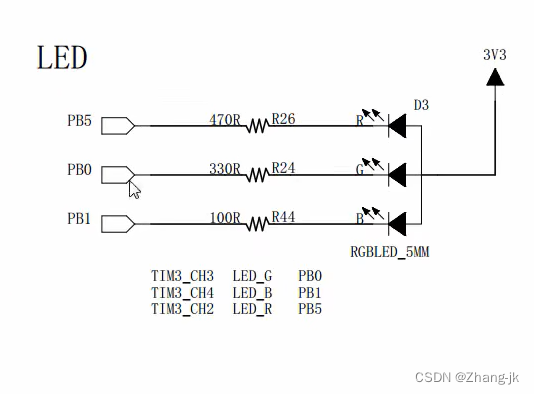
(1)LDA的基本介绍(wiki)
LDA是一种典型的词袋模型,即它认为一篇文档是由一组词构成的一个集合,词与词之间没有顺序以及先后的关系。一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。它以概率分布的形式揭示每个文档的主题,以便在分析一些文档以提取其主题分布后,可以根据主题分布进行主题聚类或使用文本分类。每个主题都用一个词分布表示。
通俗说就是:你计算机给我推测分析网络上各篇文章分别都写了些啥主题,且各篇文章中各个主题出现的概率大小(主题分布)是啥。其中有四个分布:
①Beta分布是二项式分布的共轭先验概率分布
②狄利克雷分布(Dirichlet分布)是多项式分布的共轭先验概率分布
③每一篇文档的主题分布满足多项分布,并且每一个文档的主题分布都是从 α \alpha α这个狄利克雷分布取样而来。

(2)贝叶斯学派和频率学派
①频率学派:频率学派相信概率是一个确定的值,讨论概率的分布没有意义。在机器学习中的体现就是优化似然函数(单纯从自然观测)
②贝叶斯学派:概率表示的是客观上事实的可信程度,也可以说成是主观上主体对事件的信任程度,它是建立在对事件的已有认识基础上的。
贝叶斯学派强调了先验知识的重要性。所以贝叶斯学派的思考方法如下:先验分布 π ( θ ) \pi(\theta) π(θ)指的是人们先前对事物的看法

说白了频率派认为参数是客观存在,不会改变,虽然未知,但却是固定值;贝叶斯派则认为参数是随机值,因为没有观察到,那么和是一个随机数也没有什么区别,因此参数也可以有分布,