参考文档:
- CountDownLatch、CyclicBarrier、Semaphore的用法和区别
- juc15_基本AtomicInteger、数组、引用AtomicStampedReference、对象的属性修改原子类 AtomicIntegerFieldUp 、原子操作增强类LongAdder
辅助工具类
CountDownLatch(闭锁) 做减法
允许一个或多个线程等待直到在其他线程中执行的一组操作完成的同步辅助。
CountDownLatch用给定的计数初始化。 await方法阻塞,直到由于countDown()方法的调用而导致当前计数达到零,之后所有等待线程被释放,并且任何后续的await 调用立即返回。 这是一个一次性的现象 - 计数无法重置。 如果您需要重置计数的版本,考虑使用CyclicBarrier 。CountDownLatch是一种通用的同步工具,可用于多种用途。
- 一个CountDownLatch为一个计数的CountDownLatch用作一个简单的开/关锁存器,或者门:所有线程调用await在门口等待,直到被调用countDown()的线程打开。
- 一个CountDownLatch初始化N可以用来做一个线程等待,直到N个线程完成某项操作,或某些动作已经完成N次。
构造方法
//参数count为计数值
public CountDownLatch(int count) {};
CountDownLatch的构造函数接收一个 int类型的参数作为计数器,如果你想等待 N个点完成,这里就传入 N。当我们调用 CountDownLatch的 countDown方法时, N就会减 1。 CountDownLatch的 await方法会阻塞当前线程,直到 N变成零。由于 countDown方法可以用在任何地方,所以这里说的 N个点,可以是 N个线程,也可以是 1个线程里的 N个执行步骤。用在多个线程时,只需要把这个 CountDownLatch的引用传递到线程里即可。
注意:
- 计数器必须大于等于 0,只是等于 0时候,计数器就是零,调用 await方法时不会阻塞当前线程。
- CountDownLatch不可能重新初始化或者修改 CountDownLatch对象的内部计数器的值。
常用方法
// 调用 await() 方法的线程会被挂起,它会等待直到 count 值为 0 才继续执行
public void await() throws InterruptedException {};
// 和 await() 类似,若等待 timeout 时长后,count 值还是没有变为 0,不再等待,继续执行
public boolean await(long timeout, TimeUnit unit) throws InterruptedException {};
// 会将 count 减 1,直至为 0
public void countDown() {};
// 返回当前count值
public long getCount() {}
- CountDownLatch主要有两个方法,当一个或多个线程调用await方法时,这些线程会阻塞
- 其它线程调用countDown方法会将计数器减1(调用countDown方法的线程不会阻塞)
- 计数器的值变为0时,因await方法阻塞的线程会被唤醒,继续执行
代码验证
实验CountDownLatch去解决时间等待问题
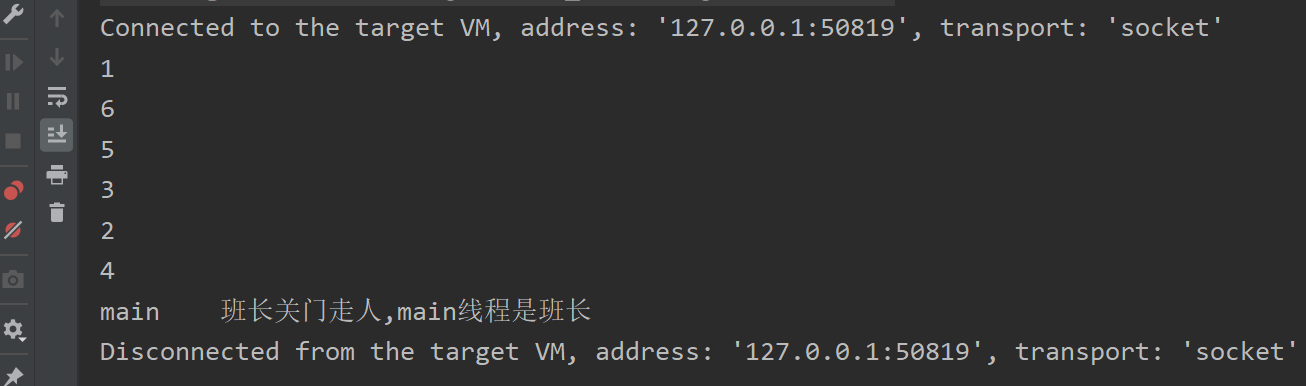
//需求:要求6个线程都执行完了,mian线程最后执行
public class CountDownLatchDemo {public static void main(String[] args) throws Exception{CountDownLatch countDownLatch=new CountDownLatch(6);for (int i = 1; i <=6; i++) {new Thread(()->{System.out.println(Thread.currentThread().getName()+"\t");countDownLatch.countDown();},i+"").start();}countDownLatch.await();System.out.println(Thread.currentThread().getName()+"\t班长关门走人,main线程是班长");}
}
多个线程完成后,进行汇总合并
public class AtomicIntegerDemo {AtomicInteger atomicInteger = new AtomicInteger(0);public void addPlusPlus() {atomicInteger.incrementAndGet();}public static void main(String[] args) throws InterruptedException {CountDownLatch countDownLatch = new CountDownLatch(10);AtomicIntegerDemo atomic = new AtomicIntegerDemo();// 10个线程进行循环100次调用addPlusPlus的操作,最终结果是10*100=1000for (int i = 1; i <= 10; i++) {new Thread(() -> {try {for (int j = 1; j <= 100; j++) {atomic.addPlusPlus();}} finally {countDownLatch.countDown();}}, String.valueOf(i)).start();}//(1). 如果不加上下面的停顿3秒的时间,会导致还没有进行i++ 1000次main线程就已经结束了//try { TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) {e.printStackTrace();}//(2). 使用CountDownLatch去解决等待时间的问题countDownLatch.await();System.out.println(Thread.currentThread().getName() + "\t" + "获取到的result:" + atomic.atomicInteger.get());}
}

CyclicBarrier做加法
CyclicBarrier的字面意思是可循环(Cyclic) 使用的屏障(barrier),允许一组线程全部等待彼此达到共同屏障点的同步辅助。它要做的事情是,让一组线程到达一个屏障(也可以叫做同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活,线程进入屏障通过CyclicBarrier的await()方法。屏障被称为_循环_ ,因为它可以在等待的线程被释放之后重新使用。
现实生活中我们经常会遇到这样的情景,在进行某个活动前需要等待人全部都齐了才开始。例如吃饭时要等全家人都上座了才动筷子,旅游时要等全部人都到齐了才出发,比赛时要等运动员都上场后才开始。
在JUC包中为我们提供了一个同步工具类能够很好的模拟这类场景,它就是CyclicBarrier类。利用CyclicBarrier类可以实现一组线程相互等待,当所有线程都到达某个屏障点后再进行后续的操作。
CyclicBarrier字面意思是“可重复使用的栅栏”,CyclicBarrier 相比 CountDownLatch 来说,要简单很多,其源码没有什么高深的地方,它是 ReentrantLock 和 Condition 的组合使用。
构造方法
// parties表示屏障拦截的线程数量,每个线程调用 await 方法告诉 CyclicBarrier
// 我已经到达了屏障,然后当前线程被阻塞。
public CyclicBarrier(int parties)// 用于在线程到达屏障时,优先执行 barrierAction,
//方便处理更复杂的业务场景(该线程的执行时机是在到达屏障之后再执行)
public CyclicBarrier(int parties, Runnable barrierAction)- CyclicBarrier默认的构造方法是 CyclicBarrier (int parties),其参数表示屏障拦截的线程数量,每个线程调用 await方法告诉 CyclicBarrier我已经到达了屏障,然后当前线程被阻塞。
- CyclicBarrier还提供一个更高级的构造函数 CyclicBarrier( int parties Runnable barrier-Action),用于在线程到达屏障时,优先执行 barrierAction,方便处理更复杂的业务场景。
相关方法
// 屏障 指定数量的线程全部调用await()方法时,这些线程不再阻塞
// BrokenBarrierException 表示栅栏已经被破坏,破坏的原因可能是其中一个线程
// await() 时被中断或者超时
public int await() throws InterruptedException, BrokenBarrierExceptionpublic int await(long timeout, TimeUnit unit) throws InterruptedException, B
rokenBarrierException, TimeoutException//循环 通过reset()方法可以进行重置
public void reset()
// 返回触发此障碍所需的参与方数量,即创建CyclicBarrier时构造方法parties参数值
public int getParties() { }代码验证
//集齐7颗龙珠就能召唤神龙
