✨✨ 欢迎大家来到景天科技苑✨✨
🎈🎈 养成好习惯,先赞后看哦~🎈🎈
🏆 作者简介:景天科技苑
🏆《头衔》:大厂架构师,华为云开发者社区专家博主,阿里云开发者社区专家博主,CSDN新星创作者,掘金优秀博主,51CTO博客专家等。
🏆《博客》:Python全栈,前后端开发,人工智能,js逆向,App逆向,网络系统安全,数据分析,Django,fastapi,flask等框架,linux,shell脚本等实操经验,网站搭建,面试宝典等分享等等。所属的专栏:数据分析系统化教学,零基础到进阶实战
景天的主页:景天科技苑
文章目录
- 1.图例显示
- 1.折线图
- 2.柱状图
- 3.直方图
- 4.散点图
- 5.饼状图
- 6.漏斗图
- 7.地图
- 2.布局
- 1.st.sidebar - 在侧边栏增添交互元素
- 2.st.columns - 并排布局多元素容器
- 3.st.tabs - 以选项卡形式布局多元素容器
- 4.st.expander - 可展开/折叠的多元素容器
- 3.实战案例
- 1.抓取拉勾网招聘岗位数据,并分析展示
- 2. 从本地表格读取数据,并进行可视化展示
大家好,我是景天,上一篇我们讲到了数据分析可视化框架streamlit的基本介绍,安装,常规用法等等,相信大家对它的使用有了一定的了解,没印象的同学可以翻看下本专栏上一章 数据分析web可视化神器—streamlit框架,无需懂前端也能搭建出精美的web网站页面
本章我们进一步探讨streamlit的一些高阶用法,喜欢的朋友点赞收藏关注不迷路哦
1.图例显示
环境安装:
pip install streamlit-echarts
1.折线图
from pyecharts.charts import Line
from pyecharts import options as opts
from streamlit_echarts import st_pyecharts# 示例数据
cate = ['Apple', 'Huawei', 'Xiaomi', 'Oppo', 'Vivo', 'Meizu']
data1 = [123, 153, 89, 107, 98, 23]
data2 = [56, 77, 93, 68, 45, 67]
#画图,画折线图
line = (Line().add_xaxis(cate).add_yaxis('电商渠道', data1,#均值标记线markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average")])).add_yaxis('门店', data2,markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average")])).set_global_opts(title_opts=opts.TitleOpts(title="Line-基本示例", subtitle="我是副标题")))
#渲染到页面中
st_pyecharts(line)
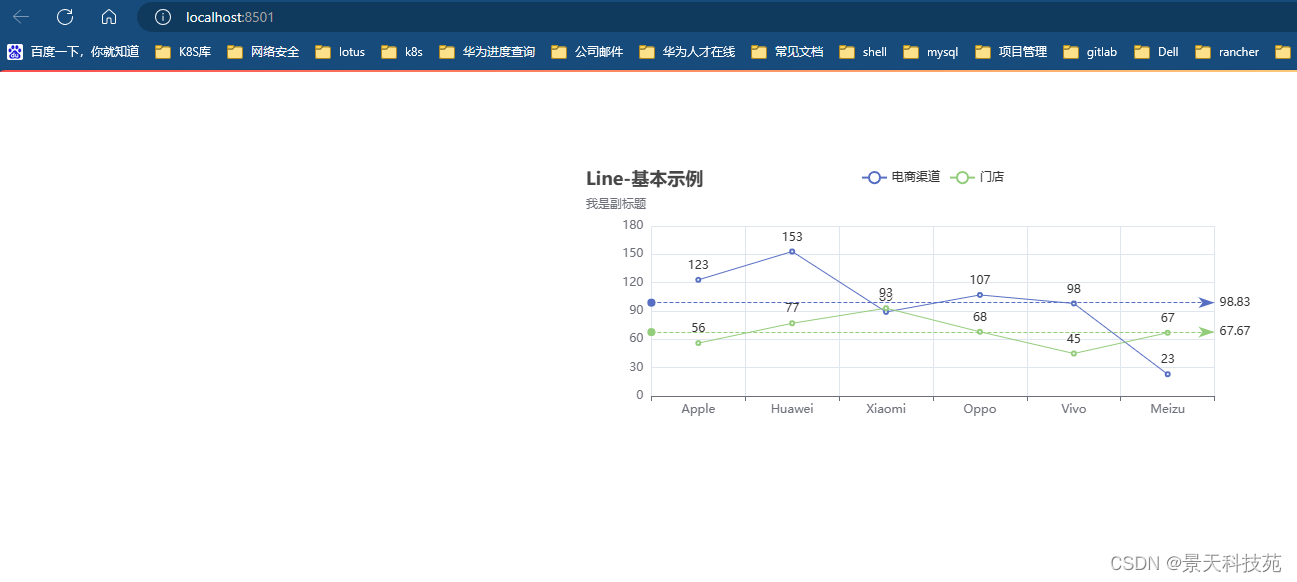
2.柱状图
from pyecharts import options as opts
from pyecharts.charts import Bar
from streamlit_echarts import st_pyechartsb = (Bar().add_xaxis(["Microsoft", "Amazon", "IBM", "Oracle", "Google", "Alibaba"]).add_yaxis("2017-2018 Revenue in (billion $)", [21.2, 20.4, 10.3, 6.08, 4, 2.2]).set_global_opts(title_opts=opts.TitleOpts(title="Top cloud providers 2018", subtitle="2017-2018 Revenue"),#工具栏,可以切换图表样式--折线图,柱状图....等切换toolbox_opts=opts.ToolboxOpts(),)
