声明:本深度学习笔记基于课时18 索引与切片-1_哔哩哔哩_bilibili学习而来
All is about Tensor
定义:Tensors are simply mathematical objects that can be used to describe physical properties, just like scalars and vectors. In fact tensors are merely a generalisation of scalars and vectors; a scalar is a zero rank tensor, and a vector is a first rank tensor.
这句话的大概意思就是张量就是标量和向量的推广,标量被称为0维张量,向量被称为一维张量。
我们先将python常用的数据类型和pytorch进行比较,我们可以很清楚的看出pytorch的数据类型都加了一个张量(Tensor),但是pytorch里面并没有字符串类型,因为pytorch主要是一个关于计算的库。

但是,我们在pytorch里面就用不到字符串吗?当让不是,在数字识别体验课的时候我们是用了One-hot的编码方式,就是我们创建一个长度为10的一维向量,如果对应上了,我们就把与此对应的数值改为1。
问题又来了,我们需要处理的数据太过庞大了,比如我们处理10万个数据,我们还要使用长度为10万的向量吗?答案,肯定不是。我们使用叫做Embedding的编码方式。
总的来说,就是讲pytorch使用编码的方式处理字符串。
再回到我们的数据类型上:

我们在pytorch上使用torch.FloatTensor表示浮点型,其它类型同理。众所周知,深度学习需要处理大量的数据,需要大量的计算,为了提高效率,我们让GPU帮助我们计算,但是此时数据类型就要加上cuda了。
Type check
import torch
a = torch.randn(2,3) # 创建一个2*3矩阵print("Tensor:",a)
# 输出:Tensor: tensor([[-0.6643, -1.7207, -0.7312],
# [-0.9627, -0.5519, -0.7359]])print("Tensor of type:",a.type())
# 输出:Tensor of type: torch.FloatTensor# 在深度学习中,我们经常会用到参数的合理化检验,一般使用下面这个方法
isinstance(a,torch.FloatTensor)
# 输出:Ture# 不常使用的
# print(type(a))再讲述一下pytorch默认类型的问题,以及设置默认类型的问题:
pytorch中使用tensor创建的张量默认类型为双精度类型
print(torch.tensor([1.2,3]).type())
# out:torch.DoubleTensor
# 设置默认类型:
torch.set_default_tensor_type(torch.FloatTensor)
print(torch.tensor([1.2,3]).type())
# out:torch.FloatTensordim
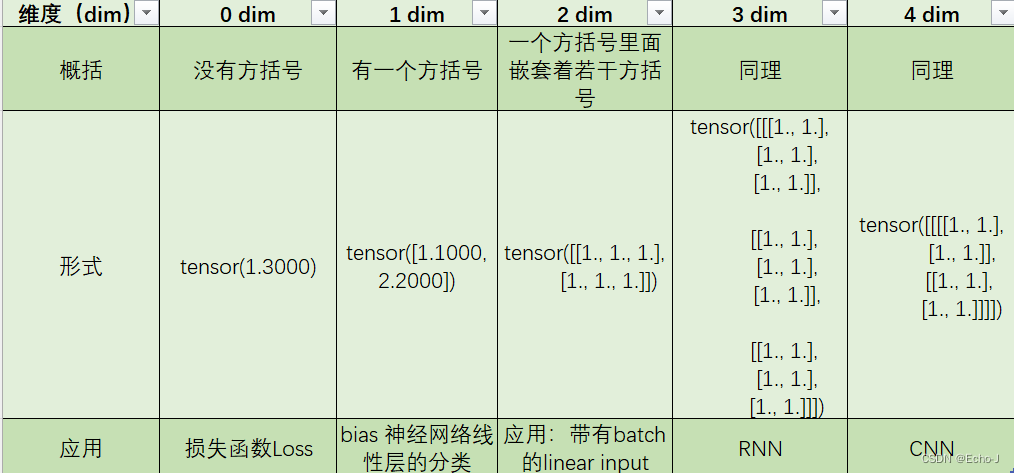
注:tensor里面包含的就是具体的数据。
size()&shape&dim()
我觉得进行下面的学习之前,应该先搞明白size,shape,dim的概念。
shape是一个属性,在使用的时候不用加括号;size()是一个方法。其实shape和size()的作用是一样的,但是shape是numpy中array和pytorch中的tensor通用的size()只能用在tensor上。
dim()方法是计算维度的,效果和len(a.shape)一样。
a = torch.tensor([[1,2,3,0],[4,5,7,9],[7,8,5,3]])
print("shape:",a.shape)
# out:shape: torch.Size([3, 4])
print("dim:",a.dim())
# out:dim: 2
print("size:",a.size())
# out:size: torch.Size([3, 4])创建Tensor
1、import from numpy
# 创建Tensor
# eg1
import numpy as np
a = np.array([2,3.3]) # 先使用numpy创建dim 1 size 2 的向量
print(torch.from_numpy(a)) # 导入
# out:tensor([2.0000, 3.3000])
#eg2
a = np.ones([2,3]) # 先使用np直接创建一个维度为2,size为3的向量
print(torch.from_numpy(a))
# out:tensor([[1., 1., 1.],
# [1., 1., 1.]])2、import from List
当时数据量不是很大的时候就可以使用此方法。直接使用List方法tensor接受现有数据,Tensor接受数据的维度,也可以接受现有数据。
print(torch.tensor([2.,3.2]))
# out:tensor([2.0000, 3.3000])
print(torch.tensor([[2.,3.2],[1.,22.369]]))
# out:tensor([[ 2.0000, 3.2000],
# [ 1.0000, 22.3690]])
print(torch.FloatTensor([2.,3.2])) # 接收数据
# out:tensor([2.0000, 3.3000])
print(torch.FloatTensor(2,3)) # 接受维度
# out:tensor([[-2.9315e-03, 1.0272e-42, -1.5882e-23],
# [ 2.1500e+00, 0.0000e+00, 1.8750e+00]], dtype=torch.float32)
print(torch.Tensor([2.,3.2]))