public class CyclicBarrierDemo {public static void main(String[] args) {// public CyclicBarrier(int parties, Runnable barrierAction) {}CyclicBarrier cyclicBarrier = new CyclicBarrier(7, () -> {System.out.println("召唤龙珠");});for (int i = 1; i <= 7; i++) {final int temp = i;new Thread(() -> {System.out.println(Thread.currentThread().getName() + "\t收集到了第" + temp + "颗龙珠");try {cyclicBarrier.await();} catch (InterruptedException e) {e.printStackTrace();} catch (BrokenBarrierException e) {e.printStackTrace();}System.out.println("线程:" + Thread.currentThread().getName() + "等待所有集齐");}, String.valueOf(i)).start();}try { TimeUnit.SECONDS.sleep(6); } catch (InterruptedException e) { e.printStackTrace(); }System.out.println("=============================================================");cyclicBarrier.reset();for (int i = 1; i <= 7; i++) {final int temp = i;new Thread(() -> {System.out.println(Thread.currentThread().getName() + "\t再次收集到了第" + temp + "颗龙珠");try {cyclicBarrier.await();} catch (InterruptedException e) {e.printStackTrace();} catch (BrokenBarrierException e) {e.printStackTrace();}}, String.valueOf(i)).start();}}
}
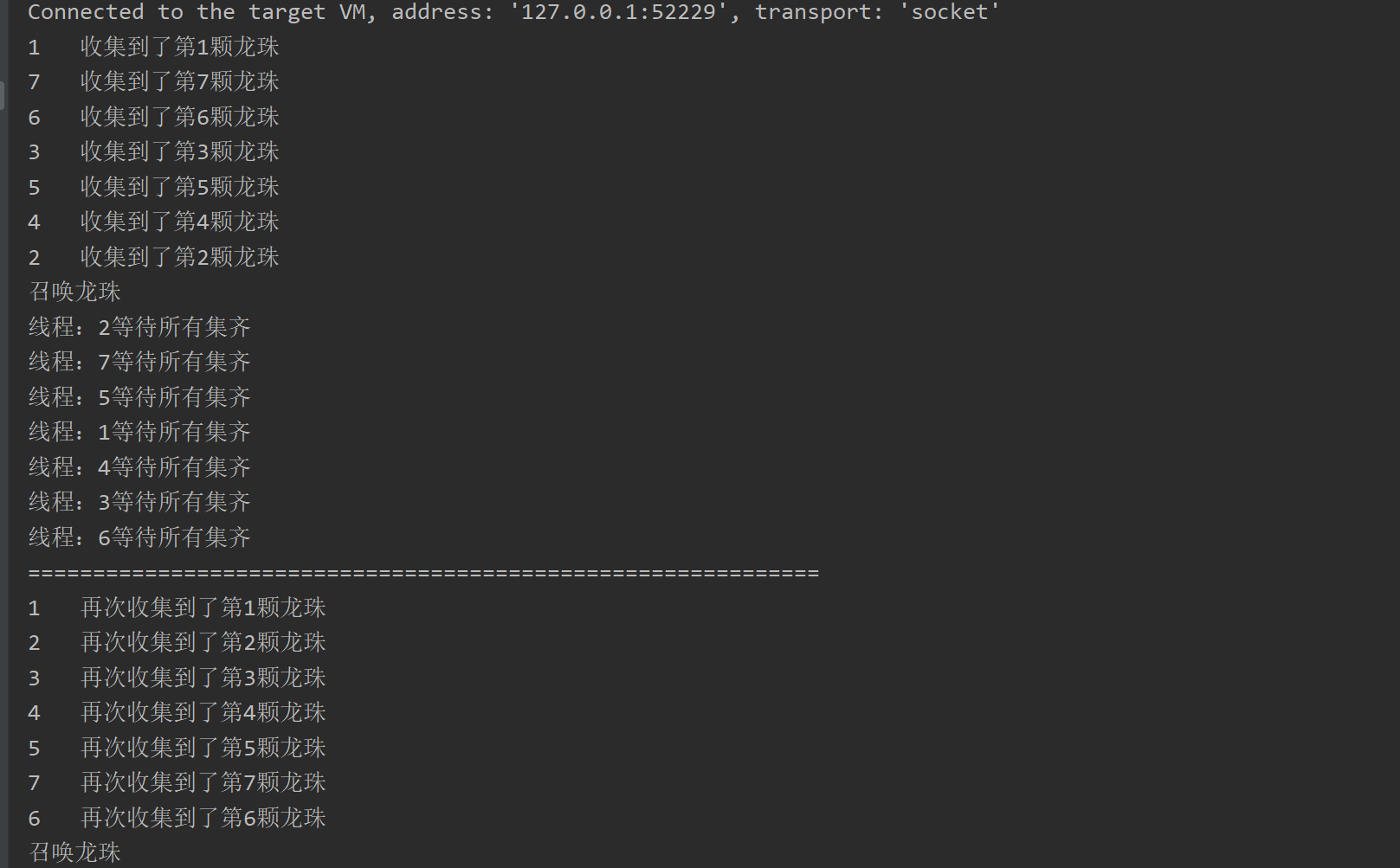
可以用于多线程计算数据,最后合并计算结果的场景。
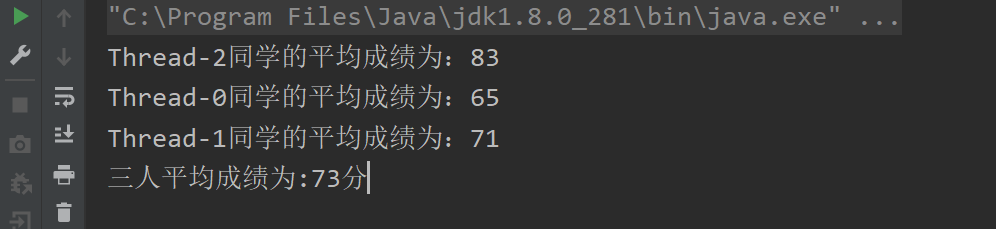
public class CyclicBarrierDemo2 {public static void main(String[] args) {//保存每个学生的平均成绩ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<String, Integer>();CyclicBarrier cb = new CyclicBarrier(3, () -> {int result = 0;Set<String> set = map.keySet();for (String s : set) {result += map.get(s);}System.out.println("三人平均成绩为:" + (result / 3) + "分");});for (int i = 0; i < 3; i++) {new Thread(() -> {//获取学生平均成绩int score = (int) (Math.random() * 40 + 60);map.put(Thread.currentThread().getName(), score);System.out.println(Thread.currentThread().getName() + "同学的平均成绩为:" + score);try {//执行完运行await(),等待所有学生平均成绩都计算完毕cb.await();} catch (InterruptedException | BrokenBarrierException e) {e.printStackTrace();}}).start();}}}
Semaphore
semaphore,俗称信号量,基于 AbstractQueuedSynchronizer 实现。使用 Semaphore 可以控制同时访问资源的线程个数,(信号量)是用来控制同时访问特定资源的线程数量,它通过协调各个线程,以保证合理的使用公共资源。
比如:停车场入口立着的那个显示屏,每有一辆车进入停车场显示屏就会显示剩余车位减 1,每有一辆车从停车场出去,显示屏上显示的剩余车辆就会加 1,当显示屏上的剩余车位为 0 时,停车场入口的栏杆就不会再打开,车辆就无法进入停车场了,直到有一辆车从停车场出去为止。
比如:在学生时代都去餐厅打过饭,假如有 3 个窗口可以打饭,同一时刻也只能有 3 名同学打饭。第 4 个人来了之后就必须在外面等着,只要有打饭的同学好了,就可以去相应的窗口了 。
构造方法
//创建具有给定的许可数和非公平的公平设置的 Semaphore。
Semaphore(int permits) //创建具有给定的许可数和给定的公平设置的 Semaphore。
Semaphore(int permits, boolean fair) - permits 表示许可证的数量(资源数),就好比一个学生可以占用 3 个打饭窗口。
- fair 表示公平性,如果这个设为 true 的话,下次执行的线程会是等待最久的线程。
常用方法
// 表示阻塞并获取许可。
public void acquire() throws InterruptedException
// 方法在没有许可的情况下会立即返回 false,要获取许可的线程不会阻塞。
public boolean tryAcquire()
// 表示释放许可。
public void release()
// 返回此信号量中当前可用的许可证数。
public int availablePermits()
// 返回正在等待获取许可证的线程数。
public final int getQueueLength()
// 是否有线程正在等待获取许可证。
public final boolean hasQueuedThreads()
// 减少 reduction 个许可证。
protected void reducePermits(int reduction)
// 返回所有等待获取许可证的线程集合。
protected Collection<Thread> getQueuedThreads()使用案例
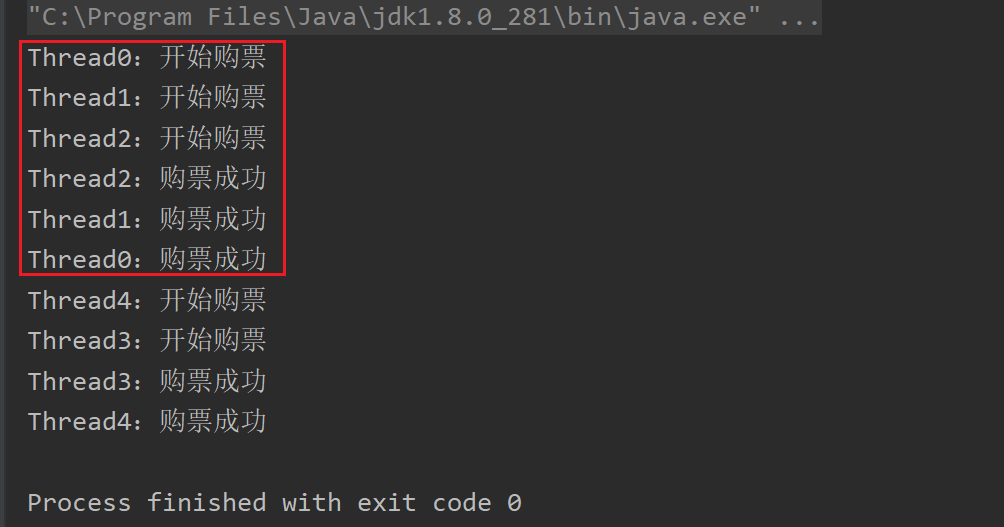
我们可以模拟车站买票,假如车站有 3 个窗口售票,那么同一时刻每个窗口只能存在一个人买票,其他人则等待前面的人完成后才可以去买票。
public class SemaphoreDemo {public static void main(String[] args) {// 3 个窗口Semaphore windows = new Semaphore(3);// 模拟 5 个人购票for (int i = 0; i < 5; i++) {new Thread(() -> {// 占用窗口,加锁try {windows.acquire();System.out.println(Thread.currentThread().getName() + ":开始购票");// 买票try { TimeUnit.SECONDS.sleep(20); } catch (InterruptedException e) { e.printStackTrace(); }System.out.println(Thread.currentThread().getName() + ":购票成功");} catch (InterruptedException e) {e.printStackTrace();} finally {// 释放许可,释放窗口windows.release();}}, "Thread" + i).start();}}
}
Exchanger
Exchanger(交换者)是一个用于线程间协作的工具类。 Exchanger用于进行线程间的数据交换。它提供一个同步点,在这个同步点,两个线程可以交换彼此的数据。这两个线程通过 exchange方法交换数据,如果第一个线程先执行 exchange()方法,它会一直等待第二个线程也执行 exchange方法,当两个线程都到达同步点时,这两个线程就可以交换数据,将本线程生产出来的数据传递给对方。
常用方法
// 等待另一个线程到达此交换点(除非当前线程为 interrupted ),
// 然后将给定对象传输给它,接收其对象作为回报。
V exchange(V x)
// 等待另一个线程到达此交换点(除非当前线程为 interrupted或指定的等待时间已过),
// 然后将给定对象传输给它,接收其对象作为回报
V exchange(V x, long timeout, TimeUnit unit)
使用案例
Exchanger可以用于遗传算法,遗传算法里需要选出两个人作为交配对象,这时候会交换两人的数据,并使用交叉规则得出 2个交配结果。 Exchanger也可以用于校对工作,比如我们需要将纸制银行流水通过人工的方式录入成电子银行流水,为了避免错误,采用 AB岗两人进行录入,录入到 Excel之后,系统需要加载这两个 Excel,并对两个Excel数据进行校对,看看是否录入一致
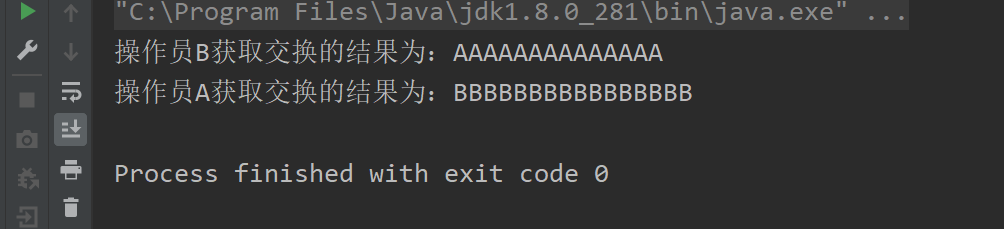
public class ExchangerDemo {public static void main(String[] args) {Exchanger<String> exchanger = new Exchanger<>();new Thread(() -> {String result = "AAAAAAAAAAAAAA";try {String exchange = exchanger.exchange(result);System.out.println(Thread.currentThread().getName() + "获取交换的结果为:" + exchange);} catch (InterruptedException e) {e.printStackTrace();}}, "操作员A").start();new Thread(() -> {String result = "BBBBBBBBBBBBBBBB";try {String exchange = exchanger.exchange(result);System.out.println(Thread.currentThread().getName() + "获取交换的结果为:" + exchange);} catch (InterruptedException e) {e.printStackTrace();}}, "操作员B").start();}
