式和视点,但比PACS小得多。遵循[2],我们随机将每个域分成90%用于训练和10%用于验证。
对于所有基准测试,我们都进行了leave-one-domain-out评估。我们在训练分割上训练我们的模型,并在所有源域的验证分割上选择最佳模型。为了进行测试,我们在hold-out目标域的所有图像上评估所选模型。所有的结果都是根据分类准确性和三次运行的平均值来报告的。我们使用从所有源数据的简单聚合中训练出来的普通卷积神经网络作为基线,在其余部分中称为DeepAll。
4.2. Implementation details(实现细节)
我们密切关注[2,52]的实现。这里我们简要介绍训练模型的主要细节,更多细节可以在补充部分找到。
基本细节:对于digital - dg,我们使用与[52,53]相同的骨干网。我们使用SGD从头开始训练网络,批大小为128,权重衰减为5e-4,持续50个epoch。初始学习率设置为0.05,每20个epoch衰减0.1。对于PACS和OfficeHome,我们使用ImageNet预训练的ResNet[13]作为我们的主干。我们用SGD训练网络,批大小为16,权值衰减为5e-4,训练了50次。初始学习率为0.001,在总epoch的80%时衰减0.1。我们还使用b[2]中的标准增强协议,它包括随机调整大小的裁剪,水平翻转和颜色抖动。
方法具体细节:对于所有实验,我们将教师模型的动量m设置为0.9995,温度T设置为10。digital - dg和PACS的一致性损失权重 β \beta β设为2,OfficeHome设为200。对于长度为5个epoch的 β \beta β,我们也使用s型爬坡[42]。对于Digits-DG和PACS, AM的增强强度 η \eta η取1.0,OfficeHome取0.2
4.3. Evaluation on Digits-DG(Digits-DG数据集的评价)
我们在表1中给出了结果。在所有的竞争者中,我们的方法取得了最好的性能,平均超过第二好的L2A-OT[53]方法3%以上。
表1:在Digits-DG上的Leave-one-domain-out<4>结果。最好和次好的结果分别用黑体和下划线表示。
【注】<4>leave-one-domain-out protocol
以 digit-5 为例,digit-5 由MNIST, MNIST-M, USPS, SVHN和SYN这5个手写数字数据集组成, 每个数据集都划分了 train / test。
DG中的protocol是这样,选定一个数据集作为目标域,剩下的数据集作为源域。训练时采用源域的训练集训练模型,测试时则使用目标域的测试集进行测试(引自这篇文章)
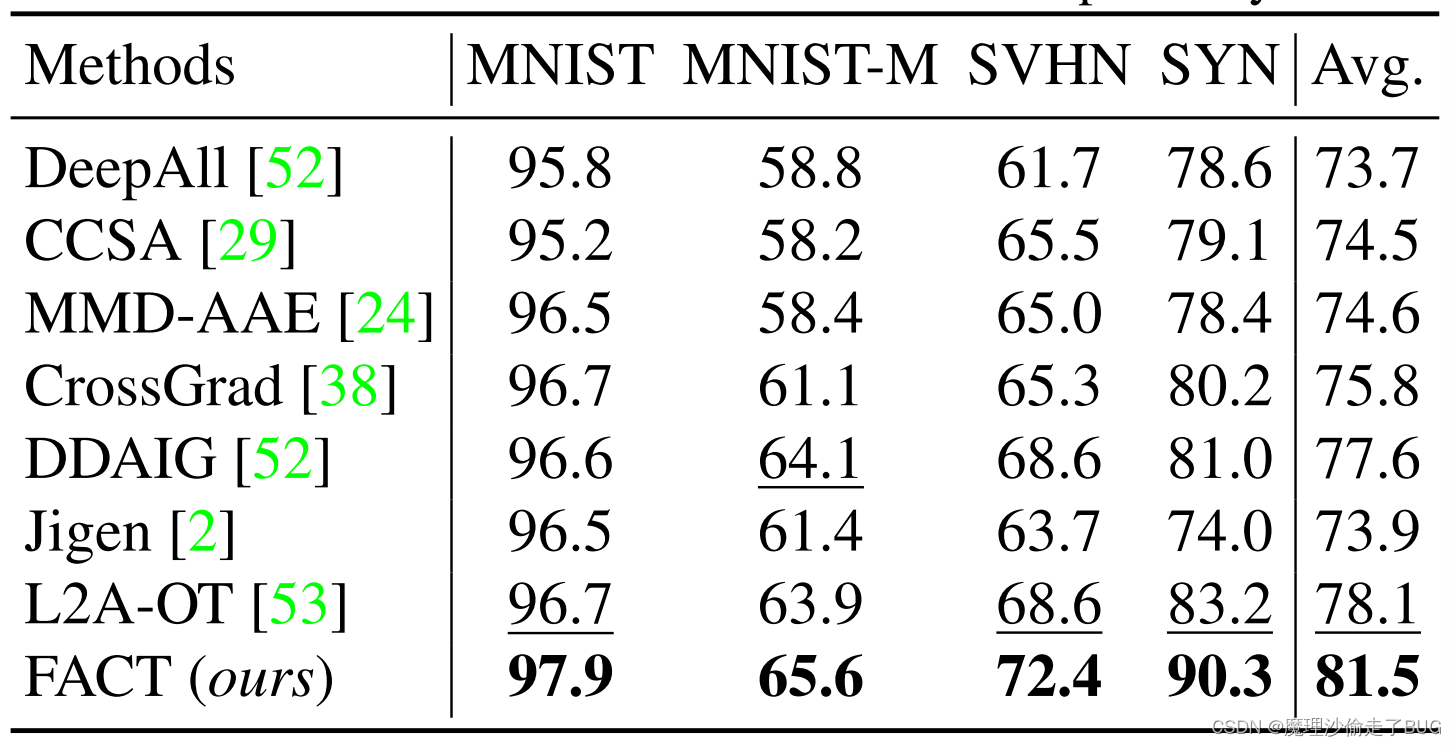
具体来说,在最硬的目标域SVHN和SYN上,其中涉及杂乱的数字和低质量图像,我们的方法分别以4%和7%的较大幅度优于L2A-OT。该方法的成功表明,训练模型更多地关注光谱相位信息可以显著提高其在域外图像上的性能。
