步骤一:定义神经网络结构
- 注意:由于一次batch_size的大小为64,表示一次放入64张图片,且Flatten()只会对单张图片的全部通道做拉直操作,也就是不会将batch_size合并,但是一张图片有3个通道,在Maxpool层之后,有64个通道,且每个通道的大小为4*4,所以Flatten()的输入为[64, 64, 4, 4]那么Flatten()的输出就为[64, 1024], 1024 = 64 * 4 * 4
- 注意:通过ones()函数创建一个全1的tensor,作为输入数据,我们只需要指定输入数据的形状即可,我们可以通过ones()创建的简单输入,来检测网络的结构是否正确,()内写序列
- 代码如下:
import torch
from torch import nnclass Tudui(nn.Module):def __init__(self):super().__init__()self.model = nn.Sequential(nn.Conv2d(3,32,5,1,2),nn.MaxPool2d(2),nn.Conv2d(32,32,5,1, 2),nn.MaxPool2d(2),nn.Conv2d(32,64,5,1,2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(1024, 64),nn.Linear(64, 10))def forward(self, x):x = self.model(x)return xif __name__ == '__main__':tudui = Tudui()input = torch.ones((64, 3, 32, 32))output = tudui(input)print(output.shape)
步骤二:导入数据集,载入数据,创建网络模型,设置训练参数
- 注意:有些代码的模型结构在module.py文件夹内,需要我们手动导包后才能创建实例
- 注意: 先进行梯度清零,之后再反向传播、更新参数
- 注意:优化器实例 . 梯度清零,损失实例 . 反向传播,优化器实例 . 更新参数
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torchvision.transforms import transformsfrom learn_pytorch.module import Tuduitrain_dataset = torchvision.datasets.CIFAR10(root='Dataset', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = torchvision.datasets.CIFAR10(root='Dataset', train=False, transform=transforms.ToTensor(), download=True)
train_dataset_size = len(train_dataset)
test_dataset_size = len(test_dataset)
print('训练数据集大小:', train_dataset_size)
print('测试数据集大小:', test_dataset_size)
train_loader = DataLoader(dataset=train_dataset, batch_size=64)
test_loader = DataLoader(dataset=test_dataset, batch_size=64)
tudui = Tudui()
loss_fn = nn.CrossEntropyLoss()
learn_rate = 1e-3
optimizer = torch.optim.SGD(tudui.parameters(), lr=learn_rate)
total_train_step = 0
total_test_step = 0
epoch = 10for i in range(epoch):print(f'----第{i+1}轮训练开始----')for data in train_loader:inputs, targets = dataoutputs = tudui(inputs)loss = loss_fn(outputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()total_train_step += 1print(f'训练次数: {total_train_step}, Loss: {loss.item()}')