# out:tensor([2.0000, 3.3000])但是一般在使用的时候会使用 tensor专门接受现有数据,Tensor专门接受数据的维度,这样不容易搞混。
3、uninitialized
当需要未初始化数据的时候可以使用以下几种方法。
# 以下方法生成的数据非常的不规律,需要使用数据进行覆盖
print(torch.empty(2)) # 生成一个未初始化长度为1的数据
# out:tensor([1.2697e-321, 4.9407e-324])
print(torch.Tensor(2,3))
# out:tensor([[4.9407e-324, 4.9407e-324, 4.9407e-324],
# [4.9407e-324, 4.9407e-324, 4.9407e-324]])
print(torch.IntTensor(2,3))
# out:tensor([[-1153427456, 733, -81441600],
# [ 1072143930, -588085446, 1071206672]], dtype=torch.int32)
print(torch.FloatTensor(2,3))
# out:tensor([[-2.9309e-03, 1.0272e-42, -8.5829e+35],
# [ 1.8095e+00, -5.4613e+17, 1.6978e+00]], dtype=torch.float32)4、rand/rand_like,randint
随机初始化,也是推荐最常使用的。
print(torch.rand(3,3)) # rand()方法随机产生0-1的数据,此时产生一个3*3的二维张量(第一维长度为3,第二维长度为3)
# out:tensor([[0.0664, 0.6562, 0.3293],
# [0.4063, 0.8417, 0.0114],
# [0.0279, 0.3318, 0.5429]])
a = torch.rand(3,3)
print(torch.rand_like(a)) # 作用:接受的是一个shape,会将a的shape直接读出来,再传入rand()方法
# out:tensor([[0.5812, 0.8895, 0.3767],
# [0.3151, 0.2174, 0.5673],
# [0.4537, 0.9913, 0.7640]])
print(torch.randint(1,10,[3,3])) # randint()方法只能随机产生整数,此时产生一个所有元素都位于1-10的3*3的二维张量
# out:tensor([[7, 1, 3],
# [2, 2, 8],
# [2, 8, 6]])如果想要均匀采样0-10的tensor,要使用x = 10*torch.rand(d1,d2),randint()只能采样整数。
5、randn
会产生正态0,1分布的随机数。
print(torch.randn(3,3))
# out:tensor([[ 0.9438, 0.8224, -0.9046],
# [-0.0314, 1.2954, -0.6943],
# [ 1.0301, -0.3824, -1.0747]])
print(torch.normal(mean=torch.full([10],0.), std=torch.arange(1,0,-0.1)))
# out:tensor([-0.4060, -0.5174, 0.1747, -0.7274, -0.0309, 0.4580, -0.6965, -0.2976,
# -0.1198, 0.0581])normal(mean, std, *, generator=None, out=None)
返回值:一个张量,张量中每个元素是从相互独立的正态分布中随机生成的。每个正态分布的均值和标准差对应着mean中的一个值和std中的一个值。
注意:张量mean和std的形状不一定相同,但是元素个数必须相同。如果二者形状不一致,返回张量的形状和mean的一致
generator=None:用于采样的伪随机数发生器
out:输出张量的形状
6、full
print(torch.full([2,3],7)) # 创建一个全为7的2*3二维向量
# out:tensor([[7, 7, 7],
# [7, 7, 7]])
print(torch.full([],7)) # 创建一个全为7的标量
# out:tensor(7)
print(torch.full([2],7)) # 创建一个全为7的1*2一维向量
# out:tensor([7, 7])7、arange/range
生成递增、递减等差数列的API。
print(torch.arange(0,10)) # 生成一个从0开始,不到10的等差数列
# out:tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
print(torch.arange(0,10,2))
# out:tensor([0, 2, 4, 6, 8])
print(torch.range(0,10)) # 不推荐使用这个
# out:tensor([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])
# C:\Users\Lenovo\AppData\Local\Temp\ipykernel_10204\2132562954.py:3: UserWarning: torch.range is deprecated and will be removed in a future release because its behavior is inconsistent with Python's range builtin. Instead, use torch.arange, which produces values in [start, end).