}
如果两个线程有一个没有执行exchange()方法,则会一直等待,如果担心有特殊情况发生,避免一直等待,可以使用 exchange V x longtimeout TimeUnit unit)设置最大等待时长。
总结
CountDownLatch、CyclicBarrier、Semaphore的区别
CountDownLatch 和 CyclicBarrier 都能够实现线程之间的等待,只不过它们侧重点不同:
- CountDownLatch 一般用于某个线程 A 等待若干个其他线程执行完任务之后,它才执行;
- CyclicBarrier一般用于一组线程互相等待至某个状态,然后这一组线程再同时执行;
- CountDownLatch是不能够重用的,而 CyclicBarrier 是可以重用的(reset)。
- Semaphore和锁有点类似,它一般用于控制对某组资源的访问权限。
CountDownLatch 与 Thread.join 的区别
CountDownLatch 的作用就是允许一个或多个线程等待其他线程完成操作,看起来有点类似 join() 方法,但其提供了比 join() 更加灵活的API。
CountDownLatch 可以手动控制在n个线程里调用 n 次 countDown() 方法使计数器进行减一操作,也可以在一个线程里调用 n 次执行减一操作。
而 join() 的实现原理是不停检查 join 线程是否存活,如果 join 线程存活则让当前线程永远等待。所以两者之间相对来说还是 CountDownLatch 使用起来较为灵活。
CyclicBarrier 与 CountDownLatch 区别
- CountDownLatch的计数器只能使用一次,而CyclicBarrier的计数器可以使用reset()方法重置。所以CyclicBarrier能处理更为复杂的业务场景,比如如果计算发生错误,可以重置计数器,并让线程们重新执行一次。
- CyclicBarrier还提供getNumberWaiting(可以获得CyclicBarrier阻塞的线程数量)、isBroken(用来知道阻塞的线程是否被中断)等方法。
- CountDownLatch会阻塞主线程,CyclicBarrier不会阻塞主线程,只会阻塞子线程。
- CountDownLatch和CyclicBarrier都能够实现线程之间的等待,只不过它们侧重点不同。CountDownLatch一般用于一个或多个线程,等待其他线程执行完任务后,再执行。CyclicBarrier一般用于一组线程互相等待至某个状态,然后这一组线程再同时执行。
- CyclicBarrier 还可以提供一个 barrierAction,合并多线程计算结果。
- CyclicBarrier是通过ReentrantLock的"独占锁"和Conditon来实现一组线程的阻塞唤醒的,而CountDownLatch则是通过AQS的“共享锁”实现。
原子操作类
Atomic 原子更新
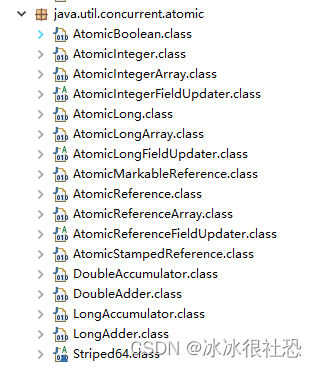
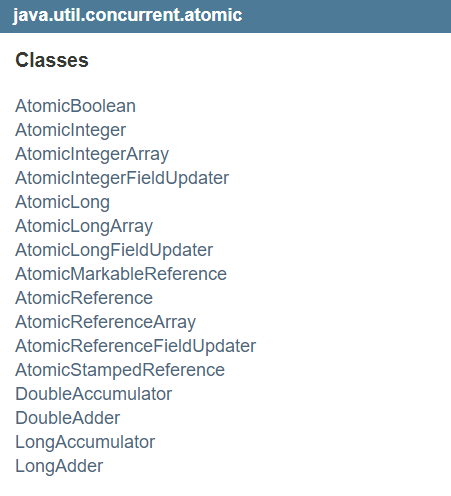
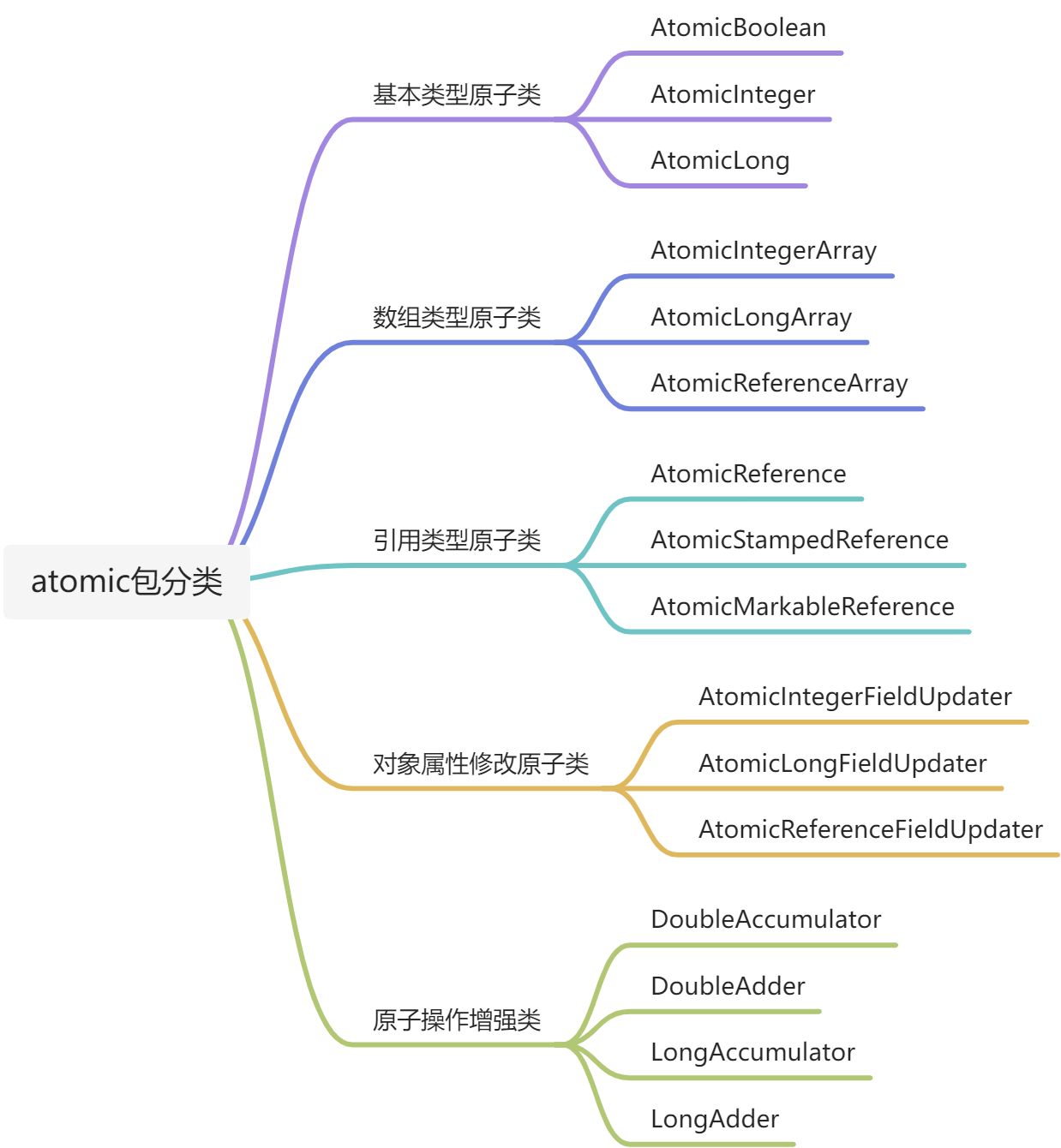
Java 从 JDK1.5 开始提供了 java.util.concurrent.atomic 包,方便程序员在多线程环 境下,无锁的进行原子操作。在 Atomic 包里一共有 12 个类,四种原子更新方式,分别是原子更新基本类型,原子更新数组,原子更新引用和原子更新字段。在 JDK 1.8 之后又新增几个原子类。如下:
- 基本类型原子类(AtomicInteger、AtomicBoolean、AtomicLong)
- 数组类型原子类 (AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray)
- 引用类型原子类 (AtomicReference、AtomicStampedReference、AtomicMarkableReference)
- 对象的属性修改原子类 (AtomicIntegerFieldUpdater、AtomicLongFieldUpdater、AtomicReferenceFieldUpdater)
- 原子操作增强类(DoubleAccumulator 、DoubleAdder 、LongAccumulator 、LongAdder)

基本类型原子类(AtomicInteger、AtomicBoolean、AtomicLong)
常用方法
// 获取当前的值
public final int get()
// 获取到当前的值,并设置新的值
public final int getAndSet(int newValue)
// 获取当前的值,并自增
public final int getAndIncrement()
// 获取到当前的值,并自减
public final int getAndDecrement()
// 获取到当前的值,并加上delta的值
public final int getAndAdd(int delta)
// 返回的是加1后的值
public final int incrementAndGet( )
// 如果输入的数值等于预期值,则自动将值设置为给定的更新值,返回true,否则返回false
boolean compareAndSet(int expect,int update)
AtomicInteger解决 i++ 多线程下不安全问题
CountDownLatch如何在程序中使用
public class AtomicIntegerDemo
{public static final int SIZE = 50;public static void main(String[] args) throws InterruptedException{MyNumber myNumber = new MyNumber();CountDownLatch countDownLatch = new CountDownLatch(SIZE);for (int i = 1; i <=SIZE; i++) {new Thread(() -> {try {for (int j = 1; j <=1000; j++) {myNumber.addPlusPlus();}} finally {countDownLatch.countDown();}},String.valueOf(i)).start();}//等待上面50个线程全部计算完成后,再去获得最终值//暂停几秒钟线程//try { TimeUnit.SECONDS.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); }countDownLatch.await();System.out.println(Thread.currentThread().getName()+"\t"+"result: "+myNumber.atomicInteger.get());}
}

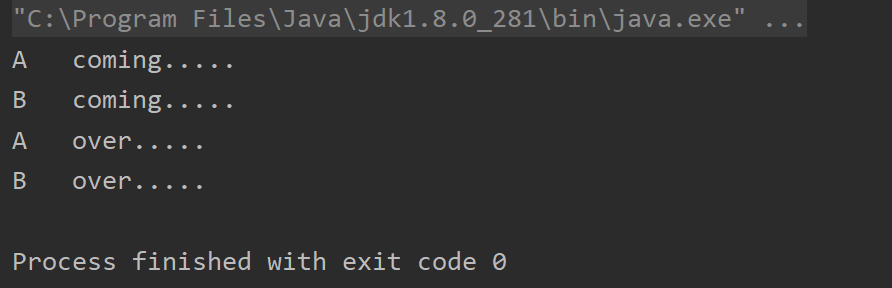
AtomicBoolean可以作为中断标识停止线程的方式
//线程中断机制的实现方法
public class AtomicBooleanDemo {public static void main(String[] args) {AtomicBoolean atomicBoolean = new AtomicBoolean(false);new Thread(() -> {System.out.println(Thread.currentThread().getName() + "\t" + "coming.....");while (!atomicBoolean.get()) {System.out.println("==========");}System.out.println(Thread.currentThread().getName() + "\t" + "over.....");}, "A").start();new Thread(() -> {atomicBoolean.set(true);}, "B").start();}
}AtomicLong自增源码查看
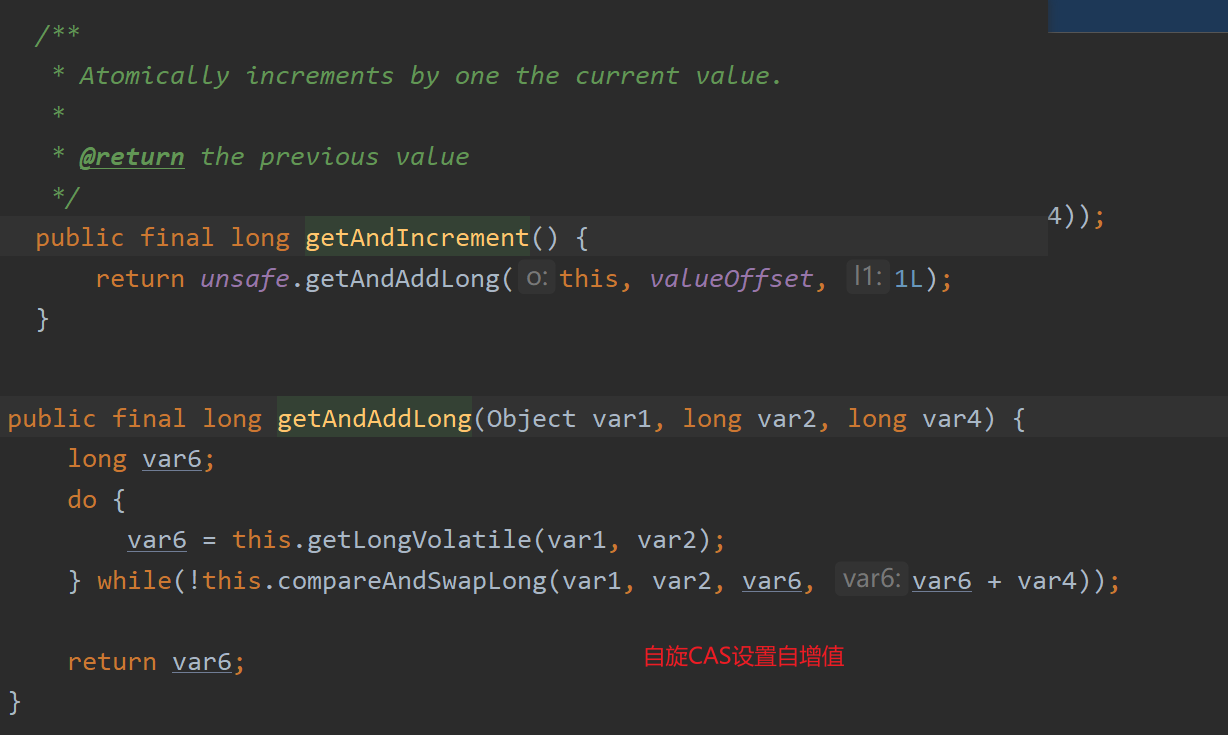
AtomicLong的底层是CAS+自旋锁的思想,适用于低并发的全局计算,高并发后性能急剧下降,原因如下:N个线程CAS操作修改线程的值,每次只有一个成功过,其他N-1失败,失败的不停的自旋直到成功,这样大量失败自旋的情况,一下子cpu就打高了(AtomicLong的自旋会成为瓶颈),在高并发的情况下,我们使用LongAdder。
数组类型原子类 (AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray)
数组类型的原子操作类与基本类型的原子类操作方式相同,只不过可以存储多个数字,在更新或者获取的时候需要指的对应值的下标。
- AtomicIntegerArray:原子更新整型数组里的元素。
- AtomicLongArray:原子更新长整型数组里的元素。
- AtomicReferenceArray:原子更新引用类型数组里的元素。
常用方法
AtomicIntegerArray类主要是提供原子的方式更新数组里的整型,其常用方法如下。
/// 以原子方式将输入值与数组中索引 i的元素相加。
int addAndGet( int i, int delta)
// 如果当前值等于预期值,则以原子方式将数组位置 i的元素设置成 update
boolean compareAndSet( int i, int expect ,int update)原子操作类数组
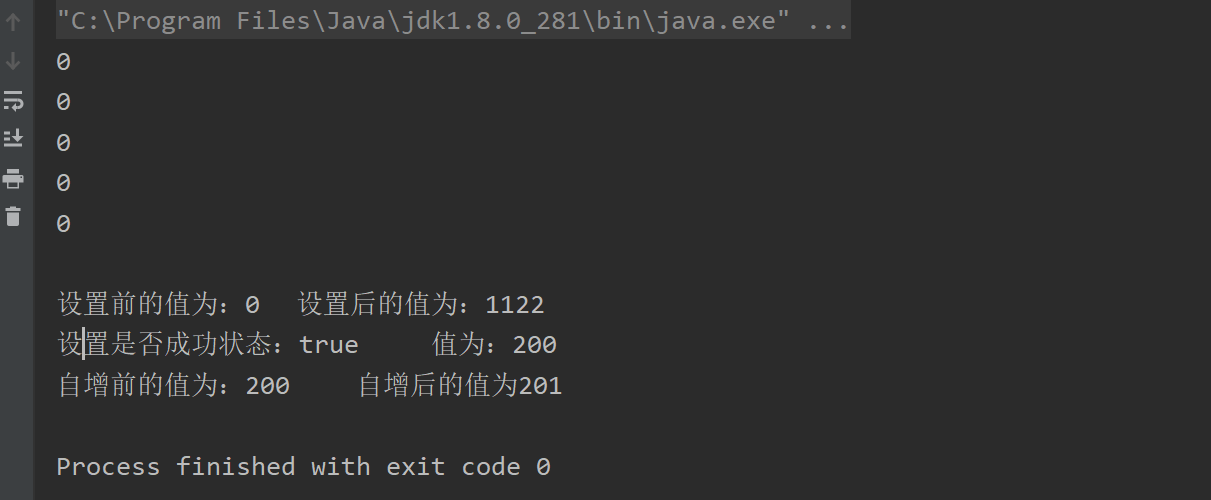