4.4. Evaluations on PACS(PACS数据集的评价)
结果如表2所示。很明显,我们的方法是表现最好的方法之一。我们注意到,由于其与预训练数据集ImageNet的相似性,朴素的DeepAll基线可以在照片域上获得显着的准确性。然而,DeepAll在艺术绘画、卡通和素描领域表现不佳,这些领域差异较大。尽管如此,我们的FACT可以将DeepAll的表现提升7.52%,漫画3.52%,素描11.41%。同时,我们的模型在照片域的性能略有下降。这是合理的,因为像照片这样的域包含复杂和冗余的细节,并且模型可能通过只突出显示相位信息而忽略一些可能有用的低级线索。尽管如此,我们的模型仍然实现了更好的整体性能。
与SOTA相比,我们的FACT明显优于基于对抗性数据增强或元学习的方法,包括最新的MASF [4], ddag[52]和L2A-OT[53],但FACT具有高效的训练过程,无需任何额外的对抗性或情景性训练步骤。我们的方法的性能也比RSC17平均高出2.11% 2。以上的比较都表明了我们的方法的有效性,并进一步证明了对相位信息的重视提高了跨域的泛化能力。
4.5. Evaluations on OfficeHome(OfficeHome数据集的评价)
表3:Leave-one-domain-out在OfficeHome数据集上的结果。最好和次好的结果分别用黑体和下划线表示。
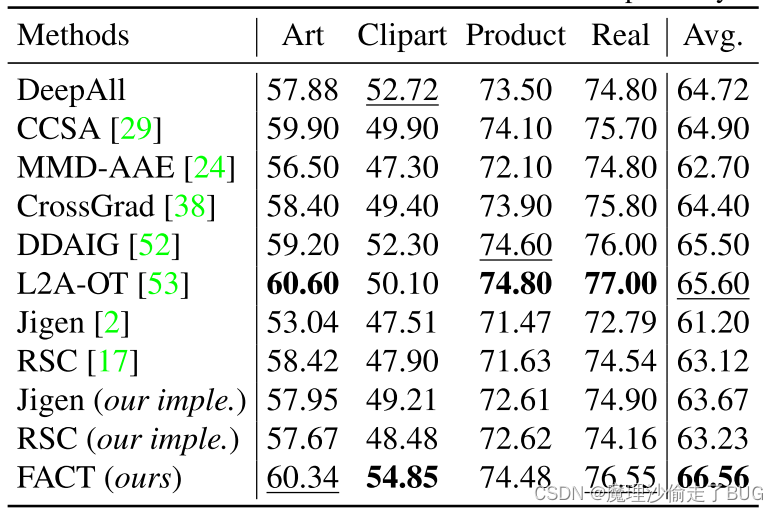
我们在表3中展示了结果。由于相对较小的域差异和与预训练数据集ImageNet的相似性,DeepAll作为OfficeHome的强大基线。许多以前的DG方法,如CCSA [29], MMD-AAE [24], CrossGrad[38]和Jigen[2],都不能比简单的DeepAll基线提高很多。尽管如此,我们的FACT在所有hold -out域上都比DeepAll实现了一致的改进。此外,FACT在平均性能方面也超过了最新的ddaigb[52]和L2A-OT[52]。这再次证明了我们方法的优越性。
4.6. Ablation studies(消融研究)
表4:利用ResNet18在PACS数据集上对我们的方法的不同成分进行了消融研究。
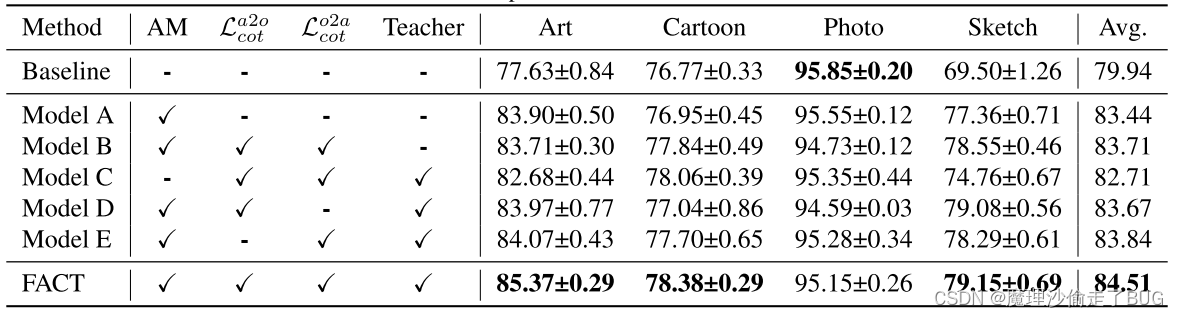
不同成分的影响:我们进行了广泛的消融研究,以调查表4中FACT模型中每个成分的作用。从基线开始,模型A仅使用AM增强进行训练,并且已经比表2中最强的竞争对手dddaig[52]更好。在A模型的基础上,我们增加了一个普通的双形式一致性损失,得到了B模型,比A模型略有改进。进一步整合在我们的FACT上将动量教师模型的结果,它在所有变体中表现最好。这表明了动量教师的重要性,它为一致性丧失提供了更好的目标。