# print(torch.range(0,10))8、linspace/logspace
生成一个等差的数列。
print(torch.linspace(0,10,steps=4)) # 后面的数是指生成元素的个数
# out:tensor([ 0.0000, 3.3333, 6.6667, 10.0000])
print(torch.linspace(0,10,steps=10))
# out:tensor([ 0.0000, 1.1111, 2.2222, 3.3333, 4.4444, 5.5556, 6.6667, 7.7778,
# 8.8889, 10.0000])
print(torch.linspace(0,10,steps=11))
# out:tensor([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])
print(torch.logspace(0,-1,steps=10)) # 生成10个10的0次方到10的-1次方的数
# out:tensor([1.0000, 0.7743, 0.5995, 0.4642, 0.3594, 0.2783, 0.2154, 0.1668, 0.1292,
# 0.1000])
print(torch.logspace(0,1,steps=10))
# out:tensor([ 1.0000, 1.2915, 1.6681, 2.1544, 2.7826, 3.5938, 4.6416, 5.9948,
# 7.7426, 10.0000])9、Ones/zeros/eye
生成全0,全1,是对角矩阵的。
print(torch.ones(3,3)) # 生成一个全一3*3的二维张量
# out:tensor([[1., 1., 1.],
# [1., 1., 1.],
# [1., 1., 1.]])
print(torch.zeros(3,3)) # 生成一个全零3*3的二维张量
# out:tensor([[0., 0., 0.],
# [0., 0., 0.],
# [0., 0., 0.]])
print(torch.eye(3,4)) # 生成一个近似对角矩阵
# out:tensor([[1., 0., 0., 0.],
# [0., 1., 0., 0.],
# [0., 0., 1., 0.]])
print(torch.eye(3)) # 生成一个对角矩阵
# out:tensor([[1., 0., 0.],
# [0., 1., 0.],
# [0., 0., 1.]])
a=torch.zeros(3,3)
print(torch.ones_like(a))
# out:tensor([[1., 1., 1.],
# [1., 1., 1.],
# [1., 1., 1.]])10、randperm
随机打散
print(torch.randperm(10)) # 随机生成一个0-9长度为10的索引
a=torch.rand(2,3)
b=torch.rand(2,2)
idx=torch.randperm(2)
print(idx)
print(idx)
print(a[idx]) # 这个必须和下面一句idx保持一致
print(b[idx])
print(a,b)补充
如果a=tensor([[[0.0787, 0.8906, 0.0690], [0.1323, 0.5660, 0.2708]]]),a[0] = tensor([[0.0787, 0.8906, 0.0690], [0.1323, 0.5660, 0.2708]]),获取a中第0个元素,就是第一维度的第0个元素;a[0][0]=tensor([0.0787, 0.8906, 0.0690]),获取a中第二维度的第0个元素的第0个元素。
a = torch.randn(2,3)
print(a)
# out:tensor([[ 1.7312, 1.8919, 0.3483],
# [ 0.6409, 1.5857, -1.4704]])
print(a.shape) # 获取tensor的具体形状
# out:torch.Size([2, 3])
print(a.size(0)) # 获取shape的第0个元素
# out:2
print(a.size(1)) # 获取shape的第1个元素
# out:3
print(a.shape[1]) # 获取shape的第1个元素,但是注意括号的区别
# out:3tensorData.numel() # 具体占用内存大小