)
st_pyecharts(b)
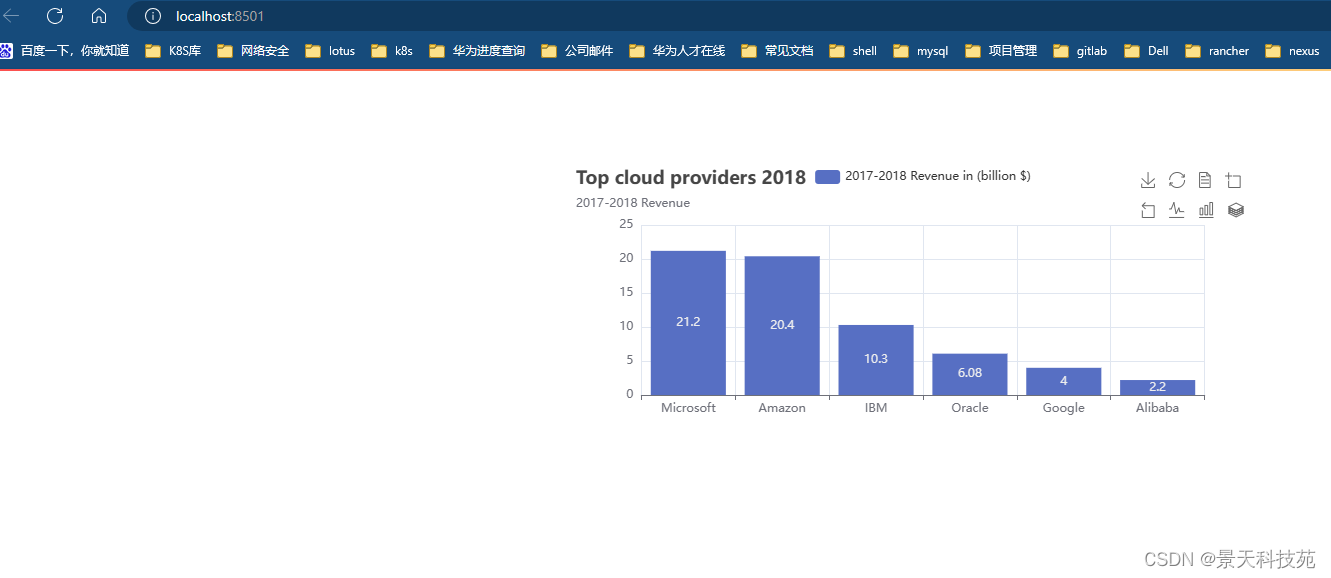
3.直方图
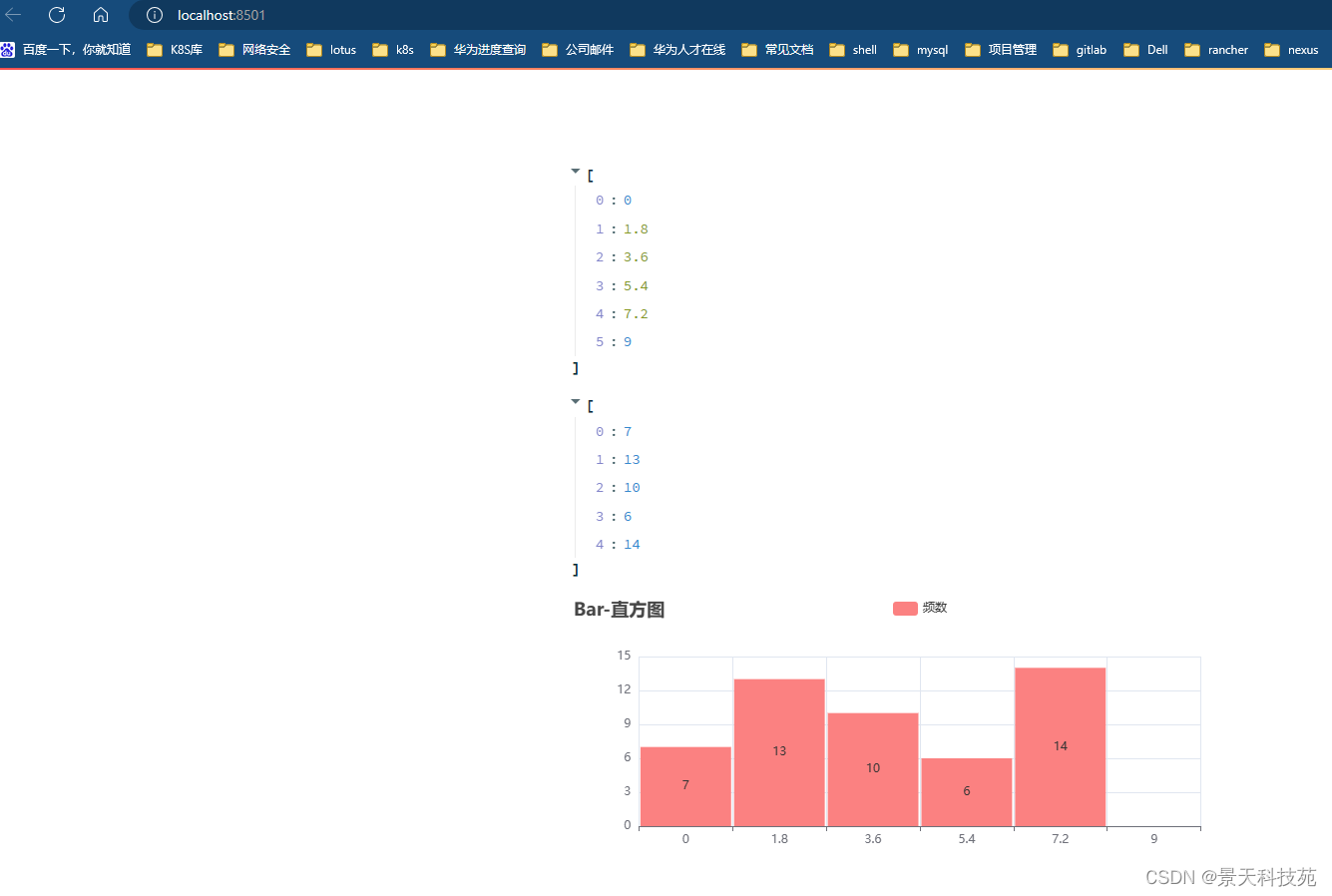
np.histogram是NumPy库中的一个函数,用于计算给定数据的直方图。
直方图是一种统计图表,用于表示数据的分布情况。它将数据划分为多个离散的区间(称为“bin”),并计算每个区间中数据点的频率。
直方图的 x 轴表示数据的取值范围,y 轴表示该取值范围内数据点的数量或频率。
from streamlit_echarts import st_pyecharts
from pyecharts.charts import Bar
from pyecharts import options as opts
import numpy as np
import pandas as pds = pd.Series(data=np.random.randint(0,10,size=(50)))#返回值有两个,分别是频率和区间
y,x = np.histogram(s,bins=5)x = x.tolist()
y = y.tolist()
x,y
c = (Bar().add_xaxis(x).add_yaxis("频数", y,category_gap=3, # 设置柱子之间的间距为3color='#ff8080').set_global_opts(title_opts=opts.TitleOpts(title="Bar-直方图"))
)st_pyecharts(c)
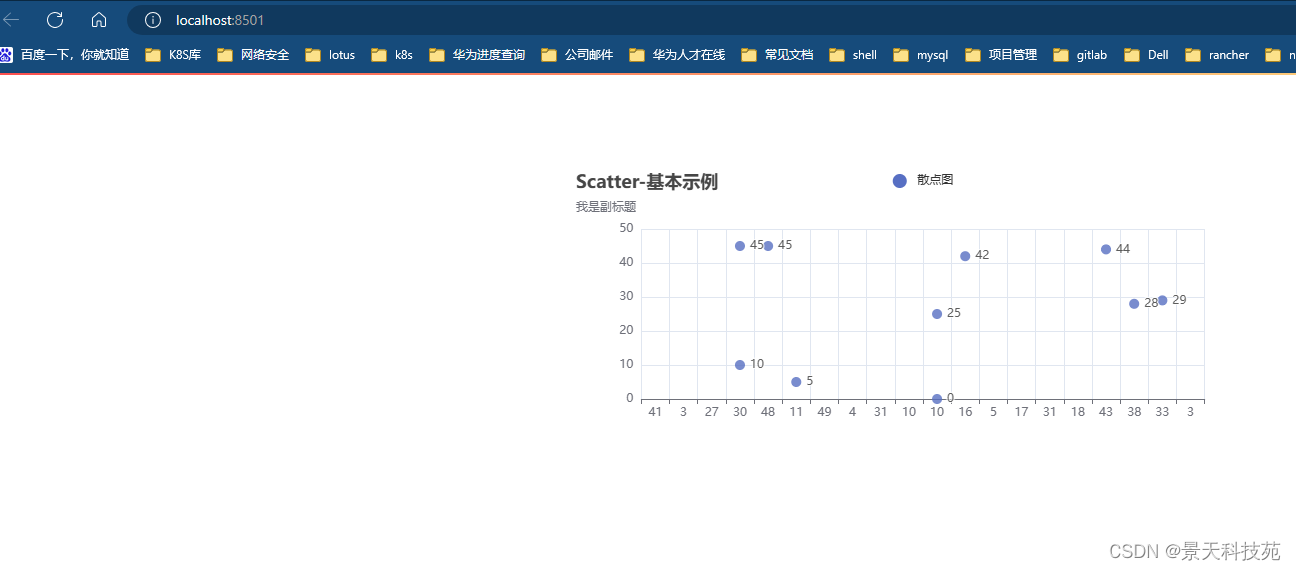
4.散点图
from streamlit_echarts import st_pyecharts
from pyecharts.charts import Scatter
from pyecharts import options as opts
import numpy as np# 示例数据
x = np.random.randint(0,50,size=(20,)).tolist()
y = np.random.randint(0,50,size=(20,)).tolist()#sort_控制排序,默认降序;
#label_opts标签显示位置
scatter = (Scatter().add_xaxis(x).add_yaxis('散点图', y).set_global_opts(title_opts=opts.TitleOpts(title="Scatter-基本示例", subtitle="我是副标题")))st_pyecharts(scatter)
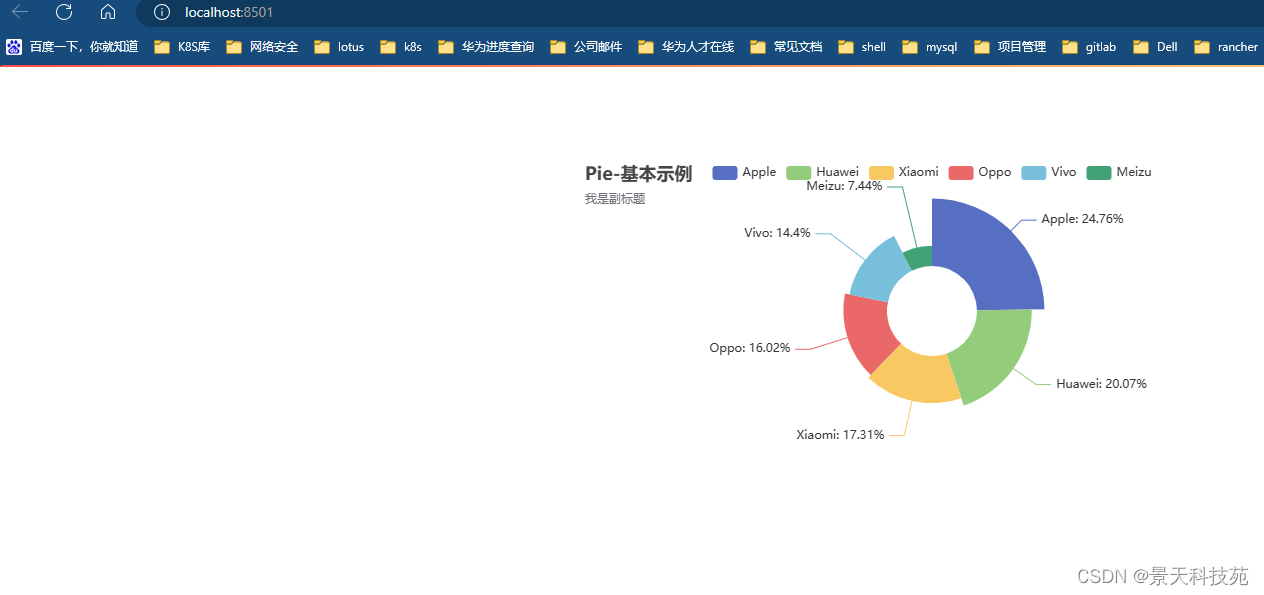
5.饼状图
from streamlit_echarts import st_pyecharts
from pyecharts.charts import Pie
from pyecharts import options as opts# 示例数据
cate = ['Apple', 'Huawei', 'Xiaomi', 'Oppo', 'Vivo', 'Meizu']
data = [153, 124, 107, 99, 89, 46]pie = (Pie().add('i am bobo', [list(z) for z in zip(cate, data)],radius=["30%", "75%"], #设置半径(内外圈半径)rosetype="radius" #半径形式的玫瑰型样式(经典)).set_global_opts(title_opts=opts.TitleOpts(title="Pie-基本示例", subtitle="我是副标题")).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%")))st_pyecharts(pie)