我们还通过从FACT中排除AM增强来创建模型C,性能下降了很多,表明基于傅里叶的数据增强起着至关重要的作用。我们通过仅使用 L c o t a 2 o \mathcal{L}_{cot}^{a2o} Lcota2o或 L c o t o 2 a \mathcal{L}_{cot}^{o2a} Lcoto2a进一步验证了对偶形式在合作教师正则化中的必要性,并分别得到模型D和E。如表4所示,模型D或E都没有优于完整的FACT,这表明通过共同教师正则化将原始增强和增强到原始的一致性对齐结合起来是有效的。
基于傅立叶的数据增强的其他选择:接下来,我们将在表5中展示AM增强相对于其替代方案的优势。
表5:利用ResNet18对PACS数据集的傅里叶数据增强的不同选择进行了研究。
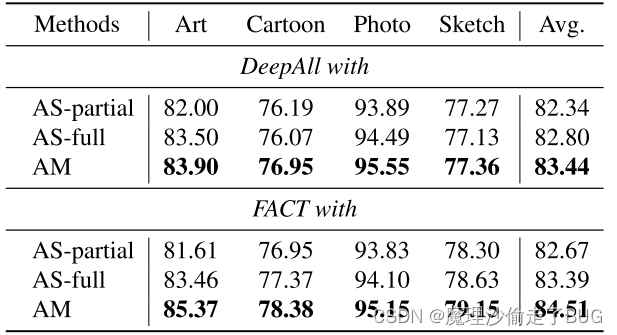
具体来说,我们将AM策略与第3.1节中提到的AS策略进行比较。在[49]之后,我们首先通过设置比值r = 0.09选择只交换集中幅度谱中的一小块区域,这种策略称为AS-partial。如表5所示,As -partial的性能不如AM。这是合理的,因为在as中选择较小的r值只会干扰振幅谱中的低频分量,而模型对剩余的振幅信息仍然存在过拟合的风险。尽管如此,我们仍然可以通过设置 r = 1.0 r = 1.0 r=1.0来干扰所有频率分量,并将结果策略称为ASfull。这个选择带来了一些改进,但仍然比AM差。我们将其归因于直接交换两幅图像的整个振幅谱所造成的负面影响,这可能对模型来说过于激进而无法学习。
5. Discussion
相位信息包含有意义的语义,有助于泛化。在前面的章节中,我们已经看到,通过从相位信息中学习更多,模型可以很好地推广到不可见的领域。本文通过对PACS的单域评估进一步验证了相位信息的重要性。
具体而言,我们首先通过将振幅分量设置为常数来生成仅相位的重建图像,仅振幅的重建图像也是如此。然后,我们分别在原始图像、仅相位图像和仅振幅图像上训练三个模型,并在表6中比较它们的性能。
表6:对比了纯相位重构图像和纯幅值重构图像训练后的性能变化。大于零的值(表示改进)以粗体显示。
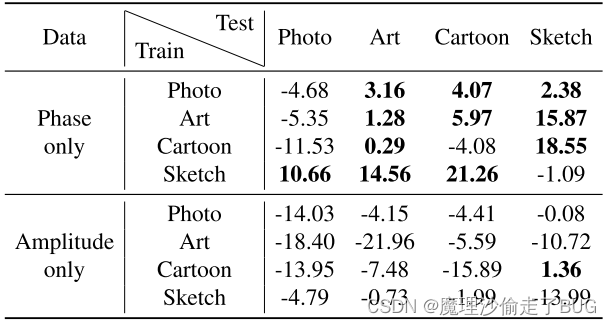
为了公平比较,这里的所有模型都是在没有ImageNet预训练的情况下从头开始训练的。如表6所示,在16种情况中的11种情况下,用仅相位图像训练的模型表现更好,或者至少与用原始图像训练的基线相当。这表明阶段信息确实包含有用的语义,有助于模型推广到看不见的领域。另一方面,在几乎所有情况下,用仅振幅图像训练的模型都会出现很大的性能退化,这表明振幅信息几乎不包含任何有意义的语义。另一个有趣的发现是,当从卡通和艺术领域推广到照片领域时,用纯相位图像训练的模型有一些性能下降。我们推测,在光域上的理想性能可能也需要振幅信息的存在。因此,在我们的FACT框架中,我们并没有完全消除振幅信息,而是以振幅扰动的方式将模型的注意力转移到相位信息上。毫无价值的是,在某些领域泛化情况下,用纯相位图像训练的模型的性能也会下降。考虑到振幅信息的损失,这是合理的。
