目录
docker安装es
docker安装kibana
为es配置中文分词器
安装原生logstash
项目服务集成日志收集
为es设置登录密码
为kibana设置登录密码
为es容器设置内存限制
使用htop或者是docker进行内存使用查询
docker安装es
与自己的springBoot版本适配即可,下面的springBoot集成ES会展示怎么选择合适版本的es的,由于在docker官网中没有找到我想要的7.15.2,所以我就安装了这个版本之上的7.16.1。
1、拉取镜像:
docker pull elasticsearch:7.16.1 2、创建挂载的目录
2、创建挂载的目录
mkdir -p /home/elasticsearch7/config
mkdir -p /home/elasticsearch7/data
mkdir -p /home/elasticsearch7/plugins3、在/home/elasticsearch7/config文件夹下新建elasticsearch.yml配置文件
/home/elasticsearch7/configvim elasticsearch.yml# 查看配置文件中的内容
cat elasticsearch.yml配置文件内容如下:
# 可以让es被任意其他ip进行访问,也可以按需配置ip
http.host: 0.0.0.0
# 为es配置文件添加跨域配置 建议手敲,直接复制可能会导致特殊字符无法被识别,记得中间有一个空格
http.cors.enabled: true
http.cors.allow-origin: "*"4、启动容器指令
docker run --name es \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPS="-Xms256m -Xmx1024m" \
-v /home/elasticsearch7/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /home/elasticsearch7/data:/usr/share/elasticsearch/data \
-v /home/elasticsearch7/plugins:/usr/share/elasticsearch/plugins \
--restart=always \
-m 1.5g \
-d elasticsearch:7.16.1ES_JAVA_OPS 的设置仅影响 Elasticsearch 的 JVM 参数,而不会直接限制 Docker 容器的整体内存使用。Docker 容器的内存限制需要使用 Docker 命令的 -m 参数来设置。
如果执行错误了,想要重新执行,那么可以先把刚刚创建的镜像给删除:docker rm -f 容器镜像id

-
docker run: 运行一个容器,每个容器相互隔离,他都是独立的运行环境,是一个完整的实例。
-
--name es:为容器取名,这个名字随意。
-
-p 9200:9200 -p 9300:9300:把es容器自己的端口映射到虚拟主机,这样我们才能访问,这是端口映射,对外暴露。(9200是我们通过rest接口请求的端口,9300是内部通信端口,es集群之间会相互通信,他们有心跳机制)
-
-e "discovery.type=single-node": 单节点形式运行
-
-e ESJAVAOPS="-Xms64m -Xmx1024m": 设置内存大小,如果不设置,es会占用虚拟机的全部内存,初始64m,最大1024m,也够用了,不够用的话再给他加内存就行。
-
-v:文件路径的挂载。(数据库文件,日志,配置文件)
查看启动状态:
docker ps -a
查看运行日志:docker logs es
发现在报错:授权的问题,因为es启动是不能使用root的,以前使用源码安装的时候就是这样,必须要创建新的用户才行。所以这里也是一样的。我们需要为自己目录添加权限给es。
解决方法:直接给刚刚我们创建的elasticsearch7目录给全部授权
chmod -R 777 /home/elasticsearch7/
重启es:docker restart es
然后再重新查看一下日志 docker logs es ,看看有没有问题就行。
可以直接访问了: http://ip地址:9200/ 记得在云服务器上开放9200与9300的安全组!!!
5、设置自动重启
docker update elasticsearch --restart=alwayssystemctl restart docker6、重新启动es:
docker restart 容器镜像id/容器名7、想要停止docker中的es
docker stop es(es运行时的命名)# 想要再次启动
docker start esdocker安装kibana
docker pull kibana:7.16.1# 记得把服务器的安全组与防火墙中的 5061端口 给开放
docker run --name kibana --link=es:es -p 5601:5601 -d kibana:7.16.1# 对其设置内存限制 内存设置太小的话,会直接挂掉的
docker run --name kibana --link=es:es -p 5601:5601 -d --memory 1024m kibana:7.16.1然后浏览器访问:ip地址:5601,报错