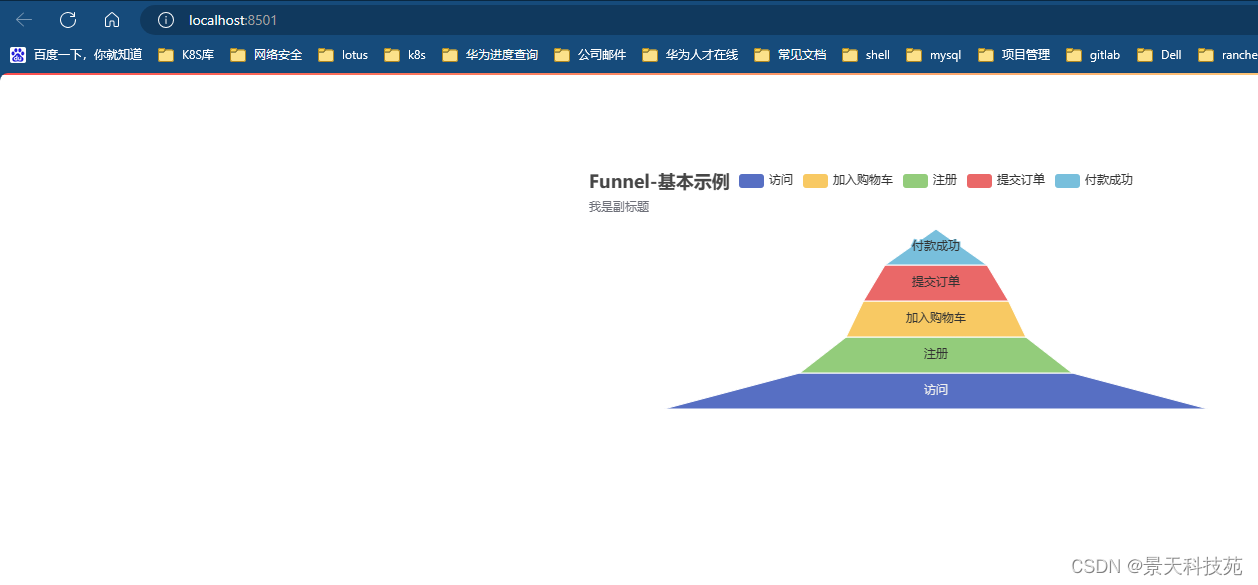
6.漏斗图
from streamlit_echarts import st_pyecharts
from pyecharts.charts import Funnel
from pyecharts import options as opts# 示例数据
cate = ['访问', '注册', '加入购物车', '提交订单', '付款成功']
data = [30398, 15230, 10045, 8109, 5698]
#要想显示转化率需要手动计算存储到data列表中#sort_控制排序,默认降序;
#label_opts标签显示位置
funnel = (Funnel().add("用户数", [list(z) for z in zip(cate, data)],sort_='ascending',label_opts=opts.LabelOpts(position="inside"),).set_global_opts(title_opts=opts.TitleOpts(title="Funnel-基本示例", subtitle="我是副标题")))st_pyecharts(funnel)
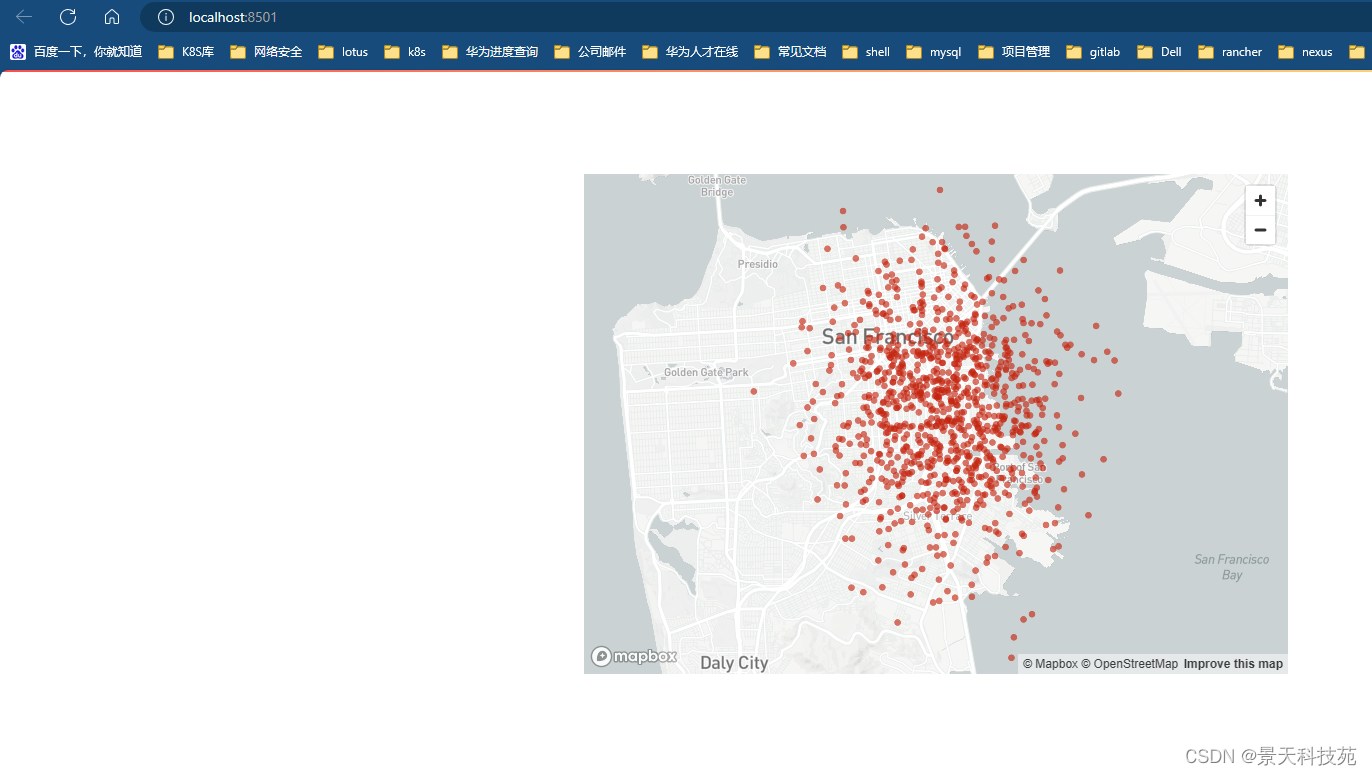
7.地图
import pandas as pd
import streamlit as st
import numpy as npmap_data = pd.DataFrame(np.random.randn(1000, 2) / [50,50] + [37.76,-122.4],columns=['lat', 'lon']
)
#注意:map的数据集中必须要有lat和lon固定列名的两列数据作为经纬度
st.map(map_data)
2.布局
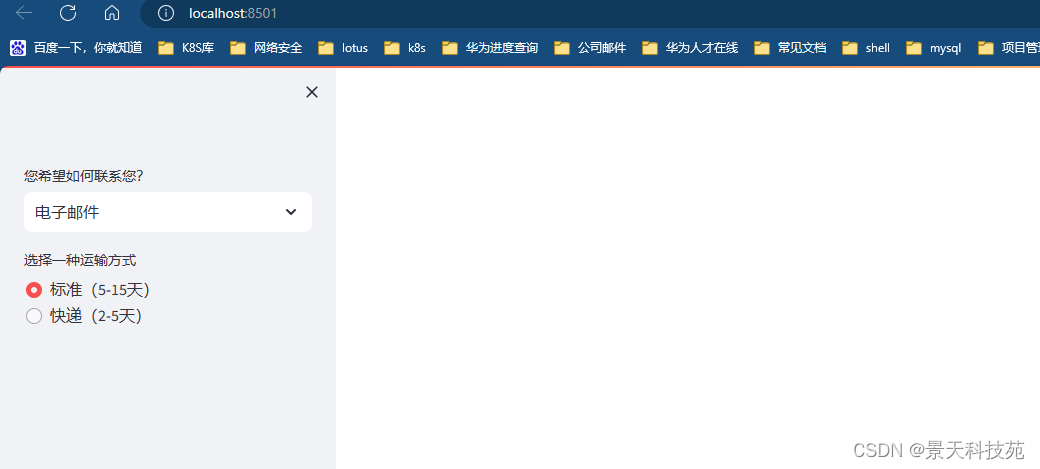
1.st.sidebar - 在侧边栏增添交互元素
import streamlit as st# 方式1:使用对象表示法添加选择框
add_selectbox = st.sidebar.selectbox("您希望如何联系您?",("电子邮件", "家庭电话", "移动电话")
)
# 方式2:使用“with”语法添加单选按钮
with st.sidebar:add_radio = st.radio("选择一种运输方式",("标准(5-15天)", "快递(2-5天)"))
2.st.columns - 并排布局多元素容器
通过调用 st.columns,您可以插入多个多元素容器,并将它们布局为并排的形式。返回的是一个容器对象的列表,每个对象都可以用来添加元素。
您可以选择使用“with”语法(更推荐)或者直接在容器对象上调用方法来添加元素。
import streamlit as stcol1, col2, col3 = st.columns(3)with col1:st.header("一只猫")st.image("https://static.streamlit.io/examples/cat.jpg") #也可以显示视频文件with col2:st.header("一只狗")st.image("https://static.streamlit.io/examples/dog.jpg")with col3:st.header("一只猫头鹰")st.image("https://static.streamlit.io/examples/owl.jpg")

或者您也可以直接在容器对象上调用方法:
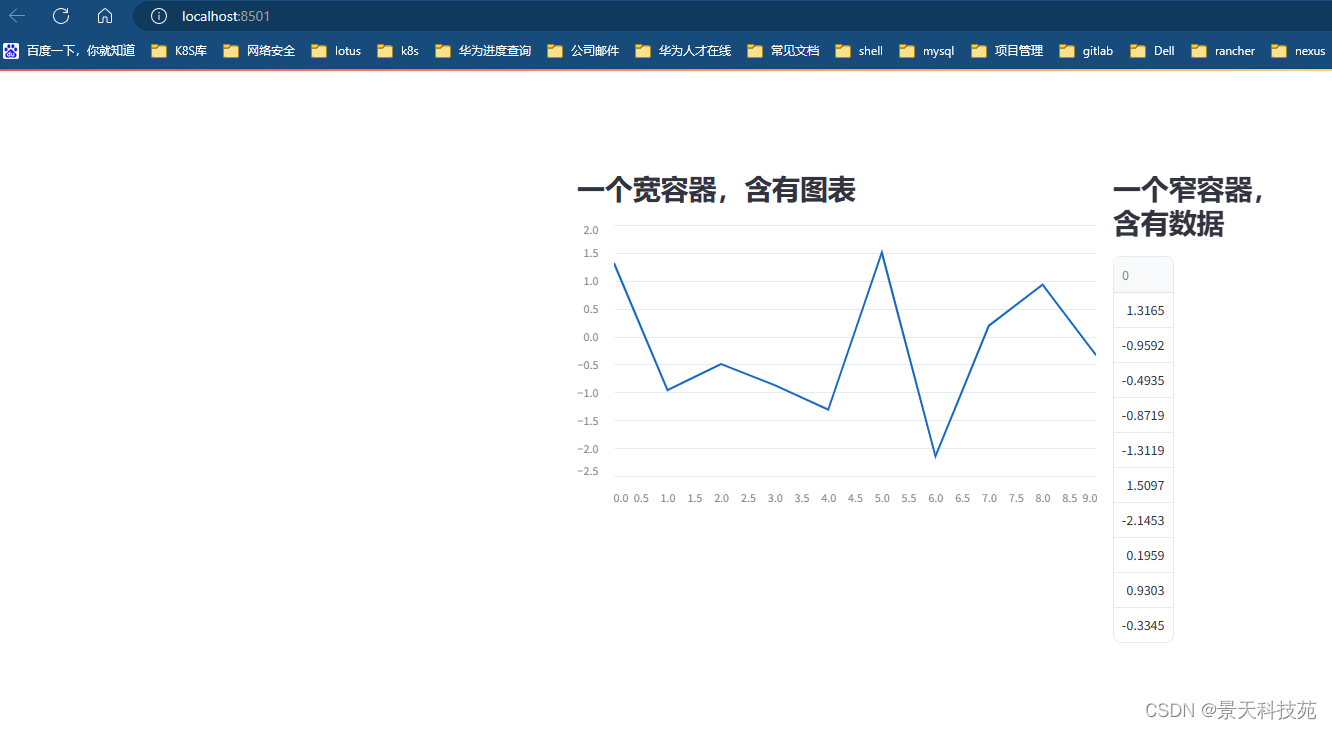
import streamlit as st
import numpy as npcol1, col2 = st.columns([3, 1])
data = np.random.randn(10, 1)col1.subheader("一个宽容器,含有图表")
col1.line_chart(data)col2.subheader("一个窄容器,含有数据")