- loss跟loss.item()的区别在于:
- 如果loss为tensor格式,那么输出会带有tensor(),而如果我们使用 .item()格式,则不会带有tensor(),如下:
import torcha = torch.tensor(5)
print(a)
print(a.item())
步骤三:测试模型性能
- 由于我们每轮训练结束,都需要看模型有没有训练好,所以我们需要用测试集对模型进行测试
- 同时我们不希望模型根据测试集来更新梯度,即保证测试集不被污染,使用 with torch.no_grad()来关闭梯度计算,
- 注意:因为此处我们没有使用梯度,所以虽然看起来不写 with torch.no_grad()和写没有什么区别,但是如果不写,就算不把梯度写入模型中,系统仍会计算梯度。而我们在测试时不需要更新参数,即不需要梯度计算,所以在测试过程中它会降低计算效率。
- 综上:推荐在测试时,关闭梯度计算,代码如下:
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torchvision.transforms import transformsfrom learn_pytorch.module import Tuduitrain_dataset = torchvision.datasets.CIFAR10(root='Dataset', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = torchvision.datasets.CIFAR10(root='Dataset', train=False, transform=transforms.ToTensor(), download=True)
train_dataset_size = len(train_dataset)
test_dataset_size = len(test_dataset)
print('训练数据集大小:', train_dataset_size)
print('测试数据集大小:', test_dataset_size)
train_loader = DataLoader(dataset=train_dataset, batch_size=64)
test_loader = DataLoader(dataset=test_dataset, batch_size=64)
tudui = Tudui()
loss_fn = nn.CrossEntropyLoss()
learn_rate = 1e-3
optimizer = torch.optim.SGD(tudui.parameters(), lr=learn_rate)
total_train_step = 0
total_test_step = 0
epoch = 10for i in range(epoch):print(f'----第{i+1}轮训练开始----')for data in train_loader:inputs, targets = dataoutputs = tudui(inputs)loss = loss_fn(outputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()total_train_step += 1if total_train_step % 100 == 0:print(f'训练次数: {total_train_step}, Loss: {loss.item()}')total_test_loss = 0with torch.no_grad():for data in test_loader:inputs, targets = dataoutputs = tudui(inputs)loss = loss_fn(outputs, targets)total_test_loss += loss.item()print(f'测试Loss = {total_test_loss}')
步骤四:在tensorboard中展示输出结果