下面这种把kibanaa中es的地址更换成 es在docker中的地址解决不了这个问题,自己尝试过,会报错licensing"],"pid":7,"message":"License information could not be obtained from Elasticsearch due to ConnectionError: connect ECONNREFUSED 172.17.0.5:9200 error。最终还是需要使用es的公网访问ip地址。
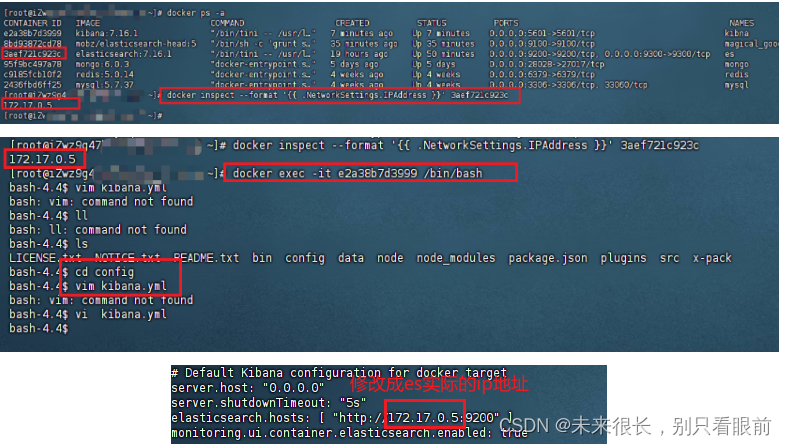
# 查看es容器内部ip 通过容器id来进行查看
docker inspect --format '{{ .NetworkSettings.IPAddress }}' 3aef721c923c# 进入kibana容器,修改其配置文件,把ip地址缓存es容器的实际地址,es容器的实际地址通过上面的指令可以查询出来
docker exec -it 你的kibana容器id /bin/bash
# 进入config目录修改配置文件
cd config
# 修改配置文件 vim使用不了的,使用vi 把刚刚获取的es在容器的实际ip地址覆盖掉配置文件中的ip地址
vi kibana.yml # 重启kibna
docker restart 你的kibana容器id会发现上面的方式还是不行,最终成功的方法是把kibana.yml中的elasticsearch.hosts中的ip地址改成了 es对外访问的ip地址(安装es服务器的公网ip地址)
由于上面方式,不生效,后面我又把这个 elasticsearch.hosts中的ip地址改成了 es对外访问的ip地址(安装es服务器的公网ip地址),然后重启kibanaa与es,等待一小段时间之后就可以正常使用了,可能是服务器配置低然后启动的太慢了。
注意:kibana是可以配置账号和密码的,后面其他文章会补充。
kibana官方学习文档: Create an index pattern | Kibana Guide [7.16] | Elastic
为es配置中文分词器
插件Github地址:GitHub - infinilabs/analysis-ik: 🚌 The IK Analysis plugin integrates Lucene IK analyzer into Elasticsearch and OpenSearch, support customized dictionary.🚌 The IK Analysis plugin integrates Lucene IK analyzer into Elasticsearch and OpenSearch, support customized dictionary. - infinilabs/analysis-ik![]() https://github.com/medcl/elasticsearch-analysis-ik
https://github.com/medcl/elasticsearch-analysis-ik
找到与自己安装的es版本相匹配的ik分词器:这里我们是7.16.1
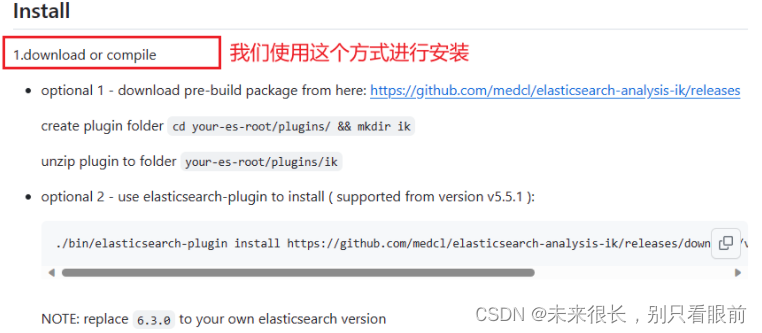

把这个zip压缩包解压释放到ik文件夹中:

# 先安装解压插件
sudo yum install unzip# 移动解压包到ik文件夹
mv elasticsearch-analysis-ik-7.16.1.zip ik# 直接在ik文件夹中释放
unzip elasticsearch-analysis-ik-7.16.1.zip#重新启动es docker start es
docker restart es测试:在postman或者是apipost中进行测试:
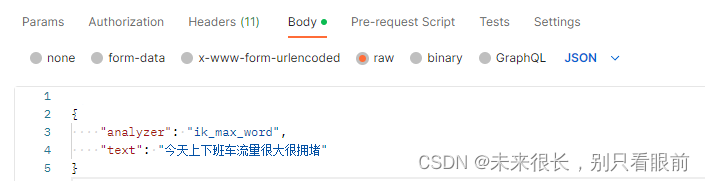
测试路径:http://es安装的ip地址:9200/_analyze
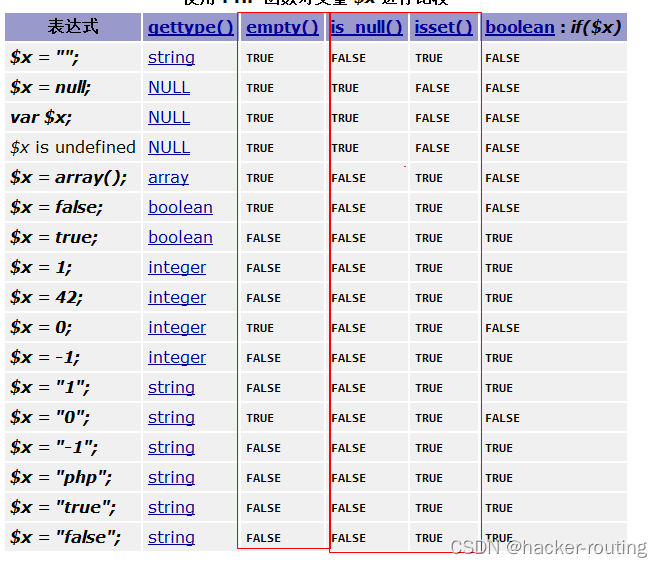
{"analyzer": "ik_max_word","text": "今天上下班车流量很大很拥堵"
}或者是使用另一个模式:
{"analyzer": "ik_smart","text": "今天上下班车流量很大很拥堵"
}
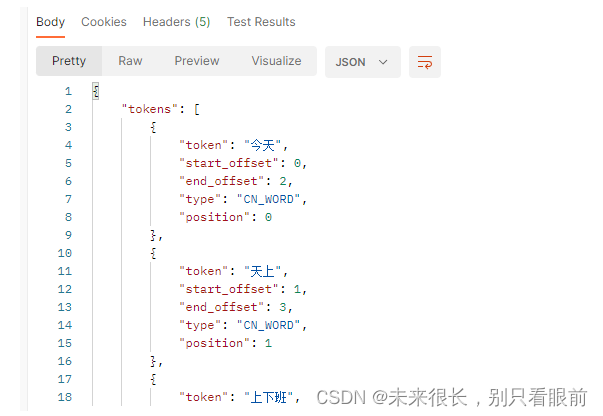
请求结果:
安装原生logstash
如果使用docker进行拉取安装的话,可能会出现各种问题(网络连接问题,配置问题),这里就建议使用原生的方式进行安装了:
下载地址: https://www.elastic.co/cn/downloads/past-releases#logstash
上传并且解压tar: tar -zxvf logstash-7.16.1-linux-x86_64.tar.gz

可以发现,解压之后的目录中自带了一个jdk,如果是使用docker进行安装的话,那么默认携带jdk9,使用这种原生的方式也会携带jdk,我们直接使用就行。
进入config文件夹修改配置文件:
先对logstash.yml进行修改(这里面的配置都是注释掉的,我们需要开放一些):