public class AtomicIntegerArrayDemo {public static void main(String[] args) {AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(new int[5]);//AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(5);//AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(new int[]{1,2,3,4,5});for (int i = 0; i < atomicIntegerArray.length(); i++) {System.out.println(atomicIntegerArray.get(i));}System.out.println();int tmpInt = 0;tmpInt = atomicIntegerArray.getAndSet(0, 1122);System.out.println("设置前的值为:" + tmpInt + "\t设置后的值为:" + atomicIntegerArray.get(0));boolean flag = atomicIntegerArray.compareAndSet(0, 1122, 200);System.out.println("设置是否成功状态:" + flag + "\t 值为:" + atomicIntegerArray.get(0));tmpInt = atomicIntegerArray.getAndIncrement(0);System.out.println("自增前的值为:" + tmpInt + "\t自增后的值为" + atomicIntegerArray.get(0));}
}
引用类型原子类 (AtomicReference、AtomicStampedReference、AtomicMarkableReference)
原子更新基本类型的AtomicInteger,只能更新一个变量,如果要原子更新多个变量,就需要使用这个原子更新引用类型提 供的类。 Atomic包提供了以下 3个类。
- AtomicReference:原子更新引用类型。
- AtomicStampedReference::原子更新带有版本号的引用类型。该类将整数值与引用 关联起来,可用于原子的更新数据和数据的版本号,可以解决使用 CAS进行原子更新时可能出现的 ABA问题。
- AtomicMarkableReference:原子更新带有标记位的引用类型。可以原子更新一个:原子更新带有标记位的引用类型。可以原子更新一个布尔类型的标记位和引用类型。构造方法是布尔类型的标记位和引用类型。构造方法是AtomicMarkableReference(V initialRef,,boolean initialMark)。
AtomicReference来实现自旋锁案例
常用方法
// 构造方法:使用null初始值创建新的AtomicReference。
AtomicReference()
// 构造方法:用给定的初始值创建一个新的AtomicReference
AtomicReference(V initialValue)
// 如果当前值 ==为预期值,则将值设置为给定的更新值。
boolean compareAndSet(V expect, V update)
// 获取当前值。
V get()
// 设置为给定值
void set(V newValue)
AtomicReference来实现自旋锁案例
/自旋锁
public class AtomicReferenceThreadDemo {static AtomicReference<Thread> atomicReference = new AtomicReference<>();static Thread thread;public static void lock() {thread = Thread.currentThread();System.out.println(Thread.currentThread().getName() + "\t" + "coming.....");while (!atomicReference.compareAndSet(null, thread)) {}}public static void unlock() {System.out.println(Thread.currentThread().getName() + "\t" + "over.....");atomicReference.compareAndSet(thread, null);}public static void main(String[] args) {new Thread(() -> {AtomicReferenceThreadDemo.lock();try {TimeUnit.SECONDS.sleep(3);} catch (InterruptedException e) {e.printStackTrace();}AtomicReferenceThreadDemo.unlock();}, "A").start();new Thread(() -> {AtomicReferenceThreadDemo.lock();AtomicReferenceThreadDemo.unlock();}, "B").start();}
}
AtomicStampedReference
常用方法
// 构造方法:传入初始引用值与初始版本号
AtomicStampedReference(V initialRef, int initialStamp)
// 如果传入的值等于当前值,则将版本号更新为newStamp
boolean attemptStamp(V expectedReference, int newStamp)
// 以原子方式设置该引用和版本号给定的更新值的值,
// 如果传入的值等于当前值,且传入的版本号等于当前版本号。
boolean compareAndSet(V expectedReference, V newReference, int expectedStamp, int newStamp)
// 获取当前引用的值
V getReference()
// 获取当前版本号的值
int getStamp()
// 无条件地设置引用和版本号的值。
void set(V newReference, int newStamp)
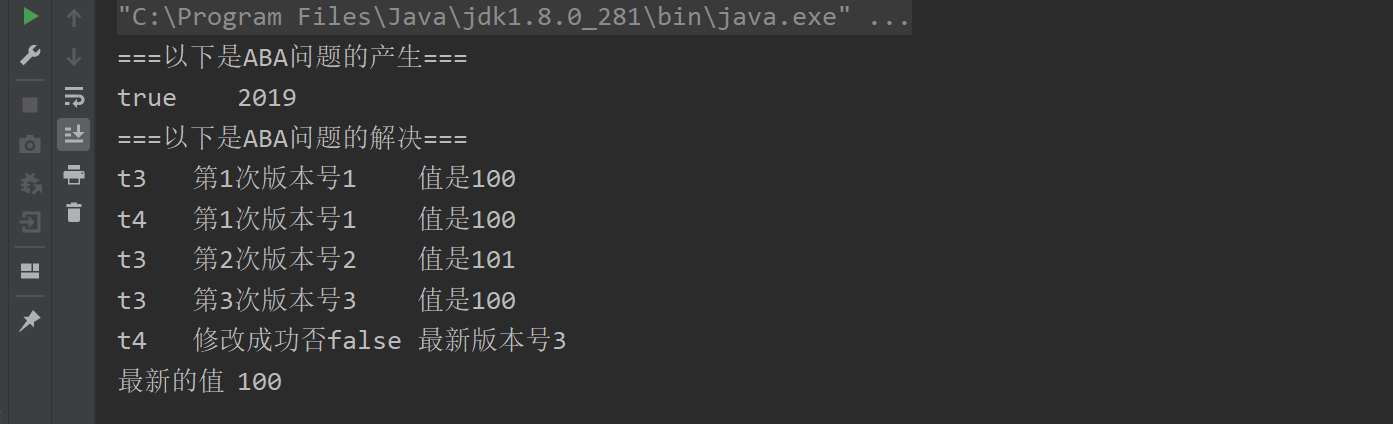
AtomicStampedReference 解决ABA问题
- 携带版本号的引用类型原子类,可以解决ABA问题
- 解决修改过几次
- 状态戳原子引用
public class AtomicStampedReferenceDemo {private static AtomicReference<Integer> atomicReference = new AtomicReference<>(100);private static AtomicStampedReference<Integer> stampedReference = new AtomicStampedReference<>(100, 1);public static void main(String[] args) {System.out.println("===以下是ABA问题的产生===");new Thread(() -> {atomicReference.compareAndSet(100, 101);atomicReference.compareAndSet(101, 100);}, "t1").start();new Thread(() -> {//先暂停1秒 保证完成ABAtry {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(atomicReference.compareAndSet(100, 2019) + "\t" + atomicReference.get());}, "t2").start();try {TimeUnit.SECONDS.sleep(2);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("===以下是ABA问题的解决===");new Thread(() -> {int stamp = stampedReference.getStamp();System.out.println(Thread.currentThread().getName() + "\t 第1次版本号" + stamp + "\t值是" + stampedReference.getReference());//暂停1秒钟t3线程try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}stampedReference.compareAndSet(100, 101, stampedReference.getStamp(), stampedReference.getStamp() + 1);System.out.println(Thread.currentThread().getName() + "\t 第2次版本号" + stampedReference.getStamp() + "\t值是" + stampedReference.getReference());stampedReference.compareAndSet(101, 100, stampedReference.getStamp(), stampedReference.getStamp() + 1);System.out.println(Thread.currentThread().getName() + "\t 第3次版本号" + stampedReference.getStamp() + "\t值是" + stampedReference.getReference());}, "t3").start();new Thread(() -> {int stamp = stampedReference.getStamp();System.out.println(Thread.currentThread().getName() + "\t 第1次版本号" + stamp + "\t值是" + stampedReference.getReference());//保证线程3完成1次ABAtry {TimeUnit.SECONDS.sleep(3);} catch (InterruptedException e) {e.printStackTrace();}boolean result = stampedReference.compareAndSet(100, 2019, stamp, stamp + 1);System.out.println(Thread.currentThread().getName() + "\t 修改成功否" + result + "\t最新版本号" + stampedReference.getStamp());System.out.println("最新的值\t" + stampedReference.getReference());}, "t4").start();}