振幅摄动限制了模型更多地关注相位信息:我们的基于傅里叶的数据增强是通过扰动振幅信息来实现的。在这里,我们提出了一个简短的理论分析,证明振幅摄动确实使模型更关注相位信息。为简单起见,我们考虑一个线性softmax分类器和一个特征提取器h的情况。假设基于傅里叶的数据增强的分布为 g ∼ G g \sim \mathcal{G} g∼G,增强数据上的训练风险为:
R ^ aug = 1 N ∑ n = 1 N E g ∼ G [ ℓ ( W ⊤ h ( g ( x ) ) , y ) ] \hat{R}_{\text {aug }}=\frac{1}{N} \sum_{n=1}^{N} \mathbb{E}_{g \sim \mathcal{G}}\left[\ell\left(\mathbf{W}^{\top} \mathbf{h}(g(x)), y\right)\right] R^aug =N1n=1∑NEg∼G[ℓ(W⊤h(g(x)),y)]
与[3,14]类似,我们将 R ^ aug \hat{R}_{\text {aug }} R^aug 泰勒展开为:
E g ∼ G [ ℓ ( W ⊤ h ( g ( x ) ) , y ) ] = ℓ ( W ⊤ h ‾ , y ) + 1 2 E g ∼ G [ Δ ⊤ H ( τ , y ) Δ ] \begin{array}{l} \mathbb{E}_{g \sim \mathcal{G}}\left[\ell\left(\mathbf{W}^{\top} \mathbf{h}(g(x)), y\right)\right]= \\ \quad \ell\left(\mathbf{W}^{\top} \overline{\mathbf{h}}, y\right)+\frac{1}{2} \mathbb{E}_{g \sim \mathcal{G}}\left[\Delta^{\top} \mathbf{H}(\tau, y) \Delta\right] \end{array} Eg∼G[ℓ(W⊤h(g(x)),y)]=ℓ(W⊤h,y)+21Eg∼G[Δ⊤H(τ,y)Δ]
其中 h ‾ = E g ∼ G [ h ( g ( x ) ) ] \overline{\mathbf{h}}=\mathbb{E}_{g \sim \mathcal{G}}[\mathbf{h}(g(x))] h=Eg∼G[h(g(x))], Δ = W ⊤ ( h ‾ − h ( g ( x ) ) ) \Delta=\mathbf{W}^{\top}(\overline{\mathbf{h}}-\mathbf{h}(g(x))) Δ=W⊤(h−h(g(x))), H \mathbf{H} H为Hessian矩阵。