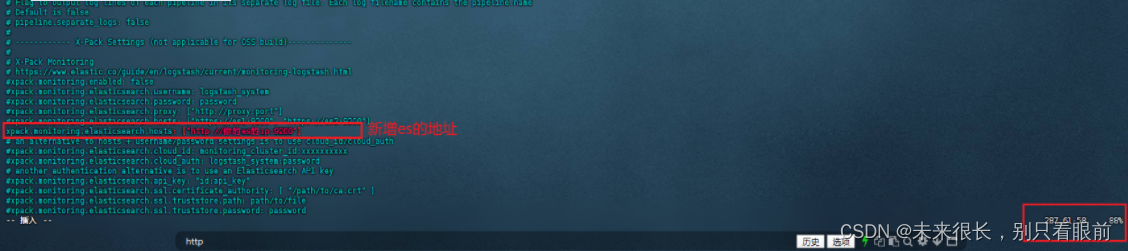
然后再在config中新增一个配置文件:my.conf,该配置文件的内容如下:
# 日志采集入口,项目的logback会和这个input交互
input {tcp {# 模式为servermode => "server"# ip为logstash的地址,如果这里使用了logstash的地址还是连接不上并且报错;无法指定被请求的地址,那么把这个下面的值改为 host => "0.0.0.0"host => "192.168.1.124"# 监听的端口,以此端口获得日志数据port => "9413"# 数据格式为jsoncodec => json_lines}
}
# 日志存储目标: es
output {elasticsearch {hosts => "192.168.1.123:9200"index => "springboot-logs-%{+YYYY.MM.dd}"codec => "json"}
}启动logstash:进入logstash的bin目录:

在bin目录下执行启动命令:./logstash -f ../config/my.conf
这个插件比较吃内存,注意自己服务器内存,还有就是运行logstash的时候,需要等待观察,如果没有报错,就说明启动成功了。
如果es配置了密码,那么logstash也要设置连接的账号和密码,否则会导致logstash连接不上不这个es的。
input {tcp {mode => "server"host => "0.0.0.0"port => "9250"codec => json_lines}
}output {elasticsearch {hosts => ["http://es服务器ip地址:9200"]index => "r-pan-server-%{+YYYY.MM.dd}"codec => "json"user => "elastic" # 添加 Elasticsearch 用户名password => "es的密码" # 为es设置密码的时候建议六个账号都设置一样的密码}
}
项目服务集成日志收集
在使用到这个日志收集的服务中集成日志收集:
添加依赖:
<dependency><groupId>net.logstash.logback</groupId><artifactId>logstash-logback-encoder</artifactId><version>7.2</version>
</dependency>springcloud官方文档中有logstash相关的配置,如下: Spring Cloud Sleuth![]() https://docs.spring.io/spring-cloud-sleuth/docs/2.2.8.RELEASE/reference/html/#json-logback-with-logstash
https://docs.spring.io/spring-cloud-sleuth/docs/2.2.8.RELEASE/reference/html/#json-logback-with-logstash
自定义日志文件配置:
在想要进行日志采集的服务新增日志配置文件:

<?xml version="1.0" encoding="UTF-8"?><configuration debug="false"><!-- 彩色日志打印器 --><conversionRule conversionWord="clr" converterClass="org.springframework.boot.logging.logback.ColorConverter" /><conversionRule conversionWord="wex" converterClass="org.springframework.boot.logging.logback.WhitespaceThrowableProxyConverter" /><conversionRule conversionWord="wEx" converterClass="org.springframework.boot.logging.logback.ExtendedWhitespaceThrowableProxyConverter" /><!-- 彩色日志格式 --><property name="CONSOLE_LOG_PATTERN" value="${CONSOLE_LOG_PATTERN:-%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}}" /><appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern>${CONSOLE_LOG_PATTERN}</pattern><charset>utf8</charset></encoder></appender><!-- 控制台输出 --><!--<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">--><!--<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">--><!--<!–--><!--格式化输出:--><!--%d: 日期--><!--%thread: 线程名,--><!--%-5level: 日志级别从,左显示5个字符宽度--><!--%msg: 日志消息--><!--%n: 换行符--><!--–>--><!--<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>--><!--</encoder>--><!--</appender>--><!-- 日志文件的存储路径 --><property name="LOG_HOME" value="/MyApp/r-pan-logs" /><!-- 每天生成日志文件 --><appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><!-- 日志文件输出的文件名 --><FileNamePattern>${LOG_HOME}/r-pan.log.%d{yyyy-MM-dd}.log</FileNamePattern><!-- 日志文件保留天数 --><MaxHistory>60</MaxHistory></rollingPolicy><encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern></encoder><!-- 日志文件最大的大小 --><triggeringPolicy class="ch.qos.logback.core.rolling.SizeBasedTriggeringPolicy"><MaxFileSize>15MB</MaxFileSize></triggeringPolicy></appender><!-- 生成到logstash进行收集 --><appender name="ES_LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender"><!-- 日志输出的目标地址,logstash的部署地址:对应端口号 --><destination>自己logstashIp地址:9250</destination><encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder"><providers><pattern><pattern>{"timestamp": "@timestamp","severity": "%level","service": "${springAppName:-}","trace": "%X{traceId:-}","span": "%X{spanId:-}","baggage": "%X{key:-}","pid": "${PID:-}","thread": "%thread","class": "%logger{40}","rest": "%message"}</pattern></pattern></providers></encoder></appender><!-- 日志输出级别 --><root level="INFO"><appender-ref ref="STDOUT" /><appender-ref ref="FILE" /><appender-ref ref="ES_LOGSTASH" /></root></configuration>重启集成了日志的项目,然后去es中查看一下索引管理,是否产生我们需要的日志文档;
在kibana中对索引进行监控:使用通配符进行匹配的话,只要符合匹配的命名规则的索引都会被匹配进来,不仅仅是再局限于监控一个项目的日志信息。
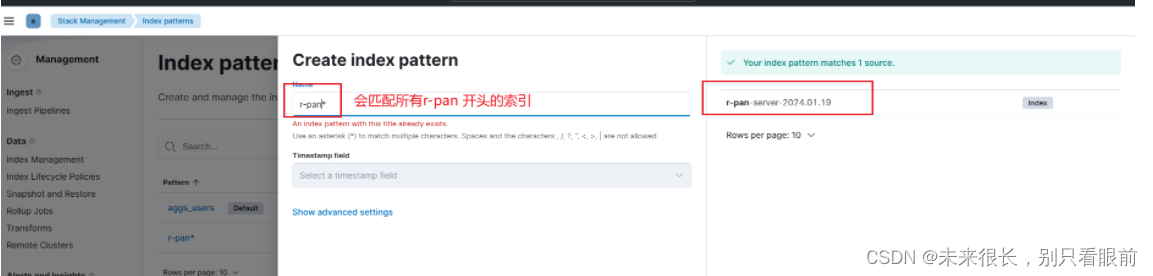
创建完成索引匹配模式之后,就可以去查看收集的日志信息了:
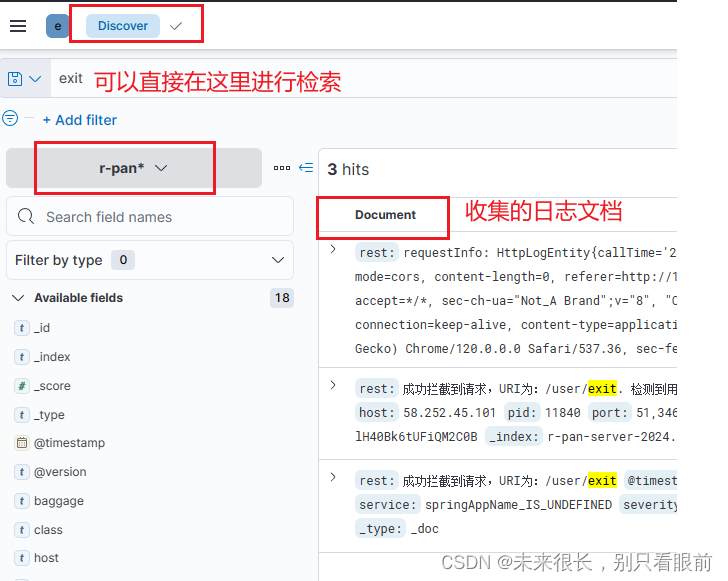
注意:需要注意的是,由于我们配置的info级别的日志记录,那么所有打印出来的info日志都会被收集存储在es中,所以在打印日志的时候就需要特别注意,不要什么日志信息都输出,不然可能会收集到很多没有意义的日志记录,从而降低了收集的日志数据的实用性,并且我们的索引命名是动态的,是根据日期来进行动态创建的,所以可能会导致索引非常多,这个需要注意。
为es设置登录密码
上面集成是成功了,但是我们并没有为访问es与访问kibana设置账号和密码,这个是很危险的操作,所以需要为es和kibana设置密码。
1、修改es的配置文件,由于我们安装的时候使用的文件挂载,所以可以直接在挂载的配置文件中修改就行:
es的配置修改为如下:
# 可以让es被任意其他ip进行访问,也可以按需配置ip
http.host: 0.0.0.0
http.cors.enabled: true
http.cors.allow-origin: "*"
# 下面三个是新增的,用来配置密码验证使用的
http.cors.allow-headers: Authorization
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true2、进入容器执行设置密码的指令:
docker exec -it es /bin/bash 3、执行创建新密码的指令
./bin/elasticsearch-setup-passwords interactive4、需要你输入密码,记得,全部输入一样的密码就行
# 为所有用户输入密码(可以为同一个),完事后回到宿主机
你的密码# 登录账号默认是 elastic
设置完成之后重启es容器:docker restart es
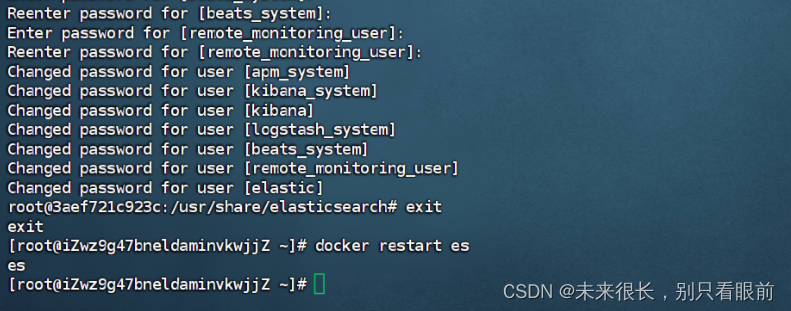
直接在浏览器访问es,如果出现弹窗让你输入账号和密码,账号为elastic,密码为刚刚设置的密码,可以成功登录就表示es的密码设置成功了。