}
AtomicMarkableReference
常用方法
// 构造方法:传入引用的对象,与标志位的初始值initialMark
AtomicMarkableReference(V initialRef, boolean initialMark)
// 以原子方式设置标志给定的更新值的值,如果当前引用 ==预期引用。
boolean attemptMark(V expectedReference, boolean newMark)
// 以原子方式设置该引用和标记给定的更新值的值,
// 如果当前的参考是 ==至预期的参考和当前标记等于预期标记。
boolean compareAndSet(V expectedReference, V newReference, boolean expectedMark, boolean newMark)
// 返回引用的当前值。
V getReference()
// 返回标记的当前值。
boolean isMarked()
// 无条件地设置引用和标记的值。
void set(V newReference, boolean newMark)
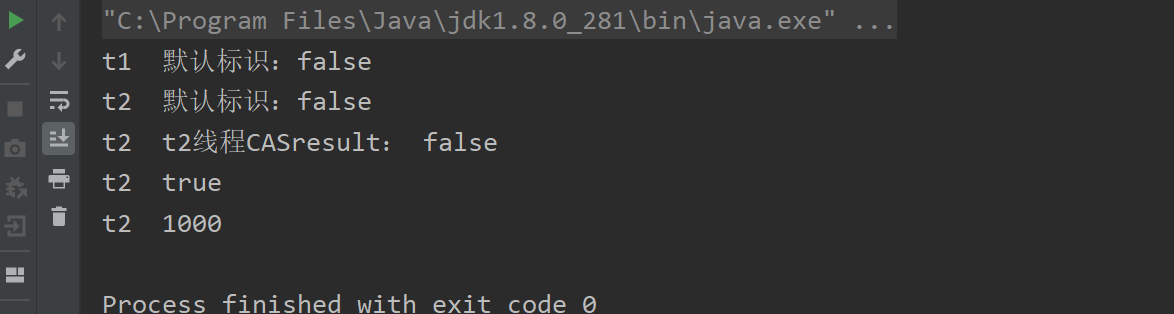
AtomicMarkableReference 不建议用它解决ABA问题
- 原子更新带有标志位的引用类型对象
- 解决是否修改(它的定义就是将状态戳简化位true|false),类似一次性筷子
- 状态戳(true/false)原子引用
- 不建议用它解决ABA问题
public class AtomicMarkableReferenceDemo
{static AtomicMarkableReference markableReference = new AtomicMarkableReference(100,false);public static void main(String[] args){new Thread(() -> {boolean marked = markableReference.isMarked();System.out.println(Thread.currentThread().getName()+"\t"+"默认标识:"+marked);//暂停1秒钟线程,等待后面的T2线程和我拿到一样的模式flag标识,都是falsetry { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); }markableReference.compareAndSet(100,1000,marked,!marked);},"t1").start();new Thread(() -> {boolean marked = markableReference.isMarked();System.out.println(Thread.currentThread().getName()+"\t"+"默认标识:"+marked);try { TimeUnit.SECONDS.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); }boolean b = markableReference.compareAndSet(100, 2000, marked, !marked);System.out.println(Thread.currentThread().getName()+"\t"+"t2线程CASresult: "+b);System.out.println(Thread.currentThread().getName()+"\t"+markableReference.isMarked());System.out.println(Thread.currentThread().getName()+"\t"+markableReference.getReference());},"t2").start();}
}
AtomicStampedReference和AtomicMarkableReference区别
- stamped – version number 版本号,修改一次+1
- Markable – true、false 是否修改过
对象的属性修改原子类 (AtomicIntegerFieldUpdater、AtomicLongFieldUpdater、AtomicReferenceFieldUpdater)
使用目的
以一种线程安全的方式操作非线程安全对象内的某些字段(可以不要锁定整个对象,减少锁定的范围,只关注长期、敏感性变化的某一个字段,而不是整个对象,已达到精确加锁+节约内存的目的)
使用要求
更新的对象属性必须使用public volatile修饰符,因为对象的属性修改类型原子类都是抽象类,所以每次使用都必须使用静态方法newUpdater( )创建一个更新器,并且需要设置想要更新的类和属性
使用案例
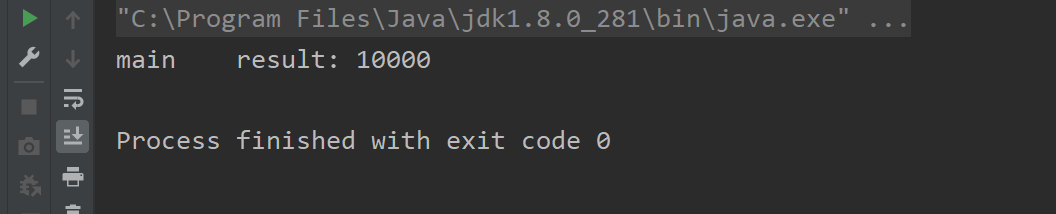
案例一
class BankAccount//资源类
{String bankName = "CCB";//更新的对象属性必须使用 public volatile 修饰符。public volatile int money = 0;//钱数public void add(){money++;}//因为对象的属性修改类型原子类都是抽象类,所以每次使用都必须// 使用静态方法newUpdater()创建一个更新器,并且需要设置想要更新的类和属性。public static final AtomicIntegerFieldUpdater<BankAccount> fieldUpdater =AtomicIntegerFieldUpdater.newUpdater(BankAccount.class,"money");//不加synchronized,保证高性能原子性,局部微创小手术public void transMoney(BankAccount bankAccount){fieldUpdater.getAndIncrement(bankAccount);}}/*** 以一种线程安全的方式操作非线程安全对象的某些字段。** 需求:* 10个线程,* 每个线程转账1000,* 不使用synchronized,尝试使用AtomicIntegerFieldUpdater来实现。*/
public class AtomicIntegerFieldUpdaterDemo
{public static void main(String[] args) throws InterruptedException{BankAccount bankAccount = new BankAccount();CountDownLatch countDownLatch = new CountDownLatch(10);for (int i = 1; i <=10; i++) {new Thread(() -> {try {for (int j = 1; j <=1000; j++) {//bankAccount.add();bankAccount.transMoney(bankAccount);}} finally {countDownLatch.countDown();}},String.valueOf(i)).start();}countDownLatch.await();System.out.println(Thread.currentThread().getName()+"\t"+"result: "+bankAccount.money);}
}
案例二
class MyVar //资源类
{public volatile Boolean isInit = Boolean.FALSE;AtomicReferenceFieldUpdater<MyVar,Boolean> referenceFieldUpdater =AtomicReferenceFieldUpdater.newUpdater(MyVar.class,Boolean.class,"isInit");public void init(MyVar myVar){if (referenceFieldUpdater.compareAndSet(myVar,Boolean.FALSE,Boolean.TRUE)){System.out.println(Thread.currentThread().getName()+"\t"+"----- start init,need 2 seconds");//暂停几秒钟线程try { TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) { e.printStackTrace(); }System.out.println(Thread.currentThread().getName()+"\t"+"----- over init");}else{System.out.println(Thread.currentThread().getName()+"\t"+"----- 已经有线程在进行初始化工作。。。。。");}}
}/*** @auther zzyy* 需求:* 多线程并发调用一个类的初始化方法,如果未被初始化过,将执行初始化工作,* 要求只能被初始化一次,只有一个线程操作成功*/
public class AtomicReferenceFieldUpdaterDemo
{public static void main(String[] args){MyVar myVar = new MyVar();for (int i = 1; i <=5; i++) {new Thread(() -> {myVar.init(myVar);},String.valueOf(i)).start();}}
}
AtomicIntegerFieldUpdater与AtomicInteger使用引发的思考
通过下面代码我们不难得知使用AtomicIntegerFieldUpdater与AtomicInteger其实效果是一致的,那既然已经存在了AtomicInteger并发之神又要写一个AtomicIntegerFieldUpdater呢?