col2.write(data)
3.st.tabs - 以选项卡形式布局多元素容器
通过调用 st.tabs,您可以插入多个多元素容器作为选项卡。每个选项卡都代表一组相关内容。返回的是一个容器对象的列表,每个对象都可以用来添加元素。与之前一样,您可以选择使用“with”语法或者直接在容器对象上调用方法来添加元素。
需要注意的是,每个选项卡的所有内容都会被一次性发送并渲染在前端。
import streamlit as sttab1, tab2, tab3 = st.tabs(["猫", "狗", "猫头鹰"])with tab1:st.header("一只猫")st.image("https://static.streamlit.io/examples/cat.jpg", width=200)with tab2:st.header("一只狗")st.image("https://static.streamlit.io/examples/dog.jpg", width=200)with tab3:st.header("一只猫头鹰")st.image("https://static.streamlit.io/examples/owl.jpg", width=200)

或者您也可以直接在容器对象上调用方法:
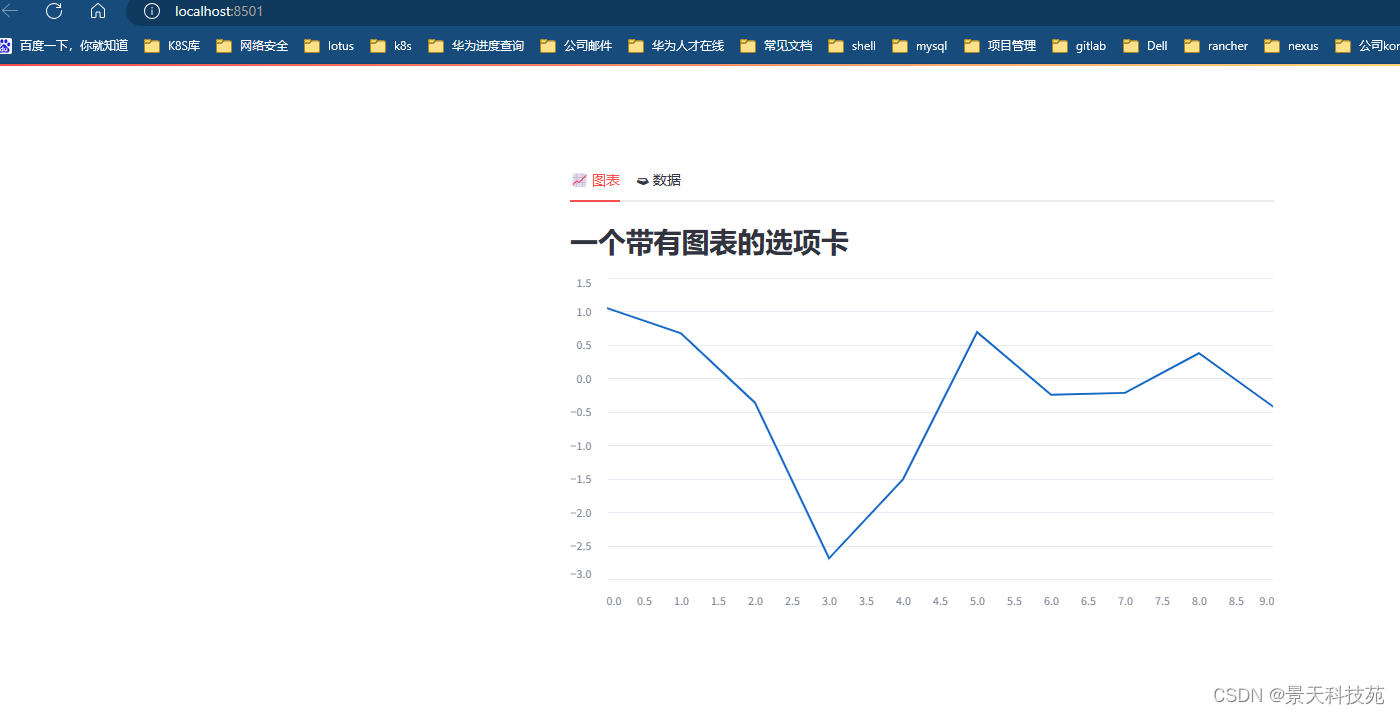
import streamlit as st
import numpy as nptab1, tab2 = st.tabs(["📈 图表", "🗃 数据"])
data = np.random.randn(10, 1)tab1.subheader("一个带有图表的选项卡")
tab1.line_chart(data)tab2.subheader("一个带有数据的选项卡")
tab2.write(data)
4.st.expander - 可展开/折叠的多元素容器
调用 st.expander,您可以插入一个可展开或折叠的容器,用于包含多个元素。容器的初始状态是折叠的,只显示提供的标签。用户可以点击标签来展开容器,查看其中的内容。
import streamlit as stst.bar_chart({"data": [1, 5, 2, 6, 2, 1]})with st.expander("查看说明"):st.write("""上面的图表展示了我为您选择的一些数字。这些数字是通过真实的骰子摇出来的,所以它们*保证*是随机的。""")st.image("https://static.streamlit.io/examples/dice.jpg")
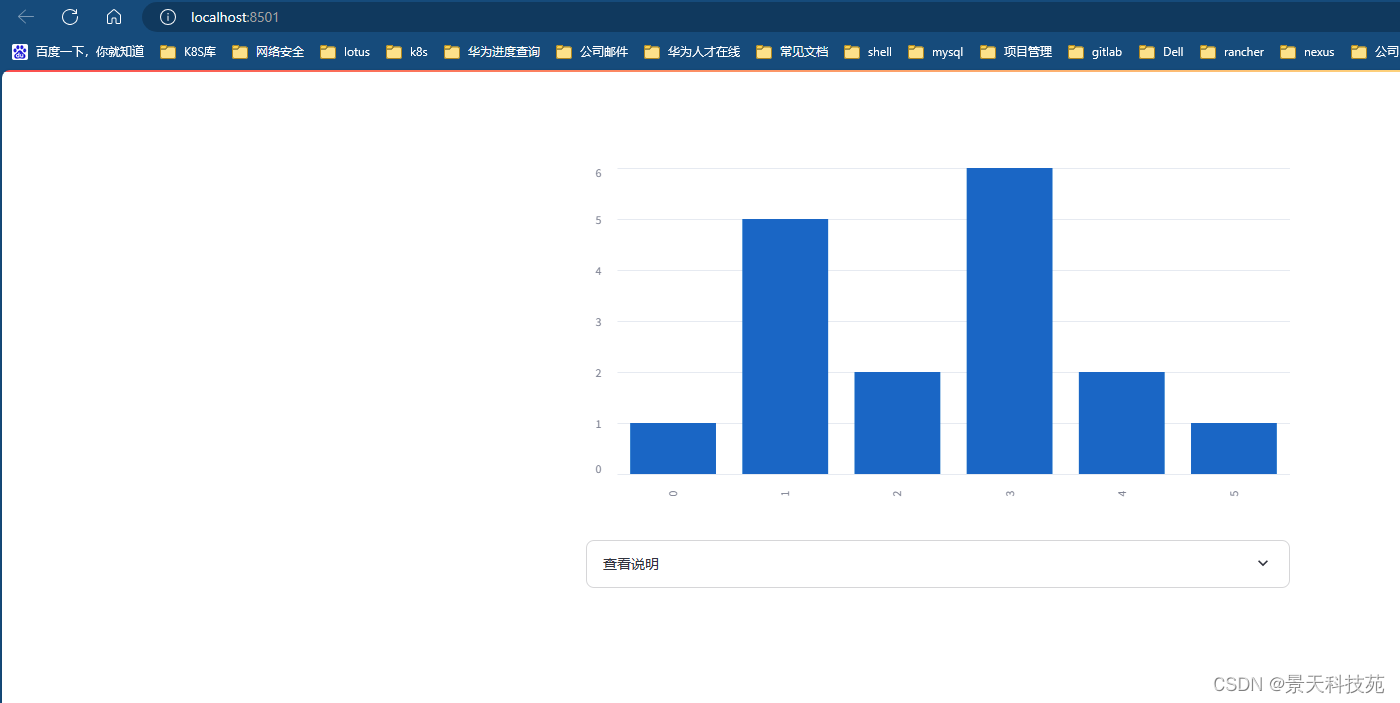
点击展开
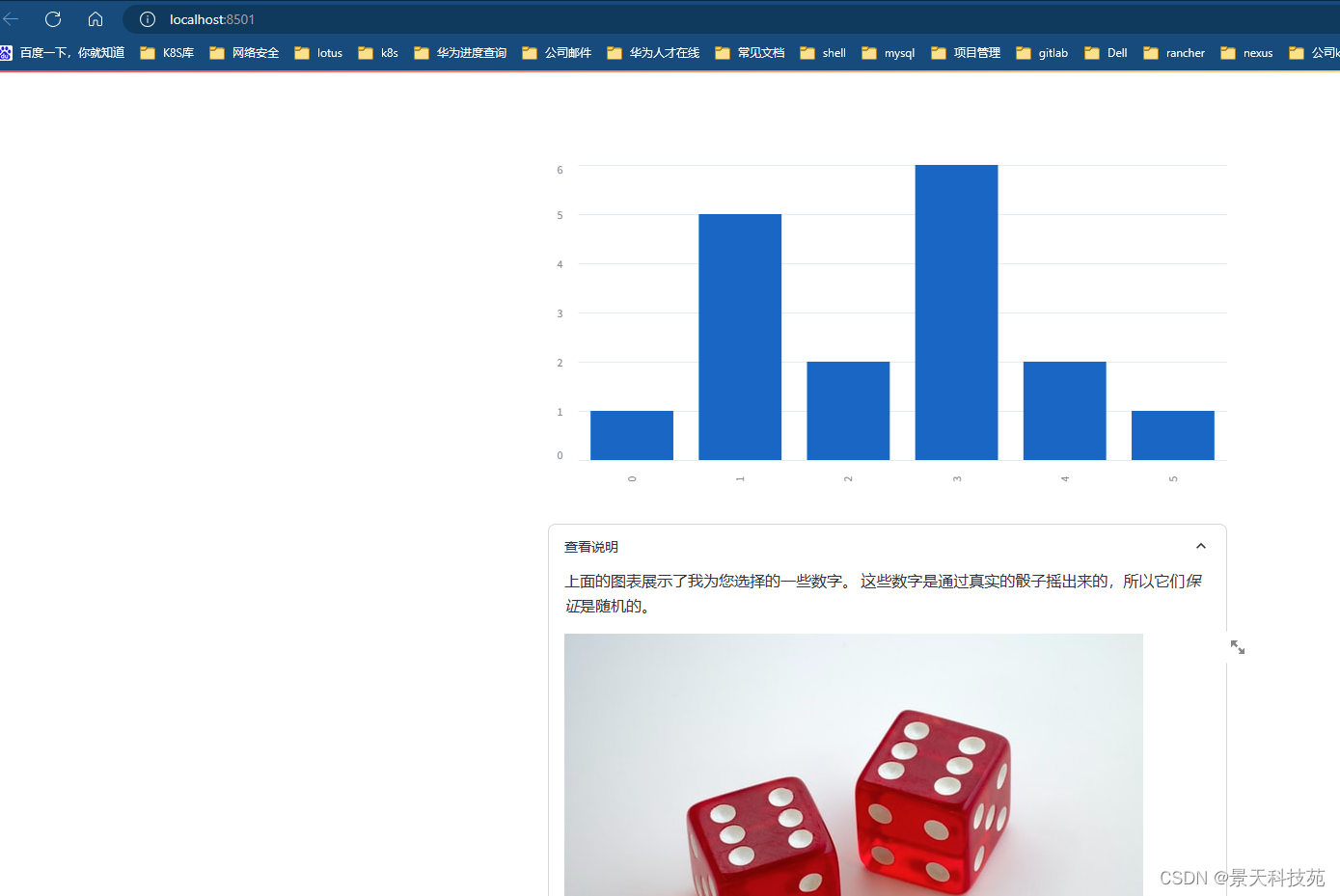
或者您也可以直接在容器对象上调用方法:
import streamlit as stst.bar_chart({"data": [1, 5, 2, 6, 2, 1]})expander = st.expander("查看说明")
expander.write("""上面的图表展示了我为您选择的一些数字。这些数字是通过真实的骰子摇出来的,所以它们*保证*是随机的。
""")
expander.image("https://static.streamlit.io/examples/dice.jpg")
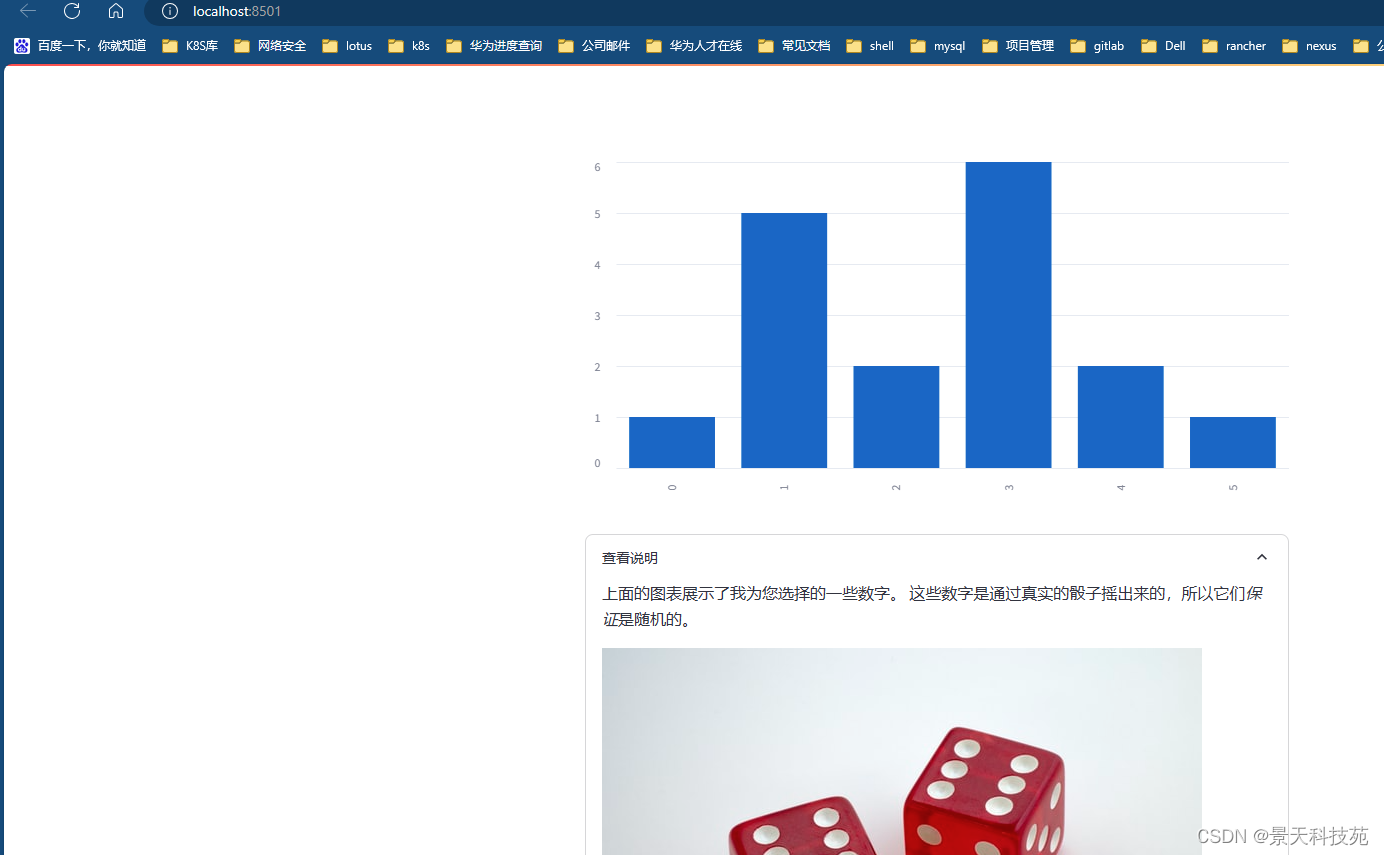
3.实战案例
1.抓取拉勾网招聘岗位数据,并分析展示
注意,运行前需要从网站拿到最新的cookie
完整代码:
import pandas as pd
import streamlit as st
import pandas as pt
import requests
from pyecharts.charts import Line
from pyecharts import options as opts
from streamlit_echarts import st_pyecharts