为kibana设置登录密码
1、进入kibana容器设置连接密码:docker exec -it kibana /bin/bash
2、修改配置文件:vi config/kibana.yml
3、在配置文件中最近下面的配置:密码不要拼写错误了,拼写错误会导致连接不上es的,从而导致kibana启动失败。
# 会把我们的kibana页面设置为中文页面
i18n.locale: "zh-CN"
elasticsearch.username: "elastic"
elasticsearch.password: "xxxxx"4、 退出容器,并且重启kibana容器
exit
docker restart kibana
修改之后的kibana的配置文件如下:
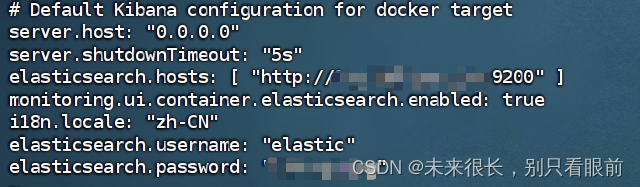
重启成功后,访问kibana,可以看到如下页面,并且输入账号 elastic,密码刚刚设置的密码可以登录成功,则表示kibana的密码也设置成功了。
还有就是注意,如果虚拟机或者是云主机内存不过的话,es很容易一直重启或者是挂掉。经常一下就把内存打满了:我这个4g的云主机目前只安装了如下软件:
-
docker
-
es 7.16.1
-
mongodb 6.0.3
-
redis 5.0.14
-
mysql 5.7.37
-
kibana 7.16.1
-
内存基本上都是98%的状态。logstash是通过原生的方式安装在另一台 2g的虚拟机上的,基本上也会500mb以上的内存空间。
注意,如果这里为es设置了密码,那么记得在logstash里面也要添加es的账号和密码!!!否则,logstash就连接不上es了!!!
为es容器设置内存限制
如果我们在运行es容器的时候忘记限制这个容器的内存,那么运行的时候可能会吃很多内存,限制es使用内存可以在两个地方设置,一个是第一次运行es容器的时候,在docker中进行设置,还有就是修改es中虚拟机的参数。
方法1:直接在运行的时候进行内存限制,这个比较推荐,不推荐修直接修改jvm.options
docker run --name es \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPS="-Xms256m -Xmx1024m" \
-v /home/elasticsearch7/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /home/elasticsearch7/data:/usr/share/elasticsearch/data \
-v /home/elasticsearch7/plugins:/usr/share/elasticsearch/plugins \
--restart=always \
-m 1.5g \
-d elasticsearch:7.16.1ES_JAVA_OPS 的设置仅影响 Elasticsearch 的 JVM 参数,而不会直接限制 Docker 容器的整体内存使用。Docker 容器的内存限制需要使用 Docker 命令的 -m 参数来设置。
方法2:先不要停止运行的es,然后进入es容器内部: docker exec -it es bash