从AtomicIntegerFieldUpdaterDemo代码中我们不难发现,通过AtomicIntegerFieldUpdater更新money我们获取最后的int值时相较于AtomicInteger来说不需要调用get()方法。
对于AtomicIntegerFieldUpdaterDemo类的AtomicIntegerFieldUpdater是static final类型也就是说即使创建了100个对象AtomicIntegerField也只存在一个不会占用对象的内存,但是AtomicInteger会创建多个AtomicInteger对象,占用的内存比AtomicIntegerFieldUpdater大。
原子操作增强类(DoubleAccumulator 、DoubleAdder 、LongAccumulator 、LongAdder)
以LongAdder为例
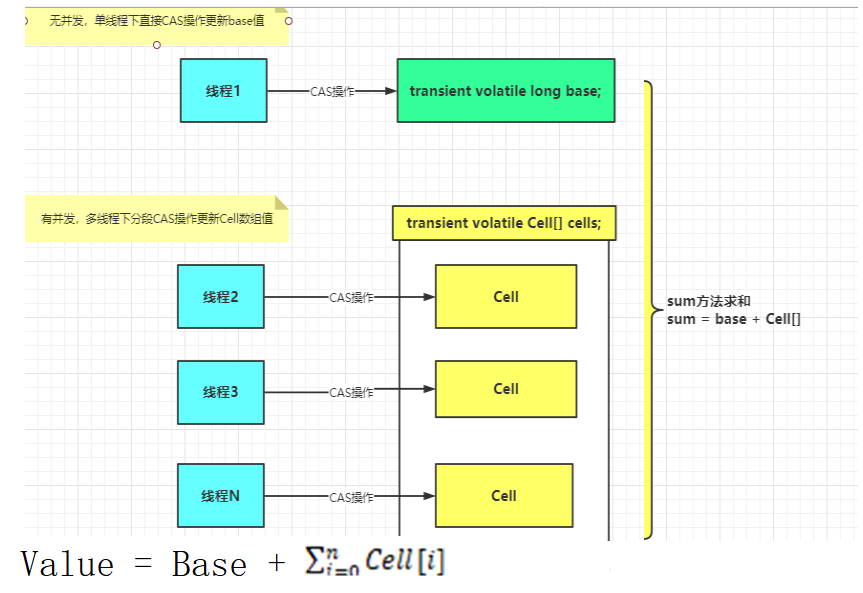
LongAdder在无竞争的情况,跟AtomicLong一样,对同一个base进行操作,当出现竞争关系时则采用化整为零的做法,从空间换时间,用一个数组cells,将一个value拆分进这个数组cells。多个线程需要同时对value进行操作时候,可以对线程id进行hash得到hash值,再根据hash值映射到这个数组cells的某个下标,再对该下标所对应的值进行自增操作。当所有线程操作完毕,将数组cells的所有值和无竞争值base都加起来作为最终结果(分散热点);
常用方法
// 将当前的value加x
void add(long x)
//将当前的value加1
void increment( )
// 将当前value减1
void decrement( )
// 返回当前的值,特别注意,在没有并发更新value的情况下
// sum会返回一个精确值,在存在并发的情况下,sum不保证返回精确值
long sum( )
LongAdder在高并发情况下为什么比AtomicLong快
- LongAdder在无竞争的情况,跟AtomicLong一样,对同一个base进行操作,当出现竞争关系时则采用化整为零的做法,从空间换时间,用一个数组cells,将一个value拆分进这个数组cells。多个线程需要同时对value进行操作时候,可以对线程id进行hash得到hash值,再根据hash值映射到这个数组cells的某个下标,再对该下标所对应的值进行自增操作。当所有线程操作完毕,将数组cells的所有值和无竞争值base都加起来作为最终结果(分散热点)
- sum( )会将所有cell数组中的value和base累加作为返回值,核心的思想就是将之前AtomicLong一个value的更新压力分散到多个value中去,从而降级更新热点
内部是一个Base+一个Cell[ ]数组
- base变量:非竞争状态条件下,直接累加到该变量上
- Cell[ ]数组:竞争条件下(高并发下),累加各个线程自己的槽Cell[i]中
longAdder.increment( )
add(1L)
- 最初无竞争时,直接通过casBase进行更新base的处理
- 如果更新base失败后,首次新建一个Cell[ ]数组(默认长度是2)
- 当多个线程竞争同一个Cell比较激烈时,可能就要对Cell[ ]扩容
源码如下:
LongAdder.javapublic void add(long x) {//as是striped64中的cells数组属性//b是striped64中的base属性//v是当前线程hash到的cell中存储的值//m是cells的长度减1,hash时作为掩码使用//a时当前线程hash到的cellCell[] as; long b, v; int m; Cell a;/**首次首线程(as = cells) != null)一定是false,此时走casBase方法,以CAS的方式更新base值,且只有当cas失败时,才会走到if中条件1:cells不为空,说明出现过竞争,cell[]已创建条件2:cas操作base失败,说明其他线程先一步修改了base正在出现竞争*/if ((as = cells) != null || !casBase(b = base, b + x)) {//true无竞争 fasle表示竞争激烈,多个线程hash到同一个cell,可能要扩容boolean uncontended = true;/*条件1:cells为空,说明正在出现竞争,上面是从条件2过来的,说明!casBase(b = base, b + x))=true会通过调用longAccumulate(x, null, uncontended)新建一个数组,默认长度是2条件2:默认会新建一个数组长度为2的数组,m = as.length - 1) < 0 应该不会出现,条件3:当前线程所在的cell为空,说明当前线程还没有更新过cell,应初始化一个cell。a = as[getProbe() & m]) == null,如果cell为空,进行一个初始化的处理条件4:更新当前线程所在的cell失败,说明现在竞争很激烈,多个线程hash到同一个Cell,应扩容(如果是cell中有一个线程操作,这个时候,通过a.cas(v = a.value, v + x)可以进行处理,返回的结果是true)**/if (as == null || (m = as.length - 1) < 0 ||//getProbe( )方法返回的时线程中的threadLocalRandomProbe字段//它是通过随机数生成的一个值,对于一个确定的线程这个值是固定的(除非刻意修改它)(a = as[getProbe() & m]) == null ||!(uncontended = a.cas(v = a.value, v + x)))//调用Striped64中的方法处理longAccumulate(x, null, uncontended);}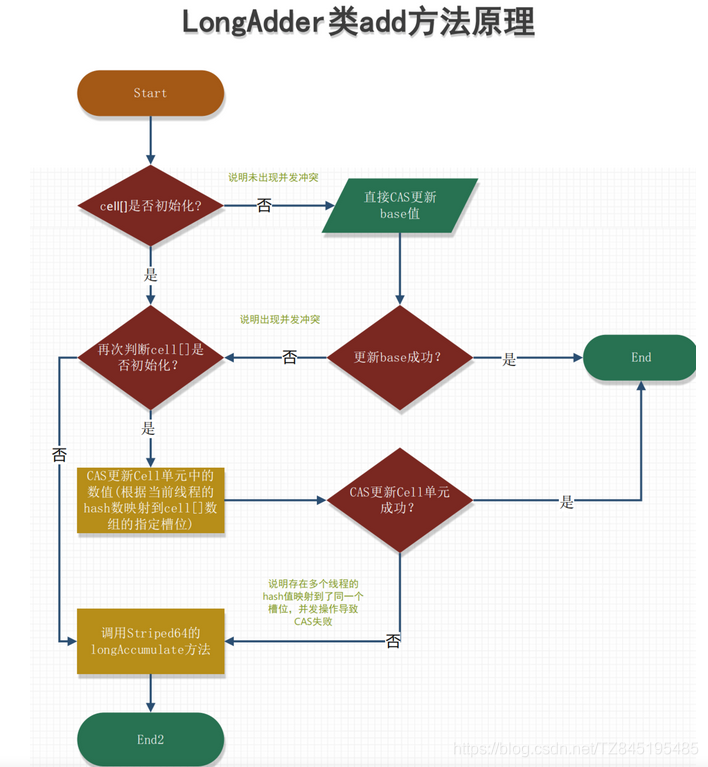 [
[
](https://blog.csdn.net/TZ845195485/article/details/117929973)
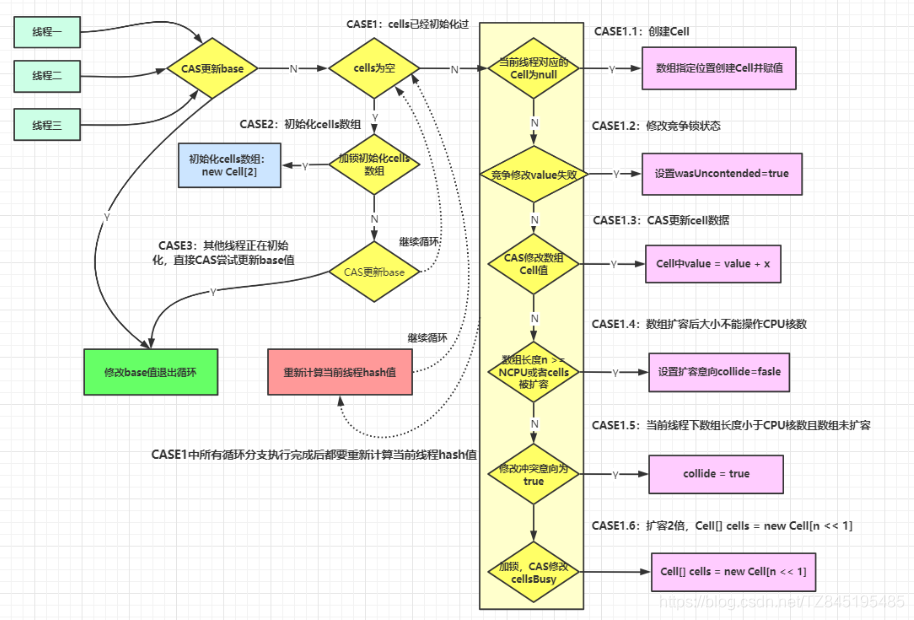
longAccumulate(x, null, uncontended)
线程hash值:probe
final void longAccumulate(long x, LongBinaryOperator fn,boolean wasUncontended) {//存储线程的probe值int h;//如果getProbe()方法返回0,说明随机数未初始化if ((h = getProbe()) == 0) { //这个if相当于给当前线程生成一个非0的hash值//使用ThreadLocalRandom为当前线程重新计算一个hash值,强制初始化ThreadLocalRandom.current(); // force initialization//重新获取probe值,hash值被重置就好比一个全新的线程一样,所以设置了wasUncontended竞争状态为trueh = getProbe();//重新计算了当前线程的hash后认为此次不算是一次竞争,都未初始化,肯定还不存在竞争激烈//wasUncontended竞争状态为truewasUncontended = true;}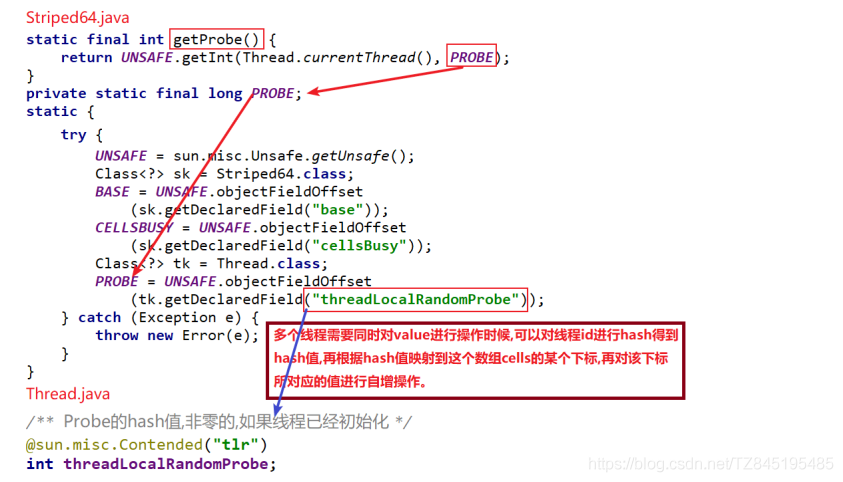
刚刚初始化Cell[ ]数组(首次新建)
//CASE2:cells没有加锁且没有初始化,则尝试对它进行加锁,并初始化cells数组/*cellsBusy:初始化cells或者扩容cells需要获取锁,0表示无锁状态,1表示其他线程已经持有了锁cells == as == null 是成立的casCellsBusy:通过CAS操作修改cellsBusy的值,CAS成功代表获取锁,返回true,第一次进来没人抢占cell单元格,肯定返回true**/else if (cellsBusy == 0 && cells == as && casCellsBusy()) { //是否初始化的标记boolean init = false;try { // Initialize table(新建cells)// 前面else if中进行了判断,这里再次判断,采用双端检索的机制if (cells == as) {//如果上面条件都执行成功就会执行数组的初始化及赋值操作,Cell[] rs = new Cell[2]标识数组的长度为2Cell[] rs = new Cell[2];//rs[h & 1] = new Cell(x)表示创建一个新的cell元素,value是x值,默认为1//h & 1 类似于我们之前hashmap常用到的计算散列桶index的算法,//通常都是hash&(table.len-1),同hashmap一个意思//看这次的value是落在0还是1rs[h & 1] = new Cell(x);cells = rs;init = true;}} finally {cellsBusy = 0;}if (init)break;}兜底(多个线程尝试CAS修改失败的线程会走这个分支)