from pyecharts.charts import Bar
from pyecharts.charts import Pie
from lxml import etree
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0','Cookie':'index_location_city=%E5%85%A8%E5%9B%BD; RECOMMEND_TIP=true; user_trace_token=20231228155703-c428ac53-3dce-4d36-ad4f-f05fefe8ca85; LGUID=20231228155703-bda9a438-ca0b-4cda-b10a-3a0b71bc38d8; _ga=GA1.2.2030589830.1703750224; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1703750224; X_HTTP_TOKEN=1f6c74284fa5532a0363573071dfaca58ed0547982; JSESSIONID=ABAABJAABGBABEB1242F78FD52E6AFAF225BE4AEF12E1D9; WEBTJ-ID=20240313095127-18e3581e05c5b7-005c92cce50259-4c657b58-2073600-18e3581e05d13a9; sensorsdata2015session=%7B%7D; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2218cae00e03e16e3-0cea6da040cc57-26031051-2073600-18cae00e03f24e8%22%2C%22first_id%22%3A%22%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24os%22%3A%22Windows%22%2C%22%24browser%22%3A%22Chrome%22%2C%22%24browser_version%22%3A%22122.0.0.0%22%7D%2C%22%24device_id%22%3A%2218cae00e03e16e3-0cea6da040cc57-26031051-2073600-18cae00e03f24e8%22%7D'
}
#按钮点击事件-数据爬取+保存
def get_job_msg():fp = open('./job_msg.csv', 'a',encoding='utf-8')for page in range(2,5):url = f'https://www.lagou.com/wn/zhaopin?fromSearch=true&kd=%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590%25E5%25B8%2588&labelWords=sug&suginput=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&pn={page}'page_text = requests.get(url, headers=headers).texttree = etree.HTML(page_text)div_list = tree.xpath('//*[@id="jobList"]/div[1]/div')for div in div_list:job_title_area = div.xpath('./div[1]/div[1]/div[1]/a//text()')salary_degree = div.xpath('./div[1]/div[1]/div[2]//text()')#岗位名称job_title = job_title_area[0]# 地区areaarea = job_title_area[1]#薪资salary = salary_degree[0]#学历degreedegree = div.xpath('./div[1]/div[1]//div[@class="p-bom__JlNur"]/text()')[0]#公司名称company_titlecompany_title = div.xpath('./div[1]/div[2]/div[1]/a/text()')[0]#公司信息company_msgcompany_msg = div.xpath('./div[1]/div[2]/div[2]/text()')if company_msg:company_msg = company_msg[0]else:company_msg = "暂无信息"#公司福利company_welfarecompany_welfare = div.xpath('./div[2]/div[2]/text()')[0]#岗位要求job_requirejob_require = div.xpath('./div[2]/div[1]/span/text()')if job_require:job_require = job_require[0]else:job_require = "暂无信息"fp.write(job_title+'#'+salary+'#'+area+'#'+degree+'#'+company_title+'#'+company_msg+'#'+company_welfare+'#'+job_require+'\n')fp.close()st.write('数据抓取结束')#按钮点击事件-数据展示
def load_show():df = pd.read_csv('./job_msg.csv',sep='#',names=['岗位名称','薪资','地区','学历/经验要求','公司名称','公司信息','福利','岗位要求'],encoding='utf-8')return dfif __name__ == '__main__':#侧边栏布局st.sidebar.text('数据爬取+存储:')#数据爬取+保存isClick_btn1 = st.sidebar.button(label='开始吧')if isClick_btn1:get_job_msg()st.sidebar.text('数据加载+展示:')#数据加载+展示isClick_btn2 = st.sidebar.button(label='一键启动')if isClick_btn2:df = load_show()# 折叠展示数据表格with st.expander("岗位信息", expanded=True):st.write(df)#侧边栏下拉框add_selectbox = st.sidebar.selectbox(label="数据分析:",options=('请选择','不同城市岗位数量&平均薪资','不同经验的岗位占比','不同学历的岗位数量'))#获取下拉选项if add_selectbox == '不同城市岗位数量&平均薪资':table = load_show()def get_city_name(x):return x.split('·')[0].split('[')[1]table['city'] = table['地区'].map(get_city_name)#不同城市岗位数量city_job_count_s = table.groupby(by='city').size().sort_values(ascending=False)#不同城市平均薪资# 求出salary每个元素表示薪资范围的均值:7k-10kret = table['薪资'].str.extract(r'(\d+)k-(\d+)k')# 注意:正则返回结果为字符串类型,将其转成数字类型ret = ret.astype('int')table['mean_sal'] = ret.apply(lambda s:s.mean(), axis=1)table['mean_sal'] = table['mean_sal']mean_sal_city = table.groupby(by='city')['mean_sal'].mean().sort_values(ascending=False)mean_sal_city = mean_sal_city.map(lambda x:format(x,'.2f'))#绘制柱状图b = (Bar().add_xaxis(city_job_count_s.index.tolist()).add_yaxis("岗位数量", city_job_count_s.values.tolist()).add_yaxis("平均薪资", mean_sal_city.values.tolist()).set_global_opts(title_opts=opts.TitleOpts(title="岗位分析", subtitle="不同城市的岗位数量&平均薪资"), # 工具栏toolbox_opts=opts.ToolboxOpts(),))st_pyecharts(b)if add_selectbox == '不同经验的岗位占比':table = load_show()#学历table["degree"] = table['学历/经验要求'].str.extract('(.*)/(.*)')[0]ret = table.groupby(by='degree').size()#饼图cate = ret.index.tolist()data = ret.values.tolist()pie = (Pie().add('i am bobo', [list(z) for z in zip(cate, data)],radius=["30%", "75%"], # 设置半径(内外圈半径)rosetype="radius" # 半径形式的玫瑰型样式(经典)).set_global_opts(title_opts=opts.TitleOpts(title="数据分析", subtitle="经验占比")).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%")))st_pyecharts(pie)if add_selectbox == '不同学历的岗位数量':st.write('兄弟们,自己玩起来吧!')
展示效果:
点开始吧,开始抓取数据,并保存到本地csv文件
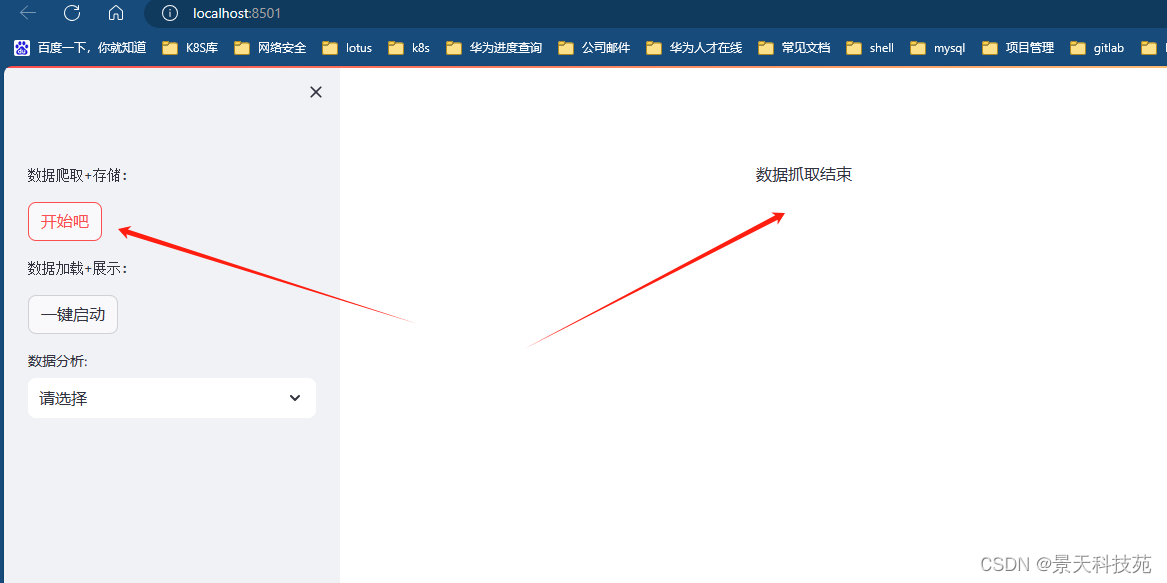
点击一键启动,就会展示抓取的表格数据
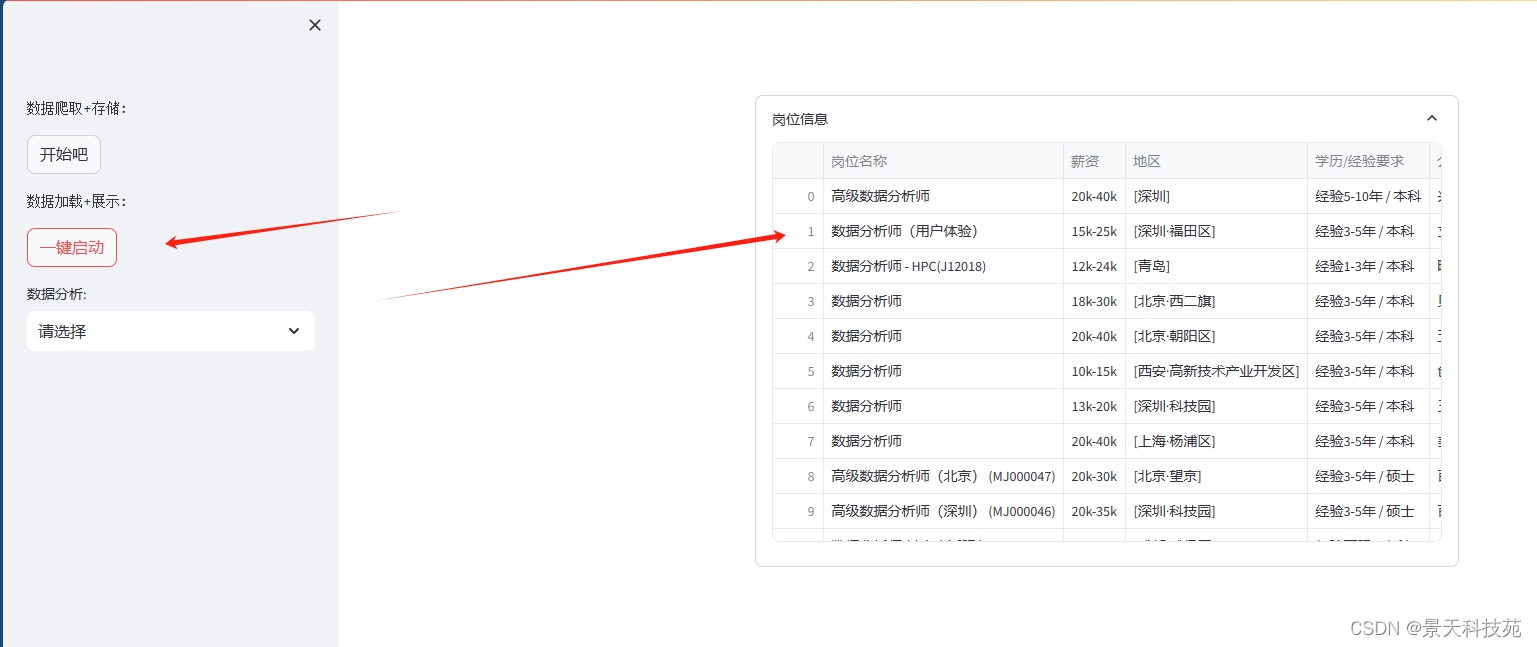
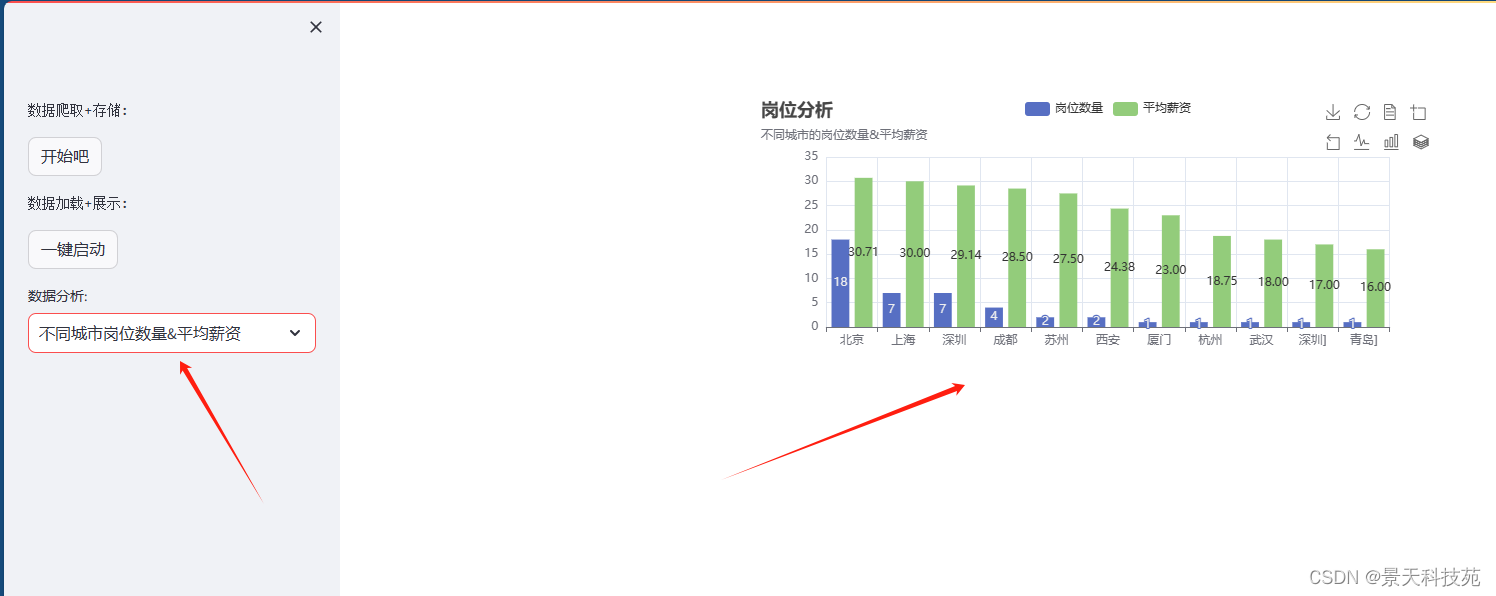
点击下拉框选择展示不同数据

2. 从本地表格读取数据,并进行可视化展示
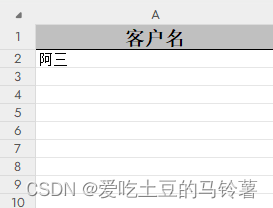
先看下原数据表
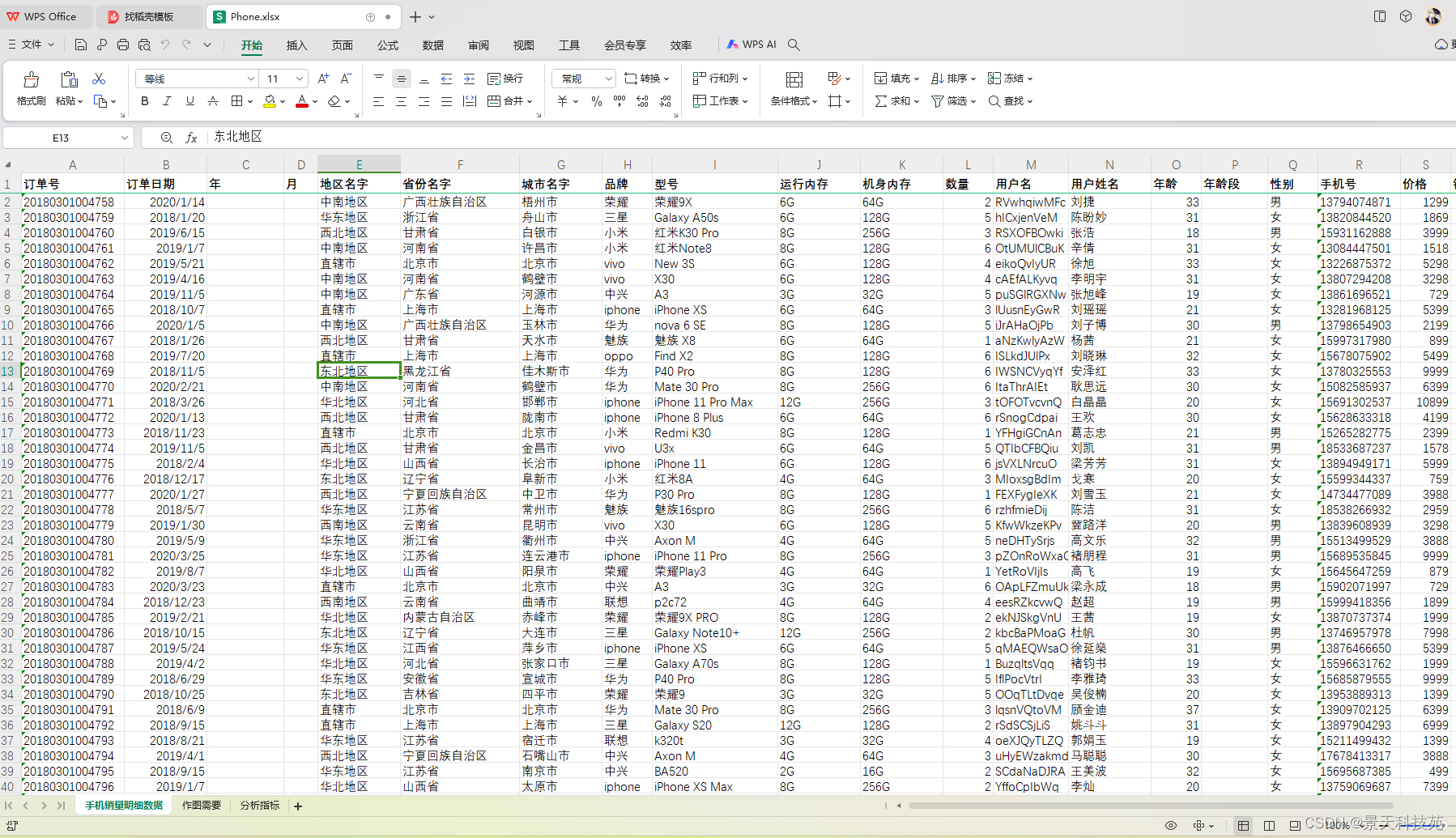
实战代码:
import pandas as pdimport streamlit as st
from pyecharts.charts import Pie,Scatter,Funnel,Page,Line,Bar
from pyecharts import options as opts
from streamlit_echarts import st_pyecharts# st.set_page_config(layout='wide')#装饰器,做数据缓存的,如果数据量比较大,不用每次都要重新加载,而是在数据第一次加载时,将数据保存到缓存中,下次直接使用
@st.cache_data
def load_data():data = pd.read_excel('Phone.xlsx')#缺失值处理data['年'] = data['订单日期'].dt.yeardata['月'] = data['订单日期'].dt.month#数据分箱:data['年龄段'] = pd.cut(data['年龄'],bins=[16,30,40,50],labels=['16-30','30-40','40-50'],right=False)#手机号脱敏处理def func(x):return str(x).replace(str(x)[3:7],'****')data['手机号'] = data['手机号'].map(func)return datadata = load_data() #加载数据