对于使用softmax的交叉熵损失,H是半正定的,与 y y y无关。那么,对于某些特征 h d h_{d} hd最小化上式的二阶项,如果其方差 h d ( g ( x ) ) h_{d}(g(x)) hd(g(x))很大,则权重 w i , d w_{i,d} wi,d将趋近于0。设相位信息和振幅信息诱导出的特征分别为 h p h_{p} hp和 h a h_{a} ha,由于我们只对振幅信息进行扰动,保持相位信息不变,则有:
{ ∣ h p ( g ( x ) ) − h p ( x ) ∣ < ζ ∣ h a ( g ( x ) ) − h a ( x ) ∣ > ϵ \left\{\begin{array}{l} \left|h_{p}(g(x))-h_{p}(x)\right|<\zeta \\ \left|h_{a}(g(x))-h_{a}(x)\right|>\epsilon \end{array}\right. {∣hp(g(x))−hp(x)∣<ζ∣ha(g(x))−ha(x)∣>ϵ
其中 ζ > 0 \zeta>0 ζ>0是一个很小的值,并且,因此,对于那些从振幅信息中得到的特征,最小化 R ^ aug \hat{R}_{\text {aug }} R^aug 限制了 w i , a → 0 w_{i, a} \rightarrow 0 wi,a→0。因此,分类器在进行决策时会更加关注从相位信息中得到的特征 h p h_{p} hp。
**为什么相位信息为模型提供了有意义的语义?**因为相位信息记录了事件b34的“位置”,并在给定图像[12]中揭示了它们之间的空间关系。然后,该模型可以汇总这些线索,以获得关于图像中所传达的对象的正确知识。类似的机制也可以在人类视觉系统中找到。我们还注意到,图1(c)中的纯相位重构图像主要保留了原始图像的轮廓和边缘。为了进一步研究,我们计算了表7中由Sobel或拉普拉斯算子产生的纯相位图像和边缘检测图像之间的余弦相似度。我们可以看到,纯相位图像和边缘检测图像之间的相似性得分非常高,这意味着在相位信息中携带了边缘和轮廓等视觉结构。由于可视化结构是描述不同对象的关键,无论底层领域分布如何,从这些信息中学习可以促进模型提取高级语义。
表7:仅相位重构图像§与Sobel算子(S)和拉普拉斯算子(L)检测的边缘图像之间的余弦相似度

6. Conclusions
本文提出了一种基于傅里叶变换的域泛化方法。主要思想是从谱相位信息中学习更多信息可以帮助模型捕获领域不变的语义概念。然后,我们提出了一个由基于傅里叶的数据增强引起的隐式约束和由共同教师正则化引起的显式约束组成的框架。在三个基准测试上的大量实验表明,我们的方法能够实现最先进的域泛化性能。此外,我们对我们的方法背后的机制和原理进行了深入的分析,这使我们更好地了解为什么关注相位信息可以帮助领域泛化。考虑到相关工作的主流仍然是领域对抗学习或元学习,我们希望我们的工作能给社区带来一些启示。