进入config后,使用vi指令编辑 jvm.options 文件,这里只能使用vi指令,容器内部是没有vim工具的。然后在下面添加你想要限制的内存大小,我添加的1g的内存限制,可以根据自己的云服务的配置来。

然后退出容器,重新启动es :docker restart es
内存被限制了:
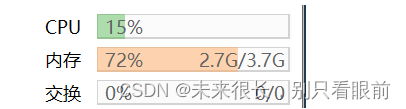
也可以使用docker state指令查看每个容器使用的内存,这里看到的是docker对容器的内存限制,如果在docker run容器的时候没有对容器的内存进行限制,那么它会默认使用服务器的最大内存为最大限制,在我没有修改jvm.options这个文件的时候,es使用的内存至少都是2.2g,目前得到了明显的控制。

注意的是:
-
JVM 内存参数中的
-Xmx仅控制 JVM 堆内存的大小,但 Elasticsearch 运行时可能还会使用额外的非堆内存。例如,Elasticsearch 还使用直接内存(off-heap memory)来存储数据,这不受 JVM 堆内存参数的限制。 -
Elasticsearch 进程本身也需要一些内存来运行,而不是完全分配给 JVM 堆内存。
-
除了 JVM 参数外,Elasticsearch 的其他配置项也可能影响内存的使用情况。例如,索引、缓存等配置可能会占用额外的内存。
使用htop或者是docker进行内存使用查询
如果服务器中的程序的运行没有在docker中运行,我们先查看云服务器中程序使用内存的情况,可以使用htop插件来查看内存使用情况:先安装top
sudo yum install htop 然后使用htop指令就行。然后使用 shift m 进行排序。
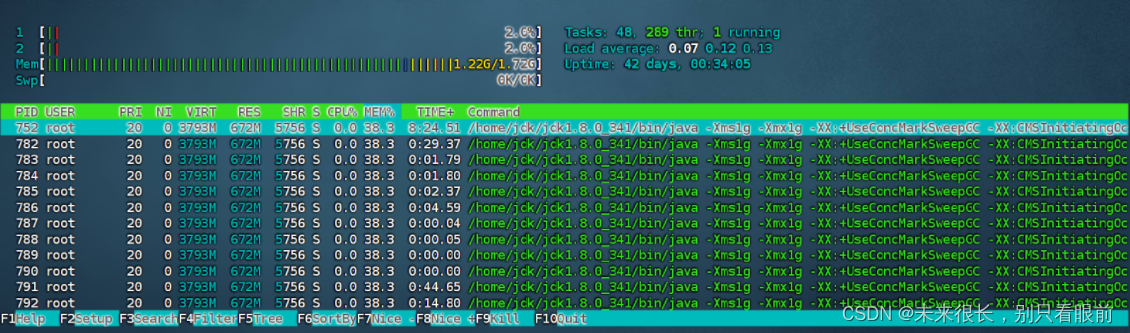
-
VIRT表示进程使用的虚拟内存量,包括实际使用的和被分配但尚未使用的内存。 -
RES表示进程使用的物理内存量,即实际占用的内存。 -
SHR表示进程使用的共享内存量。 -
%MEM表示进程占用系统物理内存的百分比。

如果安装了docker,想看docker中的容器使用内存和cpu的情况,可以使用下面的指令进行查看:
docker stats
这个指令可以动态显示容器中内存和cpu的使用情况,想要退出的话也比较简单,就是直接ctrl c就可以退出了。