//CASE3:cells正在进行初始化,则尝试直接在基数base上进行累加操作//这种情况是cell中都CAS失败了,有一个兜底的方法//该分支实现直接操作base基数,将值累加到base上,//也即其他线程正在初始化,多个线程正在更新base的值else if (casBase(v = base, ((fn == null) ? v + x :fn.applyAsLong(v, x))))break; Cell数组不再为空且可能存在Cell数组扩容
for (;;) {Cell[] as; Cell a; int n; long v;if ((as = cells) != null && (n = as.length) > 0) { // CASE1:cells已经初始化了// 当前线程的hash值运算后映射得到的Cell单元为null,说明该Cell没有被使用if ((a = as[(n - 1) & h]) == null) {//Cell[]数组没有正在扩容if (cellsBusy == 0) { // Try to attach new Cell//先创建一个CellCell r = new Cell(x); // Optimistically create//尝试加锁,加锁后cellsBusy=1if (cellsBusy == 0 && casCellsBusy()) { boolean created = false;try { // Recheck under lockCell[] rs; int m, j; //将cell单元赋值到Cell[]数组上//在有锁的情况下再检测一遍之前的判断 if ((rs = cells) != null &&(m = rs.length) > 0 &&rs[j = (m - 1) & h] == null) {rs[j] = r;created = true;}} finally {cellsBusy = 0;//释放锁}if (created)break;continue; // Slot is now non-empty}}collide = false;}/**wasUncontended表示cells初始化后,当前线程竞争修改失败wasUncontended=false,表示竞争激烈,需要扩容,这里只是重新设置了这个值为true,紧接着执行advanceProbe(h)重置当前线程的hash,重新循环*/else if (!wasUncontended) // CAS already known to failwasUncontended = true; // Continue after rehash//说明当前线程对应的数组中有了数据,也重置过hash值//这时通过CAS操作尝试对当前数中的value值进行累加x操作,x默认为1,如果CAS成功则直接跳出循环else if (a.cas(v = a.value, ((fn == null) ? v + x :fn.applyAsLong(v, x))))break;//如果n大于CPU最大数量,不可扩容,并通过下面的h=advanceProbe(h)方法修改线程的probe再重新尝试else if (n >= NCPU || cells != as)collide = false; //扩容标识设置为false,标识永远不会再扩容//如果扩容意向collide是false则修改它为true,然后重新计算当前线程的hash值继续循环else if (!collide) collide = true;//锁状态为0并且将锁状态修改为1(持有锁) else if (cellsBusy == 0 && casCellsBusy()) { try {if (cells == as) { // Expand table unless stale//按位左移1位来操作,扩容大小为之前容量的两倍Cell[] rs = new Cell[n << 1];for (int i = 0; i < n; ++i)//扩容后将之前数组的元素拷贝到新数组中rs[i] = as[i];cells = rs; }} finally {//释放锁设置cellsBusy=0,设置扩容状态,然后进行循环执行cellsBusy = 0;}collide = false;continue; // Retry with expanded table}h = advanceProbe(h);}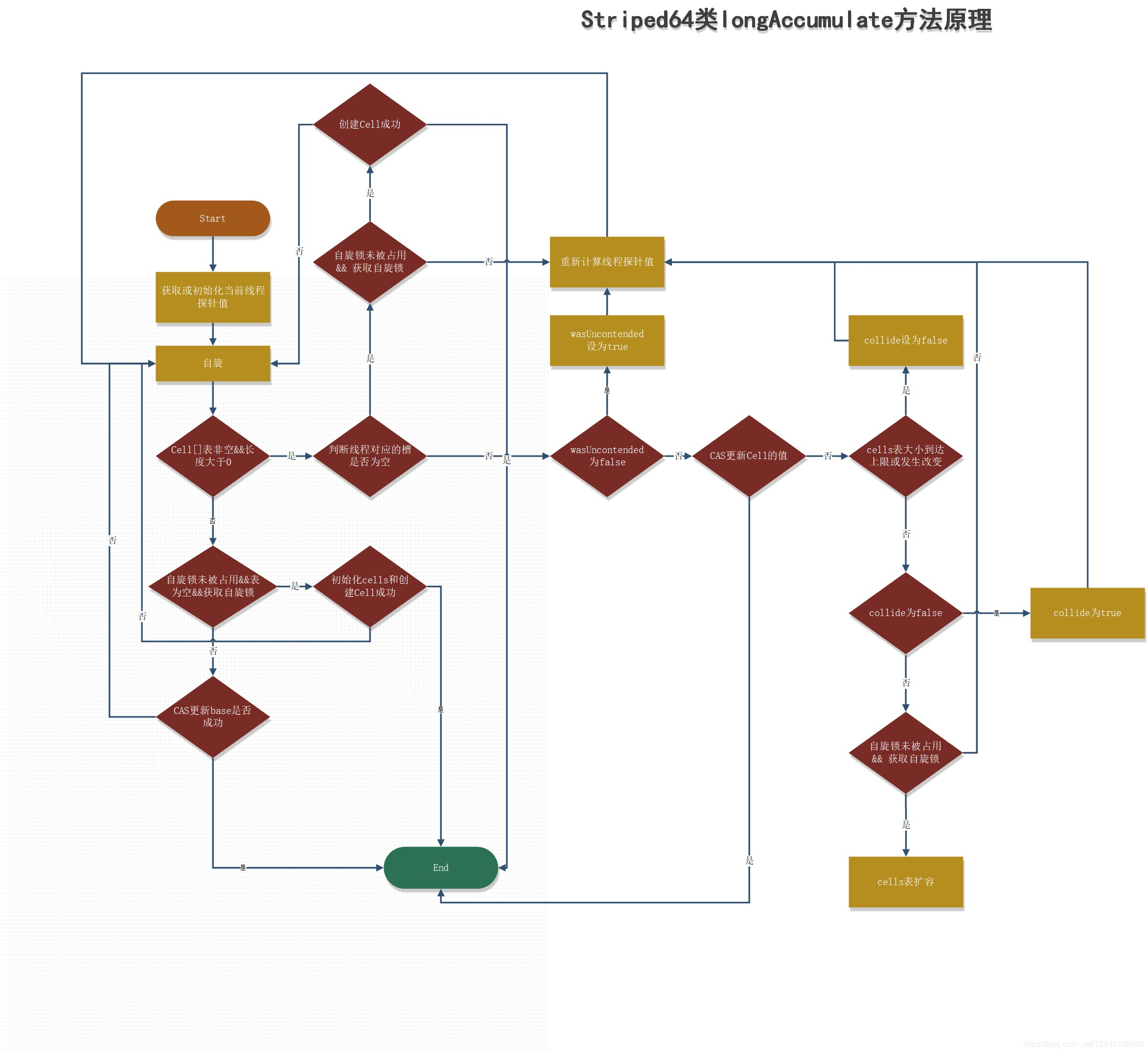
Striped64.java
Striped64.java
/**1.LongAdder继承了Striped64类,来实现累加功能,它是实现高并发累加的工具类2.Striped64的设计核心思路就是通过内部的分散计算来避免竞争3.Striped64内部包含一个base和一个Cell[] cells数组,又叫hash表4.没有竞争的情况下,要累加的数通过cas累加到base上;如果有竞争的话,会将要累加的数累加到Cells数组中的某个cell元素里面
*/
abstract class Striped64 extends Number {//CPU数量,即Cells数组的最大长度static final int NCPU = Runtime.getRuntime().availableProcessors();//存放Cell的hash表,大小为2的幂transient volatile Cell[] cells;/*1.在开始没有竞争的情况下,将累加值累加到base;2.在cells初始化的过程中,cells处于不可用的状态,这时候也会尝试将通过cas操作值累加到base*/transient volatile long base;/*cellsBusy,它有两个值0或1,它的作用是当要修改cells数组时加锁,防止多线程同时修改cells数组(也称cells表),0为无锁,1位加锁,加锁的状况有三种:(1). cells数组初始化的时候;(2). cells数组扩容的时候;(3).如果cells数组中某个元素为null,给这个位置创建新的Cell对象的时候;*/transient volatile int cellsBusy;//低并发状态,还没有新建cell数组且写入进入base,刚好够用//base罩得住,不用上cell数组final boolean casBase(long cmp, long val) {//当前对象,在base位置上,将base(类似于AtomicLong中全局的value值),将base=0(cmp)改为1(value)return UNSAFE.compareAndSwapLong(this, BASE, cmp, val);}final void longAccumulate(long x, LongBinaryOperator fn,boolean wasUncontended) {//存储线程的probe值int h;//如果getProbe()方法返回0,说明随机数未初始化if ((h = getProbe()) == 0) { //这个if相当于给当前线程生成一个非0的hash值//使用ThreadLocalRandom为当前线程重新计算一个hash值,强制初始化ThreadLocalRandom.current(); // force initialization//重新获取probe值,hash值被重置就好比一个全新的线程一样,所以设置了wasUncontended竞争状态为trueh = getProbe();//重新计算了当前线程的hash后认为此次不算是一次竞争,都未初始化,肯定还不存在竞争激烈,wasUncontended竞争状态为truewasUncontended = true;}//如果hash取模映射得到的Cell单元不是null,则为true,此值也可以看作是扩容意向boolean collide = false; // True if last slot nonemptyfor (;;) {Cell[] as; Cell a; int n; long v;if ((as = cells) != null && (n = as.length) > 0) { // CASE1:cells已经初始化了// 当前线程的hash值运算后映射得到的Cell单元为null,说明该Cell没有被使用if ((a = as[(n - 1) & h]) == null) {//Cell[]数组没有正在扩容if (cellsBusy == 0) { // Try to attach new Cell//先创建一个CellCell r = new Cell(x); // Optimistically create//尝试加锁,加锁后cellsBusy=1if (cellsBusy == 0 && casCellsBusy()) { boolean created = false;try { // Recheck under lockCell[] rs; int m, j; //将cell单元赋值到Cell[]数组上//在有锁的情况下再检测一遍之前的判断 if ((rs = cells) != null &&(m = rs.length) > 0 &&rs[j = (m - 1) & h] == null) {rs[j] = r;created = true;}} finally {cellsBusy = 0;//释放锁}if (created)break;continue; // Slot is now non-empty}}collide = false;}/**wasUncontended表示cells初始化后,当前线程竞争修改失败wasUncontended=false,表示竞争激烈,需要扩容,这里只是重新设置了这个值为true,紧接着执行advanceProbe(h)重置当前线程的hash,重新循环*/else if (!wasUncontended) // CAS already known to failwasUncontended = true; // Continue after rehash//说明当前线程对应的数组中有了数据,也重置过hash值//这时通过CAS操作尝试对当前数中的value值进行累加x操作,x默认为1,如果CAS成功则直接跳出循环else if (a.cas(v = a.value, ((fn == null) ? v + x :fn.applyAsLong(v, x))))break;//如果n大于CPU最大数量,不可扩容,并通过下面的h=advanceProbe(h)方法修改线程的probe再重新尝试else if (n >= NCPU || cells != as)collide = false; //扩容标识设置为false,标识永远不会再扩容//如果扩容意向collide是false则修改它为true,然后重新计算当前线程的hash值继续循环else if (!collide) collide = true;//锁状态为0并且将锁状态修改为1(持有锁) else if (cellsBusy == 0 && casCellsBusy()) { try {if (cells == as) { // Expand table unless stale//按位左移1位来操作,扩容大小为之前容量的两倍Cell[] rs = new Cell[n << 1];for (int i = 0; i < n; ++i)//扩容后将之前数组的元素拷贝到新数组中rs[i] = as[i];cells = rs; }} finally {//释放锁设置cellsBusy=0,设置扩容状态,然后进行循环执行cellsBusy = 0;}collide = false;continue; // Retry with expanded table}h = advanceProbe(h);}//CASE2:cells没有加锁且没有初始化,则尝试对它进行加锁,并初始化cells数组/*cellsBusy:初始化cells或者扩容cells需要获取锁,0表示无锁状态,1表示其他线程已经持有了锁cells == as == null 是成立的casCellsBusy:通过CAS操作修改cellsBusy的值,CAS成功代表获取锁,返回true,第一次进来没人抢占cell单元格,肯定返回true**/else if (cellsBusy == 0 && cells == as && casCellsBusy()) { //是否初始化的标记boolean init = false;try { // Initialize table(新建cells)// 前面else if中进行了判断,这里再次判断,采用双端检索的机制if (cells == as) {//如果上面条件都执行成功就会执行数组的初始化及赋值操作,Cell[] rs = new Cell[2]标识数组的长度为2Cell[] rs = new Cell[2];//rs[h & 1] = new Cell(x)表示创建一个新的cell元素,value是x值,默认为1//h & 1 类似于我们之前hashmap常用到的计算散列桶index的算法,通常都是hash&(table.len-1),同hashmap一个意思rs[h & 1] = new Cell(x);cells = rs;init = true;}} finally {cellsBusy = 0;}if (init)break;}//CASE3:cells正在进行初始化,则尝试直接在基数base上进行累加操作//这种情况是cell中都CAS失败了,有一个兜底的方法//该分支实现直接操作base基数,将值累加到base上,也即其他线程正在初始化,多个线程正在更新base的值else if (casBase(v = base, ((fn == null) ? v + x :fn.applyAsLong(v, x))))break; // Fall back on using base}}static final int getProbe() {return UNSAFE.getInt(Thread.currentThread(), PROBE);}
}LongAdder.java
LongAdder.java(1).baseOK,直接通过casBase进行处理(2).base不够用了,开始新建一个cell数组,初始值为2(3).当多个线程竞争同一个Cell比较激烈时,可能就要对Cell[ ]扩容public void add(long x) {//as是striped64中的cells数组属性//b是striped64中的base属性//v是当前线程hash到的cell中存储的值//m是cells的长度减1,hash时作为掩码使用//a时当前线程hash到的cellCell[] as; long b, v; int m; Cell a;/**首次首线程(as = cells) != null)一定是false,此时走casBase方法,以CAS的方式更新base值,且只有当cas失败时,才会走到if中条件1:cells不为空,说明出现过竞争,cell[]已创建条件2:cas操作base失败,说明其他线程先一步修改了base正在出现竞争*/if ((as = cells) != null || !casBase(b = base, b + x)) {//true无竞争 fasle表示竞争激烈,多个线程hash到同一个cell,可能要扩容boolean uncontended = true;/*条件1:cells为空,说明正在出现竞争,上面是从条件2过来的,说明!casBase(b = base, b + x))=true会通过调用longAccumulate(x, null, uncontended)新建一个数组,默认长度是2条件2:默认会新建一个数组长度为2的数组,m = as.length - 1) < 0 应该不会出现,条件3:当前线程所在的cell为空,说明当前线程还没有更新过cell,应初始化一个cell。a = as[getProbe() & m]) == null,如果cell为空,进行一个初始化的处理条件4:更新当前线程所在的cell失败,说明现在竞争很激烈,多个线程hash到同一个Cell,应扩容(如果是cell中有一个线程操作,这个时候,通过a.cas(v = a.value, v + x)可以进行处理,返回的结果是true)**/if (as == null || (m = as.length - 1) < 0 ||//getProbe( )方法返回的时线程中的threadLocalRandomProbe字段//它是通过随机数生成的一个值,对于一个确定的线程这个值是固定的(除非刻意修改它)(a = as[getProbe() & m]) == null ||!(uncontended = a.cas(v = a.value, v + x)))//调用Striped64中的方法处理longAccumulate(x, null, uncontended);}}Striped64.javaabstract class Striped64 extends Number {static final int NCPU = Runtime.getRuntime().availableProcessors();transient volatile Cell[] cells;transient volatile long base;transient volatile int cellsBusy;//低并发状态,还没有新建cell数组且写入进入base,刚好够用//base罩得住,不用上cell数组final boolean casBase(long cmp, long val) {//当前对象,在base位置上,将base(类似于AtomicLong中全局的value值),将base=0(cmp)改为1(value)return UNSAFE.compareAndSwapLong(this, BASE, cmp, val);}}sum( )
①. sum( )会将所有Cell数组中的value和base累加作为返回值
public long sum() {Cell[] as = cells; Cell a;long sum = base;if (as != null) {for (int i = 0; i < as.length; ++i) {if ((a = as[i]) != null)sum += a.value;}}return sum;
}核心的思想就是将之前AtomicLong一个value的更新压力分散到多个value中去,从而降级更新热点
为啥高并发下sum的值不精确?
sum执行时,并没有限制对base和cells的更新(一句要命的话)。所以LongAdder不是强一致性,它是最终一致性的
首先,最终返回的sum局部变量,初始被赋值为base,而最终返回时,很可能base已经被更新了,而此时局部变量sum不会更新,造成不一致
其次,这里对cell的读取也无法保证是最后一次写入的值。所以,sum方法在没有并发的情况下,可以获得正确的结果;
关于AtomicLong和LongAdder区别