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision.transforms import transformsfrom learn_pytorch.module import Tuduitrain_dataset = torchvision.datasets.CIFAR10(root='Dataset', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = torchvision.datasets.CIFAR10(root='Dataset', train=False, transform=transforms.ToTensor(), download=True)
train_dataset_size = len(train_dataset)
test_dataset_size = len(test_dataset)
print('训练数据集大小:', train_dataset_size)
print('测试数据集大小:', test_dataset_size)
train_loader = DataLoader(dataset=train_dataset, batch_size=64)
test_loader = DataLoader(dataset=test_dataset, batch_size=64)
tudui = Tudui()
loss_fn = nn.CrossEntropyLoss()
learn_rate = 1e-3
optimizer = torch.optim.SGD(tudui.parameters(), lr=learn_rate)
writer = SummaryWriter('logs_module')
total_train_step = 0
total_test_step = 0
epoch = 10for i in range(epoch):print(f'----第{i+1}轮训练开始----')for data in train_loader:inputs, targets = dataoutputs = tudui(inputs)loss = loss_fn(outputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()total_train_step += 1if total_train_step % 100 == 0:print(f'训练次数: {total_train_step}, Loss: {loss.item()}')writer.add_scalar('train_loss', loss.item(), total_train_step)total_test_loss = 0with torch.no_grad():for data in test_loader:inputs, targets = dataoutputs = tudui(inputs)loss = loss_fn(outputs, targets)total_test_loss += loss.item()total_test_step += 1print(f'测试Loss = {total_test_loss}')writer.add_scalar('test_loss', total_test_loss, total_test_step)writer.close()
- 结果如下:
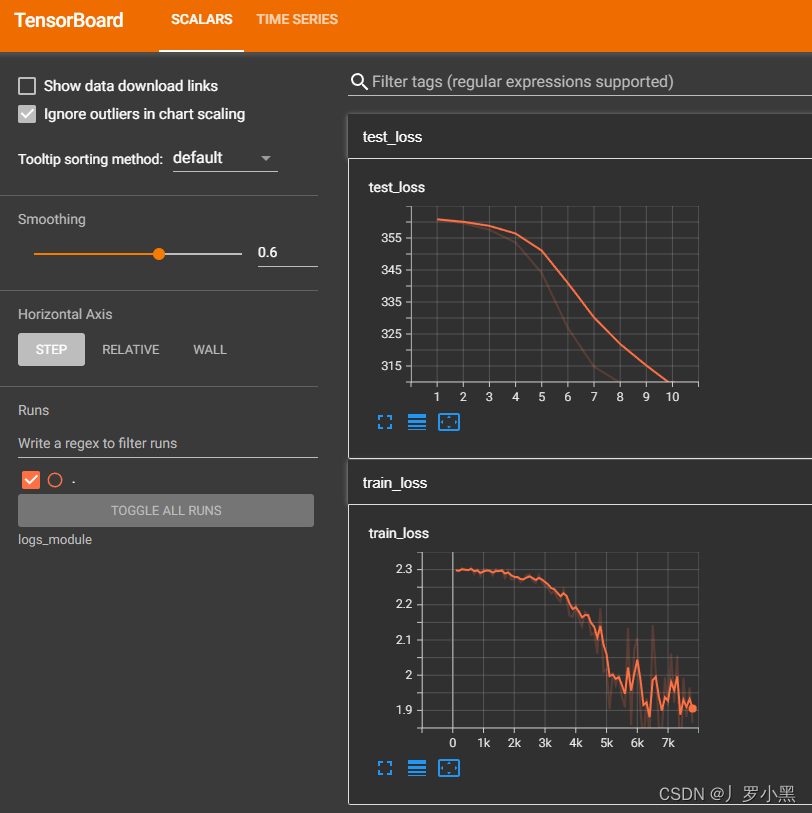
步骤五:保存每轮模型训练的结果
torch.save(tudui, f'pth/module{i}')print('模型已保存')
步骤六:计算每轮训练的AP
- 注意:通过argmax()来得出output的每组序列中哪一个下标的概率最大,()内填1表示横向看,0表示纵向看
- 注意:通过Preds == target来得出每个预测是否与真实值相同,返回False、True的序列
- 注意:通过.sum()来计算一共有多少个True

- 代码如下:
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision.transforms import transformsfrom learn_pytorch.module import Tuduitrain_dataset = torchvision.datasets.CIFAR10(root='Dataset', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = torchvision.datasets.CIFAR10(root='Dataset', train=False, transform=transforms.ToTensor(), download=True)
train_dataset_size = len(train_dataset)
test_dataset_size = len(test_dataset)
print('训练数据集大小:', train_dataset_size)
print('测试数据集大小:', test_dataset_size)
train_loader = DataLoader(dataset=train_dataset, batch_size=64)
test_loader = DataLoader(dataset=test_dataset, batch_size=64)
tudui = Tudui()
loss_fn = nn.CrossEntropyLoss()
learn_rate = 1e-3
optimizer = torch.optim.SGD(tudui.parameters(), lr=learn_rate)
writer = SummaryWriter('logs_module')
total_train_step = 0
total_test_step = 0
epoch = 10for i in range(epoch):print(f'----第{i+1}轮训练开始----')for data in train_loader:inputs, targets = dataoutputs = tudui(inputs)loss = loss_fn(outputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()total_train_step += 1if total_train_step % 100 == 0:print(f'训练次数: {total_train_step}, Loss: {loss.item()}')writer.add_scalar('train_loss', loss.item(), total_train_step)total_test_loss = 0total_accuracy = 0with torch.no_grad():for data in test_loader:inputs, targets = dataoutputs = tudui(inputs)loss = loss_fn(outputs, targets)total_test_loss += loss.item()accuray = (outputs.argmax(1) == targets).sum()total_accuracy += accurayprint(f'测试准确率 = {total_accuracy / test_dataset_size}')total_test_step += 1print(f'测试Loss = {total_test_loss}')writer.add_scalar('test_loss', total_test_loss, total_test_step)writer.add_scalar('test_accuracy', total_accuracy / test_dataset_size, total_test_step)torch.save(tudui, f'pth/module{i}')print('模型已保存')
writer.close()
- 结果如下:
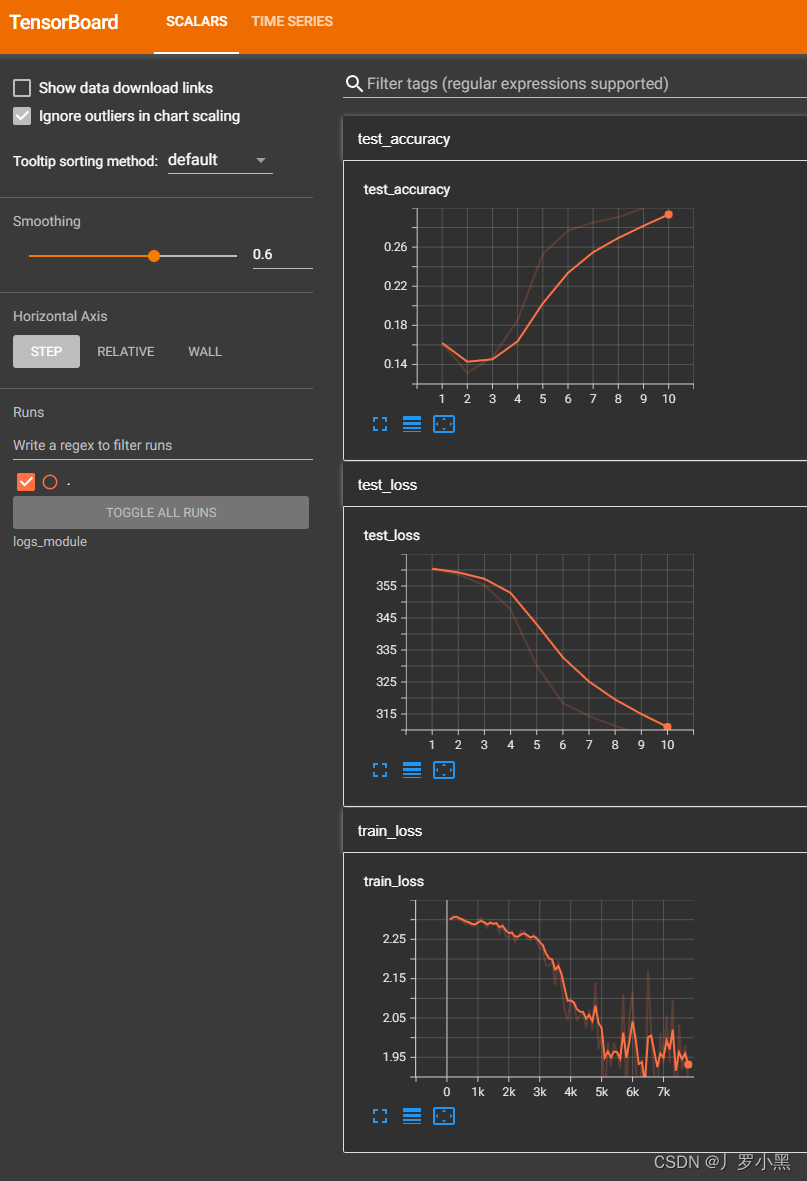
注意事项
- 在模型的训练代码前,可以加上如下代码,因为有些网络层需要它才能表示训练状态开启:
- 官网解释如下:
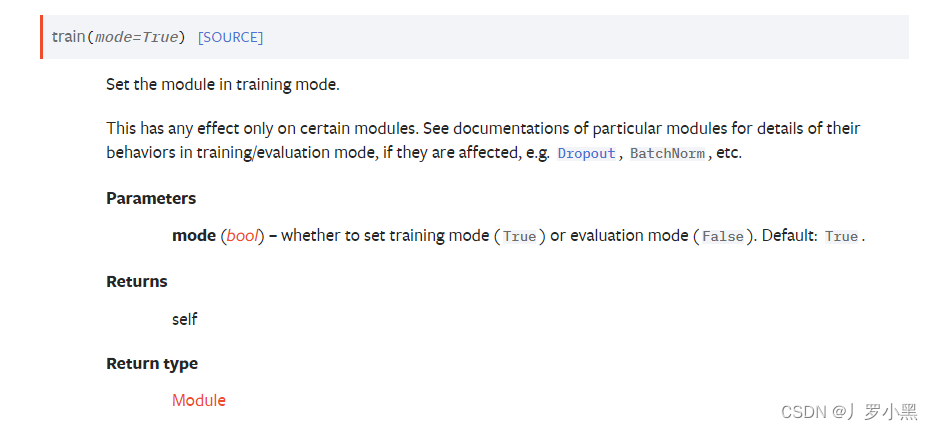
tudui.train()
- 在模型的测试代码前,也可以加上如下代码,因为有些网络层需要它才能表示测试状态开启:
- 官网解释如下:
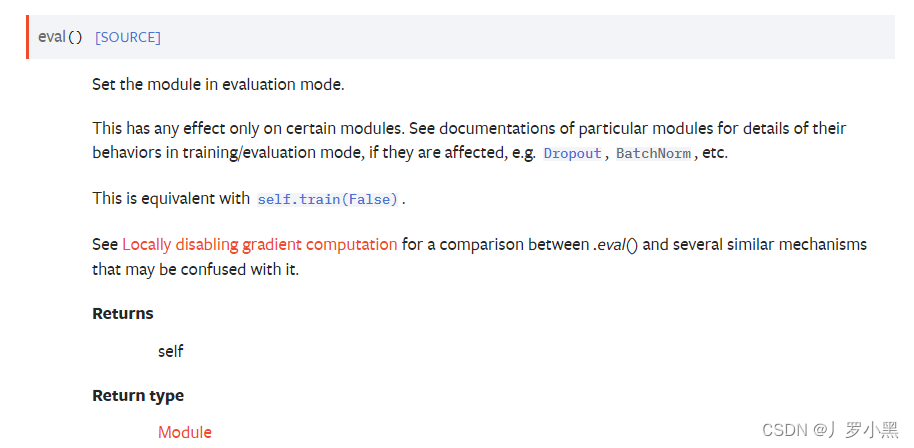
tudui.eval()