#侧边栏布局年份选择
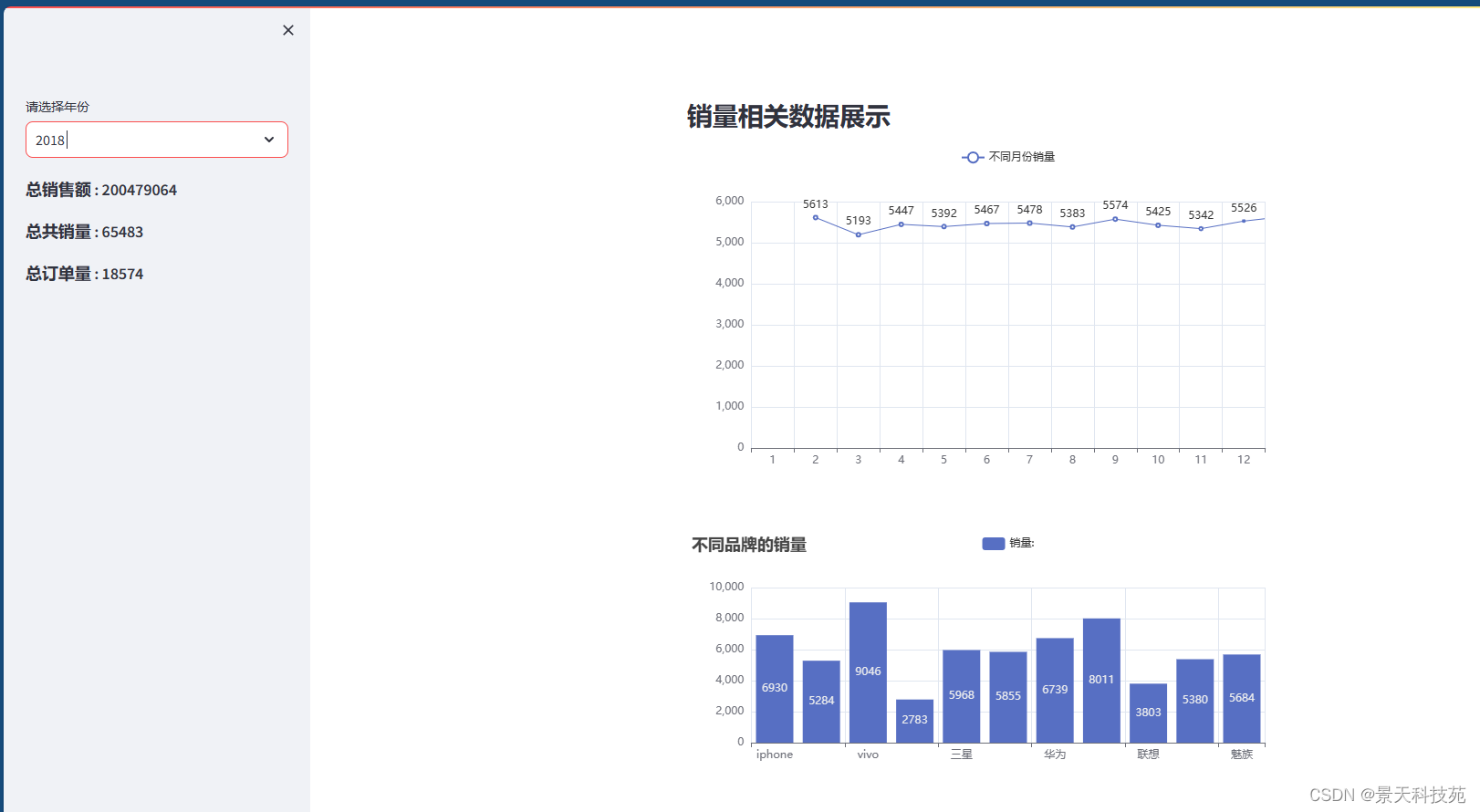
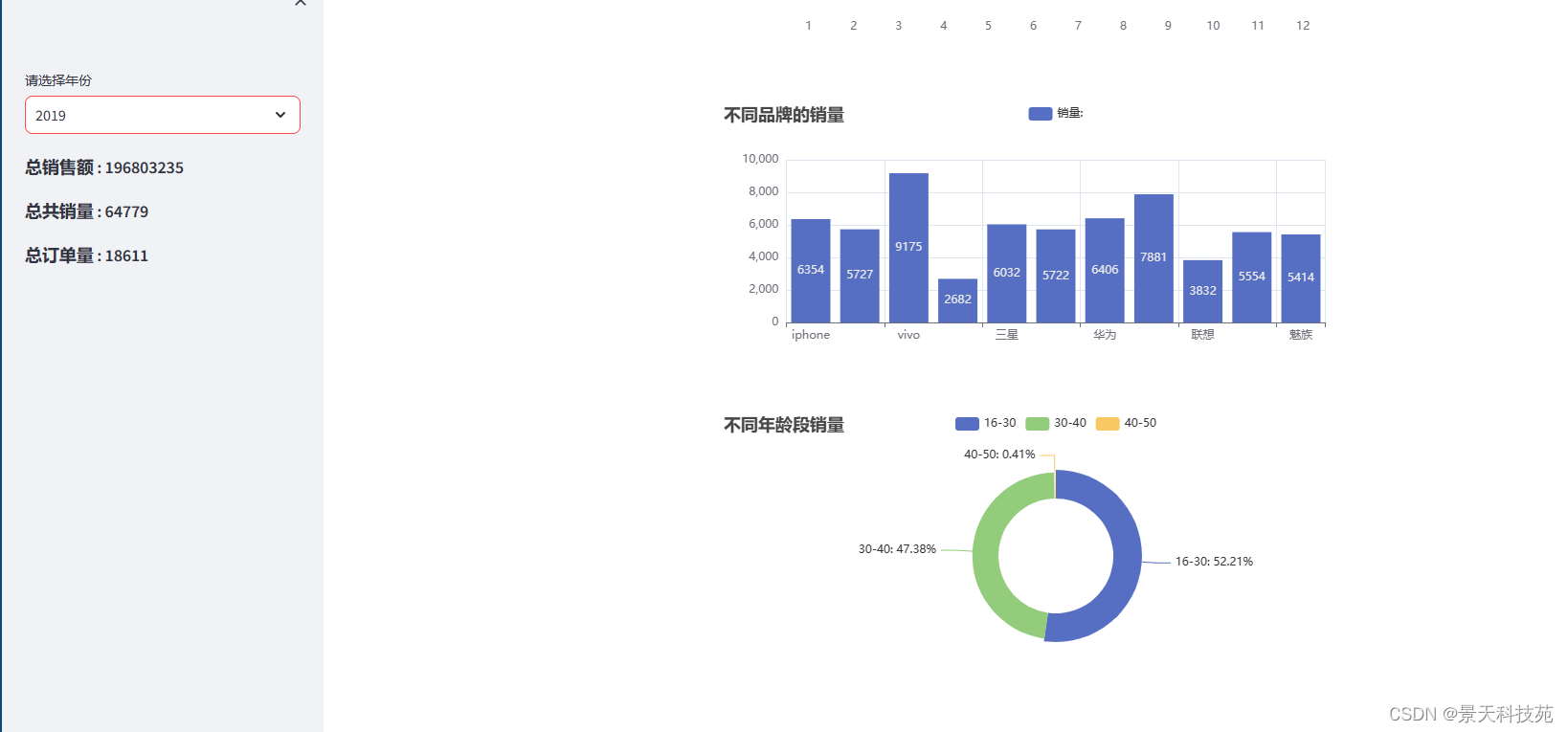
with st.sidebar:# 不同年份years = data['年'].unique().tolist()#下拉选中的年份值select_value = st.selectbox(label='请选择年份',options=years)#计算对应年份的总销量和总销售额year_data = data.loc[data['年']==select_value]#总销售额year_total_amount = year_data['销售额'].sum()st.markdown('### 总销售额 : '+str(year_total_amount))#总销量year_total_product = year_data['数量'].sum()st.markdown('### 总共销量 : ' + str(year_total_product))#总订单数year_total_count = year_data.shape[0]st.markdown('### 总订单量 : ' + str(year_total_count))st.subheader('销量相关数据展示')
#月份和销售额
month_data = year_data.groupby(by='月')['数量'].sum()
indexs = month_data.index.tolist()
values = month_data.values.tolist()
#画图
line = (Line().add_xaxis(indexs).add_yaxis('不同月份销量', values).set_global_opts(title_opts=opts.TitleOpts('不同月份销量')))
#渲染到页面中
st_pyecharts(line,height=400)#不同品牌与销量
good_data = year_data.groupby(by='品牌')['数量'].sum()
indexs = good_data.index.tolist()
values = good_data.values.tolist()
b = (Bar().add_xaxis(indexs).add_yaxis("销量:", values).set_global_opts(title_opts=opts.TitleOpts(title="不同品牌的销量"))
)
st_pyecharts(b)#年龄段和销售额
age_data = year_data.groupby(by='年龄段')['数量'].sum()
indexs = age_data.index.tolist()
values = age_data.values.tolist()
pie = (Pie().add('销量', [list(item) for item in zip(indexs,values)],radius=["40%", "60%"], #设置半径(内外圈半径)rosetype="radius", #半径形式的玫瑰型样式(经典)label_opts=opts.LabelOpts(is_show=False, position="center")).set_global_opts(title_opts=opts.TitleOpts(title="不同年龄段销量")).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%")))
st_pyecharts(pie)
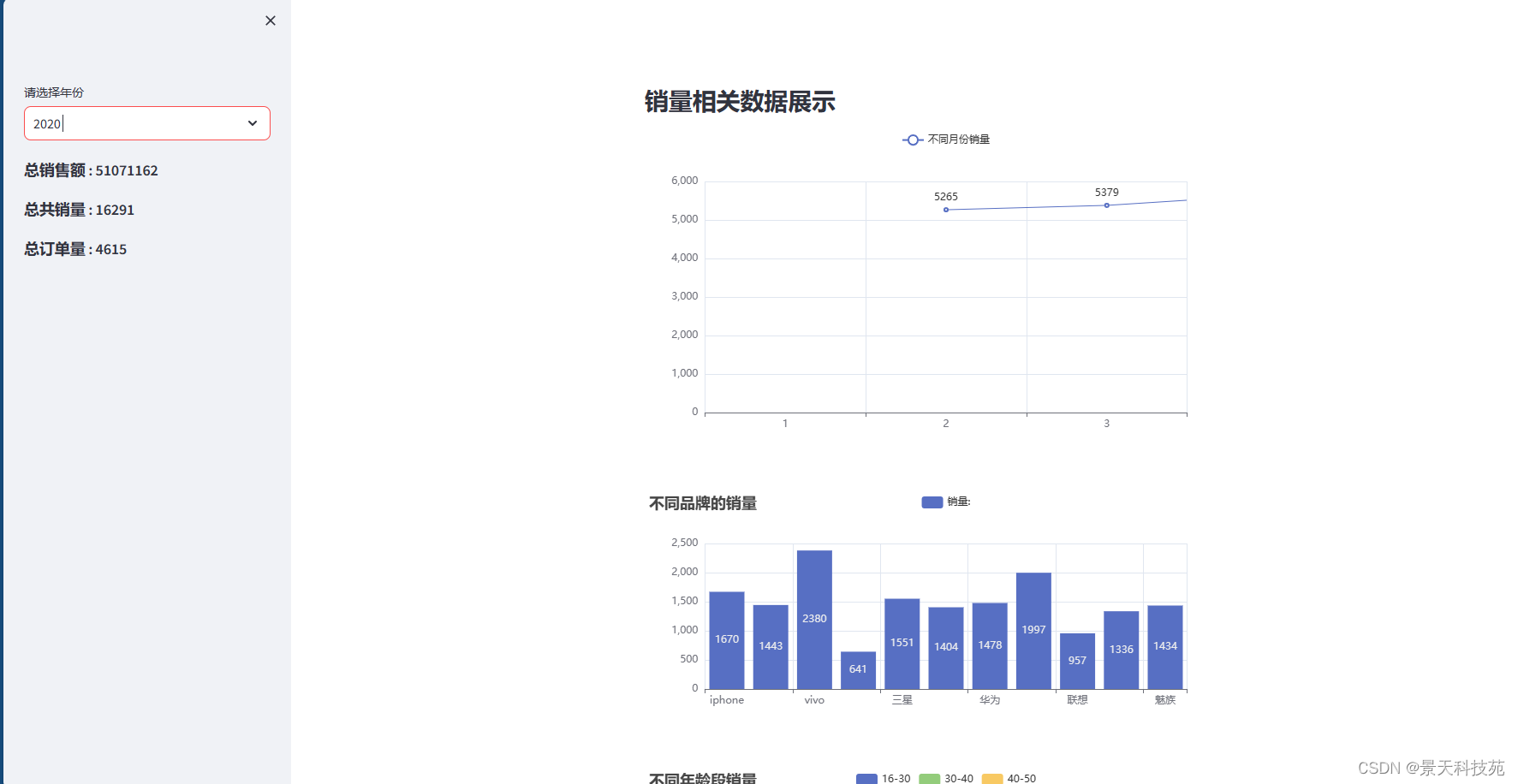
可以选